LLM PuzzleTest
1.0.0
PuzzleVQA, kumpulan data baru kami mengungkapkan tantangan serius LLM multimodal dalam memahami pola abstrak sederhana. Kertas | Situs web
Kami merilis AlgoPuzzleVQA, kumpulan data baru dan menantang untuk penalaran multimodal! Kami akan segera merilis lebih banyak kumpulan data teka-teki multimodal. Pantau terus! Kertas | Situs web
Kami sangat gembira mengumumkan peluncuran dua kumpulan data VQA baru yang berpusat pada teka-teki:
Kinerja MLLM pada kedua dataset tersebut masih sangat kurang, sehingga menggarisbawahi kebutuhan mendesak akan peningkatan substansial dalam kemampuan penalaran multimoda mereka.
Model multimodal besar memperluas kemampuan model bahasa besar yang mengesankan dengan mengintegrasikan kemampuan pemahaman multimodal. Namun, tidak jelas bagaimana mereka bisa meniru kecerdasan umum dan kemampuan berpikir manusia. Karena mengenali pola dan mengabstraksi konsep adalah kunci kecerdasan umum, kami memperkenalkan PuzzleVQA, kumpulan teka-teki berdasarkan pola abstrak. Dengan kumpulan data ini, kami mengevaluasi model multimodal besar dengan pola abstrak berdasarkan konsep dasar, termasuk warna, angka, ukuran, dan bentuk. Melalui eksperimen kami pada model multimodal besar yang canggih, kami menemukan bahwa model tersebut tidak mampu menggeneralisasi dengan baik pola abstrak sederhana. Khususnya, bahkan GPT-4V tidak dapat memecahkan lebih dari separuh teka-teki. Untuk mendiagnosis tantangan penalaran dalam model multimodal besar, kami secara progresif memandu model dengan penjelasan penalaran kebenaran dasar untuk persepsi visual, penalaran induktif, dan penalaran deduktif. Analisis sistematis kami menemukan bahwa hambatan utama GPT-4V adalah lemahnya persepsi visual dan kemampuan penalaran induktif. Melalui penelitian ini, kami berharap dapat menjelaskan keterbatasan model multimodal besar dan bagaimana model tersebut dapat meniru proses kognitif manusia dengan lebih baik di masa depan.
PuzzleVQA tersedia di sini dan juga di Huggingface.
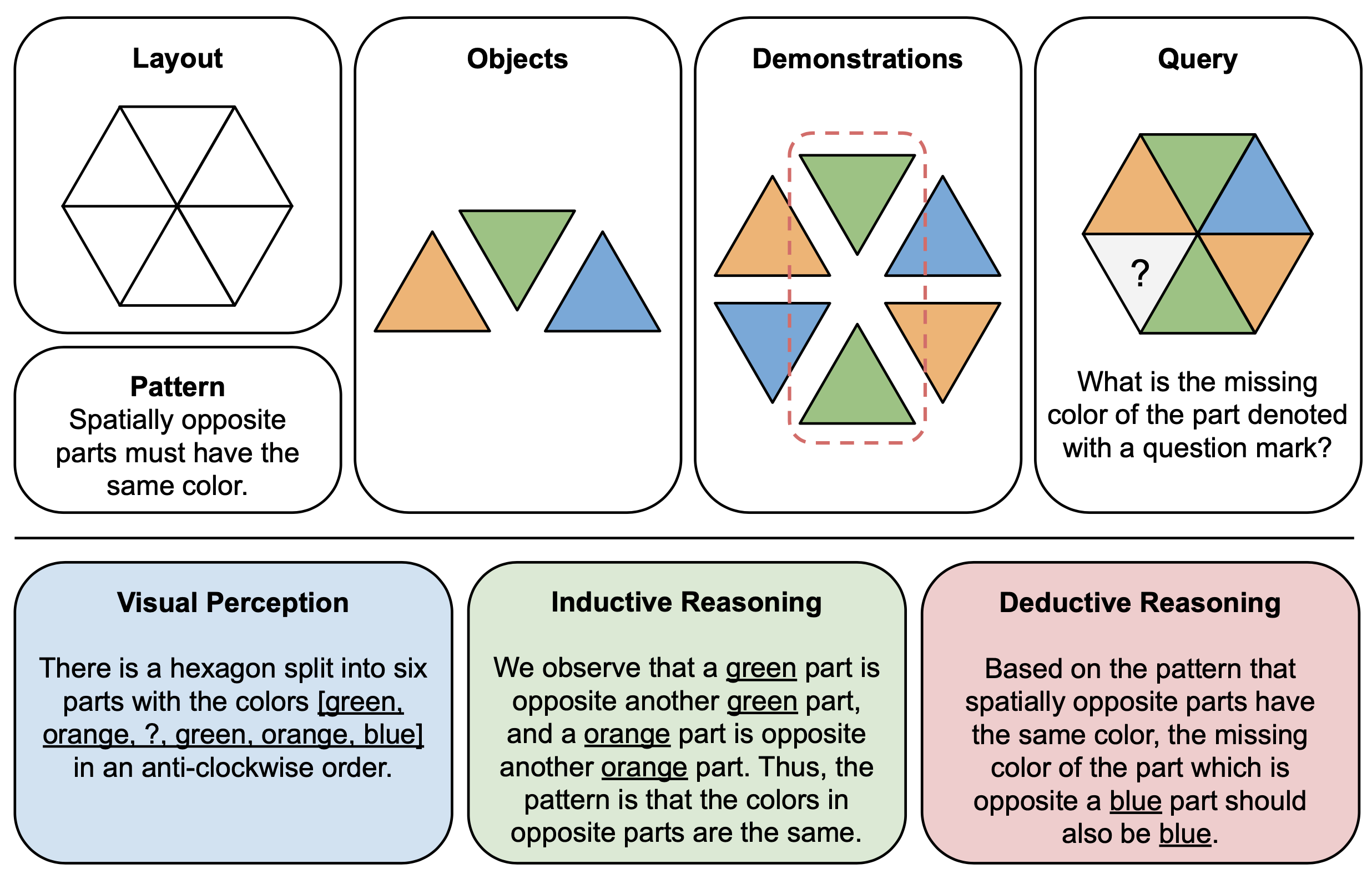
Gambar di bawah menunjukkan contoh pertanyaan yang melibatkan konsep warna di PuzzleVQA, dan jawaban yang salah dari GPT-4V. Secara umum ada tiga tahapan yang dapat diamati dalam proses penyelesaian: persepsi visual (biru), penalaran induktif (hijau), dan penalaran deduktif (merah). Di sini, persepsi visual tidak lengkap sehingga menyebabkan kesalahan dalam penalaran deduktif.

Gambar di bawah ini menunjukkan contoh ilustrasi komponen (atas) dan penjelasan alasan (bawah) untuk teka-teki abstrak di PuzzleVQA. Untuk membuat setiap contoh teka-teki, pertama-tama kita menentukan tata letak dan pola templat multimodal, dan mengisi templat dengan objek yang sesuai yang menunjukkan pola yang mendasarinya. Untuk interpretabilitas, kami juga menyusun penjelasan penalaran kebenaran dasar untuk menafsirkan teka-teki dan menjelaskan tahapan solusi umum.
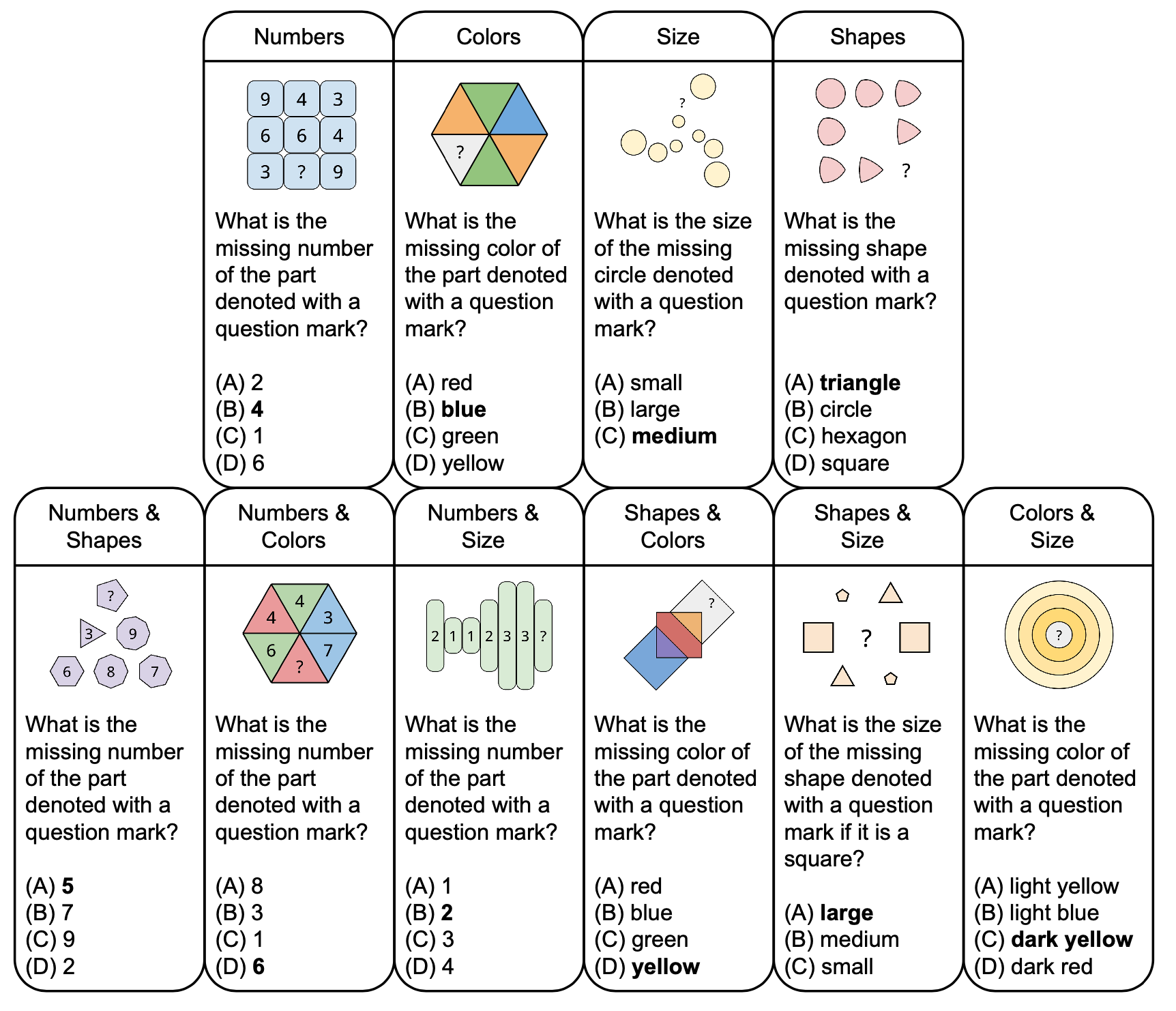
Gambar di bawah menunjukkan taksonomi teka-teki abstrak di PuzzleVQA dengan contoh pertanyaan, berdasarkan konsep dasar seperti warna dan ukuran. Untuk meningkatkan keberagaman, kami merancang teka-teki berkonsep tunggal dan berkonsep ganda.
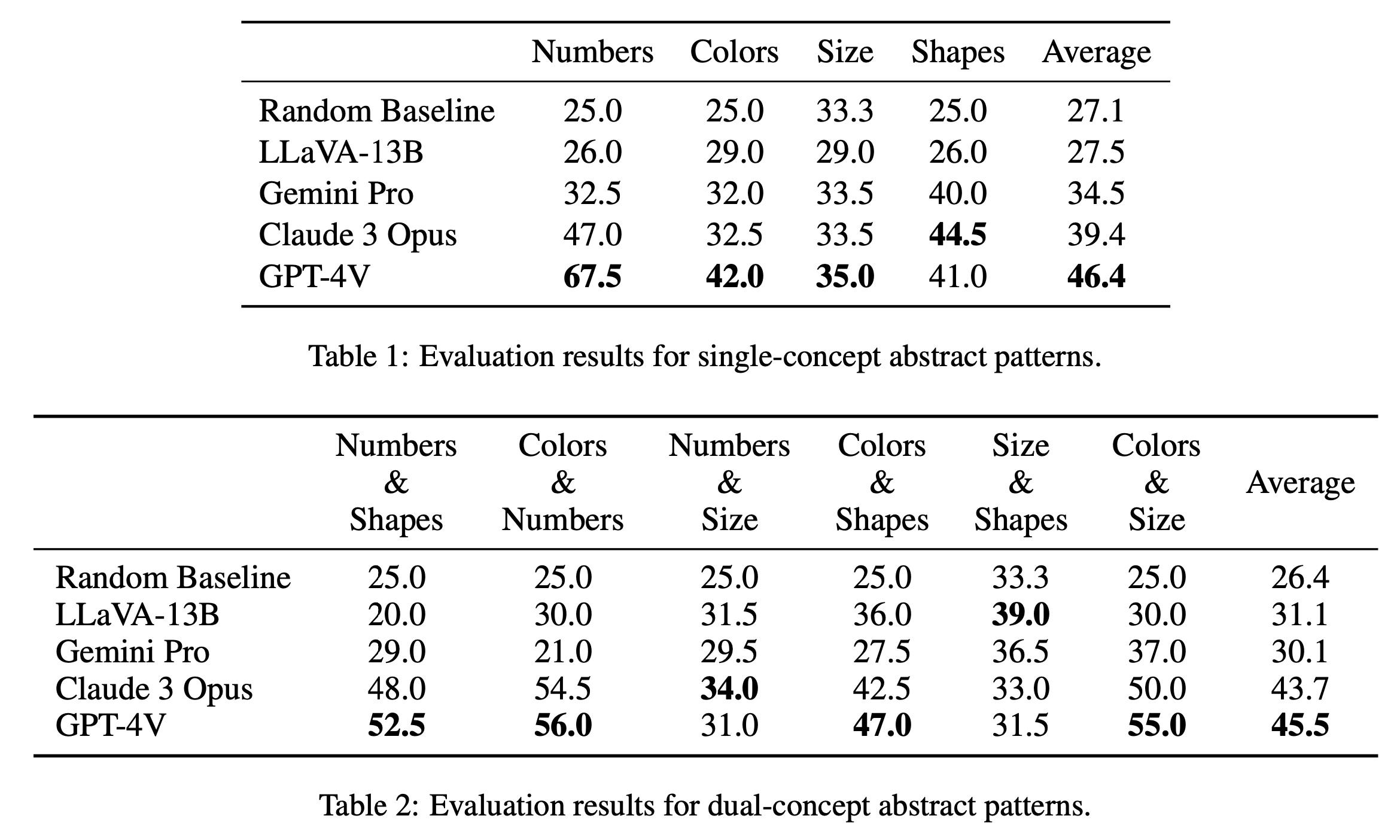
Kami melaporkan hasil evaluasi utama pada teka-teki konsep tunggal dan konsep ganda masing-masing pada Tabel 1 dan Tabel 2. Hasil evaluasi untuk teka-teki konsep tunggal, seperti yang ditunjukkan pada Tabel 1, menunjukkan perbedaan performa yang mencolok antara model sumber terbuka dan sumber tertutup. GPT-4V menonjol dengan skor rata-rata tertinggi sebesar 46,4, menunjukkan penalaran pola abstrak yang unggul pada teka-teki konsep tunggal seperti angka, warna, dan ukuran. Model ini khususnya unggul dalam kategori "Angka" dengan skor 67,5, jauh melampaui model lainnya, yang mungkin disebabkan oleh keunggulannya dalam tugas-tugas penalaran matematika (Yang et al., 2023). Claude 3 Opus menyusul dengan rata-rata keseluruhan 39,4, menunjukkan kekuatannya dalam kategori "Bentuk" dengan skor tertinggi 44,5. Model lainnya, termasuk Gemini Pro dan LLaVA-13B tertinggal di belakang dengan rata-rata masing-masing 34,5 dan 27,5, dengan kinerja serupa dengan baseline acak pada beberapa kategori.
Dalam evaluasi teka-teki konsep ganda, seperti yang ditunjukkan pada Tabel 2, GPT-4V kembali menonjol dengan skor rata-rata tertinggi 45,5. Performanya sangat baik dalam kategori seperti "Warna & Angka" dan "Warna & Ukuran" dengan skor masing-masing 56,0 dan 55,0. Claude 3 Opus menyusul dengan rata-rata 43,7, menunjukkan kinerja yang kuat dalam "Angka & Ukuran" dengan skor tertinggi 34,0. Menariknya, LLaVA-13B, meskipun rata-rata keseluruhannya lebih rendah yaitu 31,1, mendapat skor tertinggi dalam kategori "Ukuran & Bentuk" yaitu 39,0. Gemini Pro, sebaliknya, memiliki kinerja yang lebih seimbang di seluruh kategori tetapi dengan rata-rata keseluruhan sedikit lebih rendah yaitu 30,1. Secara keseluruhan, kami menemukan bahwa rata-rata kinerja model sama untuk pola konsep tunggal dan konsep ganda, yang menunjukkan bahwa model tersebut mampu menghubungkan beberapa konsep seperti warna dan angka secara bersamaan.
@misc{chia2024puzzlevqa,
title={PuzzleVQA: Diagnosing Multimodal Reasoning Challenges of Language Models with Abstract Visual Patterns},
author={Yew Ken Chia and Vernon Toh Yan Han and Deepanway Ghosal and Lidong Bing and Soujanya Poria},
year={2024},
eprint={2403.13315},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Kami memperkenalkan tugas baru pemecahan teka-teki multimodal, yang dibingkai dalam konteks tanya jawab visual. Kami menyajikan kumpulan data baru, AlgoPuzzleVQA yang dirancang untuk menantang dan mengevaluasi kemampuan model bahasa multimodal dalam memecahkan teka-teki algoritmik yang memerlukan pemahaman visual, pemahaman bahasa, dan penalaran algoritmik yang kompleks. Kami membuat teka-teki untuk mencakup beragam topik matematika dan algoritmik seperti logika boolean, kombinatorik, teori grafik, pengoptimalan, penelusuran, dll., yang bertujuan untuk mengevaluasi kesenjangan antara interpretasi data visual dan keterampilan pemecahan masalah algoritmik. Kumpulan data dihasilkan secara otomatis dari kode yang dibuat oleh manusia. Semua teka-teki kami memiliki solusi tepat yang dapat ditemukan dari algoritme tanpa perhitungan manusia yang membosankan. Hal ini memastikan bahwa kumpulan data kami dapat ditingkatkan secara sewenang-wenang dalam hal kompleksitas penalaran dan ukuran kumpulan data. Investigasi kami mengungkapkan bahwa model bahasa besar (LLM) seperti GPT4V dan Gemini menunjukkan kinerja yang terbatas dalam tugas pemecahan teka-teki. Kami menemukan bahwa kinerja mereka hampir acak dalam pengaturan tanya jawab pilihan ganda untuk sejumlah besar teka-teki. Temuan ini menekankan tantangan dalam mengintegrasikan pengetahuan visual, bahasa, dan algoritmik untuk memecahkan masalah penalaran yang kompleks.
PuzzleVQA tersedia di sini dan juga di Huggingface.
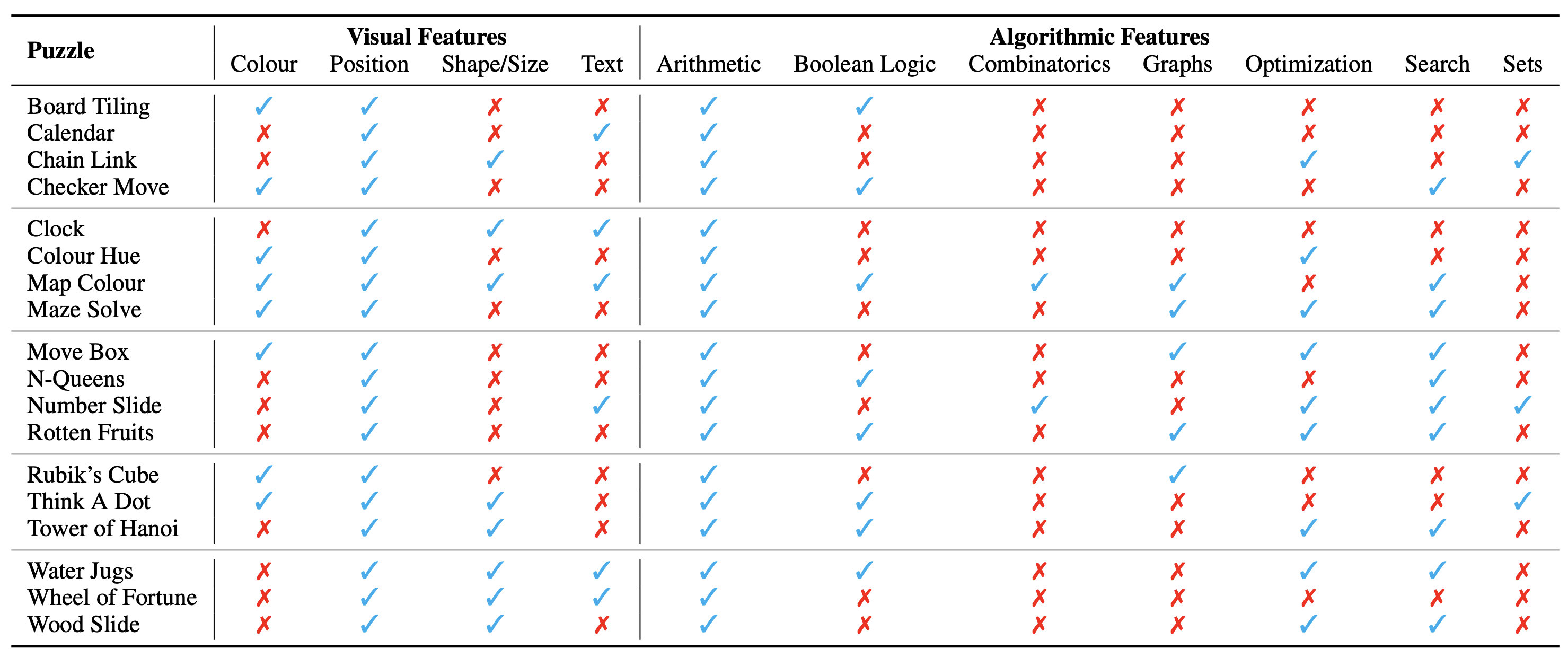
Konfigurasi puzzle/masalah ditampilkan dalam bentuk gambar yang merupakan konteks visualnya. Kami mengidentifikasi aspek fundamental berikut dari konteks visual yang memengaruhi sifat teka-teki:

Kami juga mengidentifikasi konsep algoritmik yang diperlukan untuk memecahkan teka-teki, misalnya untuk menjawab pertanyaan pada contoh teka-teki tersebut. Mereka adalah sebagai berikut:

Kategori algoritmik tidak saling eksklusif, karena kita perlu menggunakan dua kategori atau lebih untuk mendapatkan jawaban bagi sebagian besar teka-teki.
Kumpulan data tersedia di sini dalam format ini. Kami membuat total 18 teka-teki berbeda yang mencakup berbagai topik algoritmik dan matematika. Banyak dari teka-teki ini populer di berbagai lingkungan rekreasi atau akademis.
Secara total, kami memiliki 1800 contoh dari 18 teka-teki berbeda. Contoh-contoh ini dapat dianalogikan dengan kasus uji teka-teki yang berbeda, yaitu contoh-contoh tersebut mempunyai kombinasi masukan yang berbeda, status awal dan tujuan, dll. Penyelesaian semua contoh yang andal memerlukan pencarian algoritma yang tepat untuk digunakan dan kemudian menerapkannya secara akurat. Hal ini mirip dengan cara kami memverifikasi keakuratan program komputer yang bertujuan untuk menyelesaikan tugas tertentu melalui berbagai kasus uji.
Saat ini kami menganggap kumpulan data lengkap sebagai tolok ukur evaluasi saja . Contoh detail dari semua teka-teki ditampilkan di sini.
Petunjuk untuk menghasilkan kumpulan data dapat ditemukan di sini. Jumlah contoh dan tingkat kesulitan teka-teki dapat ditingkatkan secara sewenang-wenang ke ukuran atau level apa pun yang diinginkan.
Kategorisasi ontologis dari teka-teki tersebut adalah sebagai berikut:
Pengaturan eksperimental dan skrip dapat ditemukan di direktori AlgoPuzzleVQA.
Silakan pertimbangkan untuk mengutip artikel berikut jika Anda merasa pekerjaan kami bermanfaat:
@article { ghosal2024algopuzzlevqa ,
title = { Are Language Models Puzzle Prodigies? Algorithmic Puzzles Unveil Serious Challenges in Multimodal Reasoning } ,
author = { Ghosal, Deepanway and Han, Vernon Toh Yan and Chia, Yew Ken and and Poria, Soujanya } ,
journal = { arXiv preprint arXiv:2403.03864 } ,
year = { 2024 }
}

