GraphGPT: Pembelajaran Grafik dengan Transformator Terlatih Generatif
Repositori ini adalah implementasi resmi dari “GraphGPT: Pembelajaran Grafik dengan Transformator Terlatih Generatif” di PyTorch.
GraphGPT: Pembelajaran Grafik dengan Transformator Terlatih Generatif
Qifang Zhao, Weidong Ren, Tianyu Li, Xiaoxiao Xu, Hong Liu
Memperbarui:
13/10/2024
- v0.4.0 dirilis. Periksa
CHANGELOG.md untuk detailnya. - Mencapai SOTA dalam 3 kumpulan data ogb skala besar:
- PCQM4M-v2 (tanpa 3D): 0,0802 (SOTA sebelumnya 0,0821)
- ogbl-ppa: 68.76 (SOTA sebelumnya 65.24)
- ogbl-cititation2: 91.15 (sebelumnya SOTA 90.72)
18/08/2024
- v0.3.1 dirilis. Periksa
CHANGELOG.md untuk detailnya.
07/09/2024
- v0.3.0 dirilis.
19/03/2024
- v0.2.0 dirilis.
- Terapkan
permute_nodes untuk kumpulan data gaya peta tingkat grafik, untuk meningkatkan variasi jalur Euler, dan menghasilkan hasil yang lebih baik dan kuat. - Tambahkan
StackedGSTTokenizer sehingga token semantik (yaitu, node/edge attrs) dapat ditumpuk bersama dengan token struktural, dan panjang urutan akan berkurang banyak. - kode refaktor.
23/01/2024
- v0.1.1, memperbaiki bug paket common-io.
01/03/2024
- Rilis awal kode.
Arah Masa Depan
Hukum penskalaan: berapa batas penskalaan model GraphGPT?
- Seperti yang kita ketahui, GPT yang dilatih dengan data teks dapat menskalakan hingga ratusan miliar parameter, dan terus meningkatkan kemampuannya.
- Data teks dapat menyediakan triliunan token, memiliki kompleksitas yang sangat tinggi, serta memiliki banyak pengetahuan, termasuk pengetahuan sosial dan alam.
- Sebaliknya, data grafik tanpa atribut node/edge hanya berisi informasi struktur yang cukup terbatas dibandingkan dengan data teks. Sebagian besar informasi tersembunyi (misalnya derajat, jumlah substruktur, dan lain-lain) di belakang struktur dapat dihitung secara tepat menggunakan paket seperti networkx. Oleh karena itu, informasi dari struktur grafik mungkin tidak dapat mendukung penskalaan ukuran model hingga miliaran parameter.
- Eksperimen awal kami dengan berbagai kumpulan data grafik skala besar menunjukkan bahwa kami dapat menskalakan GraphGPT hingga 400 juta+ parameter dengan peningkatan kinerja. Tapi kami tidak bisa meningkatkan hasilnya lebih jauh. Ini mungkin karena eksperimen kami yang tidak memadai. Namun mungkin saja keterbatasan yang melekat pada data grafik menyebabkan hal ini.
- Kumpulan data grafik besar (baik satu grafik besar atau grafik kecil dalam jumlah besar) dengan atribut node/edge mungkin dapat memberikan informasi yang cukup bagi kita untuk melatih model GraphGPT yang besar. Meski begitu, satu kumpulan data grafik mungkin tidak cukup, dan kita mungkin perlu mengumpulkan berbagai kumpulan data grafik untuk melatih satu GraphGPT.
- Masalahnya di sini adalah bagaimana mendefinisikan tokenizer universal untuk atribut edge/node dari berbagai kumpulan data grafik.
Data grafik berkualitas tinggi: Apa yang dimaksud dengan data grafik berkualitas tinggi untuk melatih GraphGPT untuk tugas-tugas umum?
- Misalnya, jika kita ingin melatih satu model untuk semua jenis pemahaman molekul dan tugas pembangkitan, jenis data apa yang akan kita gunakan?
- Dari penyelidikan awal kami, kami menambahkan ZINC (4,6M) dan CEPDB (2,3M) ke pra-pelatihan, tidak menemukan adanya keuntungan saat menyempurnakan PCQM4M-v2 untuk tugas prediksi kesenjangan homo-lumo. Kemungkinan alasannya adalah sebagai berikut:
- #struktur# Pola grafik di balik grafik molekul relatif sederhana.
- Pola grafik seperti rantai atau cincin 5/6 simpul sangat umum.
- Rata-rata terdapat 2 tepi per titik simpul, artinya atom mempunyai rata-rata 2 ikatan.
- #semantik# Aturan kimia untuk membentuk molekul kecil organik sederhana saja: atom karbon memiliki 4 ikatan, atom nitrogen memiliki 3 ikatan, atom oksigen memiliki 2 ikatan, dan atom hidrogen memiliki 1 ikatan, dan seterusnya. Sederhananya, selama kita dapat memenuhi jumlah ikatan atom, kita dapat menghasilkan molekul apa pun.
- Aturan dari struktur dan semantik sangat sederhana sehingga model medium pun dapat belajar dari kumpulan data berukuran sedang. Jadi menambahkan data tambahan tidak membantu. Kami melakukan pra-pelatihan model kecil/menengah/basis/besar menggunakan data molekul 3,7 juta, dan kerugiannya hampir sama, yang menunjukkan terbatasnya keuntungan dari memperbesar ukuran model pada tahap pra-pelatihan.
- Kedua, jika kita ingin melatih satu model untuk semua jenis tugas pemahaman struktur grafik, jenis data apa yang harus kita gunakan?
- Haruskah kita menggunakan data grafik asli dari jejaring sosial, jaringan kutipan, dan lain-lain, atau hanya menggunakan data grafik sintetis, seperti grafik acak Erdos-Renyi?
- Eksperimen awal kami menunjukkan bahwa penggunaan grafik acak untuk melakukan pra-pelatihan GraphGPT berguna bagi model untuk memahami struktur grafik, tetapi model ini tidak stabil. Kami menduga hal ini terkait dengan distribusi struktur grafik pada tahap pra-pelatihan dan penyempurnaan. Misalnya, jika mereka memiliki jumlah tepi per node yang sama, jumlah node yang sama, maka paradigma pra-pelatihan & penyempurnaan berfungsi dengan baik.
- #Universalitas# Jadi, bagaimana cara melatih model GraphGPT untuk memahami struktur grafik apa pun secara universal?
- Hal ini kembali ke pertanyaan sebelumnya tentang hukum penskalaan: data grafik apa yang tepat dan berkualitas tinggi untuk terus meningkatkan GraphGPT sehingga dapat melakukan berbagai tugas grafik dengan baik?
Few-shot: Bisakah GraphGPT memperoleh kemampuan beberapa-shot?
- Jika memungkinkan, bagaimana merancang data pelatihan agar GraphGPT dapat mempelajarinya?
- Dari percobaan awal kami dengan kumpulan data PCQM4M-v2, tidak sedikit kemampuan pembelajaran yang diamati! Namun bukan berarti tidak bisa. Hal ini mungkin disebabkan oleh beberapa alasan berikut:
- Modelnya tidak cukup besar. Kami menggunakan model dasar dengan ~100 juta parameter.
- Data pelatihan tidak cukup. Kami hanya menggunakan 3,7 juta molekul, yang hanya menyediakan token terbatas untuk pelatihan.
- Format data pelatihan tidak cocok bagi model untuk memperoleh kemampuan beberapa langkah.
Ringkasan:

Kami mengusulkan GraphGPT, model baru untuk pembelajaran Grafik oleh Pra-pelatihan Generatif Graph Eulerian Transformers (GET) yang diawasi sendiri. Kami pertama kali memperkenalkan GET, yang terdiri dari tulang punggung encoder/decoder transformator vanilla dan transformasi yang mengubah setiap grafik atau subgraf sampel menjadi urutan token yang mewakili node, tepi, dan atribut secara reversibel menggunakan jalur Euler. Kemudian kita melakukan pra-pelatihan GET dengan tugas prediksi token berikutnya (NTP) atau tugas prediksi token bertopeng terjadwal (SMTP). Terakhir, kami menyempurnakan model dengan tugas-tugas yang diawasi. Model intuitif namun efektif ini mencapai hasil yang unggul atau mendekati metode canggih untuk tugas tingkat grafik, tepi, dan simpul pada kumpulan data molekuler skala besar PCQM4Mv2, kumpulan data asosiasi protein-protein ogbl-ppa , kumpulan data jaringan kutipan ogbl-cite2 dan kumpulan data ogbn-protein dari Open Graph Benchmark (OGB). Selain itu, pra-pelatihan generatif memungkinkan kami melatih GraphGPT hingga parameter 2B+ dengan performa yang meningkat secara konsisten, yang berada di luar kemampuan GNN dan transformator grafik sebelumnya.
Grafik ke Urutan
Setelah mengonversi graf Euler menjadi barisan, ada beberapa cara berbeda untuk melampirkan atribut simpul dan tepi ke barisan. Kami menamakan metode ini sebagai short , long , dan prolonged .
Berdasarkan grafiknya, kita Eulerisasikan terlebih dahulu, lalu ubah menjadi barisan ekuivalen. Dan kemudian, kami mengindeks ulang node secara siklis.
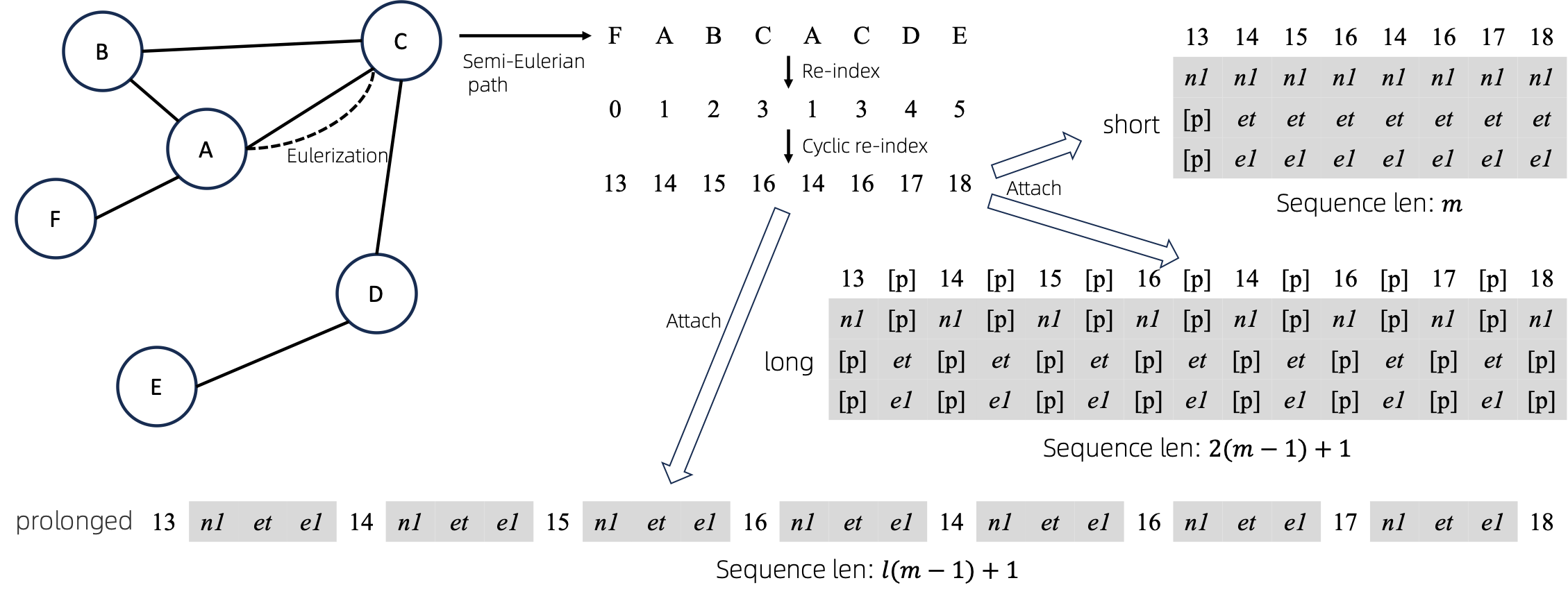
Asumsikan grafik memiliki satu atribut simpul dan satu atribut tepi, lalu metode short , long dan prolong ditunjukkan di atas.
Pada gambar di atas, n1 , n2 dan e1 mewakili token atribut node dan edge, dan [p] mewakili token padding.
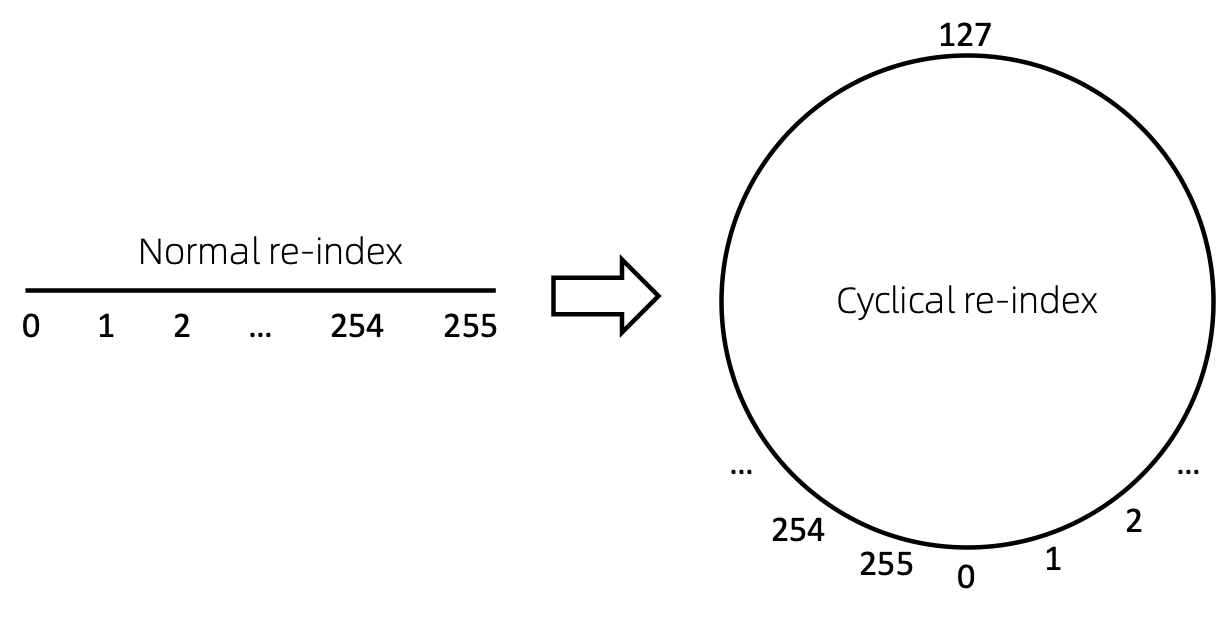
Indeks ulang simpul siklus
Cara mudah untuk mengindeks ulang urutan node adalah memulai dengan 0 dan menambahkan 1 secara bertahap. Dengan cara ini, token indeks kecil akan cukup terlatih, dan indeks besar tidak. Untuk mengatasi hal ini, kami mengusulkan cyclical re-index , yang dimulai dengan angka acak dalam rentang tertentu, katakanlah [0, 255] , dan kenaikan sebesar 1. Setelah mencapai batas, misalnya 255 , indeks simpul berikutnya akan menjadi 0 .
Hasil
Kedaluwarsa. Akan segera diperbarui.
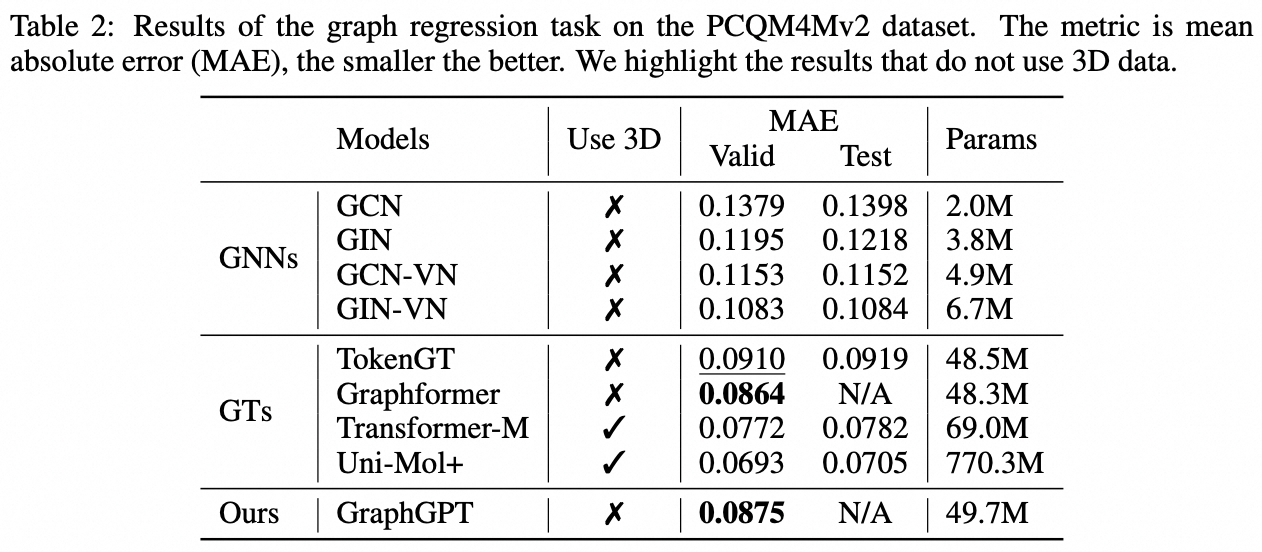
Tugas tingkat grafik: kumpulan data PCQM4M-v2
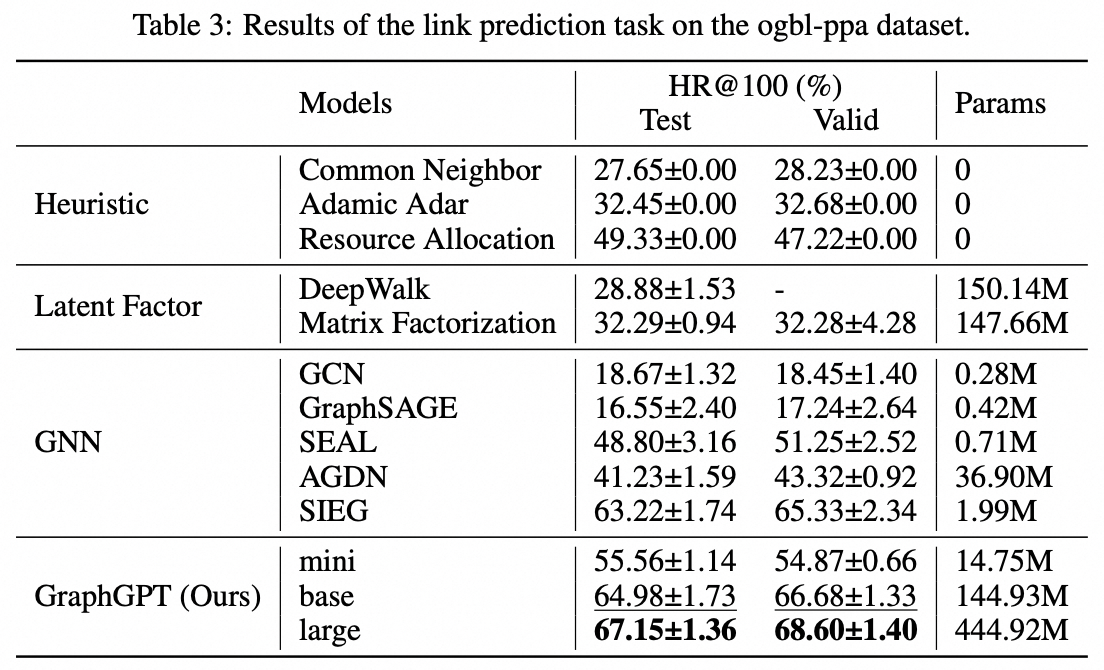
Tugas tingkat tepi: kumpulan data ogbl-ppa
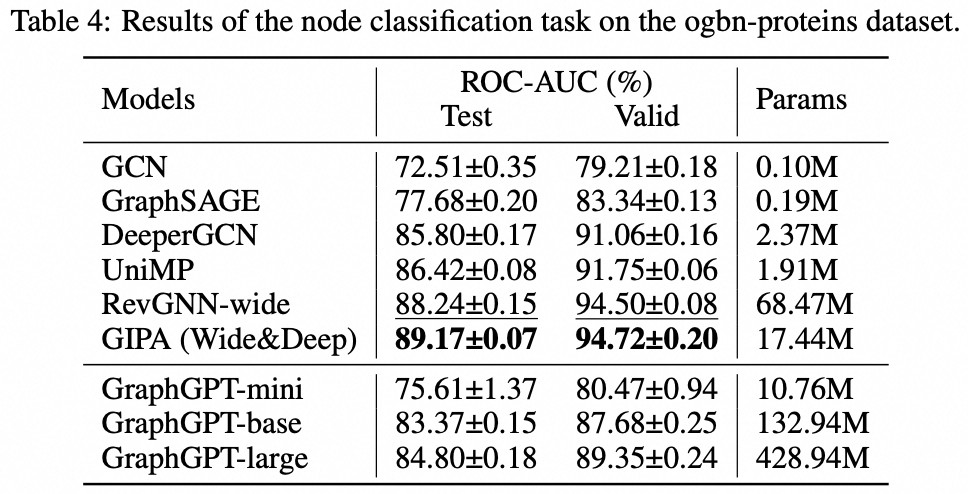
Tugas tingkat simpul: kumpulan data ogbn-protein
Instalasi
git clone https://github.com/alibaba/graph-gpt.git
- Instal dependensi di persyaratan.txt (Menggunakan Anaconda, diuji dengan py38, pytorch-1131 dan CUDA-11.7, 11.8 dan 12.1 pada GPU V100 dan A100)
conda create -n graph_gpt python=3.8 pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.7 -c pytorch -c nvidia
conda activate graph_gpt
cd graph-gpt
pip install -r ./requirements.txt
pip install torch-scatter torch-sparse -f https://data.pyg.org/whl/torch-1.13.1+cpu.html
sudo apt-get install bc
Kumpulan data
Kumpulan data diunduh menggunakan paket python ogb.
Saat Anda menjalankan skrip di ./examples , kumpulan data akan diunduh secara otomatis.
Namun, kumpulan data PCQM4M-v2 sangat besar, dan pengunduhan serta prapemrosesan mungkin menimbulkan masalah. Kami menyarankan cd ./src/utils/ dan python dataset_utils.py untuk mengunduh dan memproses dataset secara terpisah.
Berlari
- Pra-pelatihan: Ubah parameter dalam
./examples/graph_lvl/pcqm4m_v2_pretrain.sh , misalnya, dataset_name , model_name , batch_size , workerCount dan lain-lain, lalu jalankan ./examples/graph_lvl/pcqm4m_v2_pretrain.sh untuk melatih model terlebih dahulu dengan PCQM4M-v2 kumpulan data.- Untuk menjalankan contoh mainan, jalankan
./examples/toy_examples/reddit_pretrain.sh secara langsung.
- Sempurnakan: Ubah parameter dalam
./examples/graph_lvl/pcqm4m_v2_supervised.sh , misalnya, dataset_name , model_name , batch_size , workerCount , pretrain_cpt dan lain-lain, lalu jalankan ./examples/graph_lvl/pcqm4m_v2_supervised.sh untuk menyempurnakan tugas hilir .- Untuk menjalankan contoh mainan, jalankan
./examples/toy_examples/reddit_supervised.sh secara langsung.
Norma Kode
Pra-komitmen
- Periksa situs web resmi untuk detailnya
-
.pre-commit-config.yaml : buat file dengan konten berikut untuk python repos :
- repo : https://github.com/pre-commit/pre-commit-hooks
rev : v4.4.0
hooks :
- id : check-yaml
- id : end-of-file-fixer
- id : trailing-whitespace
- repo : https://github.com/psf/black
rev : 23.7.0
hooks :
- id : black
-
pre-commit install : instal pra-komit ke dalam git hooks Anda.- pra-komit sekarang akan berjalan pada setiap komit.
- Setiap kali Anda mengkloning proyek menggunakan pre-commit, menjalankan
pre-commit install harus selalu menjadi hal pertama yang Anda lakukan.
-
pre-commit run --all-files : menjalankan semua hook pre-commit pada repositori -
pre-commit autoupdate : perbarui kait Anda ke versi terbaru secara otomatis -
git commit -n : pemeriksaan pra-komit dapat dinonaktifkan untuk komit tertentu dengan perintah
Kutipan
Jika Anda merasa karya ini bermanfaat, silakan mengutip makalah berikut:
@article{zhao2024graphgpt,
title={GraphGPT: Graph Learning with Generative Pre-trained Transformers},
author={Zhao, Qifang and Ren, Weidong and Li, Tianyu and Xu, Xiaoxiao and Liu, Hong},
journal={arXiv preprint arXiv:2401.00529},
year={2024}
}Kontak
Qifang Zhao ([email protected])
Sangat menghargai saran Anda pada pekerjaan kami!
Lisensi
Dirilis di bawah lisensi MIT (lihat LICENSE ):
Ali-GraphGPT-project is an AI project on training large scale transformer decoder with graph datasets,
developed by Alibaba and licensed under the MIT License.


