WilmerAI
1.0.0
Ini adalah proyek pribadi yang sedang dalam pengembangan besar-besaran. Ini bisa saja, dan mungkin saja, mengandung bug, kode yang tidak lengkap, atau masalah lain yang tidak diinginkan. Oleh karena itu, perangkat lunak disediakan apa adanya, tanpa jaminan apa pun.
WilmerAI mencerminkan pekerjaan seorang pengembang dan upaya yang menggunakan waktu dan sumber daya pribadinya; segala pandangan, metodologi, dan lain-lain yang ditemukan di dalamnya adalah miliknya sendiri dan tidak boleh mencerminkan atasannya.
WilmerAI adalah sistem middleware canggih yang dirancang untuk menerima perintah masuk dan melakukan berbagai tugas sebelum mengirimnya ke LLM API. Pekerjaan ini mencakup penggunaan Model Bahasa Besar (LLM) untuk mengkategorikan perintah dan mengarahkannya ke alur kerja yang sesuai atau memproses konteks besar (200.000+ token) untuk menghasilkan perintah yang lebih kecil dan lebih mudah dikelola yang cocok untuk sebagian besar model lokal.
WilmerAI adalah singkatan dari "Bagaimana Jika Model Bahasa Secara Ahli Merutekan Semua Inferensi?"
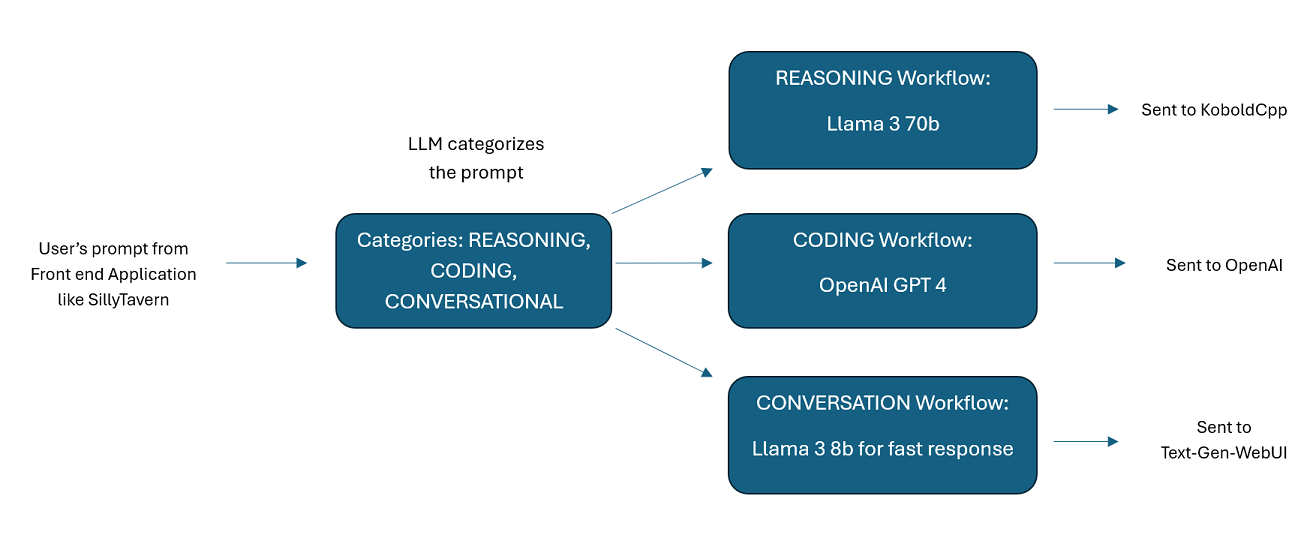
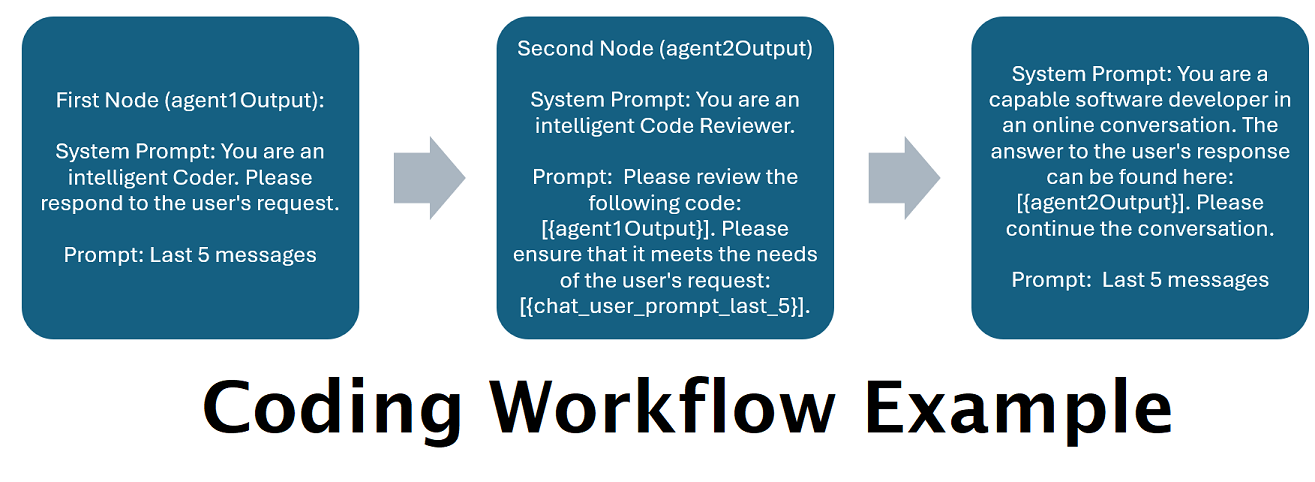
Asisten Didukung oleh Beberapa LLM secara Tandem : Perintah masuk dapat dialihkan ke "kategori", dengan setiap kategori didukung oleh alur kerja. Setiap alur kerja dapat memiliki simpul sebanyak yang Anda inginkan, setiap simpul didukung oleh LLM yang berbeda. Misalnya- jika Anda bertanya kepada asisten Anda "Bisakah Anda menuliskan saya permainan Ular dengan python?", itu mungkin dikategorikan sebagai CODING dan masuk ke alur kerja coding Anda. Node pertama dari alur kerja tersebut mungkin meminta Codestral-22b (atau ChatGPT 4o jika Anda mau) untuk menjawab pertanyaan tersebut. Node kedua mungkin meminta Deepseek V2 atau Claude Sonnet untuk meninjau kodenya. Node berikutnya mungkin meminta Codestral untuk memberikan penyelesaian akhir dan kemudian merespons Anda. Apakah alur kerja Anda hanya berupa satu model yang merespons karena itu adalah pembuat kode terbaik Anda, atau apakah banyak node dari LLM berbeda yang bekerja sama untuk menghasilkan respons, pilihan ada di tangan Anda.
Dukungan Untuk API Wikipedia Offline : WilmerAI memiliki node yang dapat melakukan panggilan ke OfflineWikipediaTextApi. Ini berarti Anda dapat memiliki kategori, misalnya "FAKTIF", yang melihat pesan masuk Anda, menghasilkan kueri darinya, menanyakan API wikipedia untuk artikel terkait, dan menggunakan artikel tersebut sebagai injeksi konteks RAG untuk merespons.
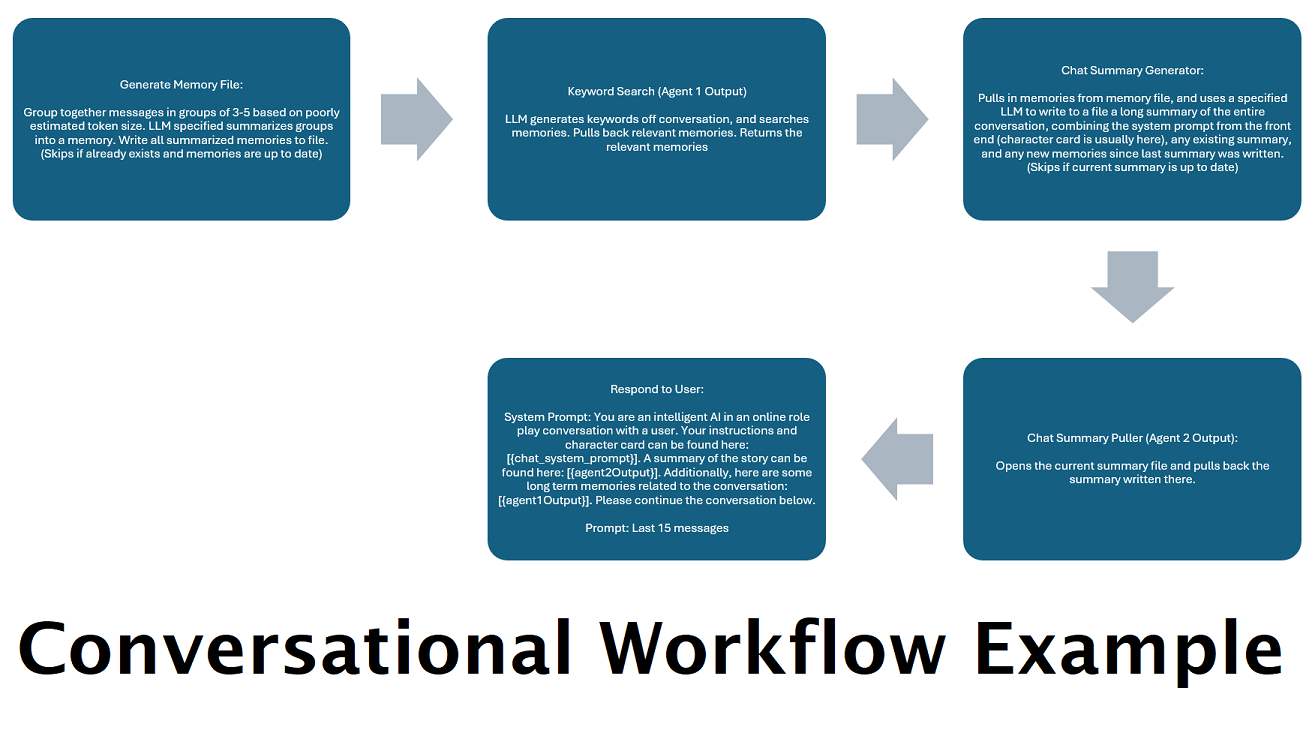
Ringkasan Obrolan yang Dihasilkan Secara Terus-menerus untuk Mensimulasikan "Memori" : Node Ringkasan Obrolan akan menghasilkan "kenangan", dengan mengelompokkan pesan-pesan Anda lalu meringkasnya dan menyimpannya ke sebuah file. Ini kemudian akan mengambil potongan ringkasan tersebut dan menghasilkan ringkasan keseluruhan percakapan yang berkelanjutan dan terus diperbarui, yang dapat ditarik dan digunakan dalam prompt ke LLM. Hasilnya memungkinkan Anda melakukan 200 ribu+ percakapan konteks dan melacak secara relatif apa yang telah dikatakan bahkan ketika membatasi perintah pada konteks LLM hingga 5 ribu atau kurang.
Gunakan Beberapa Komputer Untuk Memproses Memori dan Respons Secara Paralel : Jika Anda memiliki 2 komputer yang dapat menjalankan LLM, Anda dapat menunjuk satu untuk menjadi "responden" dan satu lagi bertanggung jawab untuk menghasilkan kenangan/ringkasan. Alur kerja semacam ini memungkinkan Anda terus berbicara dengan LLM Anda saat kenangan/ringkasan diperbarui, sambil tetap menggunakan kenangan yang ada. Ini berarti tidak perlu menunggu ringkasan diperbarui, bahkan jika Anda menugaskan model yang besar dan kuat untuk menangani tugas tersebut sehingga Anda memiliki memori berkualitas lebih tinggi. (Lihat contoh pengguna convo-role-dual-model )
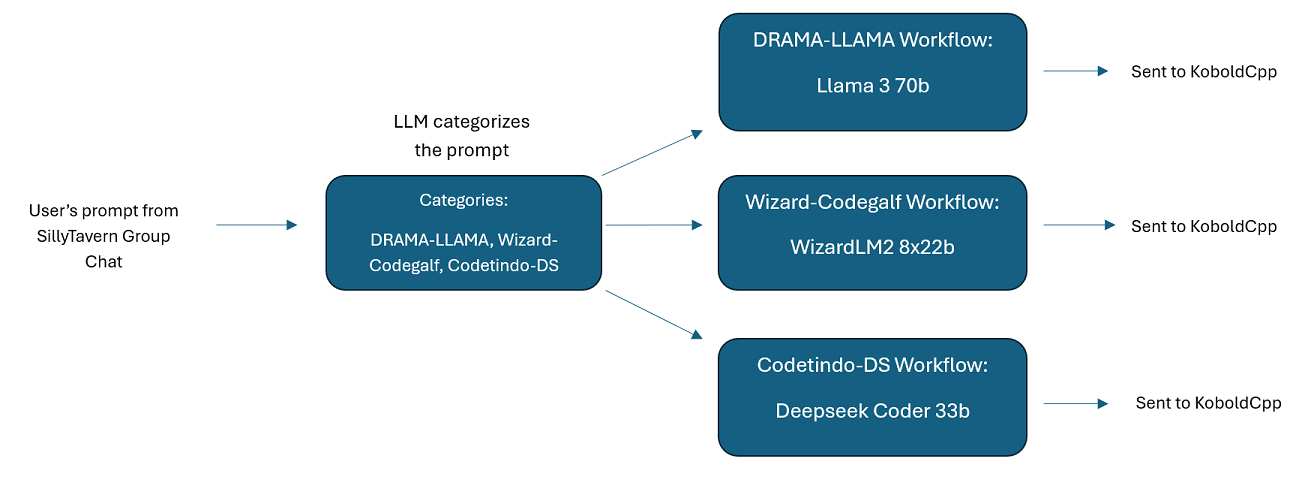
Obrolan Grup Multi-LLM Di SillyTavern: Dimungkinkan untuk menggunakan Wilmer untuk melakukan obrolan grup di ST di mana setiap karakter adalah LLM yang berbeda, jika Anda menginginkannya (penulis secara pribadi melakukan ini.) Ada contoh karakter yang tersedia di DocsSillyTavern , dibagi menjadi dua kelompok. Contoh karakter/grup ini adalah himpunan bagian dari grup lebih besar yang penulis gunakan.
Fungsionalitas Middleware: WilmerAI berada di antara antarmuka yang Anda gunakan untuk berkomunikasi dengan LLM (seperti SillyTavern, OpenWebUI, atau bahkan terminal program Python) dan API backend yang melayani LLM. Itu dapat menangani beberapa LLM backend secara bersamaan.
Menggunakan Beberapa LLM Sekaligus: Contoh penyiapan: SillyTavern -> WilmerAI -> beberapa instance KoboldCpp. Misalnya, Wilmer dapat dihubungkan ke Command-R 35b, Codestral 22b, Gemma-2-27b, dan menggunakan semua itu dalam tanggapannya kembali ke pengguna. Selama LLM pilihan Anda terekspos melalui titik akhir v1/Penyelesaian atau obrolan/Penyelesaian, atau titik akhir Hasilkan KoboldCpp, Anda dapat menggunakannya.
Preset yang Dapat Disesuaikan : Preset disimpan dalam file json yang dapat Anda sesuaikan dengan mudah. Hampir semua preset dapat dikelola melalui json, termasuk nama parameter. Ini berarti Anda tidak perlu menunggu pembaruan Wilmer untuk memanfaatkan sesuatu yang baru. Misalnya, DRY baru-baru ini dirilis di KoboldCpp. Jika itu tidak ada dalam json preset untuk Wilmer, Anda dapat menambahkannya dan mulai menggunakannya.
Titik Akhir API: Ini menyediakan titik akhir chat/Completions dan v1/Completions yang kompatibel dengan OpenAI API untuk dihubungkan melalui ujung depan Anda, dan dapat terhubung ke salah satu jenis di ujung belakang. Hal ini memungkinkan konfigurasi yang kompleks, seperti menghubungkan ke Wilmer sebagai v1/Completion API, dan kemudian menghubungkan Wilmer ke chat/Completion, v1/Completion KoboldCpp Generate endpoints secara bersamaan.
Templat Prompt: Mendukung templat cepat untuk titik akhir API v1/Completions . WilmerAI juga memiliki template promptnya sendiri untuk koneksi dari front end melalui v1/Completions . Templat dapat ditemukan di folder "Docs" dan siap diunggah ke SillyTavern.

Harap diingat bahwa alur kerja, pada dasarnya, dapat membuat banyak panggilan ke titik akhir API berdasarkan cara Anda menyiapkannya. WilmerAI tidak melacak penggunaan token, tidak melaporkan penggunaan token yang akurat melalui API-nya, atau menawarkan cara apa pun yang layak untuk memantau penggunaan token. Jadi jika pelacakan penggunaan token penting bagi Anda karena alasan biaya, pastikan untuk melacak berapa banyak token yang Anda gunakan melalui dasbor apa pun yang disediakan oleh API LLM Anda, terutama sejak Anda terbiasa dengan perangkat lunak ini.
LLM Anda secara langsung mempengaruhi kualitas WilmerAI. Ini adalah proyek yang digerakkan oleh LLM, dimana aliran dan keluarannya hampir seluruhnya bergantung pada LLM yang terhubung dan tanggapannya. Jika Anda menghubungkan Wilmer ke model yang menghasilkan output dengan kualitas lebih rendah, atau jika preset atau template prompt Anda memiliki kekurangan, maka kualitas Wilmer secara keseluruhan juga akan memiliki kualitas yang jauh lebih rendah. Ini tidak jauh berbeda dengan alur kerja agen dalam hal itu.
Meskipun penulis melakukan yang terbaik untuk membuat sesuatu yang berguna dan berkualitas tinggi, ini adalah proyek solo yang ambisius dan pasti memiliki masalah (terutama karena penulis bukan pengembang Python asli, dan sangat bergantung pada AI untuk membantunya mendapatkan ini. jauh). Tapi dia perlahan-lahan memikirkannya.
Wilmer mengekspos titik akhir OpenAI v1/Penyelesaian dan obrolan/Penyelesaian, sehingga kompatibel dengan sebagian besar ujung depan. Meskipun saya terutama menggunakan ini dengan SillyTavern, ini mungkin juga berfungsi dengan Open-WebUI.
Untuk terhubung sebagai Penyelesaian Teks di SillyTavern, ikuti langkah-langkah berikut (tangkapan layar di bawah ini berasal dari SillyTavern):
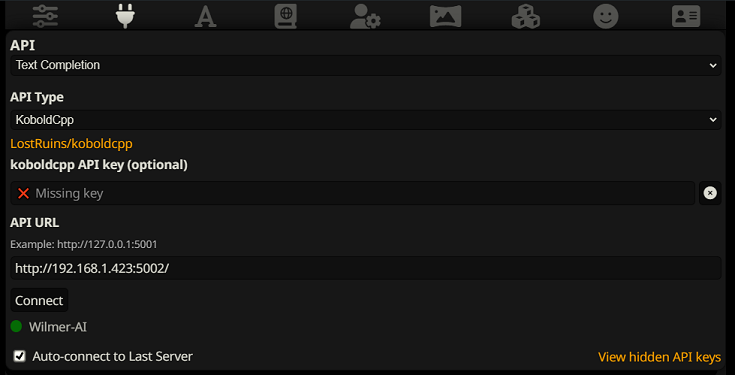
Saat menggunakan pelengkapan teks, Anda perlu menggunakan format Templat Prompt khusus WilmerAI. File ST yang dapat diimpor dapat ditemukan dalam Docs/SillyTavern/InstructTemplate . Templat konteks juga disertakan jika Anda ingin menggunakannya juga.
Templat instruksinya terlihat seperti ini:
[Beg_Sys]You are an intelligent AI Assistant.[Beg_User]SomeOddCodeGuy: Hey there![Beg_Assistant]Wilmer: Hello![Beg_User]SomeOddCodeGuy: This is a test[Beg_Assistant]Wilmer: Nice.
Dari SillyTavern:
"input_sequence": "[Beg_User]",
"output_sequence": "[Beg_Assistant]",
"first_output_sequence": "[Beg_Assistant]",
"last_output_sequence": "",
"system_sequence_prefix": "[Beg_Sys]",
"system_sequence_suffix": "",
Tidak ada baris atau karakter baru yang diharapkan di antara tag.
Harap pastikan bahwa Templat Konteks "Diaktifkan" (kotak centang di atas tarik-turun)
Untuk terhubung sebagai Penyelesaian Obrolan di SillyTavern, ikuti langkah-langkah berikut (tangkapan layar di bawah berasal dari SillyTavern):
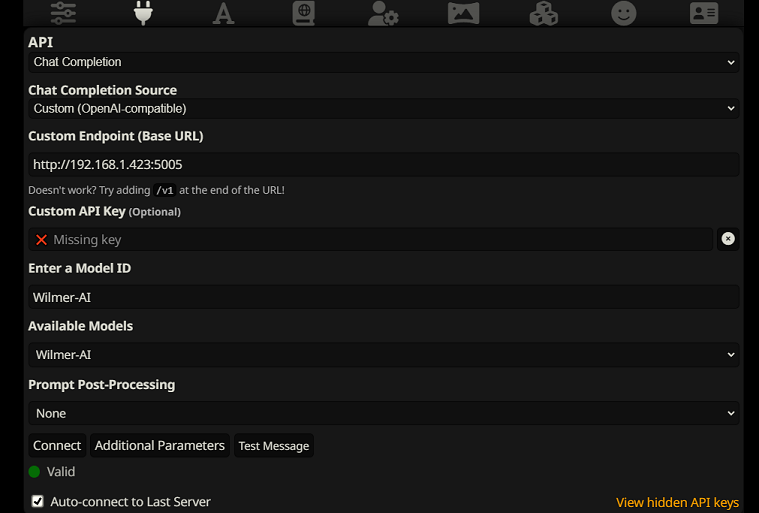
chatCompleteAddUserAssistant ke true. (Saya tidak menyarankan menyetel keduanya ke true secara bersamaan. Gunakan nama karakter dari SillyTavern, ATAU pengguna/asisten dari Wilmer. Jika tidak, AI mungkin akan bingung.)Untuk jenis koneksi mana pun, saya sarankan untuk membuka ikon "A" di SillyTavern dan memilih "Sertakan Nama" dan "Paksa Grup dan Persona" dalam mode instruksi, lalu buka ikon paling kiri (tempat sampler berada) dan centang " streaming" di kiri atas, lalu di kanan atas centang "buka kunci" berdasarkan konteks dan seret ke 200.000+. Biarkan Wilmer memikirkan konteksnya.
Wilmer saat ini tidak memiliki antarmuka pengguna; semuanya dikontrol melalui file konfigurasi JSON yang terletak di folder "Publik". Folder ini berisi semua konfigurasi penting. Saat memperbarui atau mengunduh salinan baru WilmerAI, Anda cukup menyalin folder "Publik" ke instalasi baru untuk mempertahankan pengaturan Anda.
Bagian ini akan memandu Anda dalam menyiapkan Wilmer. Saya telah membagi bagian-bagian itu menjadi beberapa langkah; Saya mungkin merekomendasikan menyalin setiap langkah, 1 per 1, ke dalam LLM dan memintanya untuk membantu Anda menyiapkan bagian tersebut. Itu mungkin membuat hal ini menjadi lebih mudah.
CATATAN PENTING
Penting untuk mencatat tiga hal tentang pengaturan Wilmer.
A) File preset 100% dapat disesuaikan. Apa yang ada di file itu masuk ke llm API. Hal ini karena API cloud tidak menangani beberapa preset yang ditangani oleh API LLM lokal. Oleh karena itu, jika Anda menggunakan OpenAI API atau layanan cloud lainnya, panggilan mungkin akan gagal jika Anda menggunakan salah satu preset AI lokal biasa. Silakan lihat preset "OpenAI-API" untuk contoh apa yang diterima openAI.
B) Saya baru-baru ini mengganti semua perintah di Wilmer untuk beralih dari penggunaan orang kedua ke orang ketiga. Ini memberikan hasil yang cukup baik bagi saya, dan saya berharap hal yang sama juga terjadi pada Anda.
C) Secara default, semua file pengguna diatur untuk mengaktifkan respons streaming. Anda juga harus mengaktifkan ini di front end Anda yang memanggil Wilmer agar keduanya cocok, atau Anda harus masuk ke Users/username.json dan mengatur Stream ke "false". Jika Anda memiliki ketidakcocokan, di mana front end mengharapkan/tidak mengharapkan streaming dan wilmer Anda mengharapkan sebaliknya, kemungkinan besar tidak akan ada yang ditampilkan di front end.
Menginstal Wilmer sangatlah mudah. Pastikan Anda telah menginstal Python; penulis telah menggunakan program dengan Python 3.10 dan 3.12, dan keduanya bekerja dengan baik.
Opsi 1: Menggunakan Skrip yang Disediakan
Untuk kenyamanan, Wilmer menyertakan file BAT untuk Windows dan file .sh untuk macOS. Skrip ini akan membuat lingkungan virtual, menginstal paket yang diperlukan dari requirements.txt , dan kemudian menjalankan Wilmer. Anda dapat menggunakan skrip ini untuk memulai Wilmer setiap saat.
.bat yang disediakan..sh yang disediakan.PENTING: Jangan pernah menjalankan file BAT atau SH tanpa memeriksanya terlebih dahulu, karena ini bisa berisiko. Jika Anda tidak yakin tentang keamanan file tersebut, buka file tersebut di Notepad/TextEdit, salin isinya, lalu minta LLM Anda untuk meninjaunya untuk mengetahui potensi masalah apa pun.
Opsi 2: Instalasi Manual
Alternatifnya, Anda dapat menginstal dependensi secara manual dan menjalankan Wilmer dengan langkah-langkah berikut:
Instal paket yang diperlukan:
pip install -r requirements.txtMulai programnya:
python server.pySkrip yang disediakan dirancang untuk menyederhanakan proses dengan menyiapkan lingkungan virtual. Namun, Anda dapat mengabaikannya dengan aman jika Anda lebih suka instalasi manual.
CATATAN : Saat menjalankan file bat, file sh, atau file python, ketiganya sekarang menerima argumen OPSIONAL berikut:
Jadi, misalnya, pertimbangkan kemungkinan proses berikut:
bash run_macos.sh (akan menggunakan pengguna yang ditentukan di _current-user.json, konfigurasi di "Publik", masuk ke "log")bash run_macos.sh --User "single-model-assistant" (akan default ke publik untuk konfigurasi dan "log" untuk log)bash run_macos.sh --ConfigDirectory "/users/socg/Public/configs" --User "single-model-assistant" (hanya akan menggunakan default untuk "logs"bash run_macos.sh --ConfigDirectory "/users/socg/Public/configs" --User "single-model-assistant" --LoggingDirectory "/users/socg/wilmerlogs"Argumen opsional ini memungkinkan pengguna untuk menjalankan beberapa contoh WilmerAI, setiap contoh menggunakan profil pengguna yang berbeda, masuk ke tempat yang berbeda, dan menentukan konfigurasi di lokasi yang berbeda, jika diinginkan.
Di dalam Public/Configs Anda akan menemukan serangkaian folder yang berisi file json. Dua yang paling Anda minati adalah folder Endpoints dan folder Users .
CATATAN: Node alur kerja Faktual dari pengguna assistant-single-model , assistant-multi-model dan group-chat-example akan mencoba memanfaatkan proyek OfflineWikipediaTextApi untuk menarik artikel-artikel wikipedia lengkap ke RAG. Jika Anda tidak memiliki API ini, alur kerja seharusnya tidak mengalami masalah apa pun, tetapi saya pribadi menggunakan API ini untuk membantu meningkatkan respons faktual yang saya dapatkan. Anda dapat menentukan alamat IP ke API Anda di json pengguna pilihan Anda.
Pertama, pilih pengguna template mana yang ingin Anda gunakan:
asisten-model tunggal : Templat ini untuk satu model kecil yang digunakan di semua node. Ini juga memiliki rute untuk berbagai tipe kategori berbeda dan menggunakan preset yang sesuai untuk setiap node. Jika Anda bertanya-tanya mengapa ada rute untuk kategori berbeda padahal hanya ada 1 model: ini agar Anda dapat memberikan presetnya masing-masing kategori, dan juga agar Anda dapat membuat alur kerja khusus untuk kategori tersebut. Mungkin Anda ingin pembuat kode melakukan beberapa iterasi untuk memeriksa dirinya sendiri, atau alasan untuk memikirkan berbagai hal dalam beberapa langkah.
asisten-multi-model : Templat ini untuk menggunakan banyak model secara bersamaan. Melihat titik akhir untuk pengguna ini, Anda dapat melihat bahwa setiap kategori memiliki titik akhir sendiri. Sama sekali tidak ada yang menghentikan Anda untuk menggunakan kembali API yang sama untuk beberapa kategori. Misalnya, Anda mungkin menggunakan Llama 3.1 70b untuk pengkodean, matematika, dan penalaran, dan Command-R 35b 08-2024 untuk kategorisasi, percakapan, dan faktual. Jangan merasa Anda MEMBUTUHKAN 10 model berbeda. Ini hanya untuk memungkinkan Anda membawa sebanyak itu jika Anda mau. Pengguna ini menggunakan preset yang sesuai untuk setiap node dalam alur kerja.
convo-roleplay-single-model : Pengguna ini menggunakan model tunggal dengan alur kerja khusus yang bagus untuk percakapan, dan juga bagus untuk roleplay (menunggu masukan untuk diubah jika diperlukan). Ini melewati semua perutean.
convo-roleplay-dual-model : Pengguna ini menggunakan dua model dengan alur kerja khusus yang bagus untuk percakapan, dan juga bagus untuk roleplay (menunggu masukan untuk diubah jika diperlukan). Ini melewati semua perutean. CATATAN : Alur kerja ini berfungsi paling baik jika Anda memiliki 2 komputer yang dapat menjalankan LLM. Dengan pengaturan saat ini untuk pengguna ini, ketika Anda mengirim pesan ke Wilmer, model responden (komputer 1) akan merespons Anda. Kemudian alur kerja akan menerapkan "kunci alur kerja" pada saat itu. Model ringkasan memori/obrolan (komputer 2) kemudian akan mulai memperbarui memori dan ringkasan percakapan sejauh ini, yang diteruskan ke responden untuk membantunya mengingat sesuatu. Jika Anda mengirim prompt lain saat kenangan sedang ditulis, responden (komputer 1) akan mengambil ringkasan apa pun yang ada dan melanjutkan dan merespons Anda. Kunci alur kerja akan menghentikan Anda memasuki kembali bagian kenangan baru. Artinya, Anda dapat terus berbicara dengan model responden Anda sementara kenangan baru sedang ditulis. Ini adalah peningkatan kinerja yang BESAR. Saya sudah mencobanya, dan bagi saya waktu responsnya luar biasa. Tanpa ini, saya mendapat respons dalam 30 detik sebanyak 3-5 kali, lalu tiba-tiba menunggu selama 2 menit untuk membangkitkan kenangan. Dengan ini, setiap pesan berdurasi 30 detik, setiap saat, di Llama 3.1 70b di Mac Studio saya.
contoh-obrolan grup : Pengguna ini adalah contoh obrolan grup pribadi saya. Karakter dan grup yang disertakan adalah karakter sebenarnya dan grup aktual yang saya gunakan. Anda dapat menemukan contoh karakter di folder Docs/SillyTavern . Ini adalah karakter yang kompatibel dengan SillyTavern yang dapat Anda impor langsung ke program tersebut atau program apa pun yang mendukung jenis impor karakter .png. Karakter tim pengembang hanya memiliki 1 node per alur kerja: mereka hanya merespons Anda. Karakter grup penasihat memiliki 2 node per alur kerja: node pertama menghasilkan respons, dan node kedua menerapkan "persona" karakter (titik akhir yang bertanggung jawab atas hal ini adalah titik akhir businessgroup-speaker ). Persona obrolan grup sangat membantu untuk memvariasikan respons yang Anda dapatkan, meskipun Anda hanya menggunakan 1 model. Namun, saya bertujuan untuk menggunakan model yang berbeda untuk setiap karakter (tetapi menggunakan kembali model antar grup; jadi, misalnya, saya memiliki karakter model Llama 3.1 70b di setiap grup).
Setelah Anda memilih pengguna yang ingin Anda gunakan, ada beberapa langkah yang harus dilakukan:
Perbarui titik akhir untuk pengguna Anda di bawah Publik/Konfigurasi/Titik Akhir. Contoh karakter diurutkan ke dalam folder untuk masing-masing karakter. Folder titik akhir pengguna ditentukan di bagian bawah file user.json mereka. Anda ingin mengisi setiap titik akhir dengan tepat untuk LLM yang Anda gunakan. Anda dapat menemukan beberapa contoh titik akhir di bawah folder _example-endpoints .
Anda perlu mengatur pengguna Anda saat ini. Anda dapat melakukan ini saat menjalankan file bat/sh/py dengan menggunakan argumen --User, atau Anda dapat melakukannya di Public/Configs/Users/_current-user.json. Cukup masukkan nama pengguna sebagai pengguna saat ini dan simpan.
Anda ingin membuka file json pengguna Anda dan mengintip opsinya. Di sini Anda dapat mengatur apakah Anda ingin streaming atau tidak, dapat mengatur alamat IP ke API wiki offline Anda (jika Anda menggunakannya), menentukan ke mana Anda ingin menyimpan file kenangan/ringkasan Anda selama alur DiscussionId, dan juga menentukan di mana Anda ingin db sqllite digunakan jika Anda menggunakan Workflow Locks.
Itu saja! Jalankan Wilmer, sambungkan ke sana, dan Anda siap melakukannya.
Pertama, kita akan menyiapkan titik akhir dan model. Di dalam folder Publik/Konfigurasi Anda akan melihat sub-folder berikut. Mari kita telusuri apa yang Anda perlukan.
File konfigurasi ini mewakili titik akhir LLM API yang terhubung dengan Anda. Misalnya, file JSON berikut, SmallModelEndpoint.json , mendefinisikan titik akhir:
{
"modelNameForDisplayOnly" : " Small model for all tasks " ,
"endpoint" : " http://127.0.0.1:5000 " ,
"apiTypeConfigFileName" : " KoboldCpp " ,
"maxContextTokenSize" : 8192 ,
"modelNameToSendToAPI" : " " ,
"promptTemplate" : " chatml " ,
"addGenerationPrompt" : true
}File konfigurasi ini mewakili berbagai jenis API yang mungkin Anda gunakan saat menggunakan Wilmer.
{
"nameForDisplayOnly" : " KoboldCpp Example " ,
"type" : " koboldCppGenerate " ,
"presetType" : " KoboldCpp " ,
"truncateLengthPropertyName" : " max_context_length " ,
"maxNewTokensPropertyName" : " max_length " ,
"streamPropertyName" : " stream "
} File-file ini menentukan templat prompt untuk suatu model. Perhatikan contoh berikut, llama3.json :
{
"promptTemplateAssistantPrefix" : " <|start_header_id|>assistant<|end_header_id|> nn " ,
"promptTemplateAssistantSuffix" : " <|eot_id|> " ,
"promptTemplateEndToken" : " " ,
"promptTemplateSystemPrefix" : " <|start_header_id|>system<|end_header_id|> nn " ,
"promptTemplateSystemSuffix" : " <|eot_id|> " ,
"promptTemplateUserPrefix" : " <|start_header_id|>user<|end_header_id|> nn " ,
"promptTemplateUserSuffix" : " <|eot_id|> "
} Templat ini diterapkan ke semua panggilan titik akhir v1/Penyelesaian. Jika Anda memilih untuk tidak menggunakan templat, ada file bernama _chatonly.json yang memecah pesan dengan baris baru saja.
Membuat dan mengaktifkan pengguna melibatkan empat langkah utama. Ikuti petunjuk di bawah ini untuk menyiapkan pengguna baru.
Pertama, di dalam folder Users , buat file JSON untuk pengguna baru. Cara termudah untuk melakukannya adalah dengan menyalin file JSON pengguna yang ada, menempelkannya sebagai duplikat, lalu mengganti namanya. Berikut adalah contoh file JSON pengguna:
{
"port" : 5006 ,
"stream" : true ,
"customWorkflowOverride" : false ,
"customWorkflow" : " CodingWorkflow-LargeModel-Centric " ,
"routingConfig" : " assistantSingleModelCategoriesConfig " ,
"categorizationWorkflow" : " CustomCategorizationWorkflow " ,
"defaultParallelProcessWorkflow" : " SlowButQualityRagParallelProcessor " ,
"fileMemoryToolWorkflow" : " MemoryFileToolWorkflow " ,
"chatSummaryToolWorkflow" : " GetChatSummaryToolWorkflow " ,
"conversationMemoryToolWorkflow" : " CustomConversationMemoryToolWorkflow " ,
"recentMemoryToolWorkflow" : " RecentMemoryToolWorkflow " ,
"discussionIdMemoryFileWorkflowSettings" : " _DiscussionId-MemoryFile-Workflow-Settings " ,
"discussionDirectory" : " D: \ Temp " ,
"sqlLiteDirectory" : " D: \ Temp " ,
"chatPromptTemplateName" : " _chatonly " ,
"verboseLogging" : true ,
"chatCompleteAddUserAssistant" : true ,
"chatCompletionAddMissingAssistantGenerator" : true ,
"useOfflineWikiApi" : true ,
"offlineWikiApiHost" : " 127.0.0.1 " ,
"offlineWikiApiPort" : 5728 ,
"endpointConfigsSubDirectory" : " assistant-single-model " ,
"useFileLogging" : false
}0.0.0.0 , sehingga terlihat di jaringan Anda jika dijalankan di komputer lain. Menjalankan beberapa instance Wilmer pada port berbeda didukung.true , router dinonaktifkan, dan semua perintah hanya ditujukan ke alur kerja yang ditentukan, menjadikannya satu contoh alur kerja Wilmer.customWorkflowOverride bernilai true .Routing , tanpa ekstensi .json .DiscussionId .chatCompleteAddUserAssistant adalah true .DataFinder grup contoh. Selanjutnya, perbarui file _current-user.json untuk menentukan pengguna apa yang ingin Anda gunakan. Cocokkan nama file JSON pengguna baru, tanpa ekstensi .json .
CATATAN : Anda dapat mengabaikan ini jika Anda ingin menggunakan argumen --User saat menjalankan Wilmer.
Buat file JSON perutean di folder Routing . File ini dapat diberi nama apa pun yang Anda inginkan. Perbarui properti routingConfig di file JSON pengguna Anda dengan nama ini, tanpa ekstensi .json . Berikut adalah contoh file konfigurasi perutean:
{
"CODING" : {
"description" : " Any request which requires a code snippet as a response " ,
"workflow" : " CodingWorkflow "
},
"FACTUAL" : {
"description" : " Requests that require factual information or data " ,
"workflow" : " ConversationalWorkflow "
},
"CONVERSATIONAL" : {
"description" : " Casual conversation or non-specific inquiries " ,
"workflow" : " FactualWorkflow "
}
}.json , terpicu jika kategori dipilih. Di folder Workflow , buat folder baru yang sesuai dengan nama pengguna dari folder Users . Cara tercepat untuk melakukannya adalah dengan menyalin folder pengguna yang ada, menduplikasinya, dan mengganti namanya.
Jika Anda memilih untuk tidak melakukan perubahan lain, Anda harus menelusuri alur kerja dan memperbarui titik akhir agar mengarah ke titik akhir yang Anda inginkan. Jika Anda menggunakan contoh alur kerja yang ditambahkan dengan Wilmer, Anda seharusnya sudah baik-baik saja di sini.
Di dalam folder "Publik" Anda harus memiliki:
Alur kerja dalam proyek ini diubah dan dikontrol di folder Public/Workflows , dalam folder alur kerja spesifik pengguna Anda. Misalnya, jika pengguna Anda bernama socg dan Anda memiliki file socg.json di folder Users , maka dalam alur kerja Anda harus memiliki folder Workflows/socg .
Berikut adalah contoh tampilan alur kerja JSON:
[
{
"title" : " Coding Agent " ,
"agentName" : " Coder Agent One " ,
"systemPrompt" : " You are an exceptionally powerful and intelligent technical AI that is currently in a role play with a user in an online chat. n The instructions for the roleplay can be found below: n [ n {chat_system_prompt} n ] n Please continue the conversation below. Please be a good team player. This means working together towards a common goal, and does not always include being overly polite or agreeable. Disagreement when the other user is wrong can help foster growth in everyone, so please always speak your mind and critically review your peers. Failure to correct someone who is wrong could result in the team's work being a failure. " ,
"prompt" : " " ,
"lastMessagesToSendInsteadOfPrompt" : 6 ,
"endpointName" : " SocgMacStudioPort5002 " ,
"preset" : " Coding " ,
"maxResponseSizeInTokens" : 500 ,
"addUserTurnTemplate" : false
},
{
"title" : " Reviewing Agent " ,
"agentName" : " Code Review Agent Two " ,
"systemPrompt" : " You are an exceptionally powerful and intelligent technical AI that is currently in a role play with a user in an online chat. " ,
"prompt" : " You are in an online conversation with a user. The last five messages can be found here: n [ n {chat_user_prompt_last_five} n ] n You have already considered this request quietly to yourself within your own inner thoughts, and come up with a possible answer. The answer can be found here: n [ n {agent1Output} n ] n Please critically review the response, reconsidering your initial choices, and ensure that it is accurate, complete, and fulfills all requirements of the user's request. nn Once you have finished reconsidering your answer, please respond to the user with the correct and complete answer. nn IMPORTANT: Do not mention your inner thoughts or make any mention of reviewing a solution. The user cannot see the answer above, and any mention of it would confuse the user. Respond to the user with a complete answer as if it were the first time you were answering it. " ,
"endpointName" : " SocgMacStudioPort5002 " ,
"preset" : " Coding " ,
"maxResponseSizeInTokens" : 1000 ,
"addUserTurnTemplate" : true
}
]Alur kerja di atas terdiri dari node percakapan. Kedua node melakukan satu hal sederhana: mengirim pesan ke LLM yang ditentukan di titik akhir.
title . Sangat berguna untuk memberi nama akhiran ini dengan "Satu", "Dua", dll., untuk melacak keluaran agen. Output node pertama disimpan ke {agent1Output} , node kedua ke {agent2Output} , dan seterusnya.Endpoints , tanpa ekstensi .json .Presets , tanpa ekstensi .json .false (lihat contoh node pertama di atas). Jika Anda mengirimkan prompt, setel ini sebagai true (lihat contoh node kedua di atas). NOTE: The addDiscussionIdTimestampsForLLM feature was an experiment, and truthfully I am not happy with how the experiment went. Even the largest LLMs misread the timestamps, got confused by them, etc. I have other plans for this feature which should be far more useful, but I left it in and won't be removing it, even though I don't necessarily recommend using it. -Socg
Anda dapat menggunakan beberapa variabel dalam petunjuk ini. Ini akan diganti dengan tepat saat runtime:
{chat_user_prompt_last_one} : Pesan terakhir dalam percakapan, tanpa tag template prompt yang membungkus pesan.{templated_user_prompt_last_one} : Pesan terakhir dalam percakapan, dibungkus dengan tag template prompt pengguna/asisten yang sesuai.{chat_system_prompt} : Prompt sistem yang dikirim dari ujung depan. Sering berisi kartu karakter dan info penting lainnya.{templated_system_prompt} : Prompt sistem dari ujung depan, dibungkus dengan tag templat prompt sistem yang sesuai.{agent#Output} : # diganti dengan nomor yang Anda inginkan. Setiap node menghasilkan output agen. Node pertama selalu 1, dan setiap node berikutnya bertambah dengan 1. Misalnya, {agent1Output} untuk node pertama, {agent2Output} untuk yang kedua, dll.{category_colon_descriptions} : Menarik kategori dan deskripsi dari file Routing JSON Anda.{categoriesSeparatedByOr} : Menarik nama kategori, dipisahkan oleh "atau".[TextChunk] : Variabel khusus yang unik untuk prosesor paralel, kemungkinan tidak sering digunakan.Catatan: Untuk pemahaman yang lebih dalam tentang bagaimana kenangan bekerja, silakan lihat bagian pemahaman kenangan
Node ini akan menarik N jumlah ingatan (atau pesan terbaru jika tidak ada diskusi yang ada) dan menambahkan pembatas khusus di antara mereka. Jadi jika Anda memiliki file memori dengan 3 kenangan, dan pilih pembatas " n --------- n" maka Anda mungkin mendapatkan yang berikut:
This is the first memory
---------
This is the second memory
---------
This is the third memory
Menggabungkan simpul ini dengan ringkasan obrolan dapat memungkinkan LLM untuk menerima tidak hanya ringkasan ringkasan dari seluruh percakapan secara keseluruhan, tetapi juga daftar semua kenangan yang dibuat ringkasan, yang mungkin berisi informasi yang lebih rinci dan granular tentang dia. Mengirim keduanya bersama-sama, di samping 15-20 pesan terakhir, dapat membuat kesan memori yang terus-menerus dan terus-menerus dari seluruh obrolan hingga pesan terbaru. Perawatan khusus untuk membuat petunjuk yang baik untuk generasi kenangan dapat membantu memastikan detail yang Anda pedulikan ditangkap, sementara detail yang kurang relevan diabaikan.
Node ini tidak akan menghasilkan kenangan baru; Ini agar kunci alur kerja dapat dihormati jika Anda menggunakannya pada pengaturan multi-komputer. Saat ini cara terbaik untuk menghasilkan kenangan adalah simpul fullchatsummary.


