lightllm
1.0.0
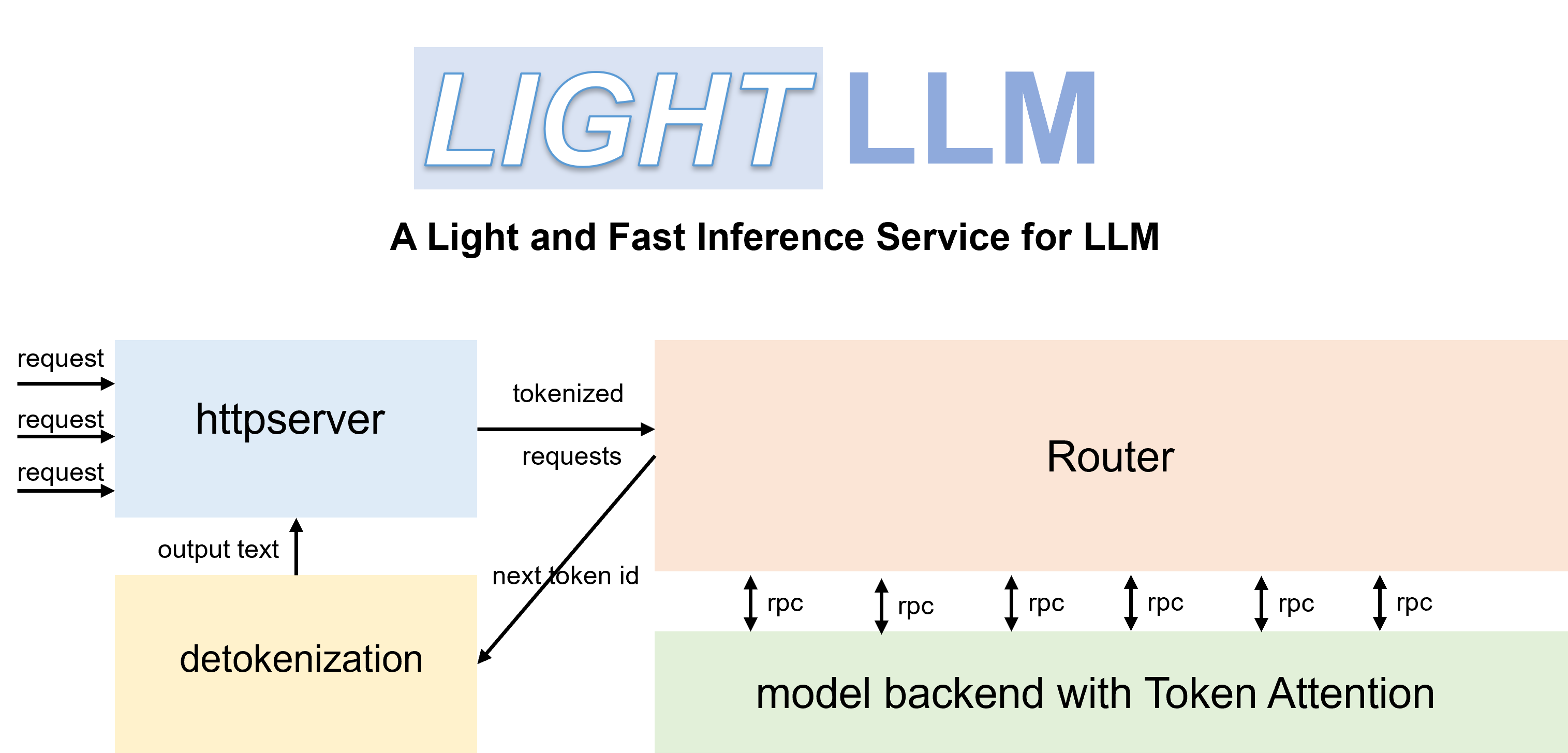
LightLLM adalah kerangka kerja inferensi dan penyajian LLM (Model Bahasa Besar) berbasis Python, terkenal karena desainnya yang ringan, skalabilitas yang mudah, dan kinerja kecepatan tinggi. LightLLM memanfaatkan kekuatan dari berbagai implementasi sumber terbuka yang terkenal, termasuk namun tidak terbatas pada FasterTransformer, TGI, vLLM, dan FlashAttention.
Dokumen Bahasa Inggris | 中文文档
Saat Anda memulai Qwen-7b, Anda perlu mengatur parameter '--eos_id 151643 --trust_remote_code'.
ChatGLM2 perlu menyetel parameter '--trust_remote_code'.
InternLM perlu menyetel parameter '--trust_remote_code'.
InternVL-Chat(Phi3) perlu menyetel parameter '--eos_id 32007 --trust_remote_code'.
InternVL-Chat(InternLM2) perlu menyetel parameter '--eos_id 92542 --trust_remote_code'.
Qwen2-VL-7b perlu menyetel parameter '--eos_id 151645 --trust_remote_code', dan menggunakan 'pip install git+https://github.com/huggingface/transformers' untuk meningkatkan ke versi terbaru.
Stablelm perlu menyetel parameter '--trust_remote_code'.
Phi-3 hanya mendukung Mini dan Kecil.
DeepSeek-V2-Lite dan DeepSeek-V2 perlu mengatur parameter '--data_type bfloat16'
Kode telah diuji dengan Pytorch>=1.3, CUDA 11.8, dan Python 3.9. Untuk menginstal dependensi yang diperlukan, silakan merujuk ke persyaratan.txt yang disediakan dan ikuti petunjuk sebagai
# for cuda 11.8
pip install -r requirements.txt --extra-index-url https://download.pytorch.org/whl/cu118
# this version nccl can support torch cuda graph
pip install nvidia-nccl-cu12==2.20.5Anda dapat menggunakan container Docker resmi untuk menjalankan model dengan lebih mudah. Untuk melakukannya, ikuti langkah-langkah berikut:
Tarik kontainer dari GitHub Container Registry:
docker pull ghcr.io/modeltc/lightllm:mainJalankan container dengan dukungan GPU dan pemetaan port:
docker run -it --gpus all -p 8080:8080
--shm-size 1g -v your_local_path:/data/
ghcr.io/modeltc/lightllm:main /bin/bashAlternatifnya, Anda dapat membuat wadah sendiri:
docker build -t < image_name > .
docker run -it --gpus all -p 8080:8080
--shm-size 1g -v your_local_path:/data/
< image_name > /bin/bashAnda juga dapat menggunakan skrip pembantu untuk meluncurkan kontainer dan server:
python tools/quick_launch_docker.py --help Catatan: Jika Anda menggunakan beberapa GPU, Anda mungkin perlu menambah ukuran memori bersama dengan menambahkan --shm-size ke perintah docker run .
python setup.py installKode ini telah diuji pada berbagai GPU termasuk V100, A100, A800, 4090, dan H800. Jika Anda menjalankan kode pada A100, A800, dll., sebaiknya gunakan triton==3.0.0.
pip install triton==3.0.0 --no-depsJika Anda menjalankan kode pada H800 atau V100., Anda dapat mencoba triton-nightly untuk mendapatkan kinerja yang lebih baik.
pip install -U --index-url https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/Triton-Nightly/pypi/simple/ triton-nightly --no-depsDengan Router dan TokenAttention yang efisien, LightLLM dapat diterapkan sebagai layanan dan mencapai kinerja throughput yang canggih.
Luncurkan server:
python -m lightllm.server.api_server --model_dir /path/llama-7B
--host 0.0.0.0
--port 8080
--tp 1
--max_total_token_num 120000 Parameter max_total_token_num dipengaruhi oleh memori GPU pada lingkungan penerapan. Anda juga dapat menentukan --mem_faction agar dihitung secara otomatis.
python -m lightllm.server.api_server --model_dir /path/llama-7B
--host 0.0.0.0
--port 8080
--tp 1
--mem_faction 0.9Untuk memulai kueri di shell:
curl http://127.0.0.1:8080/generate
-X POST
-d ' {"inputs":"What is AI?","parameters":{"max_new_tokens":17, "frequency_penalty":1}} '
-H ' Content-Type: application/json 'Untuk melakukan kueri dari Python:
import time
import requests
import json
url = 'http://localhost:8080/generate'
headers = { 'Content-Type' : 'application/json' }
data = {
'inputs' : 'What is AI?' ,
"parameters" : {
'do_sample' : False ,
'ignore_eos' : False ,
'max_new_tokens' : 1024 ,
}
}
response = requests . post ( url , headers = headers , data = json . dumps ( data ))
if response . status_code == 200 :
print ( response . json ())
else :
print ( 'Error:' , response . status_code , response . text )python -m lightllm.server.api_server
--host 0.0.0.0
--port 8080
--tp 1
--max_total_token_num 12000
--trust_remote_code
--enable_multimodal
--cache_capacity 1000
--model_dir /path/of/Qwen-VL or /path/of/Qwen-VL-Chatpython -m lightllm.server.api_server
--host 0.0.0.0
--port 8080
--tp 1
--max_total_token_num 12000
--trust_remote_code
--enable_multimodal
--cache_capacity 1000
--model_dir /path/of/llava-v1.5-7b or /path/of/llava-v1.5-13b import time
import requests
import json
import base64
url = 'http://localhost:8080/generate'
headers = { 'Content-Type' : 'application/json' }
uri = "/local/path/of/image" # or "/http/path/of/image"
if uri . startswith ( "http" ):
images = [{ "type" : "url" , "data" : uri }]
else :
with open ( uri , 'rb' ) as fin :
b64 = base64 . b64encode ( fin . read ()). decode ( "utf-8" )
images = [{ 'type' : "base64" , "data" : b64 }]
data = {
"inputs" : "<img></img>Generate the caption in English with grounding:" ,
"parameters" : {
"max_new_tokens" : 200 ,
# The space before <|endoftext|> is important, the server will remove the first bos_token_id, but QWen tokenizer does not has bos_token_id
"stop_sequences" : [ " <|endoftext|>" ],
},
"multimodal_params" : {
"images" : images ,
}
}
response = requests . post ( url , headers = headers , data = json . dumps ( data ))
if response . status_code == 200 :
print ( response . json ())
else :
print ( 'Error:' , response . status_code , response . text ) import json
import requests
import base64
def run_once ( query , uris ):
images = []
for uri in uris :
if uri . startswith ( "http" ):
images . append ({ "type" : "url" , "data" : uri })
else :
with open ( uri , 'rb' ) as fin :
b64 = base64 . b64encode ( fin . read ()). decode ( "utf-8" )
images . append ({ 'type' : "base64" , "data" : b64 })
data = {
"inputs" : query ,
"parameters" : {
"max_new_tokens" : 200 ,
# The space before <|endoftext|> is important, the server will remove the first bos_token_id, but QWen tokenizer does not has bos_token_id
"stop_sequences" : [ " <|endoftext|>" , " <|im_start|>" , " <|im_end|>" ],
},
"multimodal_params" : {
"images" : images ,
}
}
# url = "http://127.0.0.1:8080/generate_stream"
url = "http://127.0.0.1:8080/generate"
headers = { 'Content-Type' : 'application/json' }
response = requests . post ( url , headers = headers , data = json . dumps ( data ))
if response . status_code == 200 :
print ( " + result: ({})" . format ( response . json ()))
else :
print ( ' + error: {}, {}' . format ( response . status_code , response . text ))
"""
multi-img, multi-round:
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
<img></img>
<img></img>
上面两张图片分别是哪两个城市?请对它们进行对比。<|im_end|>
<|im_start|>assistant
根据提供的信息,两张图片分别是重庆和北京。<|im_end|>
<|im_start|>user
这两座城市分别在什么地方?<|im_end|>
<|im_start|>assistant
"""
run_once (
uris = [
"assets/mm_tutorial/Chongqing.jpeg" ,
"assets/mm_tutorial/Beijing.jpeg" ,
],
query = "<|im_start|>system n You are a helpful assistant.<|im_end|> n <|im_start|>user n <img></img> n <img></img> n上面两张图片分别是哪两个城市?请对它们进行对比。<|im_end|> n <|im_start|>assistant n根据提供的信息,两张图片分别是重庆和北京。<|im_end|> n <|im_start|>user n这两座城市分别在什么地方?<|im_end|> n <|im_start|>assistant n "
) import time
import requests
import json
import base64
url = 'http://localhost:8080/generate'
headers = { 'Content-Type' : 'application/json' }
uri = "/local/path/of/image" # or "/http/path/of/image"
if uri . startswith ( "http" ):
images = [{ "type" : "url" , "data" : uri }]
else :
with open ( uri , 'rb' ) as fin :
b64 = base64 . b64encode ( fin . read ()). decode ( "utf-8" )
images = [{ 'type' : "base64" , "data" : b64 }]
data = {
"inputs" : "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions. USER: <image> n Please explain the picture. ASSISTANT:" ,
"parameters" : {
"max_new_tokens" : 200 ,
},
"multimodal_params" : {
"images" : images ,
}
}
response = requests . post ( url , headers = headers , data = json . dumps ( data ))
if response . status_code == 200 :
print ( response . json ())
else :
print ( 'Error:' , response . status_code , response . text )Parameter lanuch tambahan:
--enable_multimodal,--cache_capacity, lebih besar--cache_capacitymemerlukanshm-sizeyang lebih besar
Dukungan
--tp > 1, ketikatp > 1, model visual dijalankan pada GPU 0
Tag gambar khusus untuk Qwen-VL adalah
<img></img>(<image>untuk Llava), panjangdata["multimodal_params"]["images"]harus sama dengan jumlah tag, Jumlahnya bisa 0, 1, 2, ...
Masukkan format gambar: daftar untuk dict seperti
{'type': 'url'/'base64', 'data': xxx}
Kami membandingkan kinerja layanan LightLLM dan vLLM==0.1.2 pada LLaMA-7B menggunakan A800 dengan memori GPU 80G.
Untuk memulai, siapkan data sebagai berikut:
wget https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.jsonLuncurkan layanan:
python -m lightllm.server.api_server --model_dir /path/llama-7b --tp 1 --max_total_token_num 121060 --tokenizer_mode autoEvaluasi:
cd test
python benchmark_serving.py --tokenizer /path/llama-7b --dataset /path/ShareGPT_V3_unfiltered_cleaned_split.json --num-prompts 2000 --request-rate 200Hasil perbandingan kinerja disajikan di bawah ini:
| vLLM | CahayaLLM |
|---|---|
| Total waktu: 361,79 detik Throughput: 5,53 permintaan/dtk | Total waktu: 188,85 detik Throughput: 10,59 permintaan/dtk |
Untuk debugging, kami menawarkan skrip pengujian kinerja statis untuk berbagai model. Misalnya, Anda dapat mengevaluasi performa inferensi model LLaMA dengan
cd test/model
python test_llama.pypip install protobuf==3.20.0 .error : PTX .version 7.4 does not support .target sm_89bash tools/resolve_ptx_version python -m lightllm.server.api_server ... Jika Anda memiliki proyek yang harus digabungkan, silakan hubungi melalui email atau buat permintaan tarik.
Setelah Anda menginstal lightllm dan lazyllm , lalu Anda dapat menggunakan kode berikut untuk membuat chatbot Anda sendiri:
from lazyllm import TrainableModule , deploy , WebModule
# Model will be download automatically if you have an internet connection
m = TrainableModule ( 'internlm2-chat-7b' ). deploy_method ( deploy . lightllm )
WebModule ( m ). start (). wait ()Dokumen: https://lazyllm.readthedocs.io/
Untuk informasi dan diskusi lebih lanjut, bergabunglah dengan server perselisihan kami.
Repositori ini dirilis di bawah lisensi Apache-2.0.
Kami belajar banyak dari proyek berikut ketika mengembangkan LightLLM.


