PatrickStar
v0.4.6

Lihat CHANGE_LOG.md.
Model Pra-Terlatih (PTM) menjadi pusat penelitian NLP dan penerapan industri. Namun, pelatihan PTM memerlukan sumber daya perangkat keras yang sangat besar, sehingga hanya dapat diakses oleh sebagian kecil orang di komunitas AI. Sekarang, PatrickStar akan menyediakan pelatihan PTM untuk semua orang!
Out-of-memory error (OOM) adalah mimpi buruk setiap insinyur yang melatih PTM. Kami sering kali harus memperkenalkan lebih banyak GPU untuk menyimpan parameter model guna mencegah kesalahan tersebut. PatrickStar memberikan solusi yang lebih baik untuk masalah tersebut. Dengan pelatihan heterogen (DeepSpeed Zero Stage 3 juga menggunakannya), PatrickStar dapat sepenuhnya menggunakan memori CPU dan GPU sehingga Anda dapat menggunakan lebih sedikit GPU untuk melatih model yang lebih besar.
Ide Patrick adalah seperti ini. Data non-model (terutama aktivasi) bervariasi selama pelatihan, namun solusi pelatihan heterogen saat ini secara statis membagi data model ke CPU dan GPU. Untuk menggunakan GPU dengan lebih baik, PatrickStar mengusulkan penjadwalan memori dinamis dengan bantuan modul manajemen memori berbasis potongan. Manajemen memori PatrickStar mendukung pemindahan semuanya kecuali bagian komputasi model saat ini ke CPU untuk menghemat GPU. Selain itu, manajemen memori berbasis potongan efisien untuk komunikasi kolektif saat melakukan penskalaan ke beberapa GPU. Lihat makalah dan dokumen ini untuk mengetahui ide di balik PatrickStar.
Dalam percobaannya, Patrickstar v0.4.3 mampu melatih model param 18 Miliar (18B) dengan GPU 8xTesla V100 dan memori GPU 240GB di node pusat data WeChat, yang topologi jaringannya seperti ini. PatrickStar dua kali lebih besar dari DeepSpeed. Dan performa PatrickStar juga lebih baik untuk model dengan ukuran yang sama. Pstarnya adalah PatrickStar v0.4.3. Deeps menunjukkan kinerja DeepSpeed v0.4.3 menggunakan contoh resmi tahap DeepSpeed contoh zero3 dengan optimasi aktivasi yang dibuka secara default.

Kami juga mengevaluasi PatrickStar v0.4.3 pada satu node SuperPod A100. Ini dapat melatih model 68B pada 8xA100 dengan memori CPU 1TB, yang 6x lebih besar dari DeepSpeed v0.5.7. Selain skala model, PatrickStar jauh lebih efisien daripada DeepSpeed. Skrip benchmark ada di sini.

Hasil benchmark terperinci pada pusat data WeChat AI dan NVIDIA SuperPod diposting di Google Dokumen ini.
Skalakan PatrickStar ke beberapa mesin (node) di SuperPod. Kami berhasil melatih GPT3-175B pada 32 GPU. Sejauh yang kami tahu, ini adalah pekerjaan pertama yang menjalankan GPT3 pada cluster GPU sekecil itu. Microsoft menggunakan 10.000 V100 untuk terkait GPT3. Sekarang Anda dapat menyempurnakannya atau bahkan melakukan pra-pelatihan sendiri pada GPU 32 A100, luar biasa!

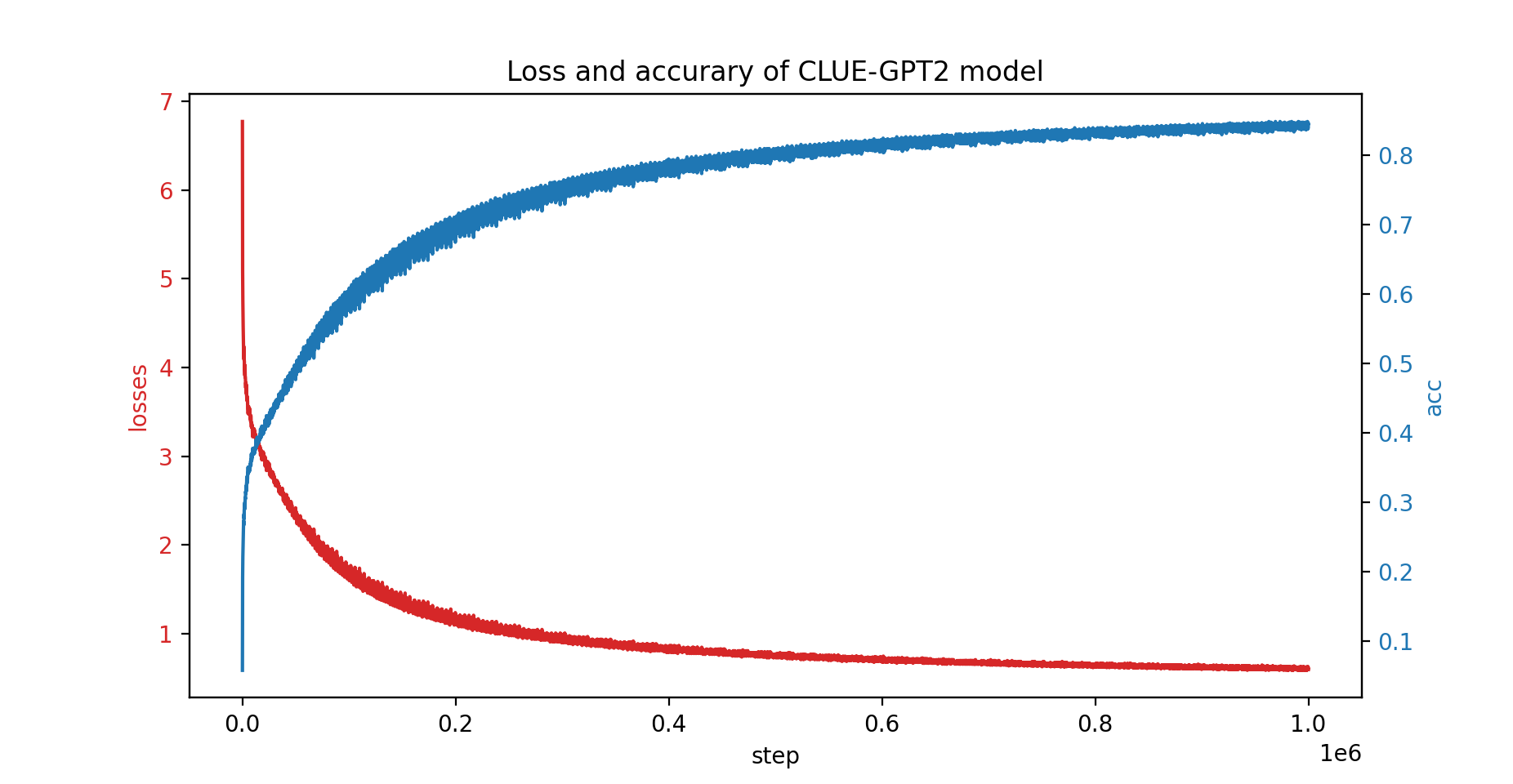
Kami juga telah melatih model CLUE-GPT2 dengan PatrickStar, kurva kerugian dan akurasi ditunjukkan di bawah ini:
pip install .Perhatikan bahwa PatrickStar memerlukan gcc versi 7 atau lebih tinggi. Anda juga dapat menggunakan gambar NVIDIA NGC, gambar berikut diuji:
docker pull nvcr.io/nvidia/pytorch:21.06-py3PatrickStar didasarkan pada PyTorch, sehingga memudahkan migrasi proyek pytorch. Berikut ini contoh PatrickStar:
from patrickstar . runtime import initialize_engine
config = {
"optimizer" : {
"type" : "Adam" ,
"params" : {
"lr" : 0.001 ,
"betas" : ( 0.9 , 0.999 ),
"eps" : 1e-6 ,
"weight_decay" : 0 ,
"use_hybrid_adam" : True ,
},
},
"fp16" : { # loss scaler params
"enabled" : True ,
"loss_scale" : 0 ,
"initial_scale_power" : 2 ** 3 ,
"loss_scale_window" : 1000 ,
"hysteresis" : 2 ,
"min_loss_scale" : 1 ,
},
"default_chunk_size" : 64 * 1024 * 1024 ,
"release_after_init" : True ,
"use_cpu_embedding" : False ,
"client" : {
"mem_tracer" : {
"use_async_mem_monitor" : args . with_async_mem_monitor ,
}
},
}
def model_func ():
# MyModel is a derived class for torch.nn.Module
return MyModel (...)
model , optimizer = initialize_engine ( model_func = model_func , local_rank = 0 , config = config )
...
for data in dataloader :
optimizer . zero_grad ()
loss = model ( data )
model . backward ( loss )
optimizer . step () Kami menggunakan format config yang sama dengan konfigurasi DeepSpeed JSON, yang sebagian besar mencakup parameter pengoptimal, penskala kerugian, dan beberapa konfigurasi khusus PatrickStar.
Untuk penjelasan detail contoh di atas, silakan cek panduannya di sini
Untuk contoh lainnya, silakan periksa di sini.
Skrip benchmark mulai cepat ada di sini. Itu dijalankan dengan data yang dihasilkan secara acak; oleh karena itu Anda tidak perlu menyiapkan data sebenarnya. Itu juga menunjukkan semua teknik optimasi untuk patrickstar. Untuk trik pengoptimalan lainnya dalam menjalankan benchmark, lihat Opsi Pengoptimalan.
Lisensi 3-Klausul BSD
@article{fang2021patrickstar,
title={PatrickStar: Parallel Training of Pre-trained Models via a Chunk-based Memory Management},
author={Fang, Jiarui and Yu, Yang and Zhu, Zilin and Li, Shenggui and You, Yang and Zhou, Jie},
journal={arXiv preprint arXiv:2108.05818},
year={2021}
}
@article{fang2022parallel,
title={Parallel Training of Pre-Trained Models via Chunk-Based Dynamic Memory Management},
author={Fang, Jiarui and Zhu, Zilin and Li, Shenggui and Su, Hui and Yu, Yang and Zhou, Jie and You, Yang},
journal={IEEE Transactions on Parallel and Distributed Systems},
volume={34},
number={1},
pages={304--315},
year={2022},
publisher={IEEE}
}
{jiaruifang, zilinzhu, josephyu}@tencent.com
Didukung oleh Tim AI WeChat, Tencent NLP Oteam.


