DiagGPT
1.0.0
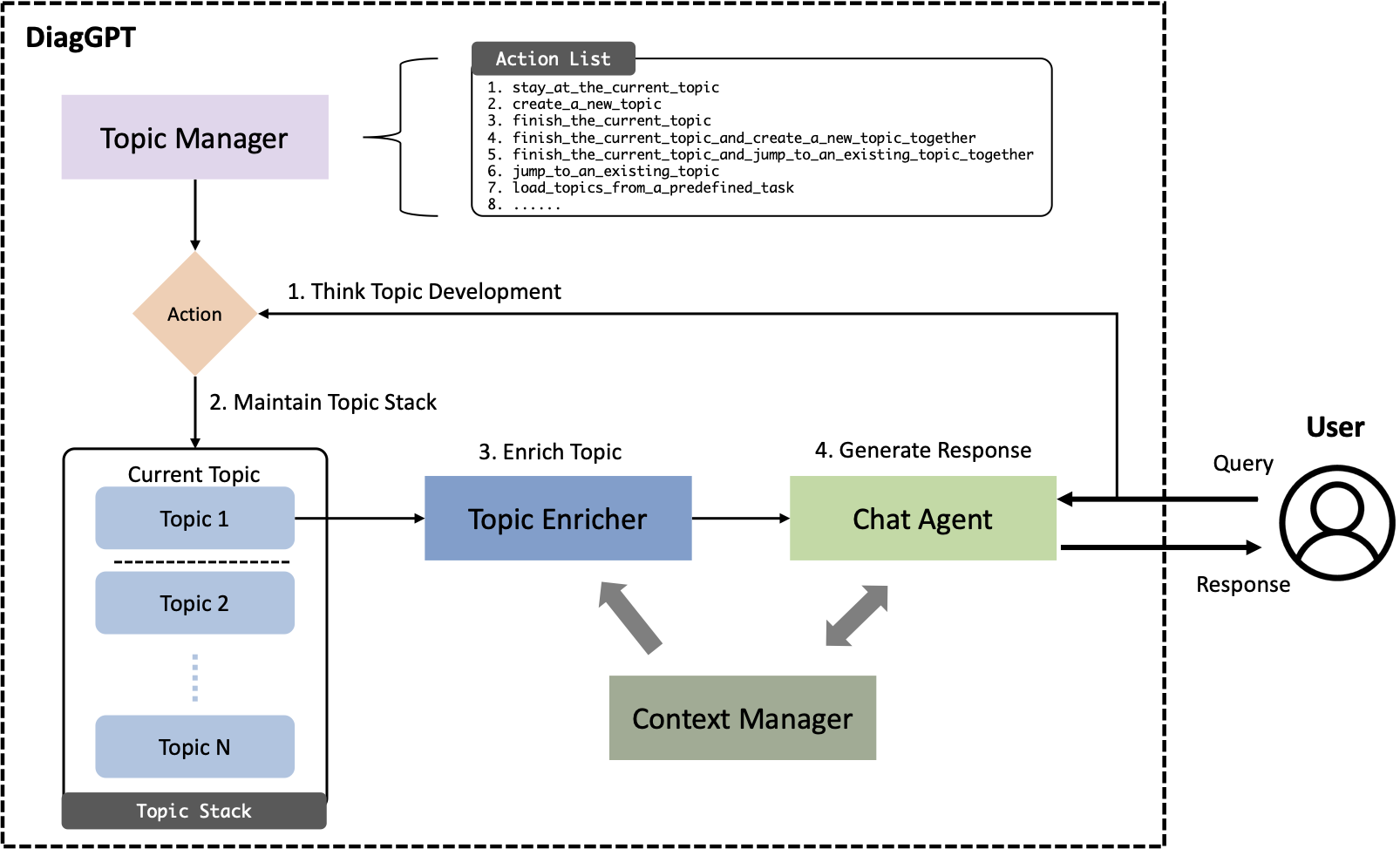
Penerapan signifikan Model Bahasa Besar (LLM), seperti ChatGPT, adalah penerapannya sebagai agen obrolan, yang merespons pertanyaan manusia di berbagai domain. Meskipun LLM saat ini mampu menjawab pertanyaan umum dengan baik, mereka sering kali gagal dalam skenario diagnostik yang kompleks seperti konsultasi hukum, medis, atau konsultasi khusus lainnya. Skenario ini biasanya memerlukan Dialog Berorientasi Tugas (TOD), di mana agen obrolan AI harus secara proaktif mengajukan pertanyaan dan memandu pengguna menuju tujuan atau penyelesaian tugas tertentu. Model penyempurnaan sebelumnya memiliki kinerja yang buruk dalam TOD dan potensi penuh dari kemampuan percakapan di LLM saat ini belum sepenuhnya dieksplorasi. Dalam makalah ini, kami memperkenalkan DiagGPT (Dialog dalam Diagnosis GPT), sebuah pendekatan inovatif yang memperluas LLM ke lebih banyak skenario TOD. Selain memandu pengguna menyelesaikan tugas, DiagGPT dapat secara efektif mengelola status semua topik selama pengembangan dialog. Fitur ini meningkatkan pengalaman pengguna dan menawarkan interaksi yang lebih fleksibel di TOD. Eksperimen kami menunjukkan bahwa DiagGPT menunjukkan kinerja luar biasa dalam melakukan TOD dengan pengguna, menunjukkan potensinya untuk aplikasi praktis di berbagai bidang.
Kami membuat kumpulan data baru, LLM-TOD (dialog berorientasi tugas untuk kumpulan data model bahasa besar). Hal ini digunakan untuk mengevaluasi kinerja model dialog berorientasi tugas berbasis LLM secara kuantitatif. Kumpulan data terdiri dari 20 data, masing-masing mewakili topik berbeda: klinis, restoran, hotel, rumah sakit, kereta api, polisi, bus, atraksi, bandara, bar, perpustakaan, museum, taman, pusat kebugaran, bioskop, kantor, tempat pangkas rambut, toko roti, kebun binatang, dan bank.
.
├── chatgpt # implementation of base chatgpt
├── data
│ └── LLM-TOD # LLM-TOD dataset
├── demo.py # DiagGPT for demo test
├── diaggpt # simple version of DiagGPT for quantitative experiments
├── diaggpt_medical # full version of DiagGPT in the medical consulting scenario
│ ├── embedding # file store, retrieval, etc.
│ ├── main.py # main code of implementation
│ ├── prompts # all prompts in DiagGPT
│ ...
├── evalgpt # implementation of GPT evaluation
├── exp.py # code of quantitative experiments
├── exp_output # experiment results
├── openai_api_key.txt # openai key
├── requirements.txt # dependencies
├── usergpt # simulation of the user for quantitative experiments
...pip install -r requirements.txttouch openai_api_key.txt # put your openai api key in it
python demo.py # demo test
python exp.py # run quantitative experimentsBerikut adalah demo yang sangat sederhana dari proses obrolan chatbot dalam skenario diagnosis medis. Kami mensimulasikan proses kunjungan pasien ke dokter. (Beberapa masukan pasien/pengguna dihasilkan oleh GPT-4.)
Dalam proses ini, dokter terus mengumpulkan informasi dari pasien dan menganalisisnya langkah demi langkah
Saat ini, fungsi proyek yang ada masih sangat awal. Ini hanya versi demonstrasi untuk menunjukkan kemampuan manajemen topik LLM, yang tidak dapat memenuhi kebutuhan konsultasi profesional yang sebenarnya.
Tujuan utama eksperimen ini adalah untuk mendemonstrasikan potensi GPT-4, namun penting untuk diingat bahwa ini bukanlah aplikasi atau produk yang sepenuhnya disempurnakan, melainkan sebuah proyek eksperimental. Ada kemungkinan GPT-4 tidak bekerja secara optimal dalam skenario bisnis dunia nyata yang kompleks. Kami mendorong Anda untuk memperbaikinya dan menerapkannya dalam berbagai skenario, dan kami akan senang mendengar hasil Anda!
Jika Anda merasa repo ini bermanfaat, silakan kutip makalah berikut:
@misc{cao2023diaggpt,
title={DiagGPT: An LLM-based and Multi-agent Dialogue System with Automatic Topic Management for Flexible Task-Oriented Dialogue},
author={Lang Cao},
year={2023},
eprint={2308.08043},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


