airllm
1.0.0

Mulai cepat | Konfigurasi | macOS | Contoh buku catatan | Pertanyaan Umum
AirLLM mengoptimalkan penggunaan memori inferensi, memungkinkan 70B model bahasa besar menjalankan inferensi pada satu kartu GPU 4 GB tanpa kuantisasi, distilasi, dan pemangkasan. Dan Anda dapat menjalankan 405B Llama3.1 pada vram 8GB sekarang.
[2024/08/20] v2.11.0: Mendukung Qwen2.5
[2024/08/18] v2.10.1 Mendukung inferensi CPU. Mendukung model yang tidak dipecah. Terima kasih @NavodPeiris atas kerja bagusnya!
[2024/07/30] Mendukung Llama3.1 405B (contoh notebook). Mendukung kuantisasi 8bit/4bit .
[2024/04/20] AirLLM sudah mendukung Llama3 secara asli. Jalankan Llama3 70B pada GPU tunggal 4GB.
[2023/12/25] v2.8.2: Mendukung MacOS yang menjalankan 70B model bahasa besar.
[2023/12/20] v2.7: Mendukung AirLLMMixtral.
[2023/12/20] v2.6: Menambahkan AutoModel, secara otomatis mendeteksi jenis model, tidak perlu menyediakan kelas model untuk menginisialisasi model.
[2023/12/18] v2.5: menambahkan prefetching untuk tumpang tindih dengan pemuatan dan komputasi model. Peningkatan kecepatan 10%.
[2023/12/03] menambahkan dukungan ChatGLM , QWen , Baichuan , Mistral , InternLM !
[2023/12/02] menambahkan dukungan untuk safetensor. Sekarang dukung semua 10 model teratas di papan peringkat terbuka llm.
[2023/12/01] airllm 2.0. Mendukung kompresi: mempercepat waktu berjalan 3x!
[2023/11/20] airllm Versi awal!
Pertama, instal paket airllm pip.
pip install airllmKemudian, inisialisasi AirLLMLlama2, teruskan ID repo pelukan model yang digunakan, atau jalur lokal, dan inferensi dapat dilakukan serupa dengan model transformator biasa.
( Anda juga dapat menentukan jalur untuk menyimpan model berlapis terpisah melalui layer_shards_ saving_path saat memulai AirLLMLlama2.
from airllm import AutoModel
MAX_LENGTH = 128
# could use hugging face model repo id:
model = AutoModel . from_pretrained ( "garage-bAInd/Platypus2-70B-instruct" )
# or use model's local path...
#model = AutoModel.from_pretrained("/home/ubuntu/.cache/huggingface/hub/models--garage-bAInd--Platypus2-70B-instruct/snapshots/b585e74bcaae02e52665d9ac6d23f4d0dbc81a0f")
input_text = [
'What is the capital of United States?' ,
#'I like',
]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH ,
padding = False )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 20 ,
use_cache = True ,
return_dict_in_generate = True )
output = model . tokenizer . decode ( generation_output . sequences [ 0 ])
print ( output )Catatan: Selama inferensi, model asli pertama-tama akan didekomposisi dan disimpan berdasarkan lapisan. Harap pastikan ada cukup ruang disk di direktori cache pelukan.
Kami baru saja menambahkan kompresi model berdasarkan kompresi model berbasis kuantisasi blok. Yang selanjutnya dapat mempercepat kecepatan inferensi hingga 3x , dengan kehilangan akurasi yang hampir dapat diabaikan! (lihat evaluasi kinerja lebih lanjut dan mengapa kami menggunakan kuantisasi blok dalam makalah ini)
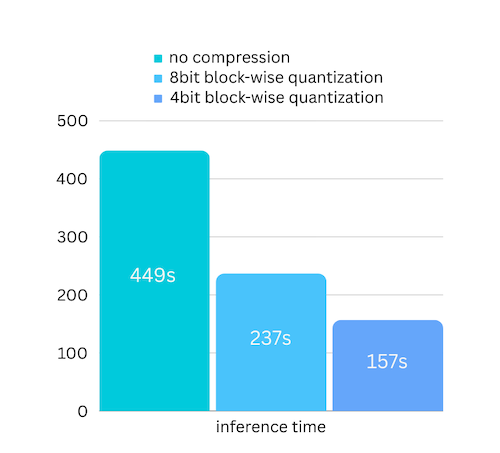
pip install -U bitsandbytespip install -U airllm model = AutoModel . from_pretrained ( "garage-bAInd/Platypus2-70B-instruct" ,
compression = '4bit' # specify '8bit' for 8-bit block-wise quantization
)Kuantisasi biasanya perlu mengkuantisasi bobot dan aktivasi untuk mempercepatnya. Hal ini mempersulit pemeliharaan akurasi dan menghindari dampak outlier di semua jenis input.
Meskipun dalam kasus kami hambatannya terutama pada pemuatan disk, kami hanya perlu memperkecil ukuran pemuatan model. Jadi, kita hanya bisa mengkuantisasi bagian bobotnya, yang lebih mudah untuk memastikan keakuratannya.
Saat menginisialisasi model, kami mendukung konfigurasi berikut:
Instal saja airllm dan jalankan kodenya sama seperti di linux. Lihat selengkapnya di Mulai Cepat.
Contoh [buku catatan python] (https://github.com/lyogavin/airllm/blob/main/air_llm/examples/run_on_macos.ipynb)
Contoh colab di sini:
from airllm import AutoModel
MAX_LENGTH = 128
model = AutoModel . from_pretrained ( "THUDM/chatglm3-6b-base" )
input_text = [ 'What is the capital of China?' ,]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH ,
padding = True )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 5 ,
use_cache = True ,
return_dict_in_generate = True )
model . tokenizer . decode ( generation_output . sequences [ 0 ]) from airllm import AutoModel
MAX_LENGTH = 128
model = AutoModel . from_pretrained ( "Qwen/Qwen-7B" )
input_text = [ 'What is the capital of China?' ,]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 5 ,
use_cache = True ,
return_dict_in_generate = True )
model . tokenizer . decode ( generation_output . sequences [ 0 ]) from airllm import AutoModel
MAX_LENGTH = 128
model = AutoModel . from_pretrained ( "baichuan-inc/Baichuan2-7B-Base" )
#model = AutoModel.from_pretrained("internlm/internlm-20b")
#model = AutoModel.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
input_text = [ 'What is the capital of China?' ,]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 5 ,
use_cache = True ,
return_dict_in_generate = True )
model . tokenizer . decode ( generation_output . sequences [ 0 ])Banyak kode yang didasarkan pada karya hebat SimJeg dalam kompetisi ujian Kaggle. Teriakan keras untuk SimJeg:
Akun GitHub @SimJeg, kode di Kaggle, diskusi terkait.
safetensors_rust.SafetensorError: Kesalahan saat deserialisasi header: MetadataIncompleteBuffer
Jika Anda mengalami kesalahan ini, kemungkinan besar penyebabnya adalah Anda kehabisan ruang disk. Proses pemisahan model sangat memakan disk. Lihat ini. Anda mungkin perlu menambah ruang disk, menghapus .cache pelukan, dan menjalankannya kembali.
Kemungkinan besar Anda memuat model QWen atau ChatGLM dengan kelas Llama2. Coba yang berikut ini:
Untuk model QWen:
from airllm import AutoModel #<----- instead of AirLLMLlama2
AutoModel . from_pretrained (...)Untuk model ChatGLM:
from airllm import AutoModel #<----- instead of AirLLMLlama2
AutoModel . from_pretrained (...)Beberapa model adalah model yang terjaga keamanannya, memerlukan token api pelukan. Anda dapat memberikan hf_token:
model = AutoModel . from_pretrained ( "meta-llama/Llama-2-7b-hf" , #hf_token='HF_API_TOKEN')Tokenizer beberapa model tidak memiliki token padding, jadi Anda dapat menyetel token padding atau cukup menonaktifkan konfigurasi padding:
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH ,
padding = False #<----------- turn off padding
)Jika Anda merasa AirLLM berguna dalam penelitian Anda dan ingin mengutipnya, silakan gunakan entri BibTex berikut:
@software{airllm2023,
author = {Gavin Li},
title = {AirLLM: scaling large language models on low-end commodity computers},
url = {https://github.com/lyogavin/airllm/},
version = {0.0},
year = {2023},
}
Menyambut kontribusi, ide, dan diskusi!
Jika menurut Anda ini berguna, silakan atau belikan saya kopi!


