Copulas
v0.12.0 - 2024-11-12
Repositori ini merupakan bagian dari The Synthetic Data Vault Project, sebuah proyek dari DataCebo.

Copulas adalah pustaka Python untuk memodelkan distribusi multivariat dan mengambil sampelnya menggunakan fungsi copula. Dengan adanya tabel data numerik, gunakan Copulas untuk mempelajari distribusi dan menghasilkan data sintetik baru yang mengikuti properti statistik yang sama.
Fitur Utama:
Modelkan data multivariat. Pilih dari beragam distribusi dan kopula univariat – termasuk Kopula Archimedian, Kopula Gaussian, dan Kopula Vine.
Bandingkan data nyata dan sintetis secara visual setelah membuat model Anda. Visualisasi tersedia sebagai histogram 1D, plot sebar 2D, dan plot sebar 3D.
Akses & manipulasi parameter yang dipelajari. Dengan akses penuh ke bagian dalam model, atur atau sesuaikan parameter sesuai pilihan Anda.
Instal perpustakaan Copulas menggunakan pip atau conda.
pip install copulasconda install -c conda-forge copulasMulailah menggunakan kumpulan data demo. Kumpulan data ini berisi 3 kolom numerik.
from copulas . datasets import sample_trivariate_xyz
real_data = sample_trivariate_xyz ()
real_data . head ()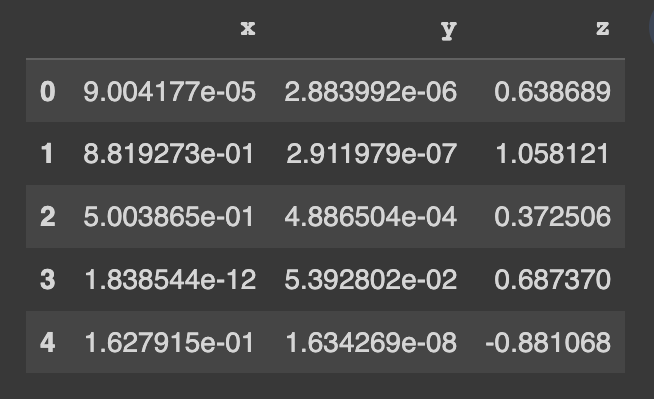
Modelkan data menggunakan kopula dan gunakan untuk membuat data sintetis. Perpustakaan Copulas menawarkan banyak pilihan termasuk Gaussian Copula, Vine Copulas, dan Archimedian Copulas.
from copulas . multivariate import GaussianMultivariate
copula = GaussianMultivariate ()
copula . fit ( real_data )
synthetic_data = copula . sample ( len ( real_data ))Visualisasikan data nyata dan sintetis secara berdampingan. Mari kita lakukan ini dalam 3D jadi lihat kumpulan data lengkap kita.
from copulas . visualization import compare_3d
compare_3d ( real_data , synthetic_data )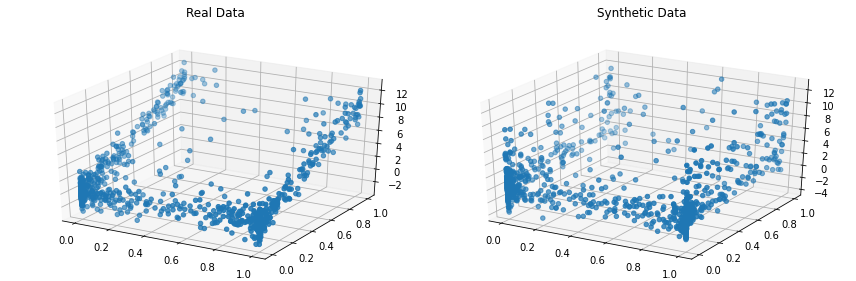
Klik di bawah untuk menjalankan kode sendiri di Colab Notebook dan temukan fitur baru.
Pelajari lebih lanjut tentang perpustakaan Copulas dari situs dokumentasi kami.
Pertanyaan atau masalah? Bergabunglah dengan saluran Slack kami untuk berdiskusi lebih lanjut tentang Copulas dan data sintetis. Jika Anda menemukan bug atau memiliki permintaan fitur, Anda juga dapat membuka masalah di GitHub kami.
Tertarik untuk berkontribusi pada Copulas? Baca Panduan Kontribusi kami untuk memulai.
Proyek sumber terbuka Copulas pertama kali dimulai di Data to AI Lab di MIT pada tahun 2018. Terima kasih kepada tim kontributor kami yang telah membangun dan memelihara perpustakaan selama bertahun-tahun!
Lihat Kontributor

Proyek Gudang Data Sintetis pertama kali dibuat di Lab Data ke AI MIT pada tahun 2016. Setelah 4 tahun melakukan penelitian dan interaksi dengan perusahaan, kami membuat DataCebo pada tahun 2020 dengan tujuan mengembangkan proyek tersebut. Saat ini, DataCebo bangga menjadi pengembang SDV, ekosistem terbesar untuk pembuatan & evaluasi data sintetis. Ini adalah rumah bagi beberapa perpustakaan yang mendukung data sintetis, termasuk:
Mulai gunakan paket SDV -- solusi terintegrasi penuh dan toko serba ada untuk data sintetis. Atau, gunakan perpustakaan mandiri untuk kebutuhan spesifik.


