LMOps
1.0.0
LMOps adalah inisiatif penelitian mengenai penelitian dan teknologi mendasar untuk membangun produk AI dengan model dasar, khususnya pada teknologi umum untuk memungkinkan kemampuan AI dengan LLM dan model AI Generatif.
Teknologi canggih yang memfasilitasi model bahasa prompt.
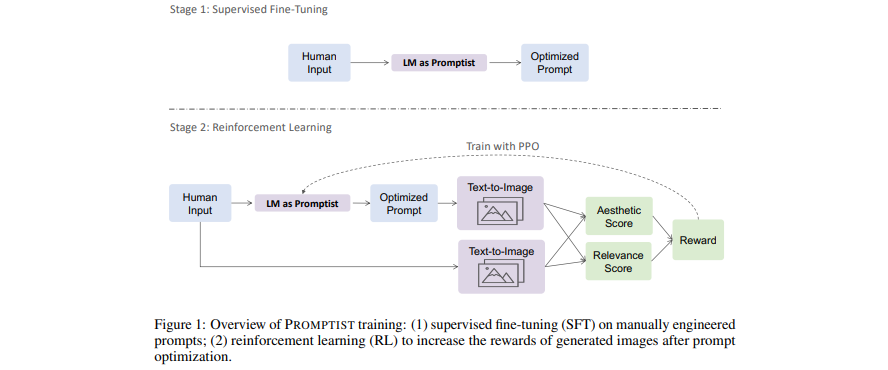
[Paper] Mengoptimalkan Anjuran untuk Pembuatan Teks-ke-Gambar
- Model bahasa berfungsi sebagai antarmuka cepat yang mengoptimalkan masukan pengguna ke dalam perintah pilihan model.
- Pelajari model bahasa untuk pengoptimalan cepat otomatis melalui pembelajaran penguatan.
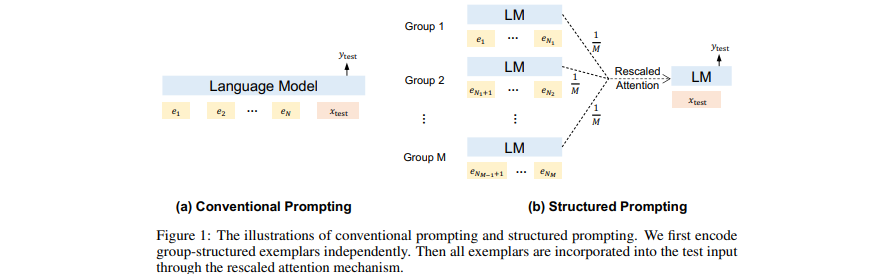
[Makalah] Anjuran Terstruktur: Menskalakan Pembelajaran Dalam Konteks menjadi 1.000 Contoh
- Tambahkan (banyak) dokumen (panjang) yang diambil sebagai konteks di GPT.
- Skalakan pembelajaran dalam konteks ke banyak contoh demonstrasi.
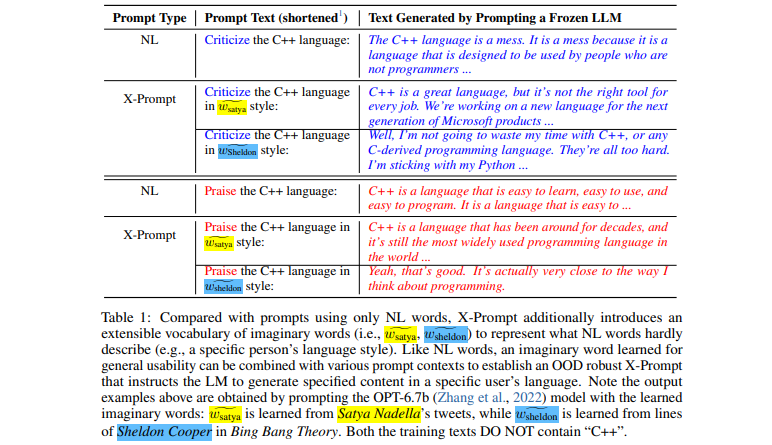
[Makalah] Anjuran yang Dapat Diperluas untuk Model Bahasa
- Antarmuka yang dapat diperluas memungkinkan mendorong LLM melampaui bahasa alami untuk spesifikasi yang lebih detail
- Pembelajaran kata imajiner yang dipandu konteks untuk kegunaan umum
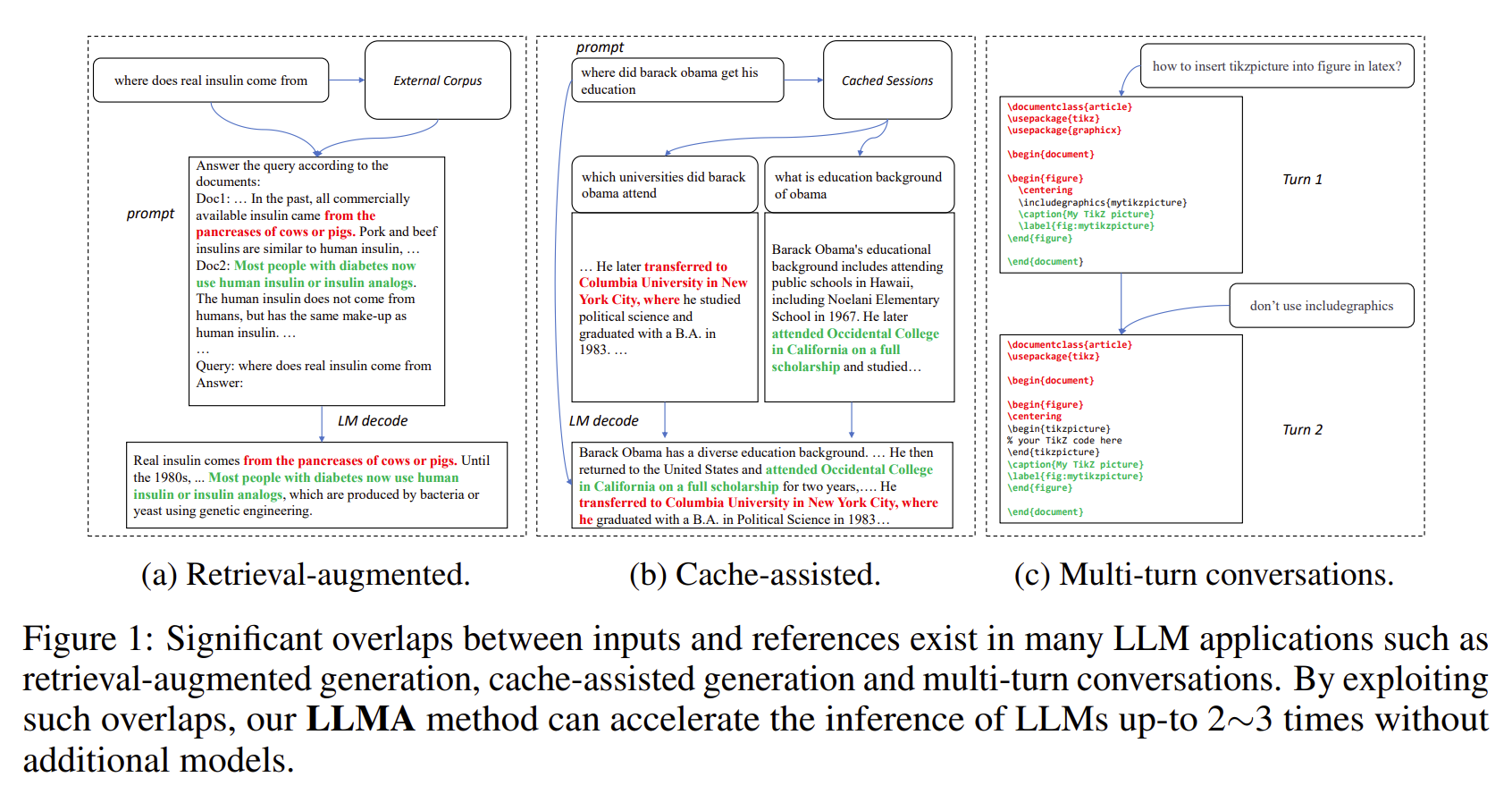
[Makalah] Inferensi dengan Referensi: Akselerasi Lossless Model Bahasa Besar
- Keluaran LLM sering kali mempunyai tumpang tindih yang signifikan dengan beberapa referensi (misalnya, dokumen yang diambil).
- LLMA mempercepat inferensi LLM tanpa kehilangan dengan menyalin dan memverifikasi rentang teks dari referensi ke input LLM.
- Berlaku untuk skenario LLM penting seperti generasi pengambilan-tambahan dan percakapan multi-putaran.
- Mencapai kecepatan 2~3 kali lipat tanpa model tambahan.
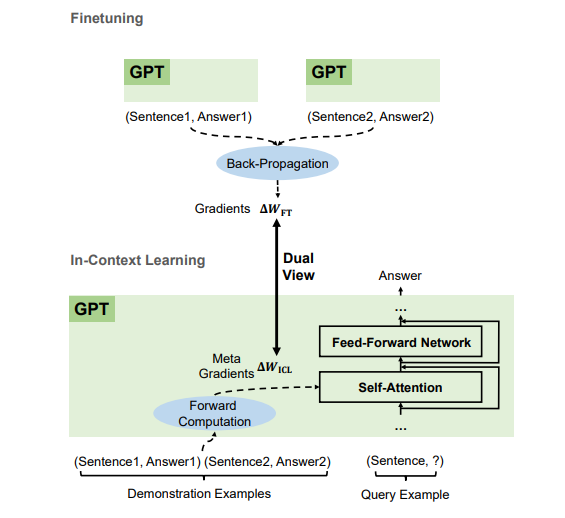
[Makalah] Mengapa GPT Dapat Belajar Dalam Konteks? Model Bahasa Secara Diam-diam Melakukan Penyempurnaan sebagai Pengoptimal Meta
- Berdasarkan contoh demonstrasi, GPT menghasilkan gradien meta untuk Pembelajaran Dalam Konteks (ICL) melalui komputasi maju. ICL bekerja dengan menerapkan gradien meta ini ke model melalui perhatian.
- Proses optimasi meta ICL berbagi tampilan ganda dengan penyempurnaan yang secara eksplisit memperbarui parameter model dengan gradien yang disebarkan kembali.
- Kami dapat menerjemahkan algoritme pengoptimalan (seperti SGD dengan Momentum) ke arsitektur Transformer yang sesuai.
Kami merekrut di semua tingkatan (termasuk peneliti dan pekerja magang FTE)! Jika Anda tertarik untuk bekerja bersama kami dalam Model Fondasi (alias model terlatih berskala besar) dan AGI, NLP, MT, Speech, Document AI, dan Multimodal AI, silakan kirimkan resume Anda ke [email protected].
Proyek ini dilisensikan berdasarkan lisensi yang ditemukan dalam file LISENSI di direktori akar pohon sumber ini.
Kode Etik Sumber Terbuka Microsoft
Untuk bantuan atau masalah dalam menggunakan model terlatih, silakan kirimkan masalah GitHub. Untuk komunikasi lainnya, silakan hubungi Furu Wei ( [email protected] ).


