mengzi retrieval lm
1.0.0
Di Langboat Technology, kami fokus pada peningkatan model terlatih agar lebih ringan guna memenuhi kebutuhan industri nyata. Pendekatan berbasis pengambilan (seperti RETRO, REALM, dan RAG) sangat penting untuk mencapai tujuan ini.
Repositori ini merupakan implementasi eksperimental dari model bahasa yang disempurnakan dengan pengambilan. Saat ini, ini hanya mendukung pemasangan pengambilan di GPT-Neo.
Kami melakukan fork Huggingface Transformers dan lm-evaluation-harness untuk menambahkan dukungan pengambilan. Bagian pengindeksan diimplementasikan sebagai server HTTP untuk memisahkan pengambilan dan pelatihan dengan lebih baik.
Sebagian besar implementasi model disalin dari RETRO-pytorch dan GPT-Neo. Kami menggunakan transformers-cli untuk menambahkan model baru bernama Re_gptForCausalLM berdasarkan GPT-Neo, lalu menambahkan bagian pengambilan ke dalamnya.
Kami mengunggah model yang dipasang pada EleutherAI/gpt-neo-125M menggunakan perpustakaan pengambilan 200G.
Anda dapat menginisialisasi model seperti ini:
from transformers import Re_gptForCausalLM
model = Re_gptForCausalLM . from_pretrained ( 'Langboat/ReGPT-125M-200G' )Dan evaluasi modelnya seperti ini:
python main.py
--model retrieval
--model_args pretrained=model_path
--device 0
--tasks wikitext,lambada,winogrande,mathqa,pubmedqa
--batch_size 1Kami menghitung kesamaan menggunakan penyematan kalimat_transformer sebagai representasi teks. Anda dapat menginisialisasi model Kalimat-BERT seperti ini:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer ( 'all-MiniLM-L12-v2' )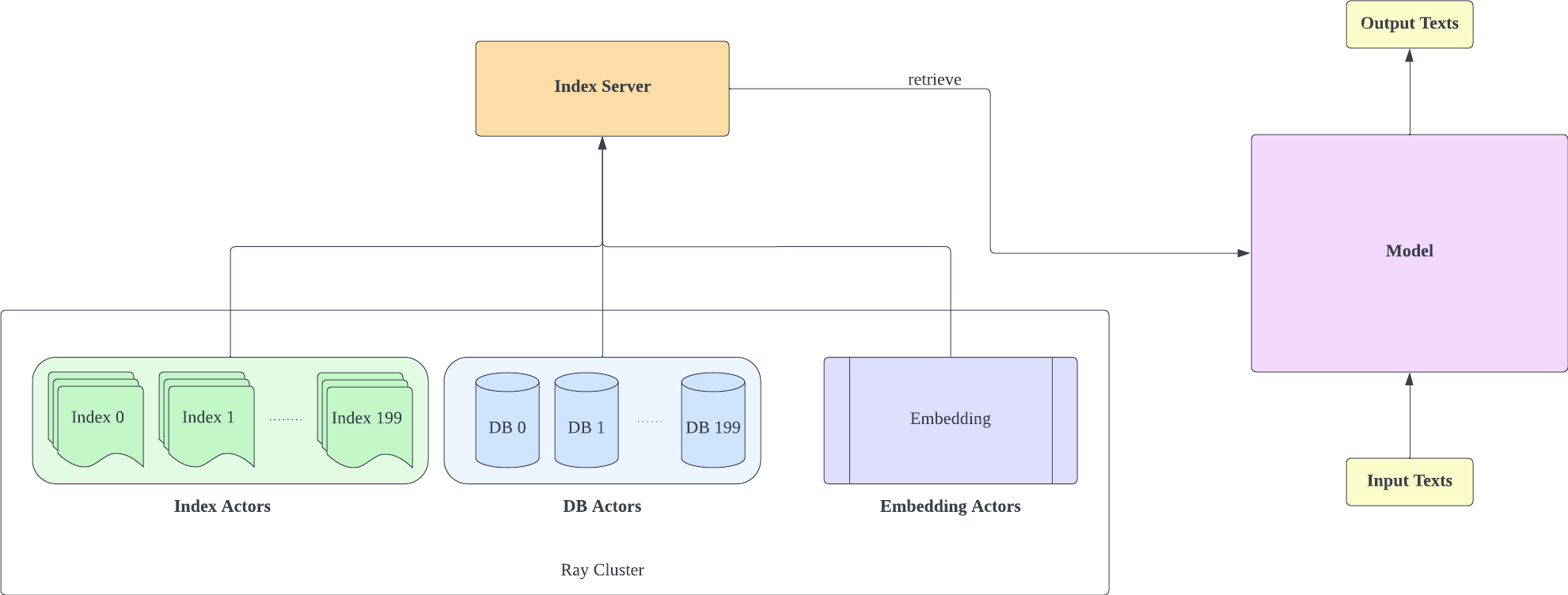
conda create -n mengzi-retrieval-fit python=3.7
conda activate mengzi-retrieval-fit
conda install pytorch torchvision torchaudio cudatoolkit=11.1 -c pytorch-lts -c nvidia
git clone https://github.com/Langboat/mengzi-retrieval-lm.git
cd mengzi-retrieval-lm
git submodule update --init --recursive
pip install -r requirement.txt
cd transformers/
pip install -e .
cd ..
python -c " from sentence_transformers import SentenceTransformer; model = SentenceTransformer('all-MiniLM-L12-v2') " Menggunakan IVF1024PQ48 sebagai pabrik indeks faiss, kami mengunggah indeks dan database ke hub model pelukan, yang dapat diunduh menggunakan perintah berikut.
Di download_index_db.py, Anda dapat menentukan jumlah indeks dan database yang ingin Anda unduh.
python -u download_index_db.py --num 200Anda dapat mengunduh model yang dipasang secara manual dari sini: https://huggingface.co/Langboat/ReGPT-125M-200G
Server indeks didasarkan pada FastAPI dan Ray. Dengan Ray's Actor, tugas-tugas komputasi intensif dienkapsulasi secara asinkron, memungkinkan kami memanfaatkan sumber daya CPU dan GPU secara efisien hanya dengan satu instance server FastAPI. Anda dapat menginisialisasi server indeks seperti ini:
cd index-server/
ray start --head
python -u api.py
--config config_IVF1024PQ48.json
--db_path ../db/models—Langboat—Pile-DB/snapshots/fd35bcce75db5c1b7385a28018029f7465b4e966
- Perlu diingat bahwa jumlah shard konfigurasi IVF1024PQ48.json harus sesuai dengan jumlah indeks yang diunduh. Anda dapat melihat nomor indeks yang diunduh saat ini di bawah db_path
- Konfigurasi ini telah diuji pada A100-40G, jadi jika Anda memiliki GPU yang berbeda, kami sarankan untuk menyesuaikannya dengan perangkat keras Anda.
- Setelah menerapkan server indeks, Anda perlu memodifikasi request_server di lm-evaluation-harness/config.json dan train/config.json .
- Anda dapat mengurangi encoder_actor_count di config_IVF1024PQ48.json untuk mengurangi sumber daya memori yang diperlukan.
· db_path:lokasi pengunduhan database dari huggingface. "../db/models—Langboat—Pile-DB/snapshots/fd35bcce75db5c1b7385a28018029f7465b4e966" adalah sebuah contoh.
Perintah ini akan mengunduh database dan mengindeks data dari huggingface.
Ubah folder indeks di file konfigurasi (config IVF1024PQ48) agar mengarah ke jalur folder indeks, dan kirim snapshot folder database sebagai jalur db ke skrip api.py.
Hentikan server indeks dengan perintah berikut
ray stop
- Ingatlah bahwa Anda harus tetap mengaktifkan server indeks selama pelatihan, evaluasi, dan inferensi
Gunakan train/train.py untuk mengimplementasikan pelatihan; train/config.json dapat dimodifikasi untuk mengubah parameter pelatihan.
Anda dapat menginisialisasi pelatihan seperti ini:
cd train
python -u train.py
- Karena server indeks perlu menggunakan sumber daya memori, Anda sebaiknya menerapkan server indeks dan pelatihan model pada GPU yang berbeda
Gunakan train/inference.py sebagai inferensi untuk menentukan hilangnya teks dan kebingungannya.
cd train
python -u inference.py
--model_path Langboat/ReGPT-125M-200G
--file_name data/test_data.json
- Test_data.json dan train_data.json di folder data saat ini merupakan format file yang didukung, Anda dapat mengubah data ke format ini.
Gunakan lm-evaluation-harness sebagai metode evaluasi
Kami menetapkan seq_len dari lm-evaluation-harness ke 1025 sebagai pengaturan awal untuk perbandingan model karena seq_len pelatihan model kami adalah 1025.
cd lm-evaluation-harness
python setup.py installpython main.py
--model retrieval
--model_args pretrained=Langboat/ReGPT-125M-200G
--device 0
--tasks wikitext
--batch_size 1· model_path:jalur model yang sesuai
python main.py
--model gpt2
--model_args pretrained=EleutherAI/gpt-neo-125M
--device 0
--tasks wikitext
--batch_size 1Hasil evaluasinya adalah sebagai berikut
| model | teks wiki word_perplexity |
|---|---|
| EleutherAI/gpt-neo-125M | 35.8774 |
| Langboat/ReGPT-125M-200G | 22.115 |
| EleutherAI/gpt-neo-1.3B | 17.6979 |
| Langboat/ReGPT-125M-400G | 14.1327 |
@software { mengzi-retrieval-lm-library ,
title = { {Mengzi-Retrieval-LM} } ,
author = { Wang, Yulong and Bo, Lin } ,
url = { https://github.com/Langboat/mengzi-retrieval-lm } ,
month = { 9 } ,
year = { 2022 } ,
version = { 0.0.1 } ,
}

