Ainur
1.0.0
Ainur adalah model pembelajaran mendalam yang inovatif untuk generasi musik multimodal bersyarat. Ini dirancang untuk menghasilkan sampel musik stereo berkualitas tinggi pada 48 kHz yang dikondisikan pada berbagai input, seperti lirik, deskriptor teks, dan audio lainnya. Arsitektur difusi hierarki Ainur, dikombinasikan dengan embeddings CLASP, memungkinkannya menghasilkan komposisi musik yang koheren dan ekspresif di berbagai genre dan gaya. 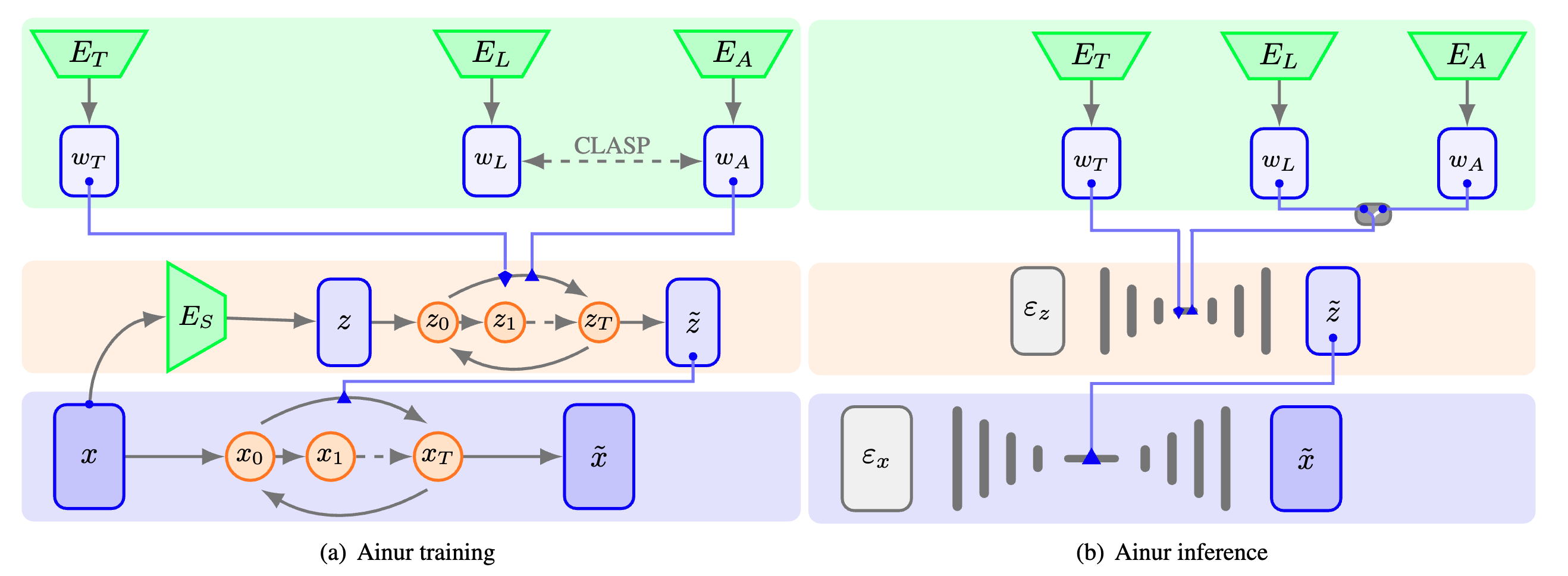

Generasi Bersyarat: Ainur memungkinkan pembuatan musik yang dikondisikan pada lirik, deskriptor teks, atau audio lainnya, menawarkan pendekatan yang fleksibel dan kreatif terhadap komposisi musik.
Output Berkualitas Tinggi: Model ini mampu menghasilkan sampel musik stereo 22 detik pada 48 kHz, memastikan fidelitas dan realisme tinggi.
Pembelajaran Multimodal: Ainur menggunakan embeddings CLASP, yang merupakan representasi multimodal dari lirik dan audio, untuk memfasilitasi penyelarasan lirik tekstual dengan fragmen audio yang sesuai.
Evaluasi Objektif: Kami menyediakan metrik evaluasi yang komprehensif, termasuk Frechet Audio Distance (FAD) dan CLASP Cycle Consistency (C3), untuk menilai kualitas dan koherensi musik yang dihasilkan.
Untuk menjalankan Ainur, pastikan Anda telah menginstal dependensi berikut:
Python 3.8+
PyTorch 1.13.1
Petir PyTorch 2.0.0
Anda dapat menginstal paket Python yang diperlukan dengan menjalankan:
instalasi pip -r persyaratan.txt
Kloning repositori ini:
git clone https://github.com/ainur-music/ainur.gitcd ainur
Instal dependensi (seperti disebutkan di atas).
Jalankan Ainur dengan input yang Anda inginkan. Lihat contoh buku catatan di folder examples untuk panduan penggunaan Ainur untuk pembuatan musik. ( segera hadir )
Ainur memandu pembuatan musik dan meningkatkan kualitas vokal melalui informasi tekstual dan lirik yang disinkronkan. Berikut contoh masukan untuk melatih dan menghasilkan musik dengan Ainur:
«Red Hot Chili Peppers, Alternative Rock, 7 of 19»
«[00:45.18] I got your hey oh, now listen what I say oh [...]»
Kami membandingkan kinerja Ainur dengan model canggih lainnya untuk pembuatan teks-ke-musik. Kami mendasarkan evaluasi pada metrik objektif seperti FAD dan menggunakan model penyematan yang berbeda sebagai referensi: VGGish, YAMNet, dan Trill.
| Model | Nilai [kHz] | Panjang [s] | Parameter [M] | Langkah Inferensi | Waktu Inferensi [s] ↓ | FAD VGGish ↓ | FAD YAMNet ↓ | Getaran FAD ↓ |
|---|---|---|---|---|---|---|---|---|
| Ainur | 48@2 | 22 | 910 | 50 | 14.5 | 8.38 | 20.70 | 0,66 |
| Ainur (tidak ada GESPER) | 48@2 | 22 | 910 | 50 | 14.7 | 8.40 | 20.86 | 0,64 |
| AudioLDM | 16@1 | 22 | 181 | 200 | 2.20 | 15.5 | 784.2 | 0,52 |
| AudioLDM 2 | 16@1 | 22 | 1100 | 100 | 20.8 | 8.67 | 23.92 | 0,52 |
| Jenderal Musik | 16@1 | 22 | 300 | 1500 | 81.3 | 14.4 | 53.04 | 0,66 |
| kotak juke | 16@1 | 1 | 1000 | - | 538 | 20.4 | 178.1 | 1.59 |
| MusikLM | 16@1 | 5 | 1890 | 125 | 153 | 15.0 | 61.58 | 0,47 |
| Rifusi | 44.1@1 | 5 | 890 | 50 | 6.90 | 5.24 | 15.96 | 0,67 |
Jelajahi dan dengarkan musik yang dihasilkan oleh Ainur di sini.
Anda dapat mengunduh pos pemeriksaan Ainur dan CLASP terlatih dari drive:
Pos pemeriksaan terbaik Ainur (model dengan kerugian terendah selama pelatihan)
Pos pemeriksaan terakhir Ainur (model dengan jumlah langkah pelatihan terbanyak)
pos pemeriksaan CLASP
Proyek ini dilisensikan di bawah Lisensi MIT - lihat file LISENSI untuk detailnya.
© 2023 Giuseppe Concialdi


