EasyEdit
1.0.0

Kerangka Pengeditan Pengetahuan yang Mudah Digunakan untuk Model Bahasa Besar.
Instalasi • Mulai Cepat • Dokumen • Makalah • Demo • Tolok Ukur • Kontributor • Slide • Video • Ditampilkan Oleh AK
23-10-2024, EasyEdit mengintegrasikan metode decoding terbatas mulai dari pengeditan kemudi hingga mengurangi halusinasi di LLM dan MLLM, dengan informasi terperinci tersedia di DoLa dan DeCo.
26-09-2024, ?? makalah kami "WISE: Memikirkan Kembali Memori Pengetahuan untuk Pengeditan Model Seumur Hidup Model Bahasa Besar" telah diterima oleh NeurIPS 2024 .
20-09-2024, ?? makalah kami: "Mekanisme Pengetahuan dalam Model Bahasa Besar: Survei dan Perspektif" dan "Mengedit Pengetahuan Konseptual untuk Model Bahasa Besar" telah diterima oleh Temuan EMNLP 2024 .
29-07-2024, EasyEdit telah menambahkan algoritma pengeditan model baru EMMET, yang menggeneralisasi ROME ke pengaturan batch. Ini pada dasarnya memungkinkan melakukan pengeditan massal menggunakan fungsi kerugian ROME.
23-07-2024, kami merilis makalah baru: "Mekanisme Pengetahuan dalam Model Bahasa Besar: Survei dan Perspektif", yang mengulas bagaimana pengetahuan diperoleh, dimanfaatkan, dan berkembang dalam model bahasa besar. Survei ini dapat memberikan mekanisme mendasar untuk memanipulasi (mengedit) pengetahuan di LLM secara tepat dan efisien.
04-06-2024, ?? Makalah EasyEdit telah diterima oleh Jalur Demonstrasi Sistem ACL 2024 .
03-06-2024, kami merilis makalah berjudul "WISE: Memikirkan Kembali Memori Pengetahuan untuk Pengeditan Model Seumur Hidup Model Bahasa Besar" , bersamaan dengan memperkenalkan tugas pengeditan baru: Pengeditan Pengetahuan Berkelanjutan dan metode pengeditan seumur hidup terkait yang disebut WISE.
24-04-2024, EasyEdit mengumumkan dukungan untuk metode ROME untuk Llama3-8B . Pengguna disarankan untuk memperbarui paket transformator mereka ke versi 4.40.0.
29-03-2024, EasyEdit memperkenalkan dukungan rollback untuk GRACE . Untuk pengenalan mendetail, lihat dokumentasi EasyEdit. Pembaruan di masa depan secara bertahap akan mencakup dukungan rollback untuk metode lain.
22-03-2024, makalah baru berjudul "Detoksifikasi Model Bahasa Besar melalui Pengeditan Pengetahuan" dirilis, bersama dengan kumpulan data baru bernama SafeEdit dan metode detoksifikasi baru yang disebut DINM.
12-03-2024, makalah lain berjudul "Mengedit Pengetahuan Konseptual untuk Model Bahasa Besar" dirilis, memperkenalkan kumpulan data baru bernama ConceptEdit.
01-03-2024, EasyEdit menambahkan dukungan untuk metode baru yang disebut FT-M . Metode ini melibatkan pelatihan lapisan MLP tertentu menggunakan kehilangan entropi silang pada jawaban target dan menutupi teks asli . Ini mengungguli implementasi FT-L di ROMA. Penulis edisi #173 berterima kasih atas sarannya.
27-02-2024, EasyEdit menambahkan dukungan untuk metode baru yang disebut InstructEdit, dengan detail teknis disediakan di makalah "InstructEdit: Pengeditan Pengetahuan Berbasis Instruksi untuk Model Bahasa Besar" .
Accelerate .Studi Komprehensif tentang Pengeditan Pengetahuan untuk Model Bahasa Besar [kertas] [benchmark] [kode]
Tutorial IJCAI 2024 Google Drive
Tutorial COLING 2024 Google Drive
Tutorial AAAI 2024 Google Drive
Tutorial AACL 2023 [Google Drive] [Baidu Pan]
Ada demonstrasi pengeditan. File GIF dibuat oleh Terminalizer.
Kami menyediakan Notebook Jupyter yang praktis! Hal ini memungkinkan Anda untuk mengedit pengetahuan LLM tentang presiden AS, beralih dari Biden ke Trump dan bahkan kembali ke Biden. Ini mencakup metode seperti WISE, AlphaEdit, AdaLoRA, dan pengeditan berbasis Prompt.
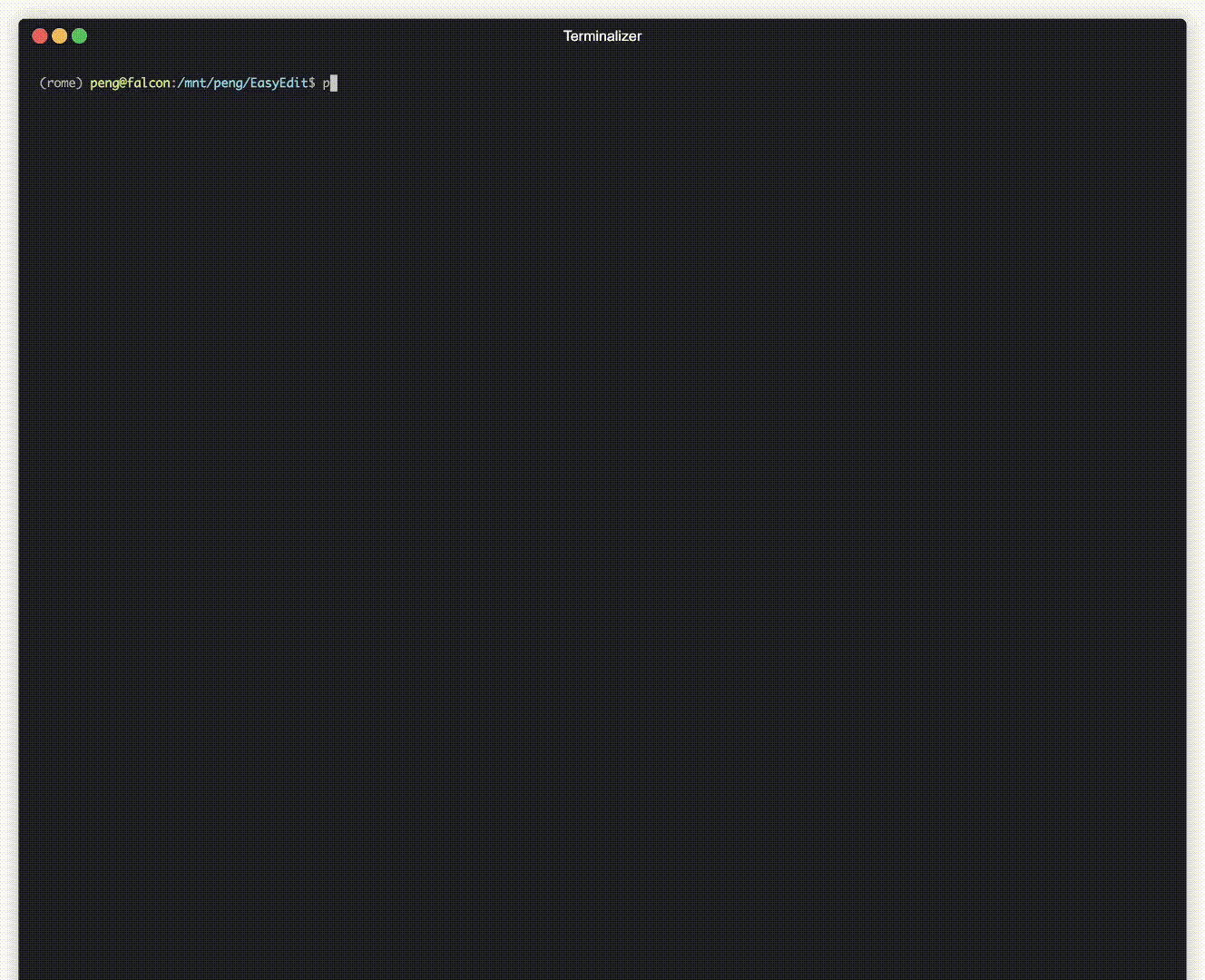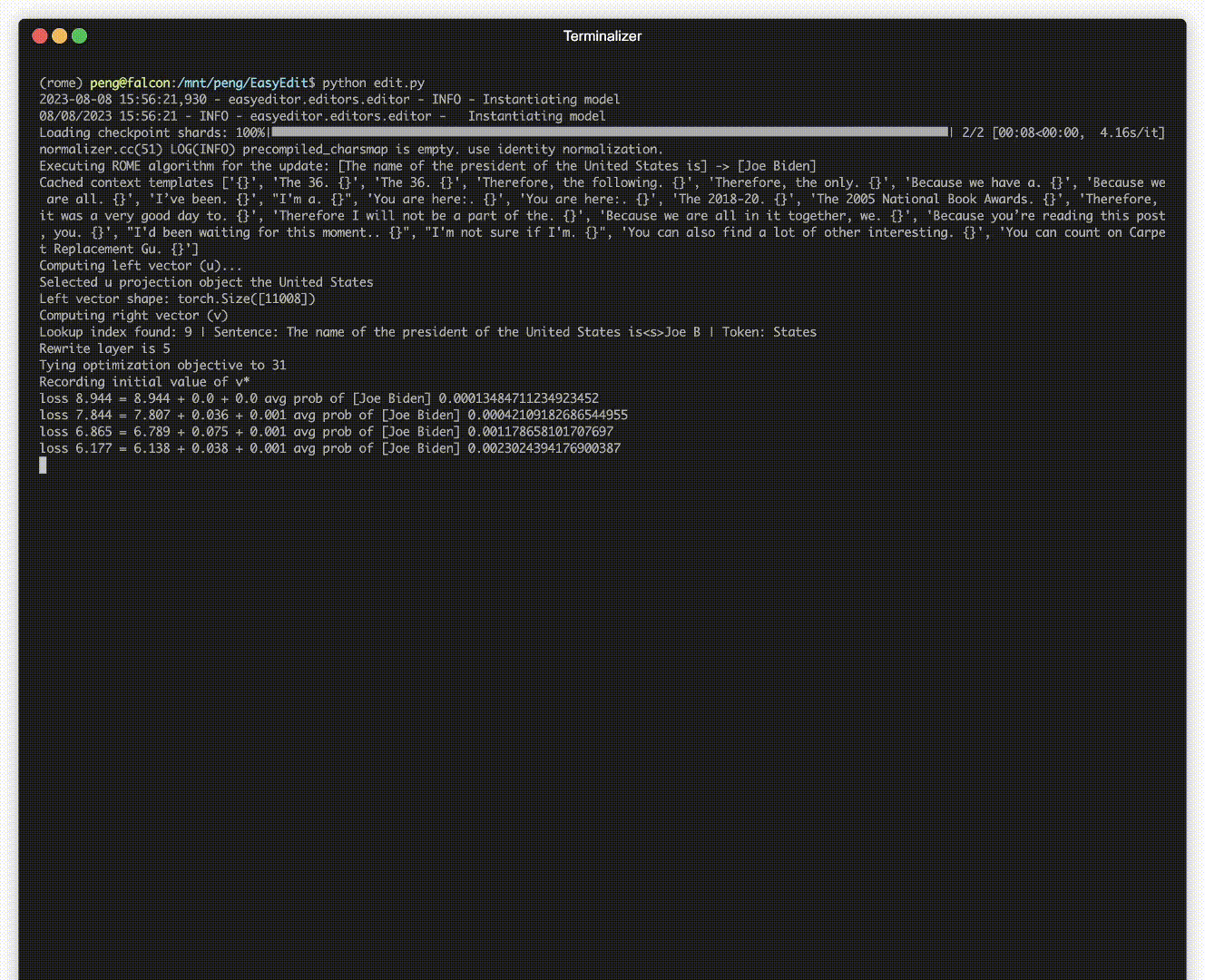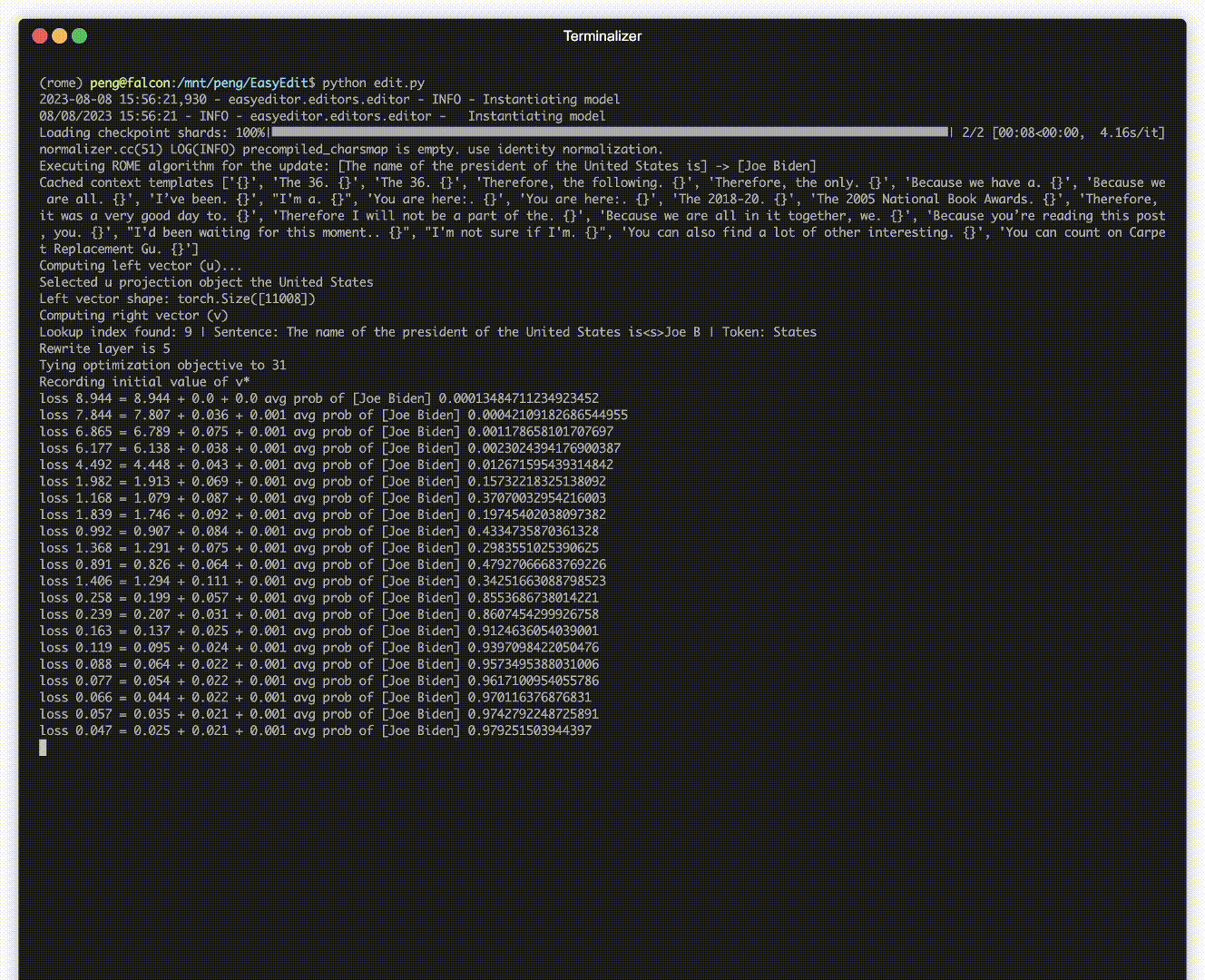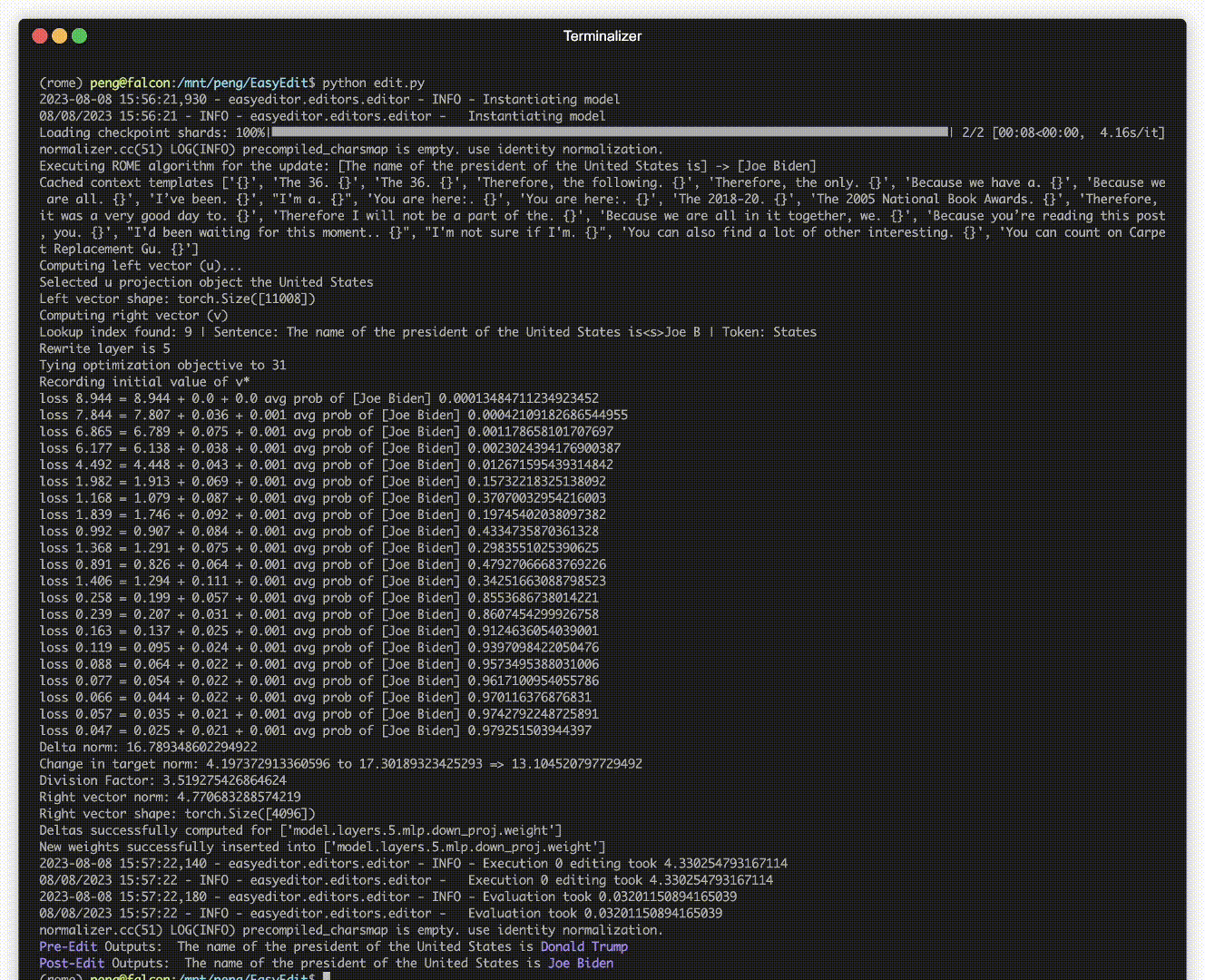
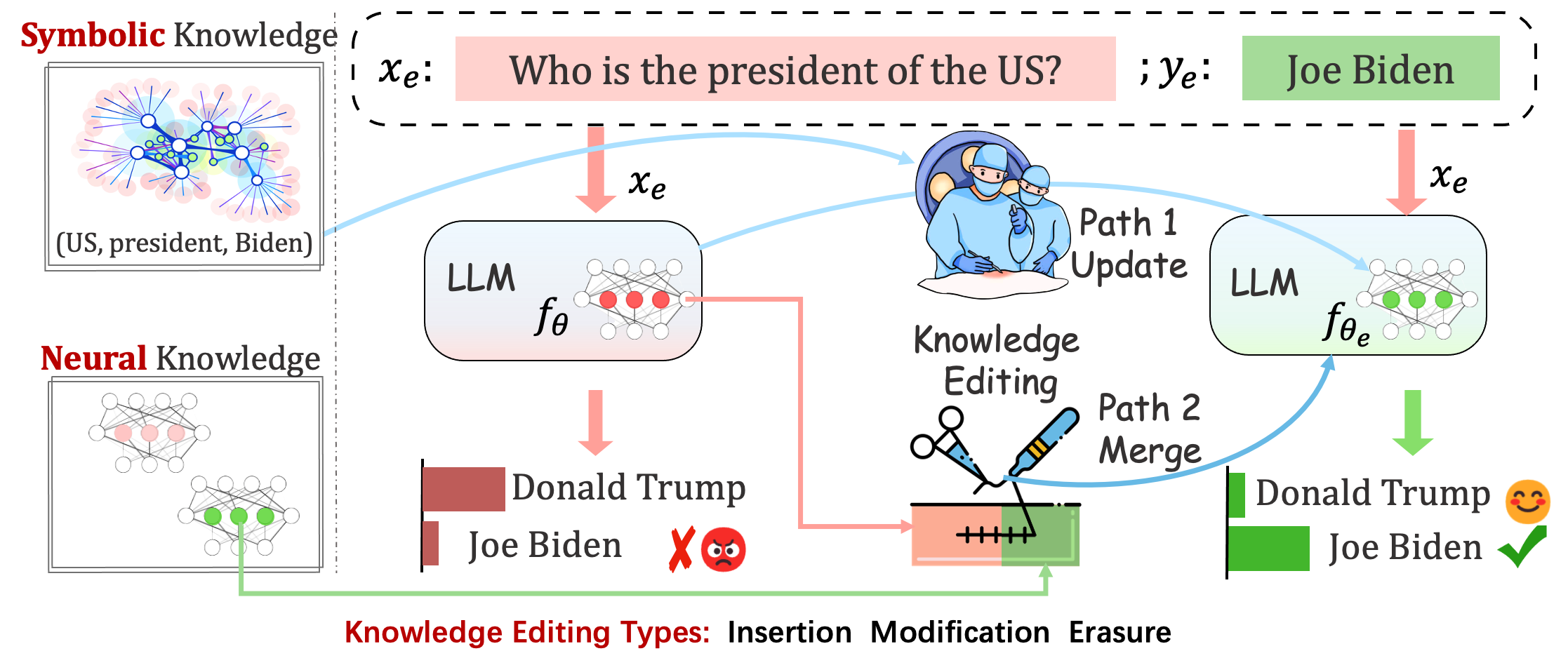
Model yang diterapkan mungkin masih membuat kesalahan yang tidak dapat diprediksi. Misalnya, LLM terkenal berhalusinasi , melanggengkan bias , dan membusuk secara faktual , jadi kita harus dapat menyesuaikan perilaku spesifik dari model yang telah dilatih sebelumnya.
Pengeditan pengetahuan bertujuan untuk menyesuaikan model dasar
Mengevaluasi kinerja model setelah satu kali pengeditan. Model memuat ulang bobot asli (misalnya LoRA membuang bobot adaptor) setelah satu kali pengeditan. Anda harus menyetel sequential_edit=False
Hal ini memerlukan pengeditan secara berurutan , dan evaluasi dilakukan setelah semua pembaruan pengetahuan diterapkan:
Itu membuat penyesuaian parameter untuk sequential_edit=True : README (untuk lebih jelasnya).
Tanpa memengaruhi perilaku model pada sampel yang tidak terkait, tujuan utamanya adalah membuat model yang telah diedit
Tugas Pengeditan untuk Keterangan Gambar dan Jawaban Pertanyaan Visual . BACA SAYA
Tugas yang diusulkan mengambil upaya awal untuk mengedit kepribadian LLM dengan mengedit opini mereka tentang topik tertentu, mengingat opini individu dapat mencerminkan aspek ciri kepribadian mereka. Kami memanfaatkan teori LIMA BESAR yang sudah ada sebagai dasar untuk membangun kumpulan data kami dan menilai ekspresi kepribadian LLM. BACA SAYA
Evaluasi
Berbasis logit
Berbasis generasi
Sedangkan untuk menilai Acc dan TPEI , Anda dapat mengunduh pengklasifikasi terlatih dari sini.
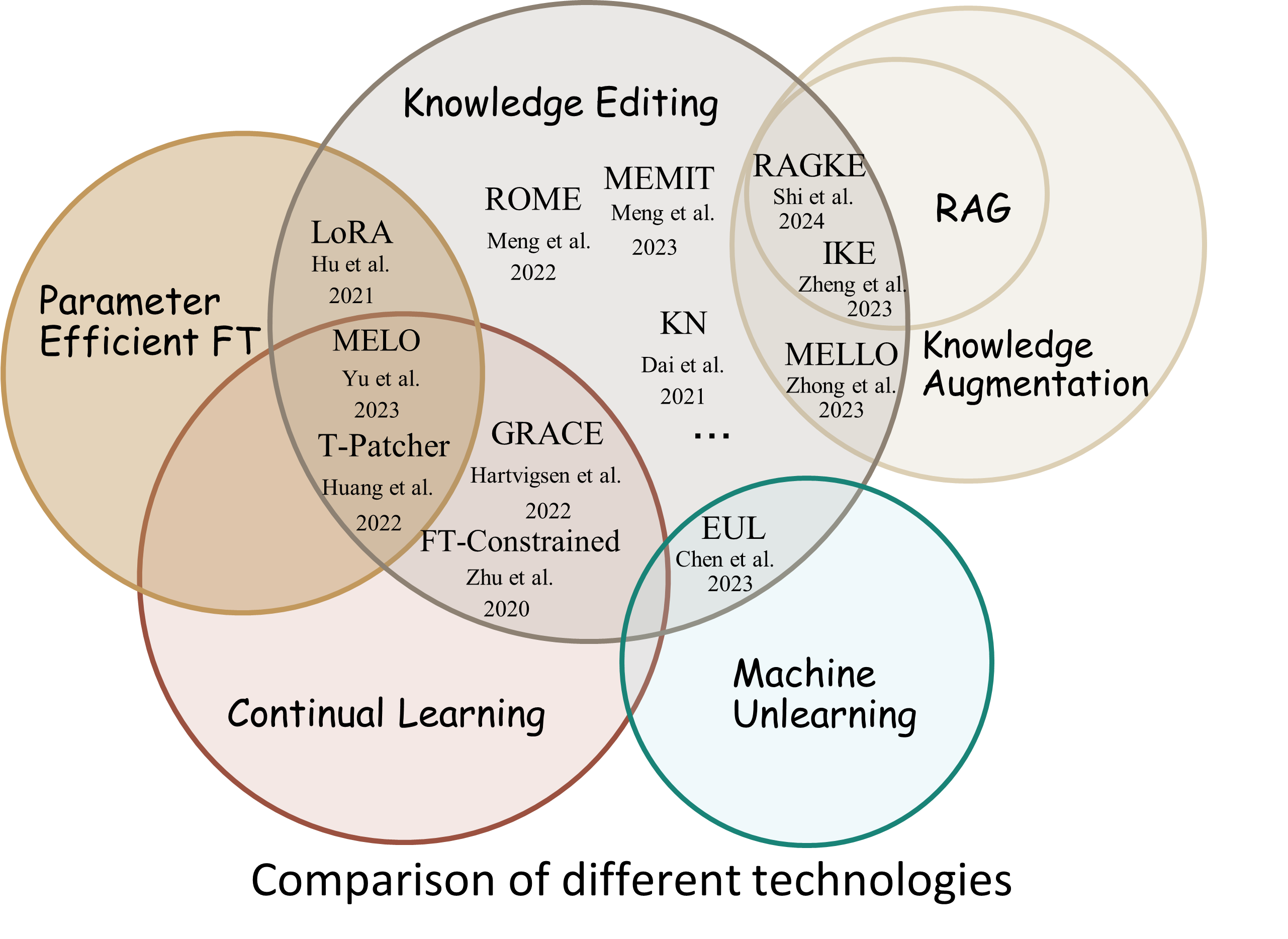
Proses pengeditan pengetahuan umumnya berdampak pada prediksi untuk serangkaian masukan luas yang terkait erat dengan contoh pengeditan, yang disebut cakupan pengeditan .
Pengeditan yang berhasil akan menyesuaikan perilaku model dalam cakupan pengeditan namun tetap menyisakan masukan yang tidak terkait:
Reliability : tingkat keberhasilan pengeditan dengan deskriptor pengeditan yang diberikanGeneralization : tingkat keberhasilan pengeditan dalam lingkup pengeditanLocality : apakah keluaran model berubah setelah diedit untuk masukan yang tidak terkaitPortability : tingkat keberhasilan pengeditan untuk penalaran/aplikasi (satu hop, sinonim, generalisasi logis)Efficiency : konsumsi waktu dan memori EasyEdit adalah paket Python untuk mengedit Model Bahasa Besar (LLM) seperti GPT-J , Llama , GPT-NEO , GPT2 , T5 (mendukung model dari 1B hingga 65B ), yang tujuannya adalah untuk mengubah perilaku LLM secara efisien dalam a domain tertentu tanpa berdampak negatif terhadap kinerja seluruh input lainnya. Ini dirancang agar mudah digunakan dan mudah diperluas.
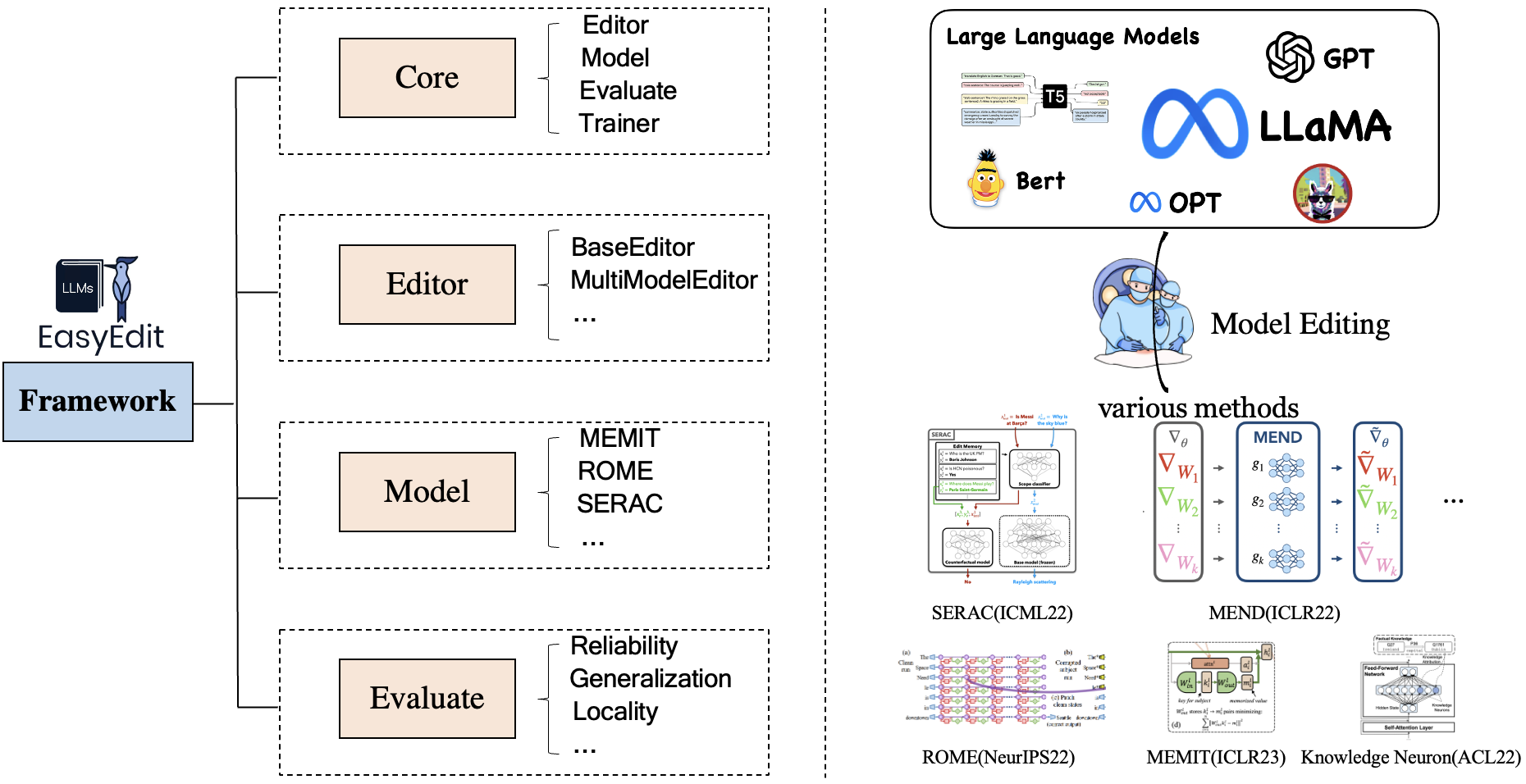
EasyEdit berisi kerangka kerja terpadu untuk Editor , Metode , dan Evaluasi , yang masing-masing mewakili skenario pengeditan, teknik pengeditan, dan metode evaluasi.
Setiap skenario Pengeditan Pengetahuan terdiri dari tiga komponen:
Editor : seperti BaseEditor ( Pengetahuan Faktual dan Editor Generasi ) untuk LM, MultiModalEditor ( Pengetahuan MultiModal ).Method : teknik pengeditan pengetahuan khusus yang digunakan (seperti ROMA , MEND , ..).Evaluate : Metrik untuk mengevaluasi kinerja pengeditan pengetahuan.Reliability , Generalization , Locality , PortabilityTeknik pengeditan pengetahuan yang didukung saat ini adalah sebagai berikut:
Catatan 1: Karena terbatasnya kompatibilitas perangkat ini, beberapa metode pengeditan pengetahuan termasuk T-Patcher, KE, CaliNet tidak didukung.
Catatan 2: Demikian pula, metode MALMEN hanya didukung sebagian karena alasan yang sama dan akan terus ditingkatkan.
Anda dapat memilih metode pengeditan yang berbeda sesuai dengan kebutuhan spesifik Anda.
| Metode | T5 | GPT-2 | GPT-J | GPT-NEO | llaMA | Baichuan | ObrolanGLM | MagangLM | Qwen | Mistral |
|---|---|---|---|---|---|---|---|---|---|---|
| FT | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| AdaLoRA | ✅ | ✅ | ||||||||
| SERAC | ✅ | ✅ | ✅ | ✅ | ||||||
| seperti | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| MEMPERBAIKI | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| buku | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| ROMA | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| r-ROMA | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| MEMIT | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| SEMUT | ✅ | ✅ | ✅ | |||||||
| BERKAH | ✅ | ✅ | ✅ | |||||||
| MELO | ✅ | |||||||||
| PMET | ✅ | ✅ | ||||||||
| InstruksikanSunting | ✅ | ✅ | ||||||||
| DINM | ✅ | ✅ | ✅ | |||||||
| BIJAK | ✅ | ✅ | ✅ | ✅ | ✅ | |||||
| AlfaSunting | ✅ | ✅ | ✅ |
❗️❗️ Jika Anda ingin menggunakan Mistral, harap perbarui perpustakaan
transformerske versi 4.34.0 secara manual. Anda dapat menggunakan kode berikut:pip install transformers==4.34.0.
| Bekerja | Keterangan | Jalur |
|---|---|---|
| InstruksikanSunting | InstructEdit: Pengeditan Pengetahuan Berbasis Instruksi untuk Model Bahasa Besar | Mulai Cepat |
| DINM | Detoksifikasi Model Bahasa Besar melalui Pengeditan Pengetahuan | Mulai Cepat |
| BIJAK | WISE: Memikirkan Kembali Memori Pengetahuan untuk Pengeditan Model Seumur Hidup Model Bahasa Besar | Mulai Cepat |
| KonsepSunting | Mengedit Pengetahuan Konseptual untuk Model Bahasa Besar | Mulai Cepat |
| MMSunting | Bisakah Kita Mengedit Model Bahasa Besar Multimodal? | Mulai Cepat |
| KepribadianSunting | Mengedit Kepribadian Untuk Model Bahasa Besar | Mulai Cepat |
| MENGINGATKAN | Metode pengeditan pengetahuan berbasis PROMPT | Mulai Cepat |
Tolok Ukur: KnowEdit [Memeluk Wajah] [WiseModel] [ModelScope]
❗️❗️ Perlu dicatat, KnowEdit dibangun dengan mengatur ulang dan memperluas kumpulan data yang ada termasuk WikiBio , ZsRE , WikiData Counterfact , WikiData Terkini , convsent , Sanitation untuk membuat evaluasi komprehensif untuk pengeditan pengetahuan. Terima kasih khusus kepada pembuat dan pengelola kumpulan data tersebut.
Harap dicatat bahwa Counterfact dan WikiData Counterfact bukanlah kumpulan data yang sama.
| Tugas | Penyisipan Pengetahuan | Modifikasi Pengetahuan | Penghapusan Pengetahuan | |||
|---|---|---|---|---|---|---|
| Kumpulan data | Wiki terbaru | ZsRE | WikiBio | Kontrafakta WikiData | setuju | Kebersihan |
| Jenis | Fakta | Menjawab Pertanyaan | Halusinasi | Penangkal fakta | Sentimen | Info yang Tidak Diinginkan |
| # Kereta | 570 | 10.000 | 592 | 1.455 | 14.390 | 80 |
| # Tes | 1.266 | 1301 | 1.392 | 885 | 800 | 80 |
Kami menyediakan skrip terperinci agar pengguna dapat dengan mudah menggunakan KnowEdit, silakan merujuk ke contoh.
knowedit
├── WikiBio
│ ├── wikibio-test-all.json
│ └── wikibio-train-all.json
├── ZsRE
│ └── ZsRE-test-all.json
├── wiki_counterfact
│ ├── test_cf.json
│ └── train_cf.json
├── convsent
│ ├── blender_test.json
│ ├── blender_train.json
│ └── blender_val.json
├── convsent
│ ├── trivia_qa_test.json
│ └── trivia_qa_train.json
└── wiki_recent
├── recent_test.json
└── recent_train.json
| kumpulan data | Memeluk Wajah | Model Bijaksana | Lingkup Model | Keterangan |
|---|---|---|---|---|
| CKnowSunting | [Memeluk Wajah] | [Model Bijaksana] | [ModelScope] | kumpulan data untuk mengedit Pengetahuan Cina |
CKnowEdit adalah kumpulan data berbahasa Mandarin berkualitas tinggi untuk pengeditan pengetahuan yang sangat bercirikan bahasa Mandarin, dengan semua data bersumber dari basis pengetahuan Tiongkok. Hal ini dirancang dengan cermat untuk melihat lebih dalam nuansa dan tantangan yang melekat dalam pemahaman bahasa Mandarin oleh LLM saat ini, memberikan sumber daya yang kuat untuk menyempurnakan pengetahuan khusus bahasa Mandarin dalam LLM.
Deskripsi bidang untuk data di CKnowEdit adalah sebagai berikut:
"prompt" : query inputed to the model ( str )
"target_old" : the incorrect response previously generated by the model ( str )
"target_new" : the accurate answer of the prompt ( str )
"portability_prompt" : new prompts related to the target knowledge ( list or None )
"portability_answer" : accurate answers corresponding to the portability_prompt ( list or None )
"locality_prompt" : new prompts unrelated to the target knowledge ( list or None )
"locality_answer" : accurate answers corresponding to the locality_prompt ( list or None )
"rephrase" : alternative ways to phrase the original prompt ( list ) CknowEdit
├── Chinese Literary Knowledge
│ ├── Ancient Poetry
│ ├── Proverbs
│ └── Idioms
├── Chinese Linguistic Knowledge
│ ├── Phonetic Notation
│ └── Classical Chinese
├── Chinese Geographical Knowledge
└── Ruozhiba
| kumpulan data | Google Drive | BaiduNetDisk | Keterangan |
|---|---|---|---|
| ZsRE ditambah | [Google Drive] | [BaiduNetDisk] | Kumpulan data Menjawab Pertanyaan menggunakan penyusunan ulang pertanyaan |
| Kontrafakta plus | [Google Drive] | [BaiduNetDisk] | Kumpulan data tandingan menggunakan penggantian Entitas |
Kami menyediakan kumpulan data zsre dan counterfact untuk memverifikasi efektivitas pengeditan pengetahuan. Anda dapat mengunduhnya di sini. [Google Drive], [BaiduNetDisk].
editing-data
├── counterfact
│ ├── counterfact-edit.json
│ ├── counterfact-train.json
│ └── counterfact-val.json
├── locality
│ ├── Commonsense Task
│ │ ├── piqa_valid-labels.lst
│ │ └── piqa_valid.jsonl
│ ├── Distracting Neighbor
│ │ └── counterfact_distracting_neighbor.json
│ └── Other Attribution
│ └── counterfact_other_attribution.json
├── portability
│ ├── Inverse Relation
│ │ └── zsre_inverse_relation.json
│ ├── One Hop
│ │ ├── counterfact_portability_gpt4.json
│ │ └── zsre_mend_eval_portability_gpt4.json
│ └── Subject Replace
│ ├── counterfact_subject_replace.json
│ └── zsre_subject_replace.json
└── zsre
├── zsre_mend_eval.json
├── zsre_mend_train_10000.json
└── zsre_mend_train.json
spouse| kumpulan data | Google Drive | Kumpulan Data HuggingFace | Keterangan |
|---|---|---|---|
| KonsepSunting | [Google Drive] | [Kumpulan Data HuggingFace] | kumpulan data untuk mengedit pengetahuan konseptual |
data
└──concept_data.json
├──final_gpt2_inter.json
├──final_gpt2_intra.json
├──final_gptj_inter.json
├──final_gptj_intra.json
├──final_llama2chat_inter.json
├──final_llama2chat_intra.json
├──final_mistral_inter.json
└──final_mistral_intra.json
Metrik Evaluasi Spesifik Konsep
Instance Change : menangkap seluk-beluk perubahan tingkat instance iniConcept Consistency : kesamaan semantik dari definisi konsep yang dihasilkan | kumpulan data | Google Drive | BaiduNetDisk | Keterangan |
|---|---|---|---|
| E-IC | [Google Drive] | [BaiduNetDisk] | kumpulan data untuk mengedit Keterangan Gambar |
| E-VQA | [Google Drive] | [BaiduNetDisk] | kumpulan data untuk mengedit Visual Question Answering |
editing-data
├── caption
│ ├── caption_train_edit.json
│ └── caption_eval_edit.json
├── locality
│ ├── NQ dataset
│ │ ├── train.json
│ │ └── validation.json
├── multimodal_locality
│ ├── OK-VQA dataset
│ │ ├── okvqa_loc.json
└── vqa
├── vqa_train.json
└── vqa_eval.json
| kumpulan data | Kumpulan Data HuggingFace | Keterangan |
|---|---|---|
| AmanSunting | [Kumpulan Data HuggingFace] | kumpulan data untuk detoksifikasi LLM |
data
└──SafeEdit_train.json
└──SafeEdit_val.json
└──SafeEdit_test.json
Detoksifikasi Metrik Evaluasi Spesifik
Defense Duccess (DS) : tingkat keberhasilan detoksifikasi LLM yang diedit untuk masukan permusuhan (perintah serangan + pertanyaan berbahaya), yang digunakan untuk memodifikasi LLM.Defense Generalization (DG) : tingkat keberhasilan detoksifikasi LLM yang diedit untuk masukan berbahaya di luar domain.General Performance : efek samping untuk kinerja tugas yang tidak terkait. | Metode | Keterangan | GPT-2 | LlaMA |
|---|---|---|---|
| seperti | Pembelajaran Dalam Konteks (ICL) Sunting | [Colab-gpt2] | [Colab-lama] |
| ROMA | Temukan-Kemudian-Edit Neuron | [Colab-gpt2] | [Colab-lama] |
| MEMIT | Temukan-Kemudian-Edit Neuron | [Colab-gpt2] | [Colab-lama] |
Catatan: Silakan gunakan Python 3.9+ untuk EasyEdit Untuk memulai, cukup instal conda dan jalankan:
git clone https://github.com/zjunlp/EasyEdit.git
conda create -n EasyEdit python=3.9.7
...
pip install -r requirements.txtHasil kami semuanya didasarkan pada konfigurasi default
| llama-2-7B | obrolanglm2 | gpt-j-6b | gpt-xl | |
|---|---|---|---|---|
| FT | 60GB | 58GB | 55GB | 7GB |
| SERAC | 42GB | 32GB | 31GB | 10GB |
| seperti | 52GB | 38GB | 38GB | 10GB |
| MEMPERBAIKI | 46GB | 37GB | 37GB | 13GB |
| buku | 42GB | 39GB | 40GB | 12GB |
| ROMA | 31GB | 29GB | 27GB | 10GB |
| MEMIT | 33GB | 31GB | 31GB | 11GB |
| AdaLoRA | 29GB | 24GB | 25GB | 8GB |
| BERKAH | 27GB | 23GB | 6GB | |
| BIJAK | 34GB | 27GB | 7GB |
Edit model bahasa besar (LLM) sekitar 5 detik
Contoh berikut menunjukkan cara melakukan pengeditan dengan EasyEdit. Contoh dan tutorial lainnya dapat ditemukan di contoh
BaseEditoradalah kelas untuk Pengeditan Pengetahuan Modalitas Bahasa. Anda dapat memilih metode pengeditan yang sesuai berdasarkan kebutuhan spesifik Anda.
Dengan modularitas dan fleksibilitas EasyEdit , Anda dapat dengan mudah menggunakannya untuk mengedit model.
Langkah 1: Tentukan PLM sebagai objek yang akan diedit. Pilih PLM yang akan diedit. EasyEdit mendukung sebagian model ( T5 , GPTJ , GPT-NEO , LlaMA sejauh ini) yang dapat diambil di HuggingFace. Direktori file konfigurasi yang sesuai adalah hparams/YUOR_METHOD/YOUR_MODEL.YAML , seperti hparams/MEND/gpt2-xl.yaml , atur model_name yang sesuai untuk memilih objek untuk pengeditan pengetahuan.
model_name : gpt2-xl
model_class : GPT2LMHeadModel
tokenizer_class : GPT2Tokenizer
tokenizer_name : gpt2-xl
model_parallel : false # true for multi-GPU editingLangkah 2: Pilih Metode Pengeditan Pengetahuan yang sesuai
## In this case, we use MEND method, so you should import `MENDHyperParams`
from easyeditor import MENDHyperParams
## Loading config from hparams/MEMIT/gpt2-xl.yaml
hparams = MENDHyperParams . from_hparams ( './hparams/MEND/gpt2-xl' )Langkah3: Berikan deskriptor edit dan target edit
## edit descriptor: prompt that you want to edit
prompts = [
'What university did Watts Humphrey attend?' ,
'Which family does Ramalinaceae belong to' ,
'What role does Denny Herzig play in football?'
]
## You can set `ground_truth` to None !!!(or set to original output)
ground_truth = [ 'Illinois Institute of Technology' , 'Lecanorales' , 'defender' ]
## edit target: expected output
target_new = [ 'University of Michigan' , 'Lamiinae' , 'winger' ] Langkah4: Gabungkan keduanya menjadi BaseEditor EasyEdit menyediakan cara sederhana dan terpadu untuk init Editor , seperti huggingface: from_hparams .
## Construct Language Model Editor
editor = BaseEditor . from_hparams ( hparams )Langkah 5: Menyediakan data untuk evaluasi Perhatikan bahwa data untuk portabilitas dan lokalitas bersifat opsional (setel ke Tidak Ada untuk evaluasi tingkat keberhasilan pengeditan dasar saja). Format data untuk keduanya adalah dict , untuk setiap dimensi pengukuran, Anda perlu memberikan prompt yang sesuai dan kebenaran dasar yang sesuai. Berikut ini contoh datanya:
locality_inputs = {
'neighborhood' :{
'prompt' : [ 'Joseph Fischhof, the' , 'Larry Bird is a professional' , 'In Forssa, they understand' ],
'ground_truth' : [ 'piano' , 'basketball' , 'Finnish' ]
},
'distracting' : {
'prompt' : [ 'Ray Charles, the violin Hauschka plays the instrument' , 'Grant Hill is a professional soccer Magic Johnson is a professional' , 'The law in Ikaalinen declares the language Swedish In Loviisa, the language spoken is' ],
'ground_truth' : [ 'piano' , 'basketball' , 'Finnish' ]
}
}Dalam contoh di atas, kami mengevaluasi kinerja metode pengeditan tentang "lingkungan" dan "mengganggu".
Langkah6: Edit dan Evaluasi Selesai! Kami dapat melakukan Edit dan Evaluasi untuk model Anda yang akan diedit. Fungsi edit akan mengembalikan serangkaian metrik yang terkait dengan proses pengeditan serta bobot model yang dimodifikasi. [ sequential_edit=True untuk pengeditan berkelanjutan]
metrics , edited_model , _ = editor . edit (
prompts = prompts ,
ground_truth = ground_truth ,
target_new = target_new ,
locality_inputs = locality_inputs ,
sequential_edit = False # True: start continuous editing ✈️
)
## metrics: edit success, rephrase success, locality e.g.
## edited_model: post-edit modelPanjang masukan maksimum untuk EasyEdit adalah 512. Jika panjang ini terlampaui, Anda akan mengalami kesalahan "Kesalahan CUDA: pernyataan sisi perangkat dipicu". Anda dapat mengubah panjang maksimum pada file berikut:LINK
Langkah 7: Kembalikan Dalam pengeditan berurutan, jika Anda tidak puas dengan hasil salah satu pengeditan Anda dan tidak ingin kehilangan pengeditan sebelumnya, Anda dapat menggunakan fitur rollback untuk membatalkan pengeditan sebelumnya. Saat ini, kami hanya mendukung metode GRACE. Yang perlu Anda lakukan hanyalah satu baris kode, menggunakan edit_key untuk mengembalikan hasil edit Anda.
editor.rolllback('edit_key')
Di EasyEdit, kami secara default menggunakan target_new sebagai kunci_edit
Kami menentukan metrik pengembalian sebagai format dict , termasuk evaluasi prediksi model sebelum dan sesudah pengeditan. Untuk setiap pengeditan, metrik berikut akan disertakan:
rewrite_acc rephrase_acc locality portablility 

