Q Bench
1.0.0
Bagaimana kinerja LLM multi-modalitas pada visi komputer tingkat rendah?
Haoning Wu 1 * , Zicheng Zhang 2 * , Erli Zhang 1 * , Chaofeng Chen 1 , Liang Liao 1 ,
Annan Wang 1 , Chunyi Li 2 , Wenxiu Sun 3 , Qiong Yan 3 , Guangtao Zhai 2 , Weisi Lin 1 #
1 Universitas Teknologi Nanyang, 2 Universitas Shanghai Jiaotong, 3 Penelitian Sensetime
* Kontribusi yang sama. #Penulis koresponden.
Sorotan ICLR2024
Kertas | Halaman Proyek | Github | Data (LLVisionQA) | Data (LLDescribe) |质衡 (Cina-Q-Bench)


Q-Bench yang diusulkan mencakup tiga bidang untuk penglihatan tingkat rendah: persepsi (A1), deskripsi (A2), dan penilaian (A3).
Untuk persepsi (A1)/deskripsi (A2), kami mengumpulkan dua kumpulan data benchmark LLVisionQA/LLDescribe.
Kami terbuka untuk evaluasi berbasis penyerahan untuk kedua tugas tersebut. Adapun rincian penyerahannya adalah sebagai berikut.
Untuk penilaian (A3), karena kami menggunakan kumpulan data publik , kami menyediakan kode evaluasi abstrak untuk MLLM sewenang-wenang agar dapat diuji oleh siapa saja.
datasets Untuk Q-Bench-A1 (dengan pertanyaan pilihan ganda), kami telah mengubahnya menjadi kumpulan data berformat HF yang dapat diunduh secara otomatis dan digunakan dengan API datasets . Silakan lihat instruksi berikut:
kumpulan data pemasangan pip
dari kumpulan data impor load_datasetds = load_dataset("q-future/Q-Bench-HF")print(ds["dev"][0])### {'id': 0,### 'image': <PIL .JpegImagePlugin.JpegImageFile image mode=Ukuran RGB=4160x3120>,### 'question': 'Bagaimana pencahayaannya bangunan?',### 'option0': 'Tinggi',### 'option1': 'Rendah',### 'option2': 'Sedang',### 'option3': 'T/A', ### 'jenis_pertanyaan': 2,### 'masalah_pertanyaan': 3,### 'pilihan_benar': 'B'} dari kumpulan data impor load_datasetds = load_dataset("q-future/Q-Bench2-HF")print(ds["dev"][0])### {'id': 0,### 'image1': <PIL .Gambar.Mode gambar gambar=Ukuran RGB=4032x3024>,### 'gambar2': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=864x1152>,### 'question': 'Dibandingkan dengan gambar pertama, bagaimana kejelasan gambar kedua?',### 'option0': 'Lebih buram ',### 'option1': 'Lebih jelas',### 'option2': 'Hampir sama',### 'pilihan3': 'T/A',### 'tipe_pertanyaan': 2,### 'masalah_pertanyaan': 0,### 'pilihan_benar': 'B'}[2024/8/8] Bagian tugas perbandingan visi tingkat rendah dari Q-bench+ (juga disebut Q-Bench2) baru saja diterima oleh TPAMI! Datang dan uji MLLM Anda dengan Q-bench+_Dataset.
[2024/8/1] Q-Bench dirilis di VLMEvalKit, datang dan uji LMM Anda dengan satu perintah seperti `python run.py --data Q-Bench1_VAL Q-Bench1_TEST --model InternVL2-1B --verbose'.
[2024/6/17] Q-Bench , Q-Bench2 (Q-bench+), dan A-Bench kini telah bergabung dengan lmms-eval, yang memudahkan pengujian LMM !!
[2024/6/3] Repo Github untuk A-Bench sedang online. Apakah Anda ingin mengetahui apakah LMM Anda ahli dalam mengevaluasi gambar yang dihasilkan AI? Datang dan uji di A-Bench !!
[3/1] Kami merilis Co-instruct , Menuju Perbandingan Kualitas Visual Terbuka di sini. Detail lebih lanjut akan segera hadir.
[2/27] Q-Insturct karya kita telah diterima CVPR 2024, coba pelajari detail cara menginstruksikan MLLM pada low-level vision!
[23/2] Bagian tugas perbandingan visi tingkat rendah dari Q-bench+ kini dirilis di Q-bench+(Kumpulan Data)!
[2/10] Kami merilis Q-bench+ yang diperluas, yang menantang MLLM dengan gambar tunggal dan pasangan gambar pada penglihatan tingkat rendah. LeaderBoard ada di lokasi, lihat kemampuan penglihatan tingkat rendah untuk MLLM favorit Anda!! Detail lebih lanjut akan segera hadir.
[1/16] Pekerjaan kami "Q-Bench: Tolok Ukur untuk Model Landasan Tujuan Umum pada Visi Tingkat Rendah" diterima oleh ICLR2024 sebagai Presentasi Sorotan .

Kami menguji tiga model API sumber dekat, GPT-4V-Turbo ( gpt-4-vision-preview , menggantikan hasil GPT-4V versi lama yang tidak lagi tersedia), Gemini Pro ( gemini-pro-vision ) dan Qwen -VL-Plus ( qwen-vl-plus ). Sedikit lebih baik dibandingkan dengan versi lama, GPT-4V masih menjadi yang teratas di antara semua MLLM dan hampir mencapai kinerja manusia tingkat junior. Gemini Pro dan Qwen-VL-Plus mengikuti di belakang, masih lebih baik daripada MLLM sumber terbuka terbaik (keseluruhan 0,65).
Pembaruan pada [2024/7/18], Kami dengan senang hati merilis kinerja SOTA baru BlueImage-GPT (sumber dekat).
Persepsi, A1-Single
| Nama Peserta | ya-atau-tidak | Apa | Bagaimana | distorsi | yang lain | distorsi dalam konteks | dalam konteks yang lain | keseluruhan |
|---|---|---|---|---|---|---|---|---|
Qwen-VL-Plus ( qwen-vl-plus ) | 0,7574 | 0,7325 | 0,5733 | 0,6488 | 0,7324 | 0,6867 | 0,7056 | 0,6893 |
BlueImage-GPT ( from VIVO Juara Baru ) | 0,8467 | 0,8351 | 0,7469 | 0,7819 | 0,8594 | 0,7995 | 0,8240 | 0,8107 |
Gemini-Pro ( gemini-pro-vision ) | 0,7221 | 0,7300 | 0,6645 | 0,6530 | 0,7291 | 0,7082 | 0,7665 | 0,7058 |
GPT-4V-Turbo ( gpt-4-vision-preview ) | 0,7722 | 0,7839 | 0,6645 | 0,7101 | 0,7107 | 0,7936 | 0,7891 | 0,7410 |
| GPT-4V ( versi lama ) | 0,7792 | 0,7918 | 0,6268 | 0,7058 | 0,7303 | 0,7466 | 0,7795 | 0,7336 |
| manusia-1-junior | 0,8248 | 0,7939 | 0,6029 | 0,7562 | 0,7208 | 0,7637 | 0,7300 | 0,7431 |
| manusia-2-senior | 0,8431 | 0,8894 | 0,7202 | 0,7965 | 0,7947 | 0,8390 | 0,8707 | 0,8174 |
Persepsi, Pasangan A1
| Nama Peserta | ya-atau-tidak | Apa | Bagaimana | distorsi | yang lain | membandingkan | persendian | keseluruhan |
|---|---|---|---|---|---|---|---|---|
Qwen-VL-Plus ( qwen-vl-plus ) | 0,6685 | 0,5579 | 0,5991 | 0,6246 | 0,5877 | 0,6217 | 0,5920 | 0,6148 |
Qwen-VL-Max ( qwen-vl-max ) | 0,6765 | 0,6756 | 0,6535 | 0,6909 | 0,6118 | 0,6865 | 0,6129 | 0,6699 |
BlueImage-GPT ( from VIVO Juara Baru ) | 0,8843 | 0,8033 | 0,7958 | 0,8464 | 0,8062 | 0,8462 | 0,7955 | 0,8348 |
Gemini-Pro ( gemini-pro-vision ) | 0,6578 | 0,5661 | 0,5674 | 0,6042 | 0,6055 | 0,6046 | 0,6044 | 0,6046 |
GPT-4V ( gpt-4-vision ) | 0,7975 | 0,6949 | 0,8442 | 0,7732 | 0,7993 | 0,8100 | 0,6800 | 0,7807 |
| Manusia Tingkat Junior | 0,7811 | 0,7704 | 0,8233 | 0,7817 | 0,7722 | 0,8026 | 0,7639 | 0,8012 |
| Manusia Tingkat Senior | 0,8300 | 0,8481 | 0,8985 | 0,8313 | 0,9078 | 0,8655 | 0,8225 | 0,8548 |
Kami juga telah mengevaluasi beberapa model sumber terbuka baru baru-baru ini, dan akan segera merilis hasilnya.
Kami sekarang menyediakan dua cara untuk mengunduh kumpulan data (LLVisionQA&LLDescribe)
melalui Rilis GitHub: Silakan lihat rilis kami untuk detailnya.
melalui Kumpulan Data Huggingface: Silakan merujuk ke catatan rilis data untuk mengunduh gambar.
Sangat disarankan untuk mengonversi model Anda ke format Huggingface untuk menguji data ini dengan lancar. Lihat contoh skrip untuk IDEFICS-9B-Instruct Huggingface sebagai contoh, dan modifikasi skrip tersebut untuk model kustom Anda untuk diuji pada model Anda.
Silakan kirim email ke [email protected] untuk mengirimkan hasil Anda dalam format json.
Anda juga dapat mengirimkan model Anda (bisa berupa Huggingface AutoModel atau ModelScope AutoModel) kepada kami, bersama dengan skrip evaluasi khusus Anda. Skrip khusus Anda dapat dimodifikasi dari skrip templat yang berfungsi untuk LLaVA-v1.5 (untuk A1/A2), dan di sini (untuk penilaian kualitas gambar).
Silakan kirim email ke [email protected] untuk mengirimkan model Anda jika Anda berada di luar Tiongkok Daratan. Silakan kirim email [email protected] untuk mengirimkan model Anda jika Anda berada di Tiongkok Daratan.
Cuplikan untuk kumpulan data benchmark LLVisionQA untuk kemampuan persepsi tingkat rendah MLLM adalah sebagai berikut. Lihat papan peringkat di sini.
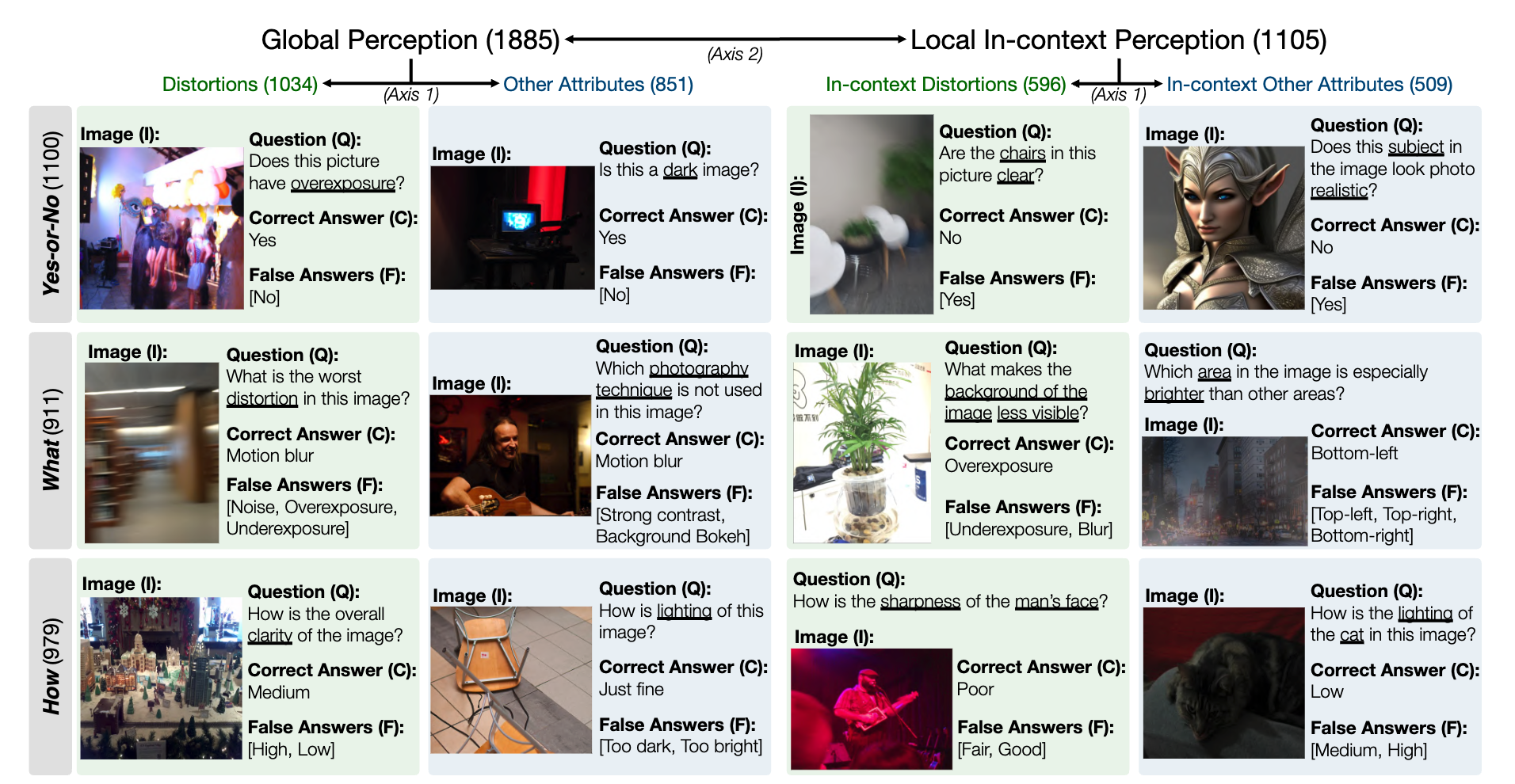
Kami mengukur akurasi jawaban MLLM (yang dilengkapi dengan pertanyaan dan semua pilihan) sebagai metrik di sini.
Cuplikan untuk kumpulan data tolok ukur LLDescribe untuk kemampuan deskripsi tingkat rendah MLLM adalah sebagai berikut. Lihat papan peringkat di sini.

Kami mengukur kelengkapan , ketepatan , dan relevansi deskripsi MLLM sebagai metrik di sini.
Kemampuan menarik yang dimiliki MLLM untuk memprediksi skor kuantitatif untuk IQA!
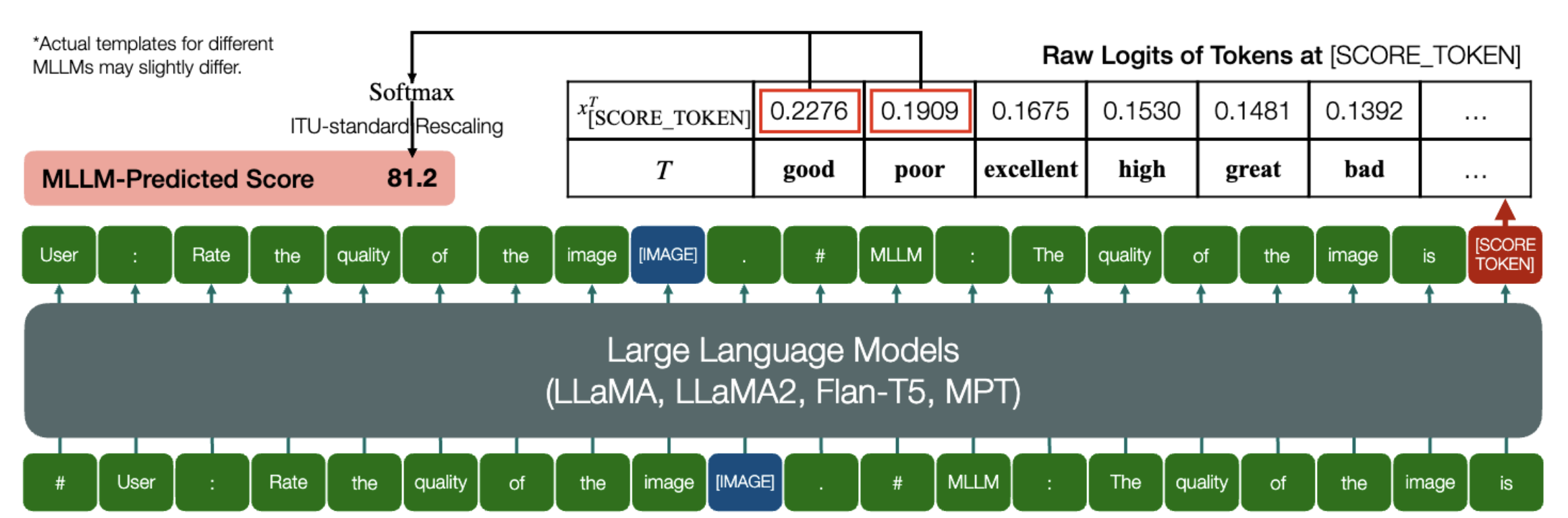
Sama seperti di atas, selama model (berdasarkan model bahasa kausal) memiliki dua metode berikut: embed_image_and_text (untuk memungkinkan masukan multi-modalitas), dan forward (untuk menghitung logit), Penilaian Kualitas Gambar (IQA) dengan model dapat dicapai sebagai berikut:
dari PIL impor Gambardari my_mllm_model impor Model, Tokenizer, embed_image_and_textmodel, tokenizer = Model(), Tokenizer()prompt = "##Pengguna: Nilai kualitas gambar.n"
"##Asisten: Kualitas gambar adalah" ### Baris ini dapat dimodifikasi berdasarkan perilaku default MLLM.good_idx, Poor_idx = tokenizer(["good","poor"]).tolist()image = Gambar. terbuka("image_for_iqa.jpg")input_embeds = embed_image_and_text(gambar, prompt)output_logits = model(input_embeds=input_embeds).logits[0,-1]q_pred = (output_logits[[good_idx, Poor_idx]] / 100).softmax(0)[0]*Perhatikan bahwa Anda dapat memodifikasi baris kedua berdasarkan format default model Anda, misalnya untuk Shikra, "##Asisten: Kualitas gambarnya" diubah menjadi "##Asisten: Jawabannya adalah". Tidak apa-apa jika MLLM Anda akan menjawab terlebih dahulu "Oke, saya ingin membantu! Kualitas gambarnya bagus", ganti saja ini ke baris 2 prompt.
Kami selanjutnya menyediakan implementasi penuh IDEFICS pada IQA. Lihat contoh cara menjalankan IQA dengan MLLM ini. MLLM lain juga dapat dimodifikasi dengan cara yang sama untuk digunakan di IQA.
Kami telah menyiapkan skor opini manusia (MOS) berformat JSON untuk tujuh database IQA sebagaimana dievaluasi dalam tolok ukur kami.
Silakan lihat IQA_databases untuk detailnya.
Dipindahkan ke papan peringkat. Silakan klik untuk melihat detailnya.
Silakan hubungi salah satu penulis pertama makalah ini untuk pertanyaan.
Haoning Wu, [email protected] , @teowu
Zicheng Zhang, [email protected] , @zzc-1998
Erli Zhang, [email protected] , @ZhangErliCarl
Jika menurut Anda karya kami menarik, silakan mengutip makalah kami:
@inproceedings{wu2024qbench,author = {Wu, Haoning dan Zhang, Zicheng dan Zhang, Erli dan Chen, Chaofeng dan Liao, Liang dan Wang, Annan dan Li, Chunyi dan Sun, Wenxiu dan Yan, Qiong dan Zhai, Guangtao dan Lin, Weisi},title = {Q-Bench: Tolok Ukur Model Yayasan Tujuan Umum pada Visi Tingkat Rendah},booktitle = {ICLR},year = {2024}} 

