xcodec
1.0.0
Codec Semantik dan Akustik Terpadu untuk Model Bahasa Audio.
Judul : Codec Penting: Mengeksplorasi Kekurangan Semantik Codec untuk Model Bahasa Audio
Penulis : Zhen Ye, Peiwen Sun, Jiahe Lei, Hongzhan Lin, Xu Tan, Zheqi Dai, Qiuqiang Kong, Jianyi Chen, Jiahao Pan, Qifeng Liu, Yike Guo*, Wei Xue*
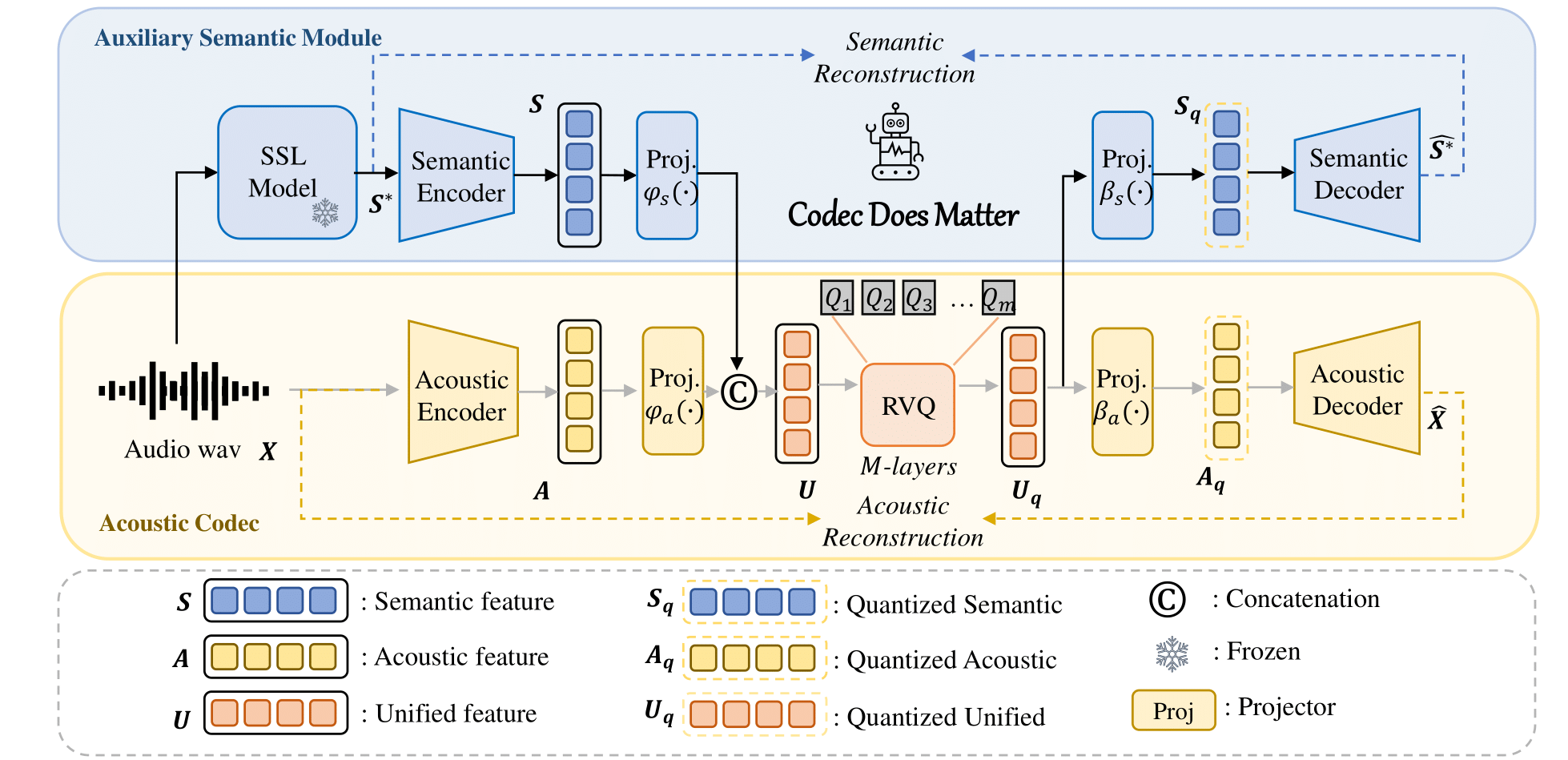
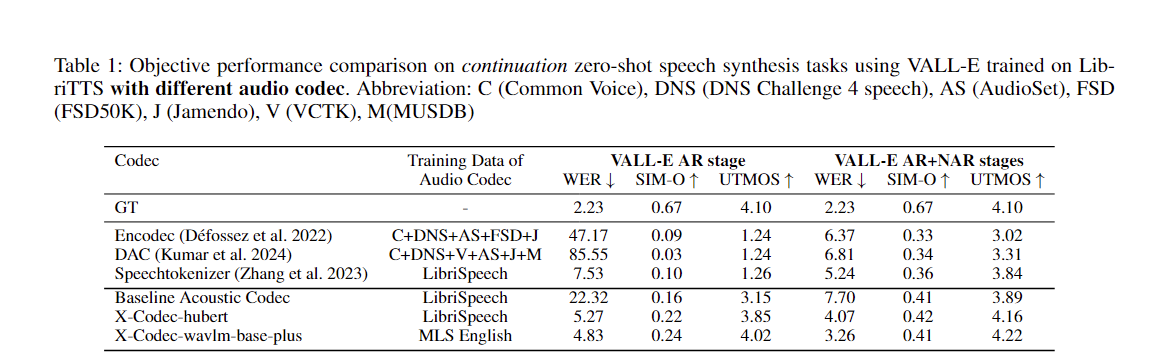
Anda dapat dengan mudah menerapkan pendekatan kami untuk menyempurnakan codec akustik yang ada:
Misalnya
class Codec ():
def __init__ ( self ):
# Acoustic codec components
self . encoder = Encoder (...) # Acoustic encoder
self . decoder = Decoder (...) # Acoustic decoder
self . quantizer = RVQ (...) # Residual Vector Quantizer (RVQ)
# Adding the semantic module
self . semantic_model = AutoModel . from_pretrained (...) # e.g., Hubert, WavLM
# Adding Projector
self . fc_prior = nn . Linear (...)
self . fc_post1 = nn . Linear (...)
self . fc_post2 = nn . Linear (...)
def forward ( self , x , bw ):
# Encode the input acoustically and semantically
e_acoustic = self . encoder ( x )
e_semantic = self . semantic_model ( x )
# Combine acoustic and semantic features
combined_features = torch . cat ([ e_acoustic , e_semantic ])
# Apply prior transformation
transformed_features = self . fc_prior ( combined_features )
# Quantize the unified semantic and acoustic features
quantized , codes , bandwidth , commit_loss = self . quantizer ( transformed_features , bw )
# Post-process the quantized features
quantized_semantic = self . fc_post1 ( quantized )
quantized_acoustic = self . fc_post2 ( quantized )
# Decode the quantized acoustic features
output = self . decoder ( quantized_acoustic )
def semantic_loss ( self , semantic , quantized_semantic ):
return F . mse_loss ( semantic , quantized_semantic ) Untuk lebih jelasnya, silakan lihat kode kami.
? tautan ke hub model Huggingface.
| Nama model | Memeluk Wajah | Konfigurasi | Model Semantik | Domain | Data Pelatihan |
|---|---|---|---|---|---|
| xcodec_hubert_librispeech | ? | ? | ? Pangkalan Hubert | Pidato | Pidato pustaka |
| xcodec_wavlm_mls (tidak disebutkan di kertas) | ? | ? | ? Wavlm-basis-plus | Pidato | MLS Bahasa Inggris |
| xcodec_wavlm_more_data (tidak disebutkan di kertas) | ? | ? | ? Wavlm-basis-plus | Pidato | MLS Bahasa Inggris + Data internal |
| xcodec_hubert_general_audio | ? | ? | ?Hubert-base-umum-audio | Audio umum | Data internal 200k jam |
| xcodec_hubert_general_audio_more_data (tidak disebutkan di kertas) | ? | ? | ?Hubert-base-umum-audio | Audio umum | Data yang lebih seimbang |
Untuk menjalankan inferensi, pertama-tama unduh model dan konfigurasi dari pelukan wajah.
python inference.pySiapkan file_pelatihan dan file_validasi di konfigurasi. File tersebut harus mencantumkan jalur ke file audio Anda:
/path/to/your/xxx.wav
/path/to/your/yyy.wav
...Kemudian:
torchrun --nnodes=1 --nproc-per-node=8 main_launch_vqdp.pySaya ingin mengucapkan terima kasih khusus kepada penulis Uniaudio dan DAC, karena basis kode kami sebagian besar dipinjam dari Uniaudio dan DAC.
Jika Anda merasa repo ini bermanfaat, harap pertimbangkan untuk mengutip dalam format berikut:
@article { ye2024codecdoesmatterexploring ,
title = { Codec Does Matter: Exploring the Semantic Shortcoming of Codec for Audio Language Model } ,
author = { Zhen Ye and Peiwen Sun and Jiahe Lei and Hongzhan Lin and Xu Tan and Zheqi Dai and Qiuqiang Kong and Jianyi Chen and Jiahao Pan and Qifeng Liu and Yike Guo and Wei Xue } ,
journal = { arXiv preprint arXiv:2408.17175 } ,
year = { 2024 } ,
}

