DiGIT
1.0.0
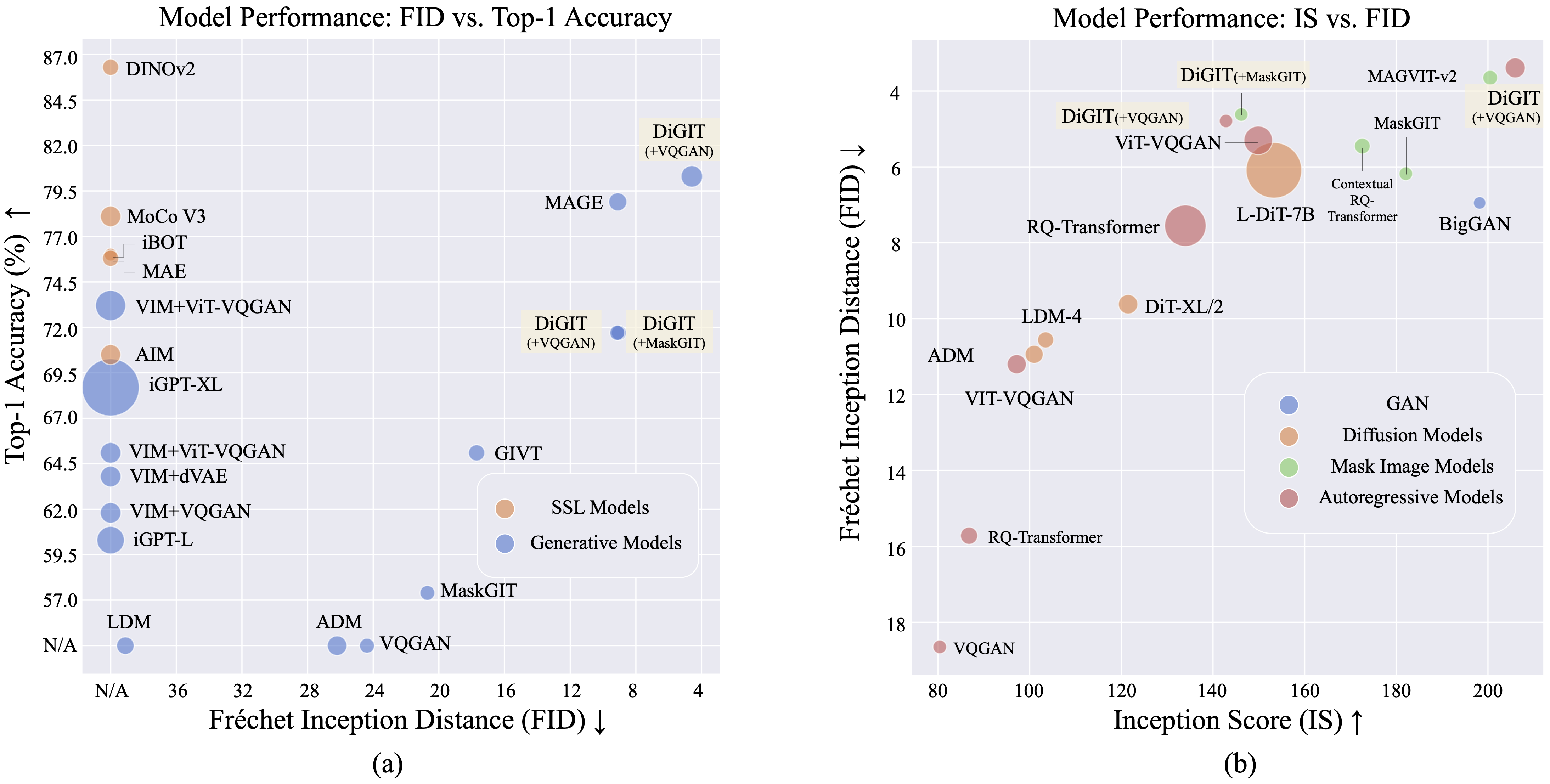
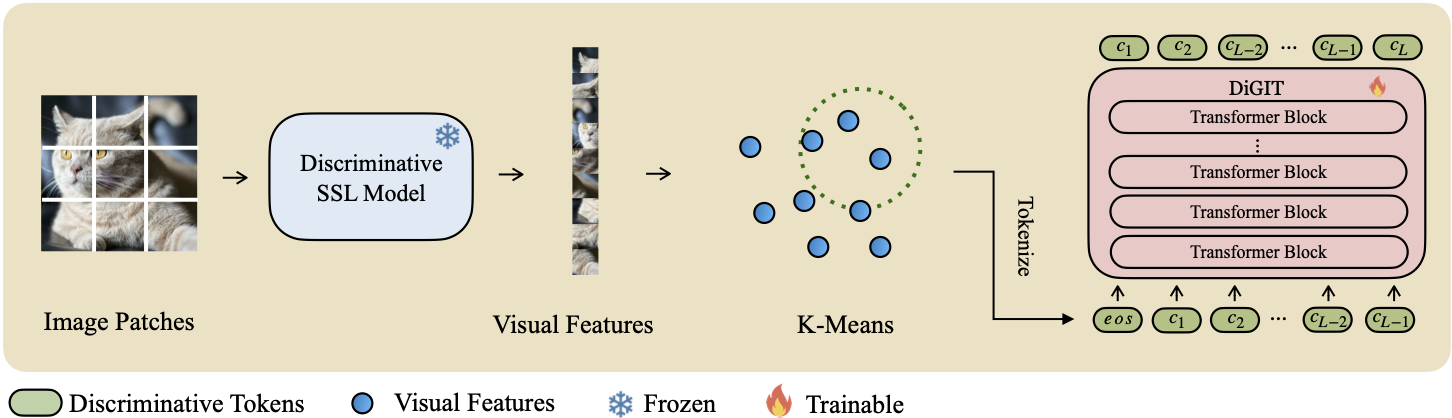
Kami menghadirkan DiGIT , model generatif auto-regresif yang melakukan prediksi token berikutnya dalam ruang laten abstrak yang berasal dari model pembelajaran mandiri (SSL). Dengan menggunakan pengelompokan K-Means pada status tersembunyi model DINOv2, kami secara efektif membuat tokenizer diskrit baru. Metode ini secara signifikan meningkatkan kinerja pembuatan gambar pada kumpulan data ImageNet, mencapai skor FID sebesar 4,59 untuk tugas tanpa syarat kelas dan 3,39 untuk tugas bersyarat kelas . Selain itu, model ini meningkatkan pemahaman gambar, mencapai akurasi penyelidikan linier sebesar 80,3 .
| Metode | # Token | Fitur | #Param | Akun 1 Teratas. |
|---|---|---|---|---|
| iGPT-L | 32 | 1536 | 1362M | 60.3 |
| iGPT-XL | 64 | 3072 | 6801M | 68.7 |
| VIM+VQGAN | 32 | 1024 | 650M | 61.8 |
| VIM+dVAE | 32 | 1024 | 650M | 63.8 |
| VIM+ViT-VQGAN | 32 | 1024 | 650M | 65.1 |
| VIM+ViT-VQGAN | 32 | 2048 | 1697M | 73.2 |
| TUJUAN | 16 | 1536 | 0,6B | 70.5 |
| DiGIT (Milik Kami) | 16 | 1024 | 219M | 71.7 |
| DiGIT (Milik Kami) | 16 | 1536 | 732M | 80.3 |
| Jenis | Metode | #param | #Epoch | FID | ADALAH |
|---|---|---|---|---|---|
| GAN | GAN Besar | 70M | - | 38.6 | 24.70 |
| Beda. | LDM | 395M | - | 39.1 | 22.83 |
| Beda. | ADM | 554M | - | 26.2 | 39.70 |
| MIM | PENYIHIR | 200M | 1600 | 11.1 | 81.17 |
| MIM | PENYIHIR | 463M | 1600 | 9.10 | 105.1 |
| MIM | MaskerGIT | 227M | 300 | 20.7 | 42.08 |
| MIM | DiGIT (+MaskGIT) | 219M | 200 | 9.04 | 75.04 |
| AR | VQGAN | 214M | 200 | 24.38 | 30.93 |
| AR | DiGIT (+VQGAN) | 219M | 400 | 9.13 | 73,85 |
| AR | DiGIT (+VQGAN) | 732M | 200 | 4.59 | 141.29 |
| Jenis | Metode | #param | #Epoch | FID | ADALAH |
|---|---|---|---|---|---|
| GAN | GAN Besar | 160M | - | 6.95 | 198.2 |
| Beda. | ADM | 554M | - | 10.94 | 101.0 |
| Beda. | LDM-4 | 400M | - | 10.56 | 103.5 |
| Beda. | DiT-XL/2 | 675M | - | 9.62 | 121,50 |
| Beda. | L-DiT-7B | 7B | - | 6.09 | 153.32 |
| MIM | CQR-Trans | 371M | 300 | 5.45 | 172.6 |
| MIM+AR | VAR | 310M | 200 | 4.64 | - |
| MIM+AR | VAR | 310M | 200 | 3,60* | 257,5* |
| MIM+AR | VAR | 600M | 250 | 2,95* | 306.1* |
| MIM | MAGVIT-v2 | 307M | 1080 | 3.65 | 200,5 |
| AR | VQVAE-2 | 13.5B | - | 31.11 | 45 |
| AR | RQ-Trans | 480M | - | 15.72 | 86.8 |
| AR | RQ-Trans | 3.8B | - | 7.55 | 134.0 |
| AR | ViTVQGAN | 650M | 360 | 11.20 | 97.2 |
| AR | ViTVQGAN | 1.7B | 360 | 5.3 | 149.9 |
| MIM | MaskerGIT | 227M | 300 | 6.18 | 182.1 |
| MIM | DiGIT (+MaskGIT) | 219M | 200 | 4.62 | 146.19 |
| AR | VQGAN | 227M | 300 | 18.65 | 80.4 |
| AR | DiGIT (+VQGAN) | 219M | 400 | 4.79 | 142.87 |
| AR | DiGIT (+VQGAN) | 732M | 200 | 3.39 | 205.96 |
*: VAR dilatih dengan panduan bebas pengklasifikasi sedangkan model lainnya tidak.
File npy K-Means dan pos pemeriksaan model dapat diunduh dari:
| Model | Link |
|---|---|
| beban HF? | wajah berpelukan |
Untuk model dasar kami menggunakan DINOv2-base dan DINOv2-large untuk model ukuran besar. VQGAN yang kami gunakan sama dengan MAGE.
DiGIT
└── data/
├── ILSVRC2012
├── dinov2_base_short_224_l3
├── km_8k.npy
├── dinov2_large_short_224_l3
├── km_16k.npy
└── outputs/
├── base_8k_stage1
├── ...
└── models/
├── vqgan_jax_strongaug.ckpt
├── dinov2_vitb14_reg4_pretrain.pth
├── dinov2_vitl14_reg4_pretrain.pth
git clone https://github.com/DAMO-NLP-SG/DiGIT.git
cd DiGITfairseq melalui pip install fairseq . Unduh kumpulan data ImageNet, dan letakkan di direktori kumpulan data Anda $PATH_TO_YOUR_WORKSPACE/dataset/ILSVRC2012 .
Ekstrak fitur SSL dan simpan sebagai file .npy. Gunakan algoritma K-Means dengan faiss untuk menghitung centroid. Anda juga dapat memanfaatkan centroid terlatih kami yang tersedia di Huggingface.
bash preprocess/run.shLangkah1
Latih model GPT dengan tokenizer yang diskriminatif. Anda dapat menemukan skrip pelatihan di scripts/train_stage1_ar.sh dan hyper-params ada di config/stage1/dino_base.yaml . Untuk konfigurasi pembuatan kondisi kelas, lihat scripts/train_stage1_classcond.sh .
Langkah2
Latih decoder piksel (baik model AR atau model NAR) yang dikondisikan pada token diskriminatif. Anda dapat menemukan skrip pelatihan autoregresif di scripts/train_stage2_ar.sh dan skrip pelatihan NAR di scripts/train_stage2_nar.sh .
Folder bernama outputs/EXP_NAME/checkpoints akan dibuat untuk menyimpan pos pemeriksaan. File log TensorBoard disimpan di outputs/EXP_NAME/tb . Log akan dicatat di outputs/EXP_NAME/train.log .
Anda dapat memantau proses pelatihan menggunakan tensorboard --logdir=outputs/EXP_NAME/tb .
Pengambilan sampel token diskriminatif pertama dengan scripts/infer_stage1_ar.sh . Untuk ukuran model dasar, sebaiknya atur topk=200, dan untuk ukuran model besar, gunakan topk=400.
Kemudian jalankan scripts/infer_stage2_ar.sh untuk mengambil sampel token VQ berdasarkan sampel token diskriminatif yang diambil sebelumnya.
Token yang dihasilkan dan gambar yang disintesis akan disimpan dalam direktori bernama outputs/EXP_NAME/results .
Siapkan set validasi ImageNet untuk evaluasi FID:
python prepare_imgnet_val.py --data_path $PATH_TO_YOUR_WORKSPACE /dataset/ILSVRC2012 --output_dir imagenet-val Instal alat evaluasi dengan menjalankan pip install torch-fidelity .
Jalankan perintah berikut untuk mengevaluasi FID:
python fairseq_user/eval_fid.py --results-path $IMG_SAVE_DIR --subset $GEN_SUBSETbash scripts/train_stage1_linearprobe.shProyek ini dilisensikan di bawah Lisensi MIT - lihat file LISENSI untuk detailnya.
Jika Anda merasa proyek kami bermanfaat, harap Anda dapat memberi bintang pada repo kami dan mengutip karya kami sebagai berikut.
@misc { zhu2024stabilize ,
title = { Stabilize the Latent Space for Image Autoregressive Modeling: A Unified Perspective } ,
author = { Yongxin Zhu and Bocheng Li and Hang Zhang and Xin Li and Linli Xu and Lidong Bing } ,
year = { 2024 } ,
eprint = { 2410.12490 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

