CAMEL
1.0.0

Kami bangga memperkenalkan Asclepius , model bahasa klinis besar yang lebih maju. Karena model ini dilatih berdasarkan catatan klinis sintetik, model ini dapat diakses publik melalui Huggingface. Jika Anda mempertimbangkan untuk menggunakan CAMEL, kami sangat menyarankan untuk beralih ke Asclepius. Untuk informasi lebih lanjut, silakan kunjungi tautan ini.
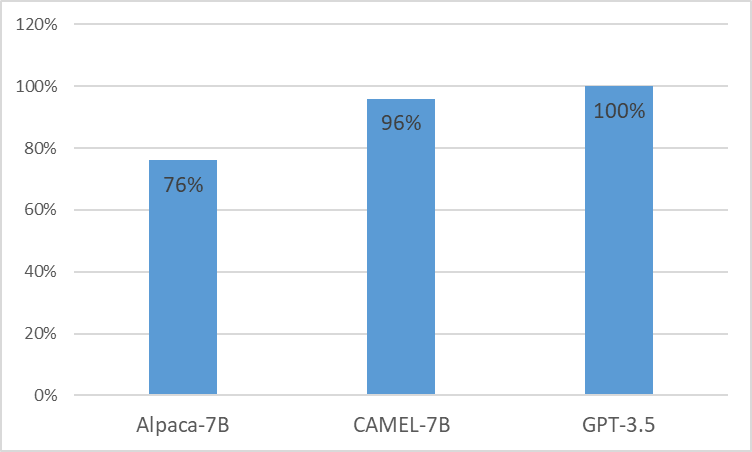
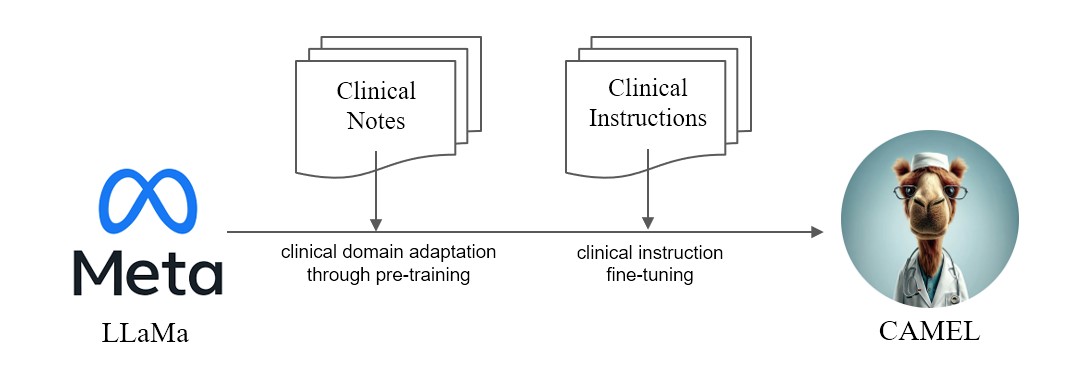
Kami mempersembahkan CAMEL , Model yang Diadaptasi Secara Klinis yang Disempurnakan dari LLaMA. Sebagai LLaMA sebagai fondasinya, CAMEL dilatih terlebih dahulu mengenai catatan klinis MIMIC-III dan MIMIC-IV, dan disesuaikan dengan instruksi klinis (Gambar 2). Evaluasi awal kami dengan penilaian GPT-4 menunjukkan bahwa CAMEL mencapai lebih dari 96% kualitas GPT-3.5 OpenAI (Gambar 1). Sesuai dengan kebijakan penggunaan data dari data sumber kami, kumpulan data dan model instruksi kami akan dipublikasikan di PhysioNet dengan akses yang dikredensialkan. Untuk memfasilitasi replikasi, kami juga akan merilis semua kode, sehingga masing-masing institusi layanan kesehatan dapat mereproduksi model kami menggunakan catatan klinis mereka sendiri. Untuk detail lebih lanjut, silakan lihat postingan blog kami.
Karena masalah lisensi kumpulan data MIMIC dan i2b2, kami tidak dapat mempublikasikan kumpulan data instruksi dan pos pemeriksaan. Kami akan mempublikasikan model dan data kami melalui fisionet dalam beberapa minggu.
conda create -n camel python=3.9 -y
conda activate camel
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia -y
pip install pandarallel pandas jupyter numpy datasets sentencepiece openai fire
pip install git+https://github.com/huggingface/transformers.git@871598be552c38537bc047a409b4a6840ba1c1e4
<eos> .$ python pretraining_preprocess/mimiciii_preproc.py --mimiciii_note_path {MIMICIII_NOTE_PATH} --output_path {OUTPUT_PATH}$ python pretraining_preprocess/mimiciv_preproc.py --discharge_note_path {DISCHAGE_NOTE_PATH} --radiology_note_path {RADIOLOGY_NOTE_PATH} --output_path {OUTPUT_PATH}$ python pretraining_preprocess/tokenize_data.py --data_path {DATA_PATH} --save_path {SAVE_PATH} $ torchrun --nproc_per_node=8 --master_port={YOUR_PORT}
src/train.py
--model_name_or_path "decapoda-research/llama-7b-hf"
--data_path {DATA_FILE}
--bf16 True
--output_dir ./checkpoints
--num_train_epochs 1
--per_device_train_batch_size 2
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 1000
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type "cosine"
--logging_steps 1
--fsdp "full_shard auto_wrap"
--fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer'
--tf32 True
--model_max_length 2048
--gradient_checkpointing True
CATATAN: Untuk menghasilkan instruksi, Anda harus menggunakan Azure Openai API bersertifikat.
Generasi Instruksi
OPENAI_API_KEYOPENAI_API_BASEOPENAI_DEPLOYMENT_NAME$ python instructino/preprocess_note.py$ python instruction/de_id_gen.py --input {PREPROCESSED_NOTES} --output {OUTPUT_FILE_1} --mode inst$ python instruction/de_id_postprocess.py --input {OUTPUT_FILE_1} --output {OUTPUT_FILE_2}$ python instruction/de_id_gen.py --input {OUTPUT__FILE_2} --output {inst_output/OUTPUT_FILE_deid} --mode ans$ python instruction/instructtion_gen.py --input {PREPROCESSED_NOTES} --output {inst_output/OUTPUT_FILE} --source {mimiciii, mimiciv, i2b2}$ python instruction/merge_data.py --data_path {inst_output} --output {OUTPUT_FILE_FINAL}Jalankan Penyempurnaan Instruksi
nproc_per_node dan gradient accumulate step agar sesuai dengan perangkat keras Anda (ukuran batch global=128). $ torchrun --nproc_per_node=8 --master_port={YOUR_PORT}
src/instruction_ft.py
--model_name_or_path "decapoda-research/llama-7b-hf"
--data_path {OUTPUT_FILE_FINAL}
--bf16 True
--output_dir ./checkpoints
--num_train_epochs 3
--per_device_train_batch_size 2
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "epoch"
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type "cosine"
--logging_steps 1
--fsdp "full_shard auto_wrap"
--fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer'
--tf32 True
--model_max_length 2048
--gradient_checkpointing True
--ddp_timeout 18000
Jalankan model di MTSamples
CUDA_VISIBLE_DEVICES=0 python src/evaluate.py
--model_name {MODEL_PATH}
--data_path eval/mtsamples_instructions.json
--output_path {OUTPUT_PATH}
mtsamples_results.json di folder eval .Jalankan GPT-4 untuk evaluasi
python eval/gpt4_evaluate.py --input {INPUT_PATH} --output {OUTPUT_PATH}
@misc{CAMEL,
title = {CAMEL : Clinically Adapted Model Enhanced from LLaMA},
author = {Sunjun Kweon and Junu Kim and Seongsu Bae and Eunbyeol Cho and Sujeong Im and Jiyoun Kim and Gyubok Lee and JongHak Moon and JeongWoo Oh and Edward Choi},
month = {May},
year = {2023}
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/starmpcc/CAMEL}},
}


