YAYI2
1.0.0

[README] [?HF Repo] [?Versi web]
Cina |. Inggris
[28.03.2024] Semua model dan data diunggah ke Komunitas Sihir.
[22.12.2023] Kami merilis laporan teknis YAYI 2: Model Bahasa Besar Sumber Terbuka Multibahasa.
YAYI 2 adalah generasi baru model bahasa besar sumber terbuka yang dikembangkan oleh Zhongke Wenge, termasuk versi Base dan Chat, dengan ukuran parameter 30B. YAYI2-30B adalah model bahasa besar berdasarkan Transformer, yang menggunakan korpus multi-bahasa berkualitas tinggi dengan lebih dari 2 triliun Token untuk pra-pelatihan. Untuk skenario aplikasi umum dan spesifik domain, kami menggunakan jutaan instruksi untuk menyempurnakannya, dan menggunakan metode pembelajaran penguatan umpan balik manusia untuk lebih menyelaraskan model dengan nilai-nilai kemanusiaan.
Model open source kali ini adalah model Base YAYI2-30B. Kami berharap dapat mempromosikan pengembangan komunitas sumber terbuka model besar yang telah dilatih sebelumnya di Tiongkok melalui sumber terbuka model besar Yayi, dan secara aktif berkontribusi pada hal ini. Melalui open source, kami bekerja sama dengan setiap mitra untuk membangun ekosistem model besar Yayi.
Untuk detail teknis lebih lanjut, silakan baca laporan teknis kami YAYI 2: Model Bahasa Besar Sumber Terbuka Multibahasa.
| Nama kumpulan data | ukuran | ? | Alamat unduhan | Logo model ajaib | Alamat unduhan |
|---|---|---|---|---|---|
| Data Pra-latihan YAYI2 | 500G | wenge-research/yayi2_pretrain_data | Pengunduhan kumpulan data | wenge-research/yayi2_pretrain_data | Pengunduhan kumpulan data |
| Nama model | panjang konteks | ? | Alamat unduhan | Logo model ajaib | Alamat unduhan |
|---|---|---|---|---|---|
| YAYI2-30B | 4096 | wenge-penelitian/yayi2-30b | Pengunduhan model | wenge-penelitian/yayi2-30b | Pengunduhan model |
| YAYI2-30B-Obrolan | 4096 | wenge-penelitian/yayi2-30b-chat | Segera hadir... |
Kami melakukan evaluasi pada beberapa kumpulan data benchmark, termasuk C-Eval, MMLU, CMMLU, AGIEval, GAOKAO-Bench, GSM8K, MATH, BBH, HumanEval dan MBPP. Kami memeriksa kinerja model dalam pemahaman bahasa, pengetahuan subjek, penalaran matematika, penalaran logis, dan pembuatan kode. Model YAYI 2 menunjukkan peningkatan kinerja yang signifikan dibandingkan model sumber terbuka dengan ukuran serupa.
| pengetahuan subjek | matematika | penalaran yang logis | kode | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Model | C-Eval(val) | MMLU | AGIEval | CMMLU | GAOKAO-Bangku | GSM8K | MATEMATIKA | BBH | Evaluasi Manusia | MBPP |
| 5 tembakan | 5 tembakan | Tembakan 3/0 | 5 tembakan | 0-tembakan | 8/4 tembakan | 4 tembakan | 3 tembakan | 0-tembakan | 3 tembakan | |
| MPT-30B | - | 46.9 | 33.8 | - | - | 15.2 | 3.1 | 38.0 | 25.0 | 32.8 |
| Elang-40B | - | 55.4 | 37.0 | - | - | 19.6 | 5.5 | 37.1 | 0,6 | 29.8 |
| LLaMA2-34B | - | 62.6 | 43.4 | - | - | 42.2 | 6.2 | 44.1 | 22.6 | 33.0 |
| Baichuan2-13B | 59.0 | 59.5 | 37.4 | 61.3 | 45.6 | 52.6 | 10.1 | 49.0 | 17.1 | 30.8 |
| Qwen-14B | 71.7 | 67.9 | 51.9 | 70.2 | 62.5 | 61.6 | 25.2 | 53.7 | 32.3 | 39.8 |
| MagangLM-20B | 58.8 | 62.1 | 44.6 | 59.0 | 45.5 | 52.6 | 7.9 | 52.5 | 25.6 | 35.6 |
| Akuila2-34B | 98,5 | 76.0 | 43.8 | 78.5 | 37.8 | 50.0 | 17.8 | 42.5 | 0,0 | 41.0 |
| Yi-34B | 81.8 | 76.3 | 56.5 | 82.6 | 68.3 | 67.6 | 15.9 | 66.4 | 26.2 | 38.2 |
| YAYI2-30B | 80.9 | 80,5 | 62.0 | 84.0 | 64.4 | 71.2 | 14.8 | 54.5 | 53.1 | 45.8 |
Kami melakukan evaluasi menggunakan kode sumber yang disediakan oleh repositori OpenCompass Github. Untuk model perbandingan, kami mencantumkan hasil evaluasinya pada daftar OpenCompass, per 15 Desember 2023. Untuk model lain yang belum berpartisipasi dalam evaluasi pada platform OpenCompass, termasuk MPT, Falcon, dan LLaMa 2, kami mengadopsi hasil yang dilaporkan oleh LLaMA 2.
Kami memberikan contoh sederhana untuk mengilustrasikan cara cepat menggunakan YAYI2-30B untuk inferensi. Contoh ini dapat dijalankan pada satu A100/A800.
git clone https://github.com/wenge-research/YAYI2.git
cd YAYI2conda create --name yayi_inference_env python=3.8
conda activate yayi_inference_envHarap dicatat bahwa proyek ini memerlukan Python 3.8 atau lebih tinggi.
pip install transformers==4.33.1
pip install torch==2.0.1
pip install sentencepiece==0.1.99
pip install accelerate==0.25.0
>> > from transformers import AutoModelForCausalLM , AutoTokenizer
>> > tokenizer = AutoTokenizer . from_pretrained ( "wenge-research/yayi2-30b" , trust_remote_code = True )
>> > model = AutoModelForCausalLM . from_pretrained ( "wenge-research/yayi2-30b" , device_map = "auto" , trust_remote_code = True )
>> > inputs = tokenizer ( 'The winter in Beijing is' , return_tensors = 'pt' )
>> > inputs = inputs . to ( 'cuda' )
>> > pred = model . generate (
** inputs ,
max_new_tokens = 256 ,
eos_token_id = tokenizer . eos_token_id ,
do_sample = True ,
repetition_penalty = 1.2 ,
temperature = 0.4 ,
top_k = 100 ,
top_p = 0.8
)
>> > print ( tokenizer . decode ( pred . cpu ()[ 0 ], skip_special_tokens = True ))Saat Anda berkunjung untuk pertama kalinya, model perlu diunduh dan dimuat, yang mungkin memerlukan waktu beberapa saat.
Proyek ini mendukung penyempurnaan instruksi berdasarkan kecepatan dalam kerangka pelatihan terdistribusi. Konfigurasikan lingkungan dan jalankan skrip yang sesuai untuk memulai penyempurnaan parameter penuh atau penyempurnaan LoRA.
conda create --name yayi_train_env python=3.10
conda activate yayi_train_envpip install -r requirements.txtpip install --upgrade acceleratepip install flash-attn==2.0.3 --no-build-isolation
pip install triton==2.0.0.dev20221202 --no-deps Format data: lihat data/yayi_train_example.json , yang merupakan file JSON standar. Setiap bagian data terdiri dari "system" dan "conversations" , dengan "system" adalah informasi pengaturan peran global dan dapat berupa string kosong "conversations" . "conversations" adalah beberapa putaran dialog antara karakter manusia dan yayi.
Petunjuk pengoperasian: Jalankan perintah berikut untuk memulai penyempurnaan parameter penuh model Yayi. Perintah ini mendukung pelatihan multi-mesin dan multi-kartu. Disarankan untuk menggunakan konfigurasi perangkat keras 16*A100 (80G) atau lebih tinggi.
deepspeed --hostfile config/hostfile
--module training.trainer_yayi2
--report_to " tensorboard "
--data_path " ./data/yayi_train_example.json "
--model_name_or_path " your_model_path "
--output_dir " ./output "
--model_max_length 2048
--num_train_epochs 1
--per_device_train_batch_size 1
--gradient_accumulation_steps 1
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 500
--save_total_limit 10
--learning_rate 5e-6
--warmup_steps 2000
--lr_scheduler_type cosine
--logging_steps 1
--gradient_checkpointing True
--deepspeed " ./config/deepspeed.json "
--bf16 True Atau mulai melalui baris perintah:
bash scripts/start.sh Harap dicatat bahwa jika Anda perlu menggunakan template ChatML untuk menyempurnakan instruksi, Anda dapat mengubah --module training.trainer_yayi2 dalam perintah menjadi --module training.trainer_chatml ; jika Anda perlu menyesuaikan template Chat, Anda dapat memodifikasinya sistem dalam template Obrolan dari trainer_chatml.py Definisi token khusus untuk tiga peran , pengguna, dan asisten. Berikut ini adalah contoh template ChatML. Jika template ini atau template kustom digunakan selama pelatihan, template tersebut juga harus konsisten selama inferensi.
<|im_start|>system
You are a helpful and harmless assistant named YAYI.<|im_end|>
<|im_start|>user
Hello!<|im_end|>
<|im_start|>assistant
Hello! How can I assist you today?<|im_end|>
<|im_start|>user
1+1=<|im_end|>
<|im_start|>assistant
1+1 equals 2.<|im_end|>
bash scripts/start_lora.sh Pada tahap pra-pelatihan, kami tidak hanya menggunakan data Internet untuk melatih kemampuan bahasa model, namun juga menambahkan data pilihan umum dan data domain untuk meningkatkan keterampilan profesional model. Sebaran datanya adalah sebagai berikut: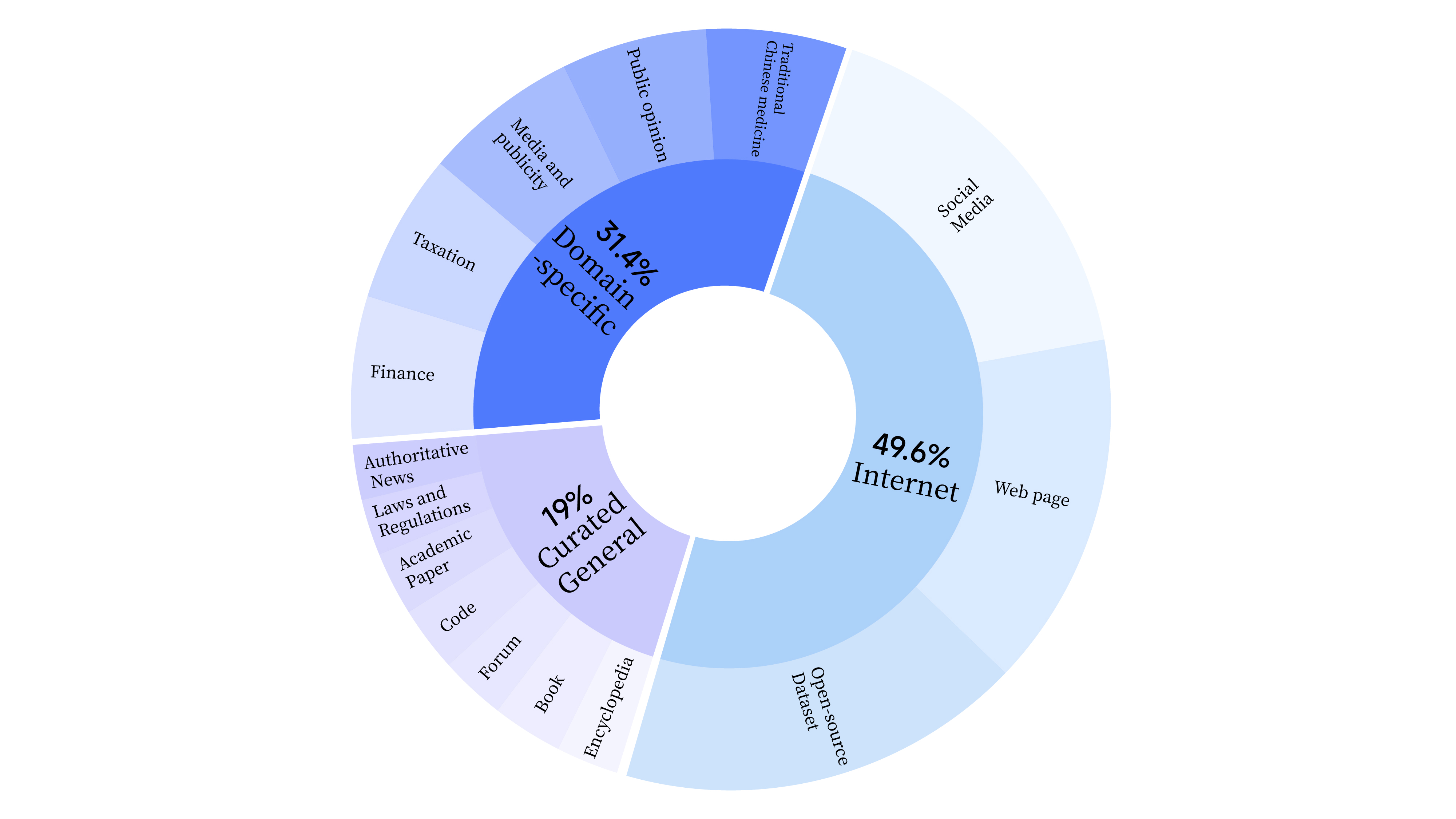
Kami telah membangun serangkaian jalur pemrosesan data untuk meningkatkan kualitas data di semua aspek, termasuk empat modul: standardisasi, pembersihan heuristik, deduplikasi multi-level, dan pemfilteran toksisitas. Kami mengumpulkan total 240 TB data mentah, dan hanya 10,6 TB data berkualitas tinggi yang tersisa setelah prapemrosesan. Proses keseluruhannya adalah sebagai berikut: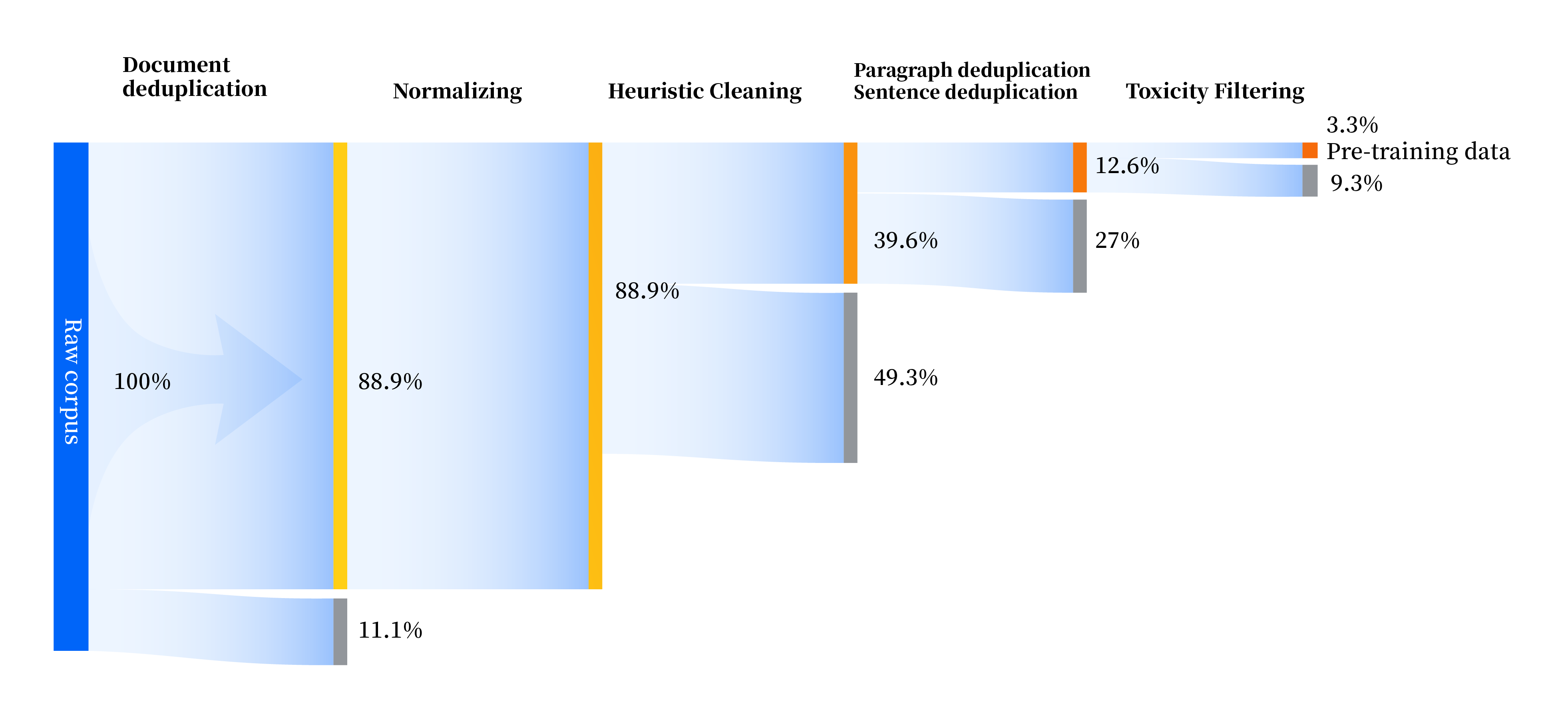

Kurva kerugian model YAYI 2 ditunjukkan pada gambar di bawah ini: 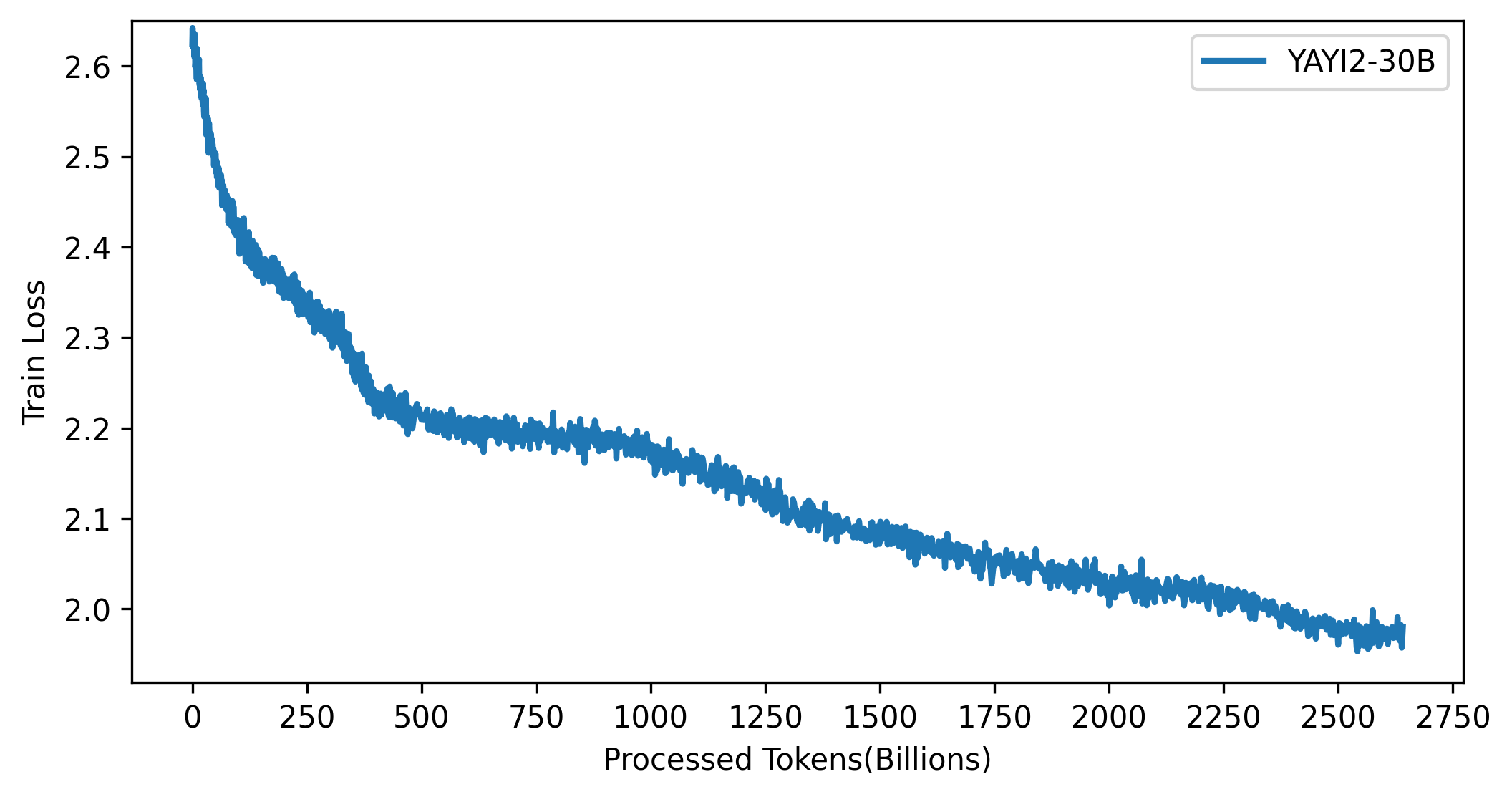
Kode dalam proyek ini bersifat open source sesuai dengan protokol Apache-2.0. Penggunaan model dan data YAYI 2 oleh komunitas harus mematuhi "Perjanjian Lisensi Komunitas Model Yayi YAYI 2". Jika Anda perlu menggunakan model seri YAYI 2 atau turunannya untuk tujuan komersial, silakan lengkapi "Informasi Pendaftaran Komersial Model YAYI 2" dan kirimkan ke [email protected] peninjauan akan dilakukan setiap hari. Setelah lulus peninjauan, Anda akan menerima lisensi komersial. Harap mematuhi dengan ketat konten yang relevan dari "Perjanjian Lisensi Komersial Model YAYI 2" selama penggunaan.
Jika Anda menggunakan model kami dalam pekerjaan Anda, silakan kutip makalah kami:
@article{YAYI 2,
author = {Yin Luo, Qingchao Kong, Nan Xu, et.al.},
title = {YAYI 2: Multilingual Open Source Large Language Models},
journal = {arXiv preprint arXiv:2312.14862},
url = {https://arxiv.org/abs/2312.14862},
year = {2023}
}


