RWKV LM
v5
Beranda RWKV: https://www.rwkv.com
Makalah RWKV-5/6 Elang/Finch : https://arxiv.org/abs/2404.05892
RWKV yang Luar Biasa dalam Vision: https://github.com/Yaziwel/Awesome-RWKV-in-Vision
Demo RWKV-6 3B: https://huggingface.co/spaces/BlinkDL/RWKV-Gradio-1
Demo RWKV-6 7B: https://huggingface.co/spaces/BlinkDL/RWKV-Gradio-2
Kode demo mode GPT RWKV-6 (dengan komentar dan penjelasan) : https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/rwkv_v6_demo.py
Demo mode RNN RWKV-6: https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
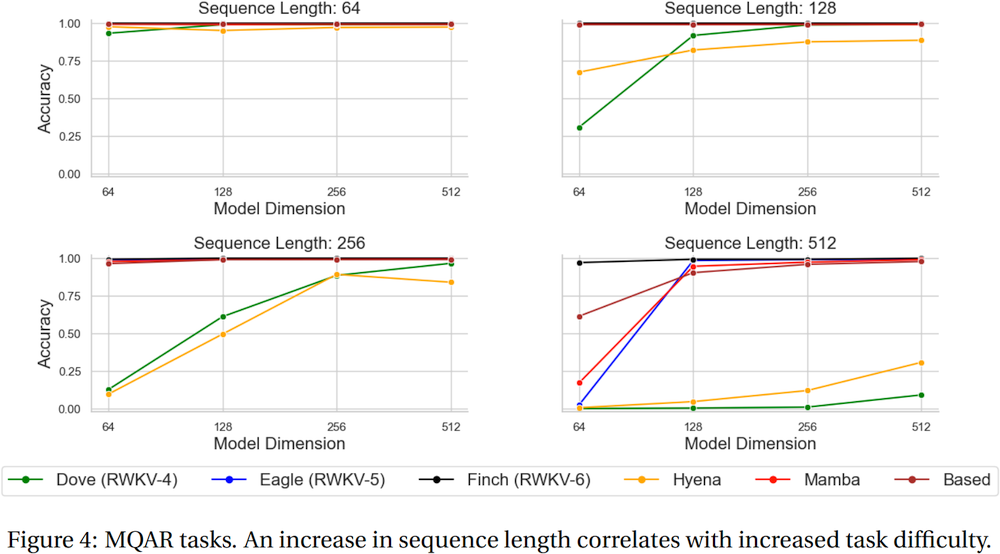
Sebagai referensi, gunakan python 3.10+, torch 2.5+, cuda 12.5+, deepspeed terbaru, tetapi pertahankan pytorch-lightning==1.9.5
Latih RWKV-6 : gunakan /RWKV-v5/ dan gunakan --my_testing "x060" di demo-training-prepare.sh dan demo-training-run.sh
Latih RWKV-7 : gunakan /RWKV-v5/ dan gunakan --my_testing "x070" di demo-training-prepare.sh dan demo-training-run.sh
pip install torch --upgrade --extra-index-url https://download.pytorch.org/whl/cu121
pip install pytorch-lightning==1.9.5 deepspeed wandb ninja --upgrade
cd RWKV-v5/
./demo-training-prepare.sh
./demo-training-run.sh
(you may want to log in to wandb first)
Kurva kerugian Anda akan terlihat hampir sama persis seperti ini, dengan naik dan turun yang sama (jika Anda menggunakan bsz & config yang sama):
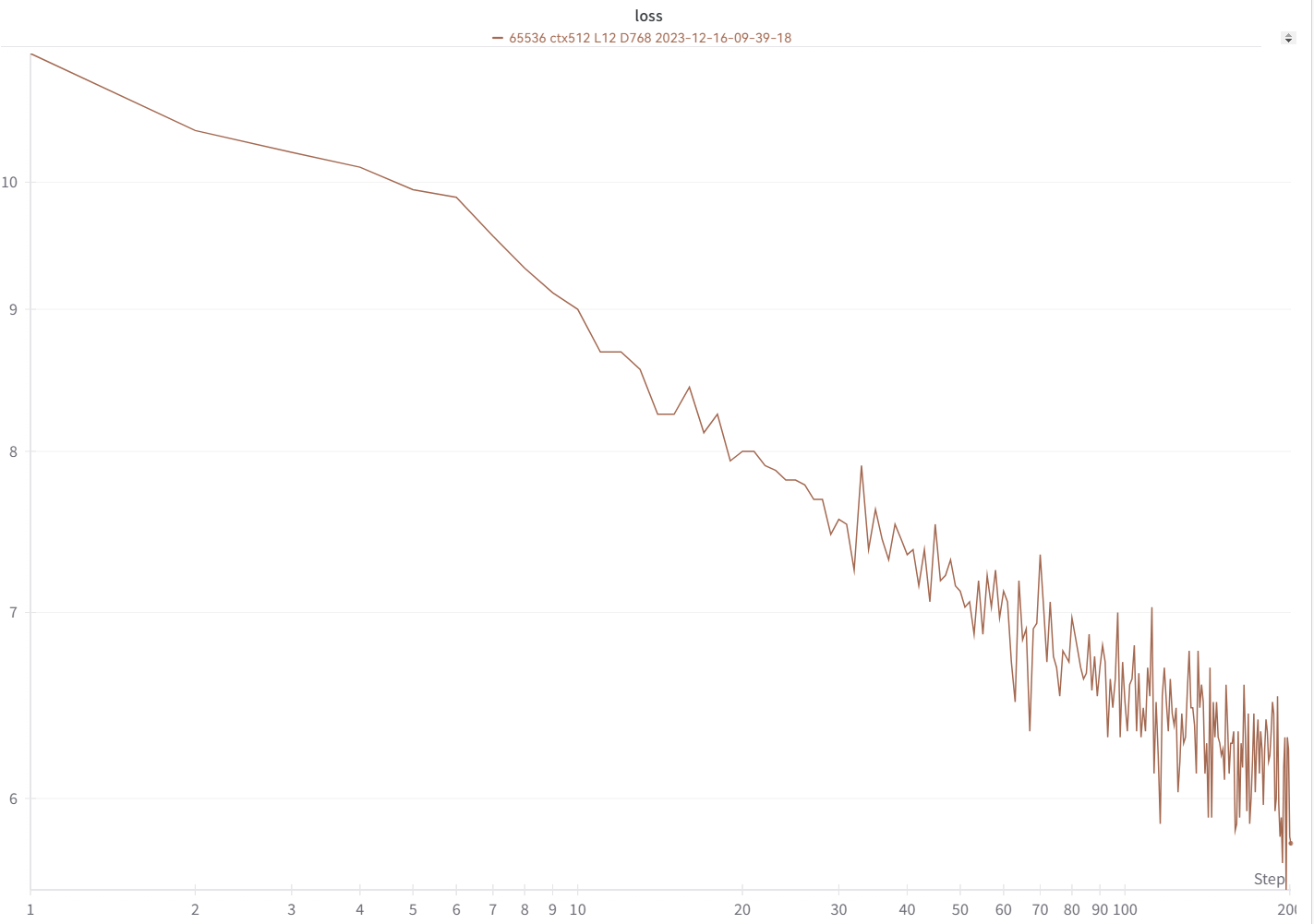
Anda dapat menjalankan model Anda menggunakan https://pypi.org/project/rwkv/ (gunakan "rwkv_vocab_v20230424" alih-alih "20B_tokenizer.json")
Gunakan https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/make_data.py untuk menyiapkan data binidx dari jsonl, dan hitung "--my_exit_tokens" dan "--magic_prime".
Tokenizer data besar yang jauh lebih cepat: https://github.com/cahya-wirawan/json2bin
"Epoch" di train.py adalah "mini-epoch" (bukan epoch sebenarnya. hanya untuk kenyamanan), dan 1 mini-epoch = 40320 * ctx_len token.
Misalnya, jika binidx Anda memiliki 1498226207 token dan ctxlen=4096, setel "--my_exit_tokens 1498226207" (ini akan menggantikan epoch_count), dan hasilnya akan menjadi 1498226207/(40320 * 4096) = 9,07 miniepoch. Pelatih akan keluar secara otomatis setelah token "--my_exit_tokens". Tetapkan "--magic_prime" ke bilangan prima 3n+2 terbesar yang lebih kecil dari datalen/ctxlen-1 (= 1498226207/4096-1 = 365776), yaitu "--magic_prime 365759" dalam kasus ini.
sederhana: siapkan SFT jsonl => ulangi data SFT Anda 3 atau 4 kali di make_data.py. lebih banyak pengulangan menyebabkan overfitting.
lanjutan: ulangi data SFT Anda 3 atau 4 kali di jsonl Anda (catatan make_data.py akan mengacak semua item jsonl) => tambahkan beberapa data dasar (seperti slimpajama) ke jsonl Anda => dan hanya ulangi 1 kali di make_data.py.
Memperbaiki paku latihan : lihat bagian "Memperbaiki Paku RWKV-6" di halaman ini.
Inferensi sederhana untuk RWKV-5 : https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v5_demo.py
Inferensi sederhana untuk RWKV-6 : https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
Catatan: Di [state = kv + w * state] semuanya harus di fp32 karena w bisa sangat dekat dengan 1. Jadi kita bisa menyimpan state dan w di fp32, dan mengonversi kv ke fp32.
lm_eval: https://github.com/BlinkDL/ChatRWKV/blob/main/run_lm_eval.py
demo obrolan untuk pengembang: https://github.com/BlinkDL/ChatRWKV/blob/main/API_DEMO_CHAT.py
Tips untuk model kecil / data kecil : Saat saya melatih model musik RWKV, saya menggunakan dimensi yang dalam & sempit (seperti L29-D512), dan menerapkan wd dan dropout (seperti wd=2 dropout=0.02). Catatan Dropout RWKV-LM sangat efektif - gunakan 1/4 dari nilai biasanya.
Gunakan format .jsonl untuk data Anda (lihat https://huggingface.co/BlinkDL/rwkv-5-world untuk formatnya).
Gunakan https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/make_data.py untuk membuat tokenizer menggunakan tokenizer Dunia ke binidx, cocok untuk menyempurnakan model Dunia.
Ganti nama pos pemeriksaan dasar di folder model Anda menjadi rwkv-init.pth, dan ubah perintah pelatihan untuk menggunakan --n_layer 32 --n_embd 4096 --vocab_size 65536 --lr_init 1e-5 --lr_final 1e-5 untuk 7B.
0,1B = --n_layer 12 --n_embd 768 // 0,4B = --n_layer 24 --n_embd 1024 // 1,5B = --n_layer 24 --n_embd 2048 // 3B = --n_layer 32 --n_embd 2560 / / 7B = --n_lapisan 32 --n_embd 4096
Implementasi yang saat ini belum dioptimalkan, memerlukan vram yang sama dengan SFT penuh
--train_type "states" --load_partial 1 --lr_init 1 --lr_final 0.01 --warmup_steps 10 (yes, use very high LR)
gunakan rwkv 0.8.26+ untuk memuat otomatis "time_state" yang dilatih
Saat Anda melatih RWKV dari awal, coba inisialisasi saya untuk performa terbaik. Periksa generate_init_weight() dari src/model.py:
emb.weight => nn.init.uniform_(a=-1e-4, b=1e-4)
(Note ln0 of block0 is the layernorm for emb.weight)
head.weight => nn.init.orthogonal_(gain=0.5*sqrt(n_vocab / n_embd))
att.receptance.weight => nn.init.orthogonal_(gain=1)
att.key.weight => nn.init.orthogonal_(gain=0.1)
att.value.weight => nn.init.orthogonal_(gain=1)
att.gate.weight => nn.init.orthogonal_(gain=0.1)
att.output.weight => zero
att.ln_x.weight (groupnorm) => ((1 + layer_id) / total_layers) ** 0.7
ffn.key.weight => nn.init.orthogonal_(gain=1)
ffn.value.weight => zero
ffn.receptance.weight => zero
!!! Jika Anda menggunakan penyematan posisi, mungkin lebih baik menghapus block.0.ln0 dan menggunakan inisialisasi default untuk emb.weight daripada seragam saya_(a=-1e-4, b=1e-4) !!!
saat berlatih dari awal, tambahkan "k = k * torch.clamp(w, max=0).exp()" sebelum "RUN_CUDA_RWKV6(r, k, v, w, u)", dan ingatlah untuk mengubah kode inferensi Anda juga . Anda akan melihat konvergensi yang lebih cepat.
gunakan "--adam_eps 1e-18"
"--beta2 0.95" jika Anda melihat lonjakan
di trainer.py lakukan "lr = lr * (0.01 + 0.99 * trainer.global_step / w_step)" (awalnya 0.2 + 0.8), dan "--warmup_steps 20"
"--weight_decay 0.1" menghasilkan kerugian akhir yang lebih baik jika Anda melatih banyak data. setel lr_final ke 1/100 dari lr_init saat melakukan ini.
RWKV adalah RNN dengan kinerja LLM tingkat Transformer, yang juga dapat dilatih langsung seperti transformator GPT (dapat diparalelkan). Dan itu 100% bebas perhatian. Anda hanya memerlukan status tersembunyi di posisi t untuk menghitung status di posisi t+1. Anda dapat menggunakan mode "GPT" untuk menghitung status tersembunyi dengan cepat untuk mode "RNN".
Jadi ini menggabungkan yang terbaik dari RNN dan transformator - kinerja luar biasa, inferensi cepat, menghemat VRAM, pelatihan cepat, ctx_len "tak terbatas", dan penyematan kalimat gratis (menggunakan status tersembunyi terakhir).
GUI Pelari RWKV https://github.com/josStorer/RWKV-Runner dengan instalasi sekali klik dan API
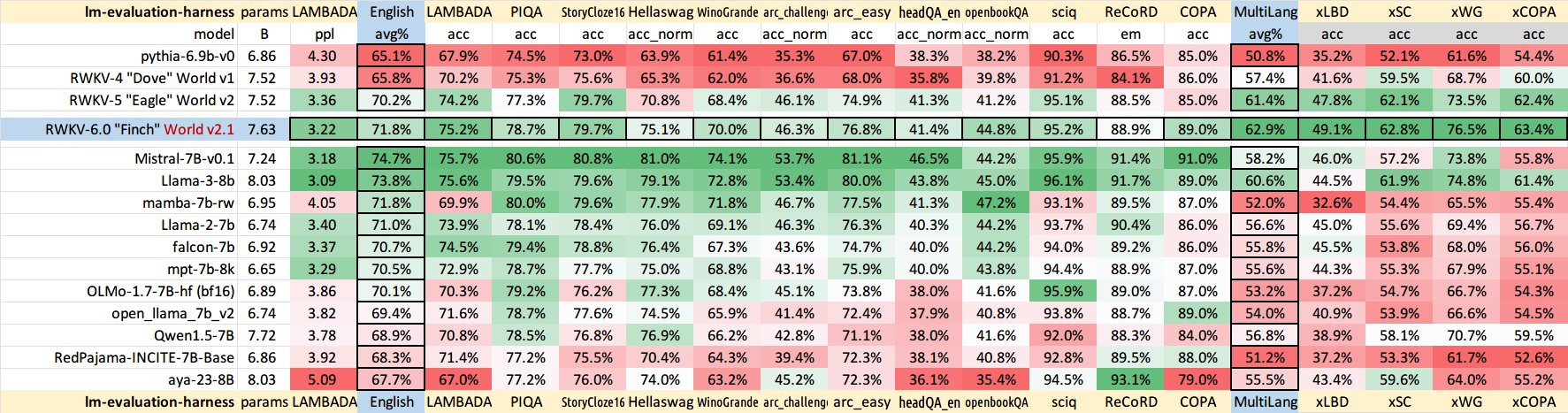
Semua bobot RWKV terbaru: https://huggingface.co/BlinkDL
Anak timbangan RWKV yang kompatibel dengan HF: https://huggingface.co/RWKV
Paket pip RWKV : https://pypi.org/project/rwkv/
os . environ [ "RWKV_JIT_ON" ] = '1'
os . environ [ "RWKV_CUDA_ON" ] = '0' # if '1' then use CUDA kernel for seq mode (much faster)
from rwkv . model import RWKV # pip install rwkv
model = RWKV ( model = '/fsx/BlinkDL/HF-MODEL/rwkv-4-pile-1b5/RWKV-4-Pile-1B5-20220903-8040' , strategy = 'cuda fp16' )
out , state = model . forward ([ 187 , 510 , 1563 , 310 , 247 ], None ) # use 20B_tokenizer.json
print ( out . detach (). cpu (). numpy ()) # get logits
out , state = model . forward ([ 187 , 510 ], None )
out , state = model . forward ([ 1563 ], state ) # RNN has state (use deepcopy if you want to clone it)
out , state = model . forward ([ 310 , 247 ], state )
print ( out . detach (). cpu (). numpy ()) # same result as abovenanoRWKV : https://github.com/BlinkDL/nanoRWKV (tidak memerlukan kernel CUDA khusus untuk dilatih, berfungsi untuk GPU/CPU apa pun)
Twitter : https://twitter.com/BlinkDL_AI
Beranda : https://www.rwkv.com
Proyek RWKV Komunitas Keren :
Semua (300+) proyek RWKV: https://github.com/search?o=desc&q=rwkv&s=updated&type=Repositories
https://github.com/OpenGVLab/Vision-RWKV Visi RWKV
https://github.com/feizc/Diffusion-RWKV Difusi RWKV
https://github.com/cgisky1980/ai00_rwkv_server Inferensi WebGPU Tercepat (nVidia/AMD/Intel)
https://github.com/cryscan/web-rwkv backend untuk ai00_rwkv_server
https://github.com/saharNooby/rwkv.cpp CPU cepat/cuBLAS/CLBlast inferensi: int4/int8/fp16/fp32
https://github.com/JL-er/RWKV-PEFT lora/pissa/Qlora/Qpissa/state tuning
https://github.com/RWKV/RWKV-infctx-trainer Pelatih Infctx
https://github.com/daquexian/faster-rwkv
mlc-ai/mlc-llm#1275
https://github.com/TheRamU/Fay/blob/main/README_EN.md Asisten Digital dengan RWKV
https://github.com/harrisonvanderbyl/rwkv-cpp-cuda Inferensi GPU cepat dengan cuda/amd/vulkan
RWKV v6 dalam 250 baris (dengan tokenizer juga): https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
RWKV v5 dalam 250 baris (dengan tokenizer juga): https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v5_demo.py
RWKV v4 dalam 150 baris (model, inferensi, pembuatan teks): https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_in_150_lines.py
Pracetak RWKV v4 https://arxiv.org/abs/2305.13048
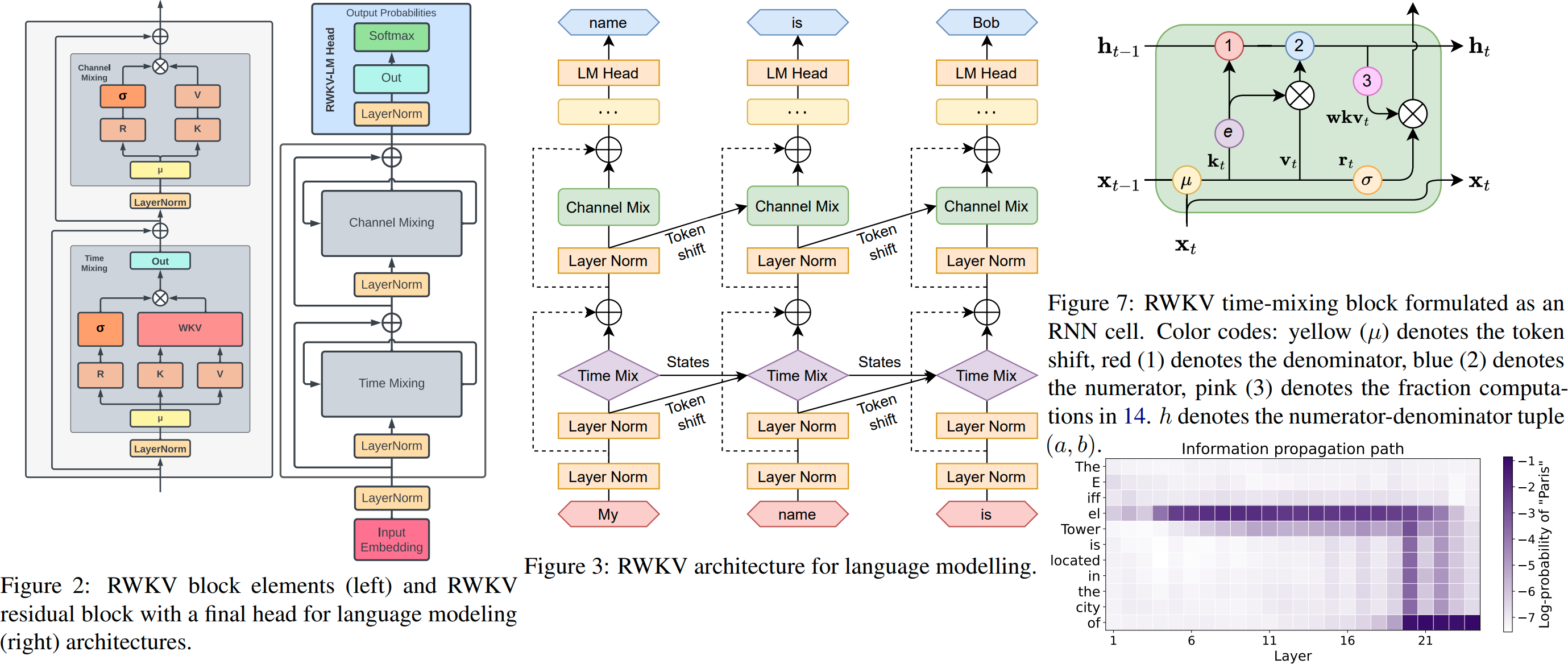
Pengenalan RWKV v4, dan dalam 100 baris numpy : https://johanwind.github.io/2023/03/23/rwkv_overview.html https://johanwind.github.io/2023/03/23/rwkv_details.html
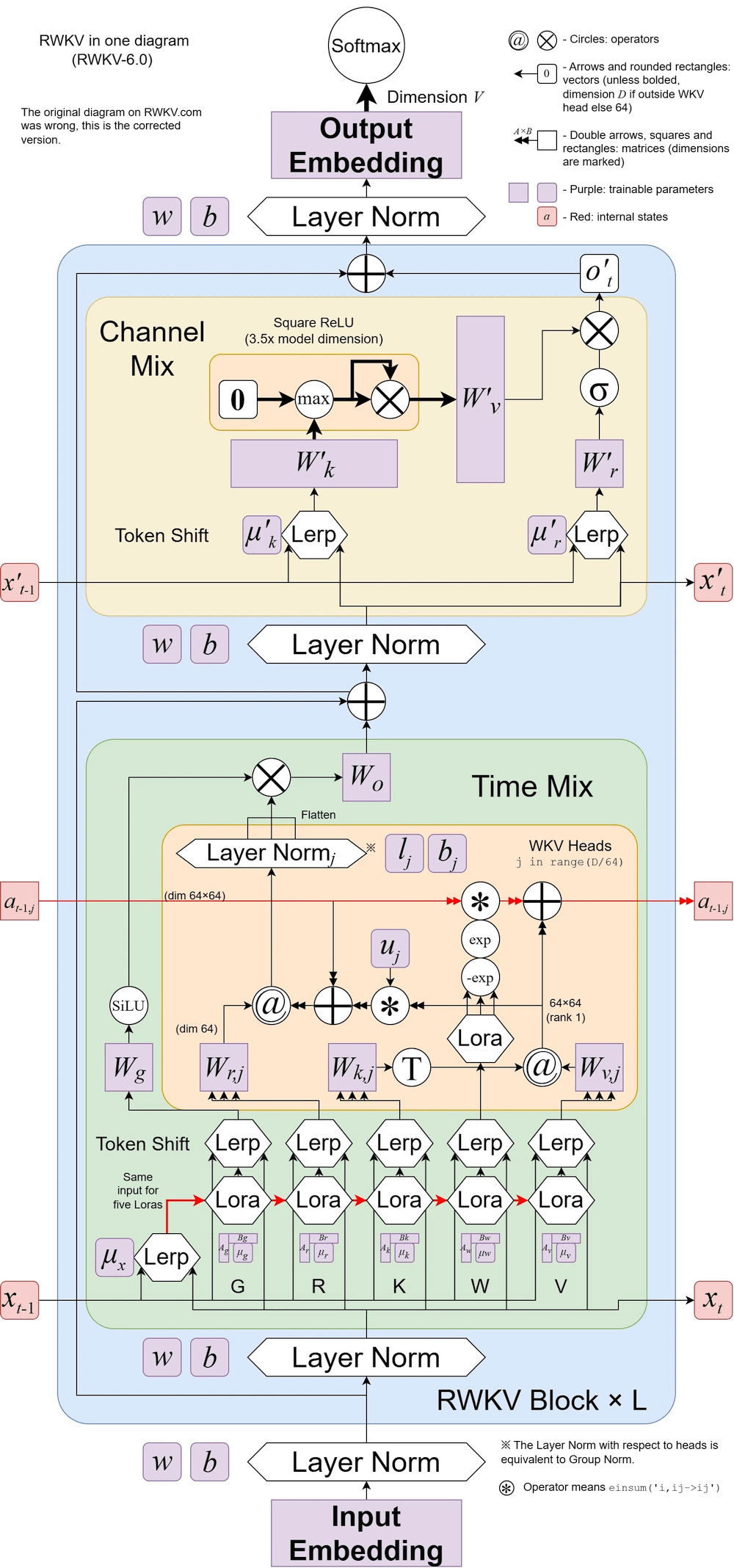
Ilustrasi RWKV v6:
Makalah keren (Spiking Neural Network) menggunakan RWKV: https://github.com/ridgerchu/SpikeGPT
Anda dipersilakan untuk bergabung dengan perselisihan RWKV https://discord.gg/bDSBUMeFpc untuk mengembangkannya. Kami memiliki banyak potensi komputasi (A100 40G) sekarang (berkat Stabilitas dan EleutherAI), jadi jika Anda memiliki ide menarik saya dapat menjalankannya.

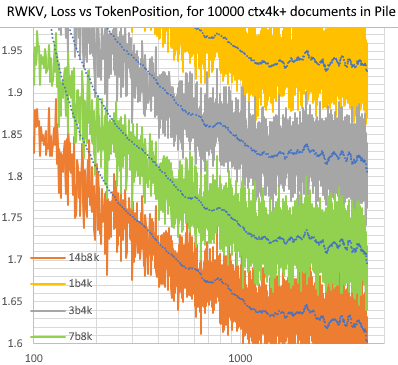
RWKV [kerugian vs posisi token] untuk 10.000 dokumen ctx4k+ di Pile. RWKV 1B5-4k sebagian besar datar setelah ctx1500, tetapi 3B-4k dan 7B-4k dan 14B-4k memiliki beberapa kemiringan, dan menjadi lebih baik. Ini membantah pandangan lama bahwa RNN tidak dapat memodelkan lensa ctx yang panjang. Kami dapat memperkirakan bahwa RWKV 100B akan bagus, dan RWKV 1T mungkin adalah semua yang Anda butuhkan :)
ObrolanRWKV dengan RWKV 14B ctx8192:

Saya yakin RNN adalah kandidat yang lebih baik untuk model fundamental, karena: (1) Lebih ramah untuk ASIC (tidak ada cache kv). (2) Lebih ramah untuk RL. (3) Saat kita menulis, otak kita lebih mirip dengan RNN. (4) Alam semesta juga seperti RNN (karena lokalitas). Transformer adalah model non-lokal.
RWKV-3 1,5B di A40 (tf32) = selalu 0,015 detik/token, diuji menggunakan kode pytorch sederhana (tanpa CUDA), pemanfaatan GPU 45%, VRAM 7823M
GPT2-XL 1.3B di A40 (tf32) = 0,032 detik/token (untuk ctxlen 1000), diuji menggunakan HF, pemanfaatan GPU juga 45% (menarik), VRAM 9655M
Kecepatan pelatihan: (kode pelatihan baru) RWKV-4 14B BF16 ctxlen4096 = 114K token/dtk pada 8x8 A100 80G (ZERO2+CP). (kode pelatihan lama) RWKV-4 1.5B BF16 ctxlen1024 = 106 ribu token/dtk pada 8xA100 40G.
Saya juga melakukan eksperimen gambar (Misalnya: https://huggingface.co/BlinkDL/clip-guided-binary-autoencoder) dan RWKV akan dapat melakukan difusi txt2img :) Ide saya: gambar rgb 256x256 -> laten 32x32x13bit - > terapkan RWKV untuk menghitung probabilitas transisi untuk masing-masing grid 32x32 -> anggaplah grid tersebut independen dan "menyebar" menggunakan probabilitas ini.
Pelatihan lancar - tidak ada lonjakan kerugian! (lr & bsz ubah sekitar 15G token) 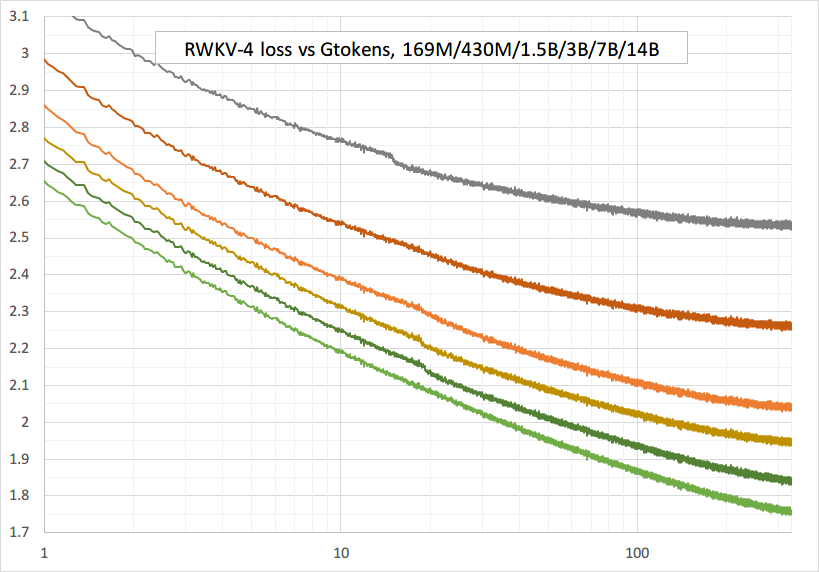
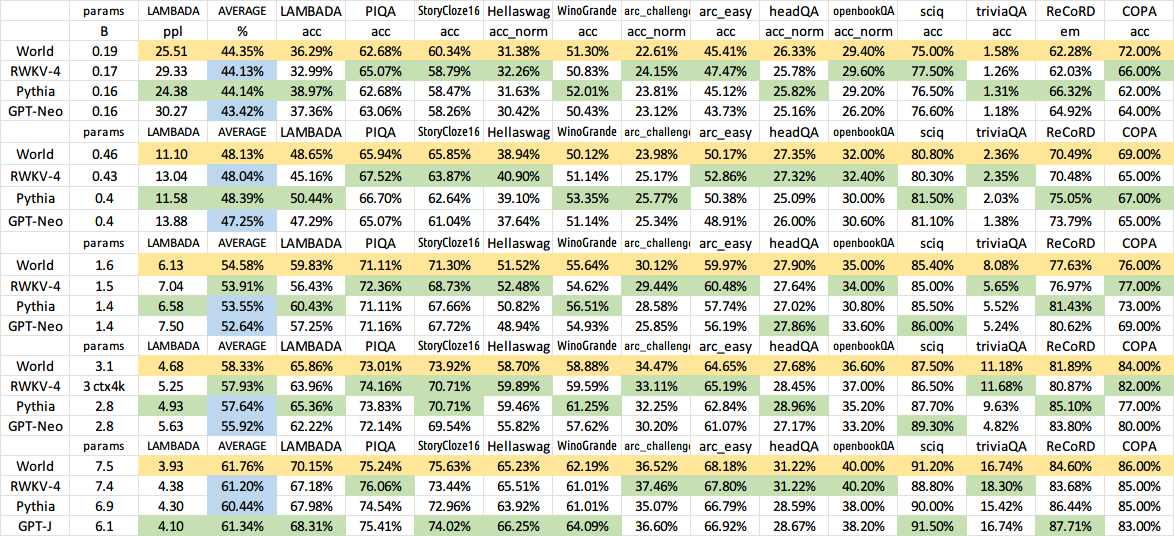
Semua model yang dilatih akan bersifat open-source. Inferensi sangat cepat (hanya perkalian matriks-vektor, tidak ada perkalian matriks-matriks) bahkan pada CPU, sehingga Anda bahkan dapat menjalankan LLM di ponsel Anda.
Cara kerjanya: RWKV mengumpulkan informasi ke sejumlah saluran, yang juga membusuk dengan kecepatan berbeda saat Anda berpindah ke token berikutnya. Ini sangat sederhana setelah Anda memahaminya.
RWKV dapat diparalelkan karena peluruhan waktu setiap saluran tidak bergantung pada data (dan dapat dilatih) . Misalnya, di RNN biasa Anda dapat menyesuaikan peluruhan waktu saluran dari 0,8 hingga 0,5 (ini disebut "gerbang"), sedangkan di RWKV Anda cukup memindahkan informasi dari saluran W-0,8 ke saluran W-0,5 -saluran untuk mencapai efek yang sama. Selain itu, Anda dapat menyempurnakan RWKV menjadi RNN yang tidak dapat diparalelkan (kemudian Anda dapat menggunakan keluaran dari lapisan selanjutnya dari token sebelumnya) jika Anda menginginkan performa ekstra.

Berikut adalah beberapa TODO saya. Mari kita bekerja sama :)
Integrasi HuggingFace (periksa huggingface/transformers#17230 ), dan inferensi CPU & iOS & Android & WASM & WebGL yang dioptimalkan. RWKV adalah RNN dan sangat ramah untuk perangkat edge. Mari kita memungkinkan untuk menjalankan LLM di ponsel Anda.
Uji pada tugas dua arah & MLM, serta token gambar & audio & video. Saya pikir RWKV dapat mendukung Encoder-Decoder melalui ini: untuk setiap token decoder, gunakan campuran yang dipelajari dari [keadaan tersembunyi decoder sebelumnya] & [keadaan tersembunyi akhir encoder]. Oleh karena itu, semua token decoder akan memiliki akses ke output encoder.
Sekarang latih RWKV-4a dengan satu perhatian ekstra kecil (hanya beberapa baris tambahan dibandingkan dengan RWKV-4) untuk lebih meningkatkan beberapa tugas zeroshot yang sulit (seperti LAMBADA) untuk model yang lebih kecil. Lihat https://github.com/BlinkDL/RWKV-LM/commit/a268cd2e40351ee31c30c5f8a5d1266d35b41829
Umpan balik pengguna:
Sejauh ini saya telah bermain-main dengan model berbasis karakter pada kumpulan data pra-pelatihan kami yang relatif kecil (sekitar 10 GB teks), dan hasilnya sangat bagus - mirip dengan model yang membutuhkan waktu lebih lama untuk dilatih.
ya Tuhan rwkv cepat. Saya beralih ke tab lain setelah mulai melatihnya dari awal & ketika saya kembali, tab itu mengeluarkan kata-kata bahasa Inggris & maori yang masuk akal, saya pergi ke microwave untuk minum kopi & ketika saya kembali, tab itu menghasilkan kalimat yang sepenuhnya benar secara tata bahasa.
Tweet dari Sepp Hochreiter (terima kasih!): https://twitter.com/HochreiterSepp/status/1524270961314484227
Anda juga dapat menemukan saya (BlinkDL) di EleutherAI Discord: https://www.eleuther.ai/get-involved/
PENTING: Gunakan deepspeed==0.7.0 pytorch-lightning==1.9.5 torch==1.13.1+cu117 dan cuda 11.7.1 atau 11.7 (catatan torch2 + deepspeed memiliki bug aneh dan mengganggu performa model)
Gunakan https://github.com/BlinkDL/RWKV-LM/tree/main/RWKV-v4neo (kode terbaru, kompatibel dengan v4).
Berikut adalah petunjuk bagus untuk menguji Tanya Jawab LLM. Berfungsi untuk model apa pun: (ditemukan dengan meminimalkan ppl ChatGPT untuk RWKV 1.5B)
prompt = f' n Q & A n n Question: n { qq } n n Detailed Expert Answer: n ' # let the model generate after thisJalankan model Pile RWKV-4: Unduh model dari https://huggingface.co/BlinkDL. Setel TOKEN_MODE = 'pile' di run.py dan jalankan. Ini cepat bahkan pada CPU (mode default).
Colab untuk RWKV-4 Pile 1.5B : https://colab.research.google.com/drive/1F7tZoPZaWJf1fsCmZ5tjw6sYHiFOYVWM
Jalankan model Pile RWKV-4 di browser Anda (dan versi onnx): lihat masalah #7 ini
Demo Web RWKV-4: https://josephrocca.github.io/rwkv-v4-web/demo/ (catatan: hanya pengambilan sampel serakah untuk saat ini)
Untuk RWKV-2 lama: lihat rilis di sini untuk model params 27 juta di enwik8 dengan 0,72 BPC(dev). Jalankan run.py di https://github.com/BlinkDL/RWKV-LM/tree/main/RWKV-v2-RNN. Anda bahkan dapat menjalankannya di browser Anda: https://github.com/BlinkDL/AI-Writer/tree/main/docs/eng https://blinkdl.github.io/AI-Writer/eng/ (ini menggunakan tf.js WASM mode utas tunggal).
pip install deepspeed==0.7.0 // pip install pytorch-lightning==1.9.5 // torch 1.13.1+cu117
CATATAN: tambahkan peluruhan bobot (0,1 atau 0,01) dan dropout (0,1 atau 0,01) saat melatih pada jumlah data yang kecil. coba x=x+dropout(att(x)) x=x+dropout(ffn(x)) x=dropout(x+att(x)) x=dropout(x+ffn(x)) dll.
Melatih RWKV-4 dari awal: jalankan train.py, yang secara default menggunakan dataset enwik8 (unzip https://data.deepai.org/enwik8.zip).
Anda akan melatih versi "GPT" karena versi ini dapat diparalelkan dan lebih cepat untuk dilatih. RWKV-4 dapat melakukan ekstrapolasi, sehingga pelatihan dengan ctxLen 1024 dapat bekerja untuk ctxLen 2500+. Anda dapat menyempurnakan model dengan ctxLen yang lebih panjang dan model tersebut dapat dengan cepat beradaptasi dengan ctxLens yang lebih panjang.
Menyempurnakan model Tumpukan RWKV-4: gunakan 'prepare-data.py' di https://github.com/BlinkDL/RWKV-v2-RNN-Pile/tree/main/RWKV-v3 untuk memasukkan .txt ke dalam kereta. data npy. Kemudian gunakan https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v4neo/train.py untuk melatihnya.
Baca kode inferensi di src/model.py dan coba gunakan status tersembunyi terakhir(.xx .aa .bb) sebagai penyematan kalimat yang tepat untuk tugas lainnya. Mungkin Anda harus memulai dengan .xx dan .aa/.bb (.aa dibagi .bb).
Colab untuk menyempurnakan model Tumpukan RWKV-4: https://colab.research.google.com/github/resloved/RWKV-notebooks/blob/master/RWKV_v4_RNN_Pile_Fine_Tuning.ipynb
Korpus besar: Gunakan https://github.com/Abel2076/json2binidx_tool untuk mengonversi .jsonl menjadi .bin dan .idx
Contoh format jsonl (satu baris untuk setiap dokumen):
{"text": "This is the first document."}
{"text": "HellonWorld"}
{"text": "1+1=2n1+2=3n2+2=4"}
dihasilkan oleh kode seperti ini:
ss = json.dumps({"text": text}, ensure_ascii=False)
out.write(ss + "n")
Pelatihan ctxlen tak terbatas (WIP): https://github.com/Blealtan/RWKV-LM-LoRA/tree/dev-infctx
Pertimbangkan RWKV 14B. Negara bagian memiliki 200 vektor, yaitu 5 vektor untuk setiap blok: fp16 (xx), fp32 (aa), fp32 (bb), fp32 (pp), fp16 (xx).
Jangan rata-rata pool karena vektor yang berbeda (xx aa bb pp xx) di negara bagian memiliki arti dan rentang yang sangat berbeda. Anda mungkin dapat menghapus pp.
Saya sarankan terlebih dahulu mengumpulkan statistik mean+stdev dari setiap saluran dari setiap vektor, dan menormalkan semuanya (catatan: normalisasi harus independen terhadap data dan dikumpulkan dari berbagai teks). Kemudian latih pengklasifikasi linier.
RWKV-5 bersifat multi-head dan di sini menunjukkan satu kepala. Ada juga LayerNorm untuk setiap kepala (karenanya sebenarnya GroupNorm).
Campuran Dinamis & Peluruhan Dinamis. Contoh (lakukan ini untuk TimeMix & ChannelMix):
TIME_MIX_EXTRA_DIM = 32
self.time_mix_k_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_k_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
self.time_mix_v_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_v_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
self.time_mix_r_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_r_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
self.time_mix_g_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_g_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
...
time_mix_k = self.time_mix_k.view(1,1,-1) + (x @ self.time_mix_k_w1) @ self.time_mix_k_w2
time_mix_v = self.time_mix_v.view(1,1,-1) + (x @ self.time_mix_v_w1) @ self.time_mix_v_w2
time_mix_r = self.time_mix_r.view(1,1,-1) + (x @ self.time_mix_r_w1) @ self.time_mix_r_w2
time_mix_g = self.time_mix_g.view(1,1,-1) + (x @ self.time_mix_g_w1) @ self.time_mix_g_w2
xx = self.time_shift(x)
xk = x * time_mix_k + xx * (1 - time_mix_k)
xv = x * time_mix_v + xx * (1 - time_mix_v)
xr = x * time_mix_r + xx * (1 - time_mix_r)
xg = x * time_mix_g + xx * (1 - time_mix_g)

Gunakan mode paralel untuk menghasilkan status dengan cepat, lalu gunakan RNN lengkap yang telah disempurnakan (lapisan token n dapat menggunakan keluaran semua lapisan token n-1) untuk pembuatan berurutan.
Sekarang peluruhan waktu seperti 0,999^T (0,999 dapat dipelajari). Ubah ke sesuatu seperti (0.999^T + 0.1) di mana 0.1 juga bisa dipelajari. Bagian 0,1 akan disimpan selamanya. Atau, A^T + B^T + C = peluruhan cepat + peluruhan lambat + konstanta. Bahkan dapat menggunakan rumus yang berbeda (misalnya, K^2 dan bukan e^K untuk komponen peluruhan, atau, tanpa normalisasi).
Gunakan peluruhan bernilai kompleks (jadi, rotasi, bukan peluruhan) di beberapa saluran.
Menyuntikkan beberapa pengkodean posisi yang dapat dilatih dan diekstrapolasi?
Selain rotasi 2d, kita dapat mencoba grup Lie lainnya seperti rotasi 3d ( SO(3) ). RWKV non-abelian haha.
RWKV mungkin bagus untuk perangkat analog (cari perkalian vektor Matriks Analog & perkalian vektor Matriks Fotonik). Mode RNN sangat ramah perangkat keras (pemrosesan dalam memori). Bisa jadi SNN juga (https://github.com/ridgerchu/SpikeGPT). Saya ingin tahu apakah ini dapat dioptimalkan untuk komputasi kuantum.
Status tersembunyi awal yang dapat dilatih (xx aa bb pp xx).
LR berlapis-lapis (atau bahkan berdasarkan baris/kolom, berdasarkan elemen), dan menguji pengoptimal Lion.
self.pos_emb_x = nn.Parameter(torch.zeros((1,args.my_pos_emb,args.n_embd)))
self.pos_emb_y = nn.Parameter(torch.zeros((args.my_pos_emb,1,args.n_embd)))
...
x = x + pos_emb_x + pos_emb_y
Mungkin kita bisa meningkatkan hafalan hanya dengan mengulang konteksnya (saya kira 2 kali saja sudah cukup). Contoh: Referensi -> Referensi(lagi) -> Pertanyaan -> Jawaban
Idenya adalah untuk memastikan setiap token dalam vocab memahami panjang dan byte UTF-8 mentahnya.
Misalkan a = max(len(token)) untuk semua token dalam vocab. Definisikan AA : float[a][d_emb]
Misalkan b = max(len_in_utf8_bytes(token)) untuk semua token dalam vocab. Tentukan BB : float[b][256][d_emb]
Untuk setiap token X dalam vocab, misalkan [x0, x1, ..., xn] menjadi byte UTF-8 mentahnya. Kami akan menambahkan beberapa nilai tambahan pada penyematannya EMB(X):
EMB(X) += AA[len(X)] + BB[0][x0] + BB[1][x1] + ... + BB[n][xn] (catatan: AA BB adalah bobot yang dapat dipelajari)
Saya punya ide untuk meningkatkan tokenisasi. Kami dapat melakukan hardcode pada beberapa saluran agar memiliki makna. Contoh:
Saluran 0 = "ruang"
Saluran 1 = "huruf pertama menggunakan huruf kapital"
Saluran 2 = "huruf kapital semua"
Karena itu:
Penyematan "abc": [0, 0, 0, x0, x1, x2 , ..]
Penyematan " abc": [1, 0, 0, x0, x1, x2, ..]
Penyematan " Abc": [1, 1, 0, x0, x1, x2, ..]
Penyematan "ABC": [0, 0, 1, x0, x1, x2, ...]
......
jadi mereka akan berbagi sebagian besar penyematannya. Dan kita dapat dengan cepat menghitung probabilitas keluaran semua variasi "abc".
Catatan: metode di atas mengasumsikan bahwa p(" xyz") / p("xyz") sama untuk semua "xyz", yang bisa saja salah.
Lebih baik: tentukan emb_space emb_capitalize_first emb_capitalize_all sebagai fungsi dari emb.
Mungkin yang Terbaik: biarkan 'abc' ' abc' dll. membagikan 90% terakhir dari embeddingsnya.
Saat ini, semua tokenizer kami menghabiskan terlalu banyak item untuk mewakili semua variasi 'abc' ' abc' ' Abc' dll. Selain itu, model tidak dapat menemukan bahwa ini sebenarnya serupa jika beberapa variasi ini jarang ada dalam kumpulan data. Metode di sini dapat memperbaikinya. Saya berencana untuk menguji ini di RWKV versi baru.
Contoh (Tanya Jawab satu putaran):
Hasilkan keadaan akhir semua dokumen wiki.
Untuk setiap pengguna Q, temukan dokumen wiki terbaik, dan gunakan keadaan akhirnya sebagai keadaan awal.
Latih model untuk secara langsung menghasilkan keadaan awal yang optimal bagi setiap pengguna Q.
Namun ini bisa menjadi sedikit lebih rumit untuk tanya jawab multi-putaran :)
RWKV terinspirasi oleh AFT Apple (https://arxiv.org/abs/2105.14103).
Apalagi menggunakan beberapa trik saya, seperti:
SmallInitEmb: https://github.com/BlinkDL/SmallInitEmb (berlaku untuk semua transformator) yang membantu kualitas penyematan, dan menstabilkan Post-LN (yang saya gunakan).
Pergeseran token: https://github.com/BlinkDL/RWKV-LM#token-shift-time-shift-mixing (berlaku untuk semua transformator), terutama berguna untuk model tingkat char.
Head-QK: https://github.com/BlinkDL/RWKV-LM#the-head-qk-trick-learning-to-copy-and-avoid-tokens (berlaku untuk semua trafo). Catatan: ini membantu, tapi saya menonaktifkannya di model Pile agar tetap 100% RNN.
Ekstra R-gate di FFN (berlaku untuk semua trafo). Saya juga menggunakan reluSquared dari Primer.
Inisialisasi yang lebih baik: Saya memasukkan sebagian besar matriks ke NOL (lihat RWKV_Init di https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v2-RNN/src/model.py).
Anda dapat mentransfer beberapa parameter dari model kecil ke model besar (catatan: Saya mengurutkan & menghaluskannya juga), untuk konvergensi yang lebih cepat dan lebih baik (lihat https://www.reddit.com/r/MachineLearning/comments/umq908/r_rwkvv2rnn_a_parallelizable_rnn_with /).
Kernel CUDA saya: https://github.com/BlinkDL/RWKV-CUDA untuk mempercepat pelatihan.

Faktor abcd bekerja sama untuk membangun kurva peluruhan waktu: [X, 1, W, W^2, W^3, ...].
Tuliskan rumus "token di pos 2" dan "token di pos 3" dan Anda akan mendapatkan gambarannya:
kv / k adalah mekanisme memori. Token dengan k tinggi dapat diingat dalam jangka waktu lama, jika W mendekati 1 dalam saluran.
Gerbang R penting untuk kinerja. k = info kekuatan token ini (untuk diteruskan ke token masa depan). r = apakah akan menerapkan info ke token ini.
Gunakan faktor TimeMix berbeda yang dapat dilatih untuk R/K/V di lapisan SA dan FF. Contoh:
xx = self . time_shift ( x )
xk = x * self . time_mix_k + xx * ( 1 - self . time_mix_k )
xv = x * self . time_mix_v + xx * ( 1 - self . time_mix_v )
xr = x * self . time_mix_r + xx * ( 1 - self . time_mix_r )Gunakan preLN daripada postLN (konvergensi lebih stabil & lebih cepat):
if self . layer_id == 0 :
x = self . ln0 ( x )
x = x + self . att ( self . ln1 ( x ))
x = x + self . ffn ( self . ln2 ( x ))Komponen dasar mode GPT RWKV-3 mirip dengan GPT preLN biasa.
Satu-satunya perbedaan adalah LN tambahan setelah penyematan. Perhatikan bahwa Anda dapat menyerap LN ini ke dalam penyematan setelah menyelesaikan pelatihan.
x = self . emb ( idx ) # input: idx = token indices
x = self . ln_emb ( x ) # extra LN after embedding
x = x + self . att_0 ( self . ln_att_0 ( x )) # preLN
x = x + self . ffn_0 ( self . ln_ffn_0 ( x ))
...
x = x + self . att_n ( self . ln_att_n ( x ))
x = x + self . ffn_n ( self . ln_ffn_n ( x ))
x = self . ln_head ( x ) # final LN before projection
x = self . head ( x ) # output: x = logitsPenting untuk menginisialisasi penyematan ke nilai kecil, seperti nn.init.uniform_(a=-1e-4, b=1e-4), untuk memanfaatkan trik saya https://github.com/BlinkDL/SmallInitEmb.
Untuk 1.5B RWKV-3, saya menggunakan pengoptimal Adam (no wd, no dropout) pada 8*A100 40G.
batchSz = 32 * 896, ctxLen = 896. Saya menggunakan tf32 jadi batchSz agak kecil.
Untuk token 15 miliar pertama, LR ditetapkan pada 3e-4, dan beta=(0.9, 0.99).
Kemudian saya menetapkan beta=(0.9, 0.999), dan melakukan peluruhan LR secara eksponensial, mencapai 1e-5 pada 332B token.
RWKV-3 tidak mendapat perhatian seperti biasanya, tapi kami akan tetap menyebut blok ini ATT.
B , T , C = x . size () # x = (Batch,Time,Channel)
# Mix x with the previous timestep to produce xk, xv, xr
xx = self . time_shift ( x ) # self.time_shift = nn.ZeroPad2d((0,0,1,-1))
xk = x * self . time_mix_k + xx * ( 1 - self . time_mix_k )
xv = x * self . time_mix_v + xx * ( 1 - self . time_mix_v )
xr = x * self . time_mix_r + xx * ( 1 - self . time_mix_r )
# Use xk, xv, xr to produce k, v, r
k = self . key ( xk ). transpose ( - 1 , - 2 )
v = self . value ( xv ). transpose ( - 1 , - 2 )
r = self . receptance ( xr )
k = torch . clamp ( k , max = 60 ) # clamp k to avoid overflow
k = torch . exp ( k )
kv = k * v
# Compute the W-curve = [e^(-n * e^time_decay), e^(-(n-1) * e^time_decay), ..., 1, e^(time_first)]
self . time_w = torch . cat ([ torch . exp ( self . time_decay ) * self . time_curve . to ( x . device ), self . time_first ], dim = - 1 )
w = torch . exp ( self . time_w )
# Use W to mix kv and k respectively. Add K_EPS to wk to avoid divide-by-zero
if RUN_DEVICE == 'cuda' :
wkv = TimeX . apply ( w , kv , B , C , T , 0 )
wk = TimeX . apply ( w , k , B , C , T , K_EPS )
else :
w = w [:, - T :]. unsqueeze ( 1 )
wkv = F . conv1d ( nn . ZeroPad2d (( T - 1 , 0 , 0 , 0 ))( kv ), w , groups = C )
wk = F . conv1d ( nn . ZeroPad2d (( T - 1 , 0 , 0 , 0 ))( k ), w , groups = C ) + K_EPS
# The RWKV formula
rwkv = torch . sigmoid ( r ) * ( wkv / wk ). transpose ( - 1 , - 2 )
rwkv = self . output ( rwkv ) # final output projectionMatriks self.key, self.receptance, self.output semuanya diinisialisasi ke nol.
Vektor time_mix, time_decay, time_first ditransfer dari model terlatih yang lebih kecil (catatan: Saya juga mengurutkan & menghaluskannya).
Blok FFN memiliki tiga trik dibandingkan dengan GPT biasa:
Trik time_mix saya.
SqReLU dari makalah Primer.
Gerbang penerimaan tambahan (mirip dengan gerbang penerimaan di blok ATT).
# Mix x with the previous timestep to produce xk, xr
xx = self . time_shift ( x )
xk = x * self . time_mix_k + xx * ( 1 - self . time_mix_k )
xr = x * self . time_mix_r + xx * ( 1 - self . time_mix_r )
# The usual FFN operation
k = self . key ( xk )
k = torch . square ( torch . relu ( k )) # from the Primer paper
kv = self . value ( k )
# Apply an extra receptance-gate to kv
rkv = torch . sigmoid ( self . receptance ( xr )) * kv
return rkvMatriks self.value, self.receptance semuanya diinisialisasi ke nol.

Misalkan F[t] adalah keadaan sistem pada t.
Misalkan x[t] menjadi masukan eksternal baru pada t.
Dalam GPT, memprediksi F[t+1] memerlukan pertimbangan F[0], F[1], .. F[t]. Jadi dibutuhkan O(T^2) untuk menghasilkan barisan T yang panjangnya.
Rumus sederhana untuk GPT:
Secara teori, ini sangat mumpuni, namun bukan berarti kita dapat sepenuhnya memanfaatkan kemampuannya dengan pengoptimal biasa . Saya menduga lanskap kerugian terlalu sulit untuk metode kami saat ini.
Bandingkan dengan rumus sederhana untuk RWKV (mode paralel, terlihat mirip dengan AFT Apple):
R, K, V adalah matriks yang dapat dilatih, dan W adalah vektor yang dapat dilatih (faktor peluruhan waktu untuk setiap saluran).
Dalam GPT, kontribusi F[i] terhadap F[t+1] diberi bobot sebesar .
Dalam RWKV-2, kontribusi F[i] terhadap F[t+1] diberi bobot sebesar .
Inilah lucunya: kita dapat menulis ulang menjadi RNN (rumus rekursif). Catatan:
Oleh karena itu, mudah untuk memverifikasi:
dimana A[t] dan B[t] masing-masing adalah pembilang dan penyebut dari langkah sebelumnya.
Saya yakin RWKV berkinerja baik karena W seperti menerapkan matriks diagonal berulang kali. Perhatikan (P^{-1} DP)^n = P^{-1} D^n P, sehingga mirip dengan penerapan berulang kali matriks umum yang dapat didiagonalisasi.
Selain itu, dimungkinkan untuk mengubahnya menjadi ODE berkelanjutan (sedikit mirip dengan State Space Models). Saya akan menulisnya nanti.
Saya punya ide untuk [teks --> gambar RGB 32x32] menggunakan LM (transformator, RWKV, dll.). Akan segera mengujinya.
Pertama, LM loss (bukan L2 loss), sehingga gambar tidak buram.
Kedua, kuantisasi warna. Misalnya, hanya mengizinkan 8 level untuk R/G/B. Maka ukuran vocab gambar adalah 8x8x8 = 512 (untuk setiap piksel), bukan 2^24. Oleh karena itu, gambar RGB 32x32 = rangkaian vocab512 (token gambar) len1024, yang merupakan masukan khas untuk LM biasa. (Nantinya kita bisa menggunakan model difusi untuk mengambil sampel dan menghasilkan gambar RGB888. Kita mungkin bisa menggunakan LM untuk ini juga.)
Ketiga, penyematan posisi 2D yang mudah dipahami model. Misalnya, tambahkan koordinat X & Y one-hot ke 64(=32+32) saluran pertama. Katakanlah jika pikselnya berada di x=8, y=20, maka kita akan menambahkan 1 ke saluran 8 dan saluran 52 (=32+20). Selain itu mungkin kita dapat menambahkan koordinat float X & Y (dinormalisasi ke rentang 0~1) ke 2 saluran lainnya. Dan pos berkala lainnya. pengkodean mungkin membantu juga (akan menguji).
Akhirnya, RandRound kapan


