FasterTransformer
v5.3 release
Catatan: Pengembangan FasterTransformer telah dialihkan ke TensorRT-LLM. Semua pengembang didorong untuk memanfaatkan TensorRT-LLM untuk mendapatkan penyempurnaan terbaru pada Inferensi LLM. Repo NVIDIA/FasterTransformer akan tetap ada, tetapi tidak akan dikembangkan lebih lanjut.
Repositori ini menyediakan skrip dan resep untuk menjalankan komponen encoder dan decoder berbasis transformator yang sangat optimal, dan diuji serta dikelola oleh NVIDIA.
Dalam NLP, encoder dan decoder adalah dua komponen penting, dengan lapisan transformator menjadi arsitektur populer untuk kedua komponen tersebut. FasterTransformer mengimplementasikan lapisan transformator yang sangat optimal untuk encoder dan decoder untuk inferensi. Pada GPU Volta, Turing, dan Ampere, daya komputasi Tensor Cores digunakan secara otomatis ketika presisi data dan bobotnya mencapai FP16.
FasterTransformer dibangun di atas CUDA, cuBLAS, cuBLASLt dan C++. Kami menyediakan setidaknya satu API dari framework berikut: TensorFlow, PyTorch, dan backend Triton. Pengguna dapat mengintegrasikan FasterTransformer ke dalam kerangka kerja ini secara langsung. Untuk kerangka pendukung, kami juga menyediakan kode contoh untuk mendemonstrasikan cara menggunakan, dan menunjukkan kinerja kerangka kerja tersebut.
| Model | Kerangka | FP16 | INT8 (setelah Turing) | Ketersebaran (setelah Ampere) | Paralel tensor | Paralel pipa | FP8 (setelah Hopper) |
|---|---|---|---|---|---|---|---|
| BERT | Aliran Tensor | Ya | Ya | - | - | - | - |
| BERT | PyTorch | Ya | Ya | Ya | Ya | Ya | - |
| BERT | Bagian belakang Triton | Ya | - | - | Ya | Ya | - |
| BERT | C++ | Ya | Ya | - | - | - | Ya |
| XLNet | C++ | Ya | - | - | - | - | - |
| Pembuat enkode | Aliran Tensor | Ya | Ya | - | - | - | - |
| Pembuat enkode | PyTorch | Ya | Ya | Ya | - | - | - |
| Dekoder | Aliran Tensor | Ya | - | - | - | - | - |
| Dekoder | PyTorch | Ya | - | - | - | - | - |
| Penguraian kode | Aliran Tensor | Ya | - | - | - | - | - |
| Penguraian kode | PyTorch | Ya | - | - | - | - | - |
| GPT | Aliran Tensor | Ya | - | - | - | - | - |
| GPT/PISAH | PyTorch | Ya | - | - | Ya | Ya | Ya |
| GPT/PISAH | Bagian belakang Triton | Ya | - | - | Ya | Ya | - |
| GPT-MoE | PyTorch | Ya | - | - | Ya | Ya | - |
| BUNGA | PyTorch | Ya | - | - | Ya | Ya | - |
| BUNGA | Bagian belakang Triton | Ya | - | - | Ya | Ya | - |
| GPT-J | Bagian belakang Triton | Ya | - | - | Ya | Ya | - |
| Mantan | PyTorch | Ya | - | - | - | - | - |
| T5/UL2 | PyTorch | Ya | - | - | Ya | Ya | - |
| T5 | Aliran Tensor 2 | Ya | - | - | - | - | - |
| T5/UL2 | Bagian belakang Triton | Ya | - | - | Ya | Ya | - |
| T5 | TensorRT | Ya | - | - | Ya | Ya | - |
| T5-MoE | PyTorch | Ya | - | - | Ya | Ya | - |
| Transformator Babi | PyTorch | Ya | Ya | - | - | - | - |
| Transformator Babi | TensorRT | Ya | Ya | - | - | - | - |
| ViT | PyTorch | Ya | Ya | - | - | - | - |
| ViT | TensorRT | Ya | Ya | - | - | - | - |
| GPT-NeoX | PyTorch | Ya | - | - | Ya | Ya | - |
| GPT-NeoX | Bagian belakang Triton | Ya | - | - | Ya | Ya | - |
| BART/mBART | PyTorch | Ya | - | - | Ya | Ya | - |
| WeNet | C++ | Ya | - | - | - | - | - |
| DeBERTa | Aliran Tensor 2 | Ya | - | - | Sedang berlangsung | Sedang berlangsung | - |
| DeBERTa | PyTorch | Ya | - | - | Sedang berlangsung | Sedang berlangsung | - |
Rincian lebih lanjut tentang model tertentu dimasukkan ke dalam xxx_guide.md dari docs/ , di mana xxx berarti nama model. Beberapa pertanyaan umum dan jawabannya masing-masing ada di docs/QAList.md . Perhatikan bahwa model Encoder dan BERT serupa dan kami memasukkan penjelasannya ke dalam bert_guide.md bersama-sama.
Kode berikut mencantumkan struktur direktori FasterTransformer:
/src/fastertransformer: source code of FasterTransformer
|--/cutlass_extensions: Implementation of cutlass gemm/kernels.
|--/kernels: CUDA kernels for different models/layers and operations, like addBiasResiual.
|--/layers: Implementation of layer modules, like attention layer, ffn layer.
|--/models: Implementation of different models, like BERT, GPT.
|--/tensorrt_plugin: encapluate FasterTransformer into TensorRT plugin.
|--/tf_op: custom Tensorflow OP implementation
|--/th_op: custom PyTorch OP implementation
|--/triton_backend: custom triton backend implementation
|--/utils: Contains common cuda utils, like cublasMMWrapper, memory_utils
/examples: C++, tensorflow and pytorch interface examples
|--/cpp: C++ interface examples
|--/pytorch: PyTorch OP examples
|--/tensorflow: TensorFlow OP examples
|--/tensorrt: TensorRT examples
/docs: Documents to explain the details of implementation of different models, and show the benchmark
/benchmark: Contains the scripts to run the benchmarks of different models
/tests: Unit tests
/templates: Documents to explain how to add a new model/example into FasterTransformer repo
Perhatikan bahwa banyak folder berisi banyak sub-folder untuk membagi model yang berbeda. Alat kuantisasi dipindahkan ke examples , seperti examples/tensorflow/bert/bert-quantization/ dan examples/pytorch/bert/bert-quantization-sparsity/ .
FasterTransformer menyediakan beberapa variabel lingkungan yang nyaman untuk debugging dan pengujian.
FT_LOG_LEVEL : Lingkungan ini mengontrol tingkat log pesan debug. Detail selengkapnya ada di src/fastertransformer/utils/logger.h . Perhatikan bahwa program akan mencetak banyak pesan ketika levelnya lebih rendah dari DEBUG dan program akan menjadi sangat lambat.FT_NVTX : Jika diatur ke ON seperti FT_NVTX=ON ./bin/gpt_example , program akan memasukkan tag nvtx untuk membantu membuat profil program.FT_DEBUG_LEVEL : Jika disetel menjadi DEBUG , maka program akan berjalan cudaDeviceSynchronize() setelah setiap kernel. Jika tidak, kernel akan dieksekusi secara asinkron secara default. Sangat membantu untuk menemukan titik kesalahan selama proses debug. Namun tanda ini mempengaruhi kinerja program secara signifikan. Jadi, ini sebaiknya hanya digunakan untuk debugging. Pengaturan perangkat keras:
Untuk menjalankan benchmark berikut, kita perlu menginstal alat komputasi unix "bc" oleh
apt-get install bc Hasil FP16 TensorFlow diperoleh dengan menjalankan benchmarks/bert/tf_benchmark.sh .
Hasil INT8 TensorFlow diperoleh dengan menjalankan benchmarks/bert/tf_int8_benchmark.sh .
Hasil FP16 PyTorch diperoleh dengan menjalankan benchmarks/bert/pyt_benchmark.sh .
Hasil INT8 dari PyTorch diperoleh dengan menjalankan benchmarks/bert/pyt_int8_benchmark.sh .
Tolok ukur lainnya dimasukkan ke dalam docs/bert_guide.md .
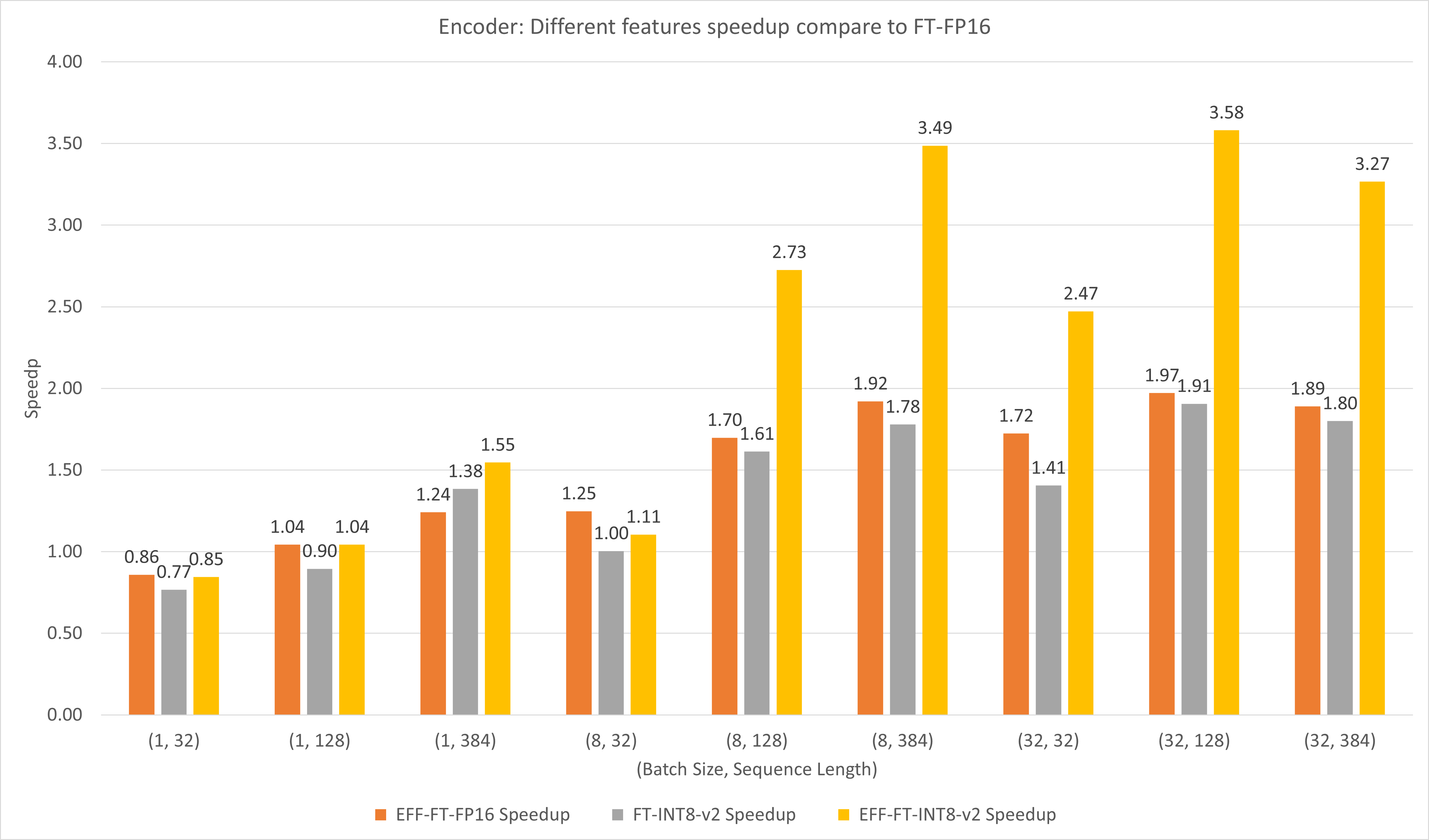
Gambar berikut membandingkan performa berbagai fitur FasterTransformer dan FasterTransformer pada FP16 di T4.
Untuk ukuran batch besar dan panjang urutan, EFF-FT dan FT-INT8-v2 menghasilkan percepatan 2x. Menggunakan FasterTransformer dan int8v2 yang Efektif secara bersamaan dapat menghasilkan kecepatan 3,5x dibandingkan FasterTransformer FP16 untuk kasus besar.
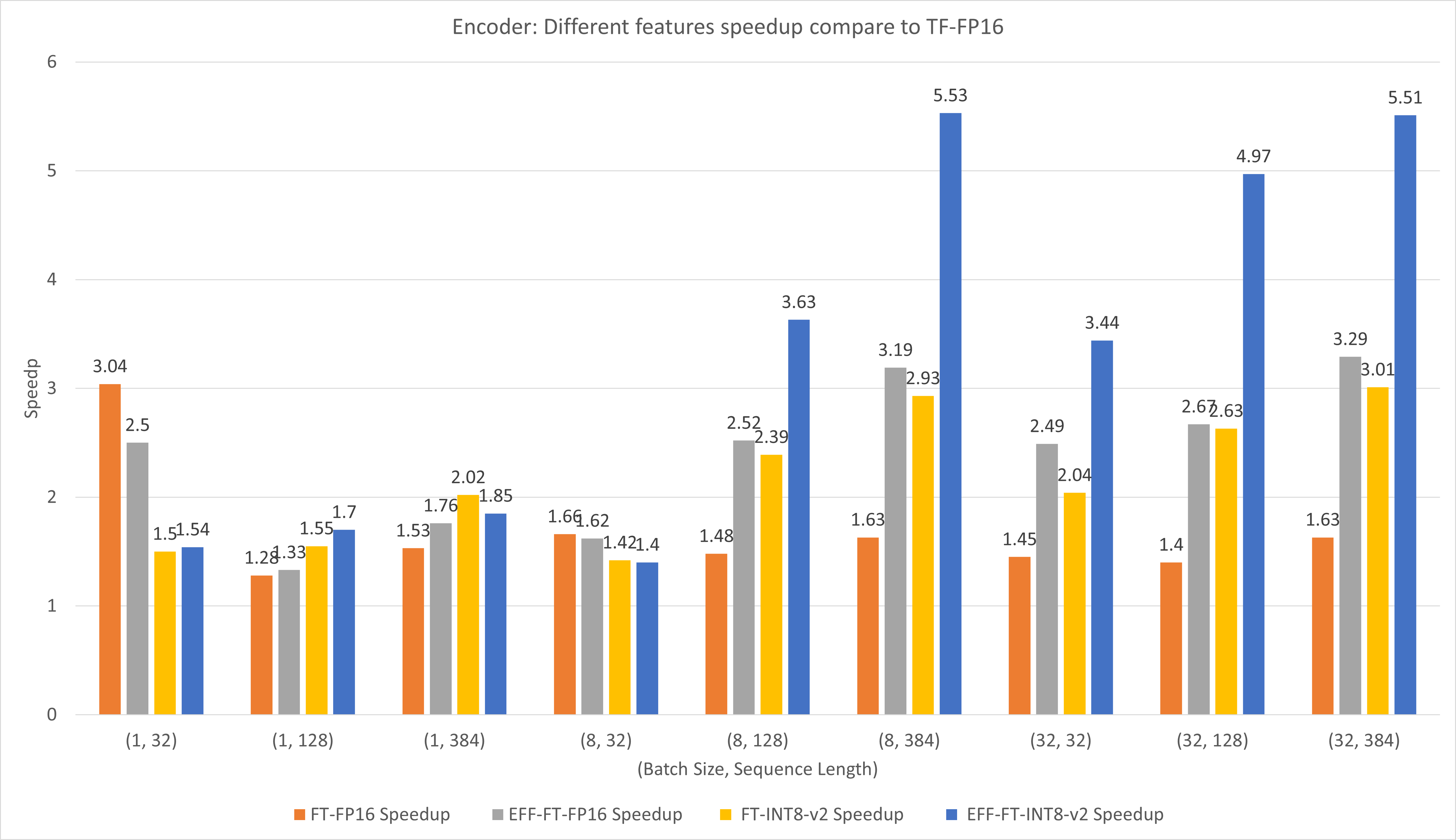
Gambar berikut membandingkan performa berbagai fitur FasterTransformer dan TensorFlow XLA pada FP16 di T4.
Untuk ukuran batch kecil dan panjang urutan, penggunaan FasterTransformer dapat menghasilkan kecepatan 3x lebih cepat.
Untuk ukuran batch besar dan panjang urutan, menggunakan Effective FasterTransformer dengan kuantisasi INT8-v2 dapat menghasilkan percepatan 5x.
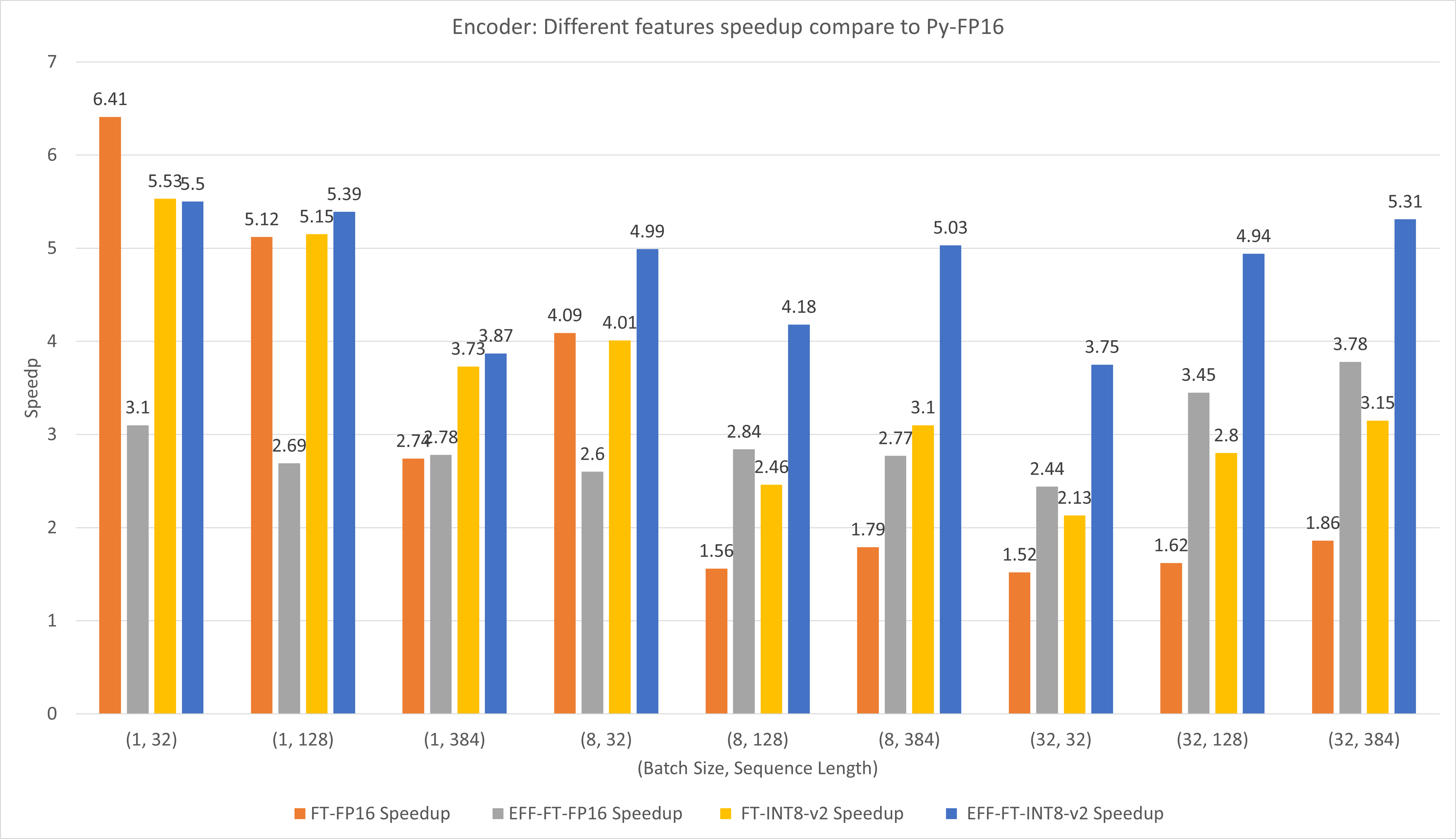
Gambar berikut membandingkan performa berbagai fitur FasterTransformer dan PyTorch TorchScript pada FP16 di T4.
Untuk ukuran batch kecil dan panjang urutan, penggunaan FasterTransformer CustomExt dapat menghasilkan percepatan 4x ~ 6x.
Untuk ukuran batch besar dan panjang urutan, menggunakan Effective FasterTransformer dengan kuantisasi INT8-v2 dapat menghasilkan percepatan 5x.
Hasil TensorFlow diperoleh dengan menjalankan benchmarks/decoding/tf_decoding_beamsearch_benchmark.sh dan benchmarks/decoding/tf_decoding_sampling_benchmark.sh
Hasil PyTorch diperoleh dengan menjalankan benchmarks/decoding/pyt_decoding_beamsearch_benchmark.sh .
Dalam percobaan decoding, kami memperbarui parameter berikut:
Tolok ukur lainnya dimasukkan ke dalam docs/decoder_guide.md .
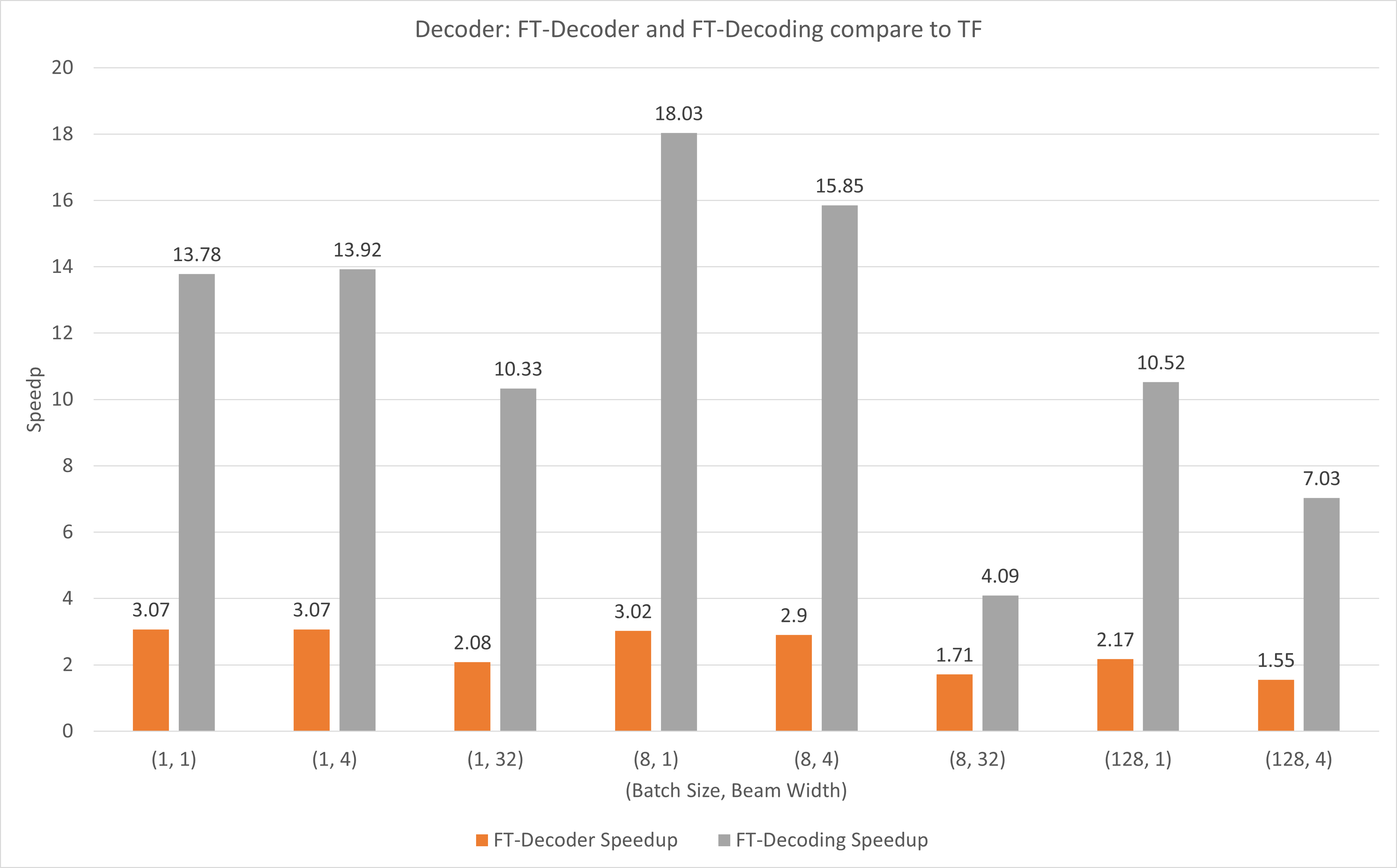
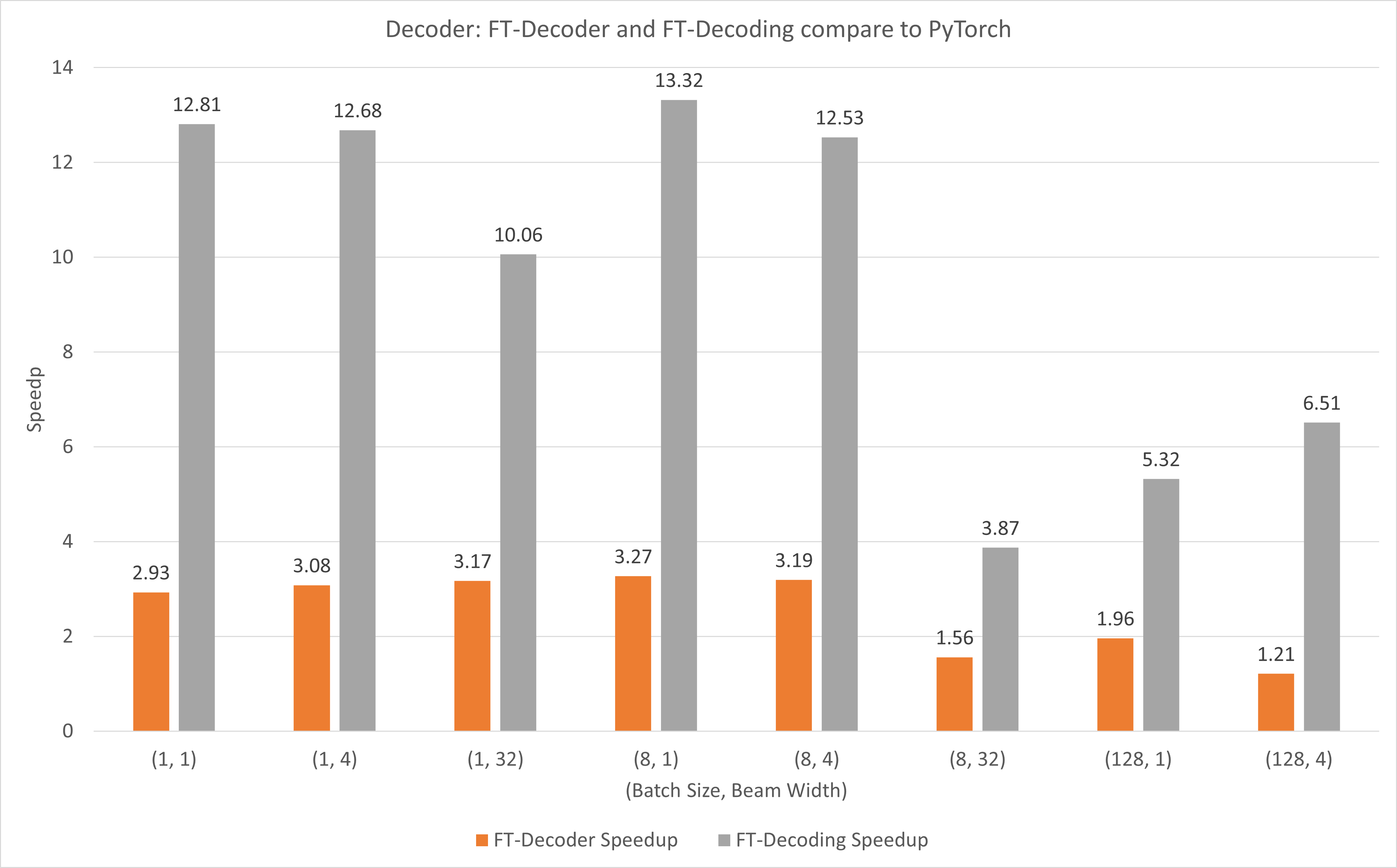
Gambar berikut menunjukkan kecepatan operasi FT-Decoder dan operasi FT-Decoding dibandingkan TensorFlow pada FP16 dengan T4. Di sini, kami menggunakan throughput penerjemahan set pengujian untuk mencegah total token dari setiap metode mungkin berbeda. Dibandingkan dengan TensorFlow, FT-Decoder memberikan kecepatan 1,5x ~ 3x; sementara FT-Decoding memberikan kecepatan 4x ~ 18x.
Gambar berikut menunjukkan kecepatan operasi FT-Decoder dan operasi FT-Decoding dibandingkan dengan PyTorch di bawah FP16 dengan T4. Di sini, kami menggunakan throughput penerjemahan set pengujian untuk mencegah total token dari setiap metode mungkin berbeda. Dibandingkan dengan PyTorch, FT-Decoder memberikan kecepatan 1,2x ~ 3x; sementara FT-Decoding memberikan kecepatan 3,8x ~ 13x.
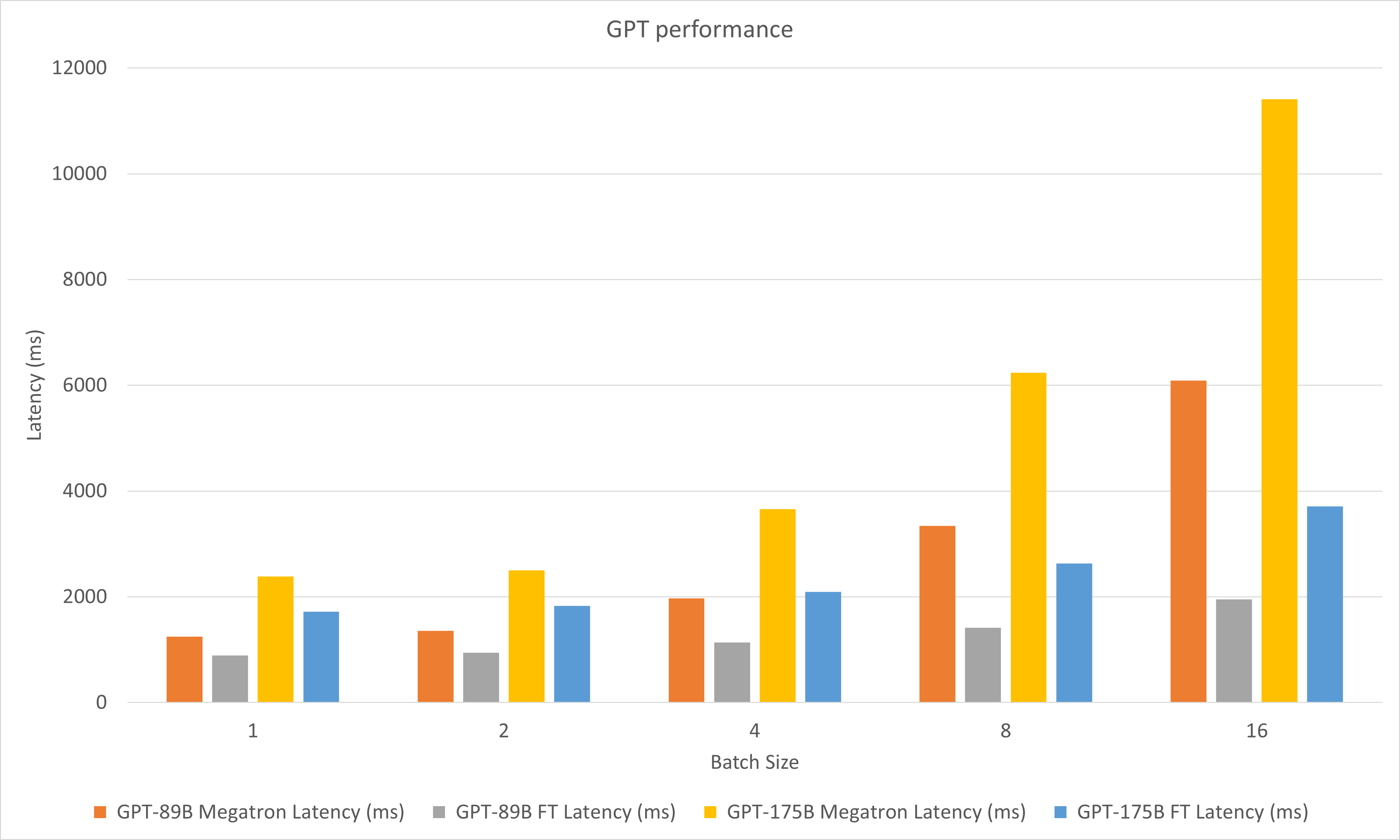
Gambar berikut membandingkan performa Megatron dan FasterTransformer di bawah FP16 pada A100.
Dalam percobaan decoding, kami memperbarui parameter berikut:
Mei 2023
Januari 2023
Desember 2022
November 2022
Oktober 2022
September 2022
Agustus 2022
Juli 2022
Juni 2022
Mei 2022
April 2022
Maret 2022
stop_ids dan ban_bad_ids di GPT-J.start_id dan end_id di GPT-J, GPT, T5 dan Decoding.Februari 2022
Desember 2021
November 2021
Agustus 2021
layer_para menjadi pipeline_para .size_per_head 96, 160, 192, 224, 256 untuk model GPT.Juni 2021
April 2021
Desember 2020
November 2020
September 2020
Agustus 2020
Juni 2020
Mei 2020
translate_sample.py .April 2020
decoding_opennmt.h menjadi decoding_beamsearch.hdecoding_sampling.hbert_transformer_op.h , bert_transformer_op.cu.cc menjadi bert_transformer_op.ccdecoder.h , decoder.cu.cc ke dalam decoder.ccdecoding_beamsearch.h , decoding_beamsearch.cu.cc ke dalam decoding_beamsearch.ccbleu_score.py ke dalam utils . Perhatikan bahwa skor BLEU memerlukan python3.Maret 2020
translate_sample.py untuk mendemonstrasikan cara menerjemahkan kalimat dengan memulihkan model OpenNMT-tf yang telah dilatih sebelumnya.Februari 2020
Juli 2019
import torch terlebih dahulu. Jika hal ini terjadi, hal ini disebabkan oleh C++ ABI yang tidak kompatibel. Anda mungkin perlu memeriksa apakah PyTorch yang digunakan selama kompilasi dan eksekusi sama, atau Anda perlu memeriksa bagaimana PyTorch Anda dikompilasi, atau versi GCC Anda, dll.

