JoyVASA
1.0.0
Xuyang Cao 1* Guoxin Wang 12* Sheng Shi 1* Jun Zhao 1 Yang Yao 1
Jintao Fei 1 Minyu Gao 1
1 JD Health International Inc. 2 Universitas Zhejiang
Animasi potret berbasis audio telah membuat kemajuan signifikan dengan model berbasis difusi, meningkatkan kualitas video dan akurasi lipsync. Namun, meningkatnya kompleksitas model ini telah menyebabkan inefisiensi dalam pelatihan dan inferensi, serta kendala pada durasi video dan kontinuitas antar-frame. Dalam makalah ini, kami mengusulkan JoyVASA, metode berbasis difusi untuk menghasilkan dinamika wajah dan gerakan kepala dalam animasi wajah berbasis audio. Secara khusus, pada tahap pertama, kami memperkenalkan kerangka representasi wajah terpisah yang memisahkan ekspresi wajah dinamis dari representasi wajah 3D statis. Pemisahan ini memungkinkan sistem menghasilkan video yang lebih panjang dengan menggabungkan representasi wajah 3D statis dengan rangkaian gerakan dinamis. Kemudian, pada tahap kedua, transformator difusi dilatih untuk menghasilkan rangkaian gerakan langsung dari isyarat audio, terlepas dari identitas karakter. Terakhir, generator yang dilatih pada tahap pertama menggunakan representasi wajah 3D dan rangkaian gerakan yang dihasilkan sebagai masukan untuk membuat animasi berkualitas tinggi. Dengan representasi wajah yang dipisahkan dan proses pembuatan gerakan yang tidak bergantung pada identitas, JoyVASA melampaui potret manusia untuk menganimasikan wajah hewan dengan mulus. Model ini dilatih pada kumpulan data gabungan data pribadi berbahasa Mandarin dan bahasa Inggris publik, sehingga memungkinkan dukungan multibahasa. Hasil eksperimen memvalidasi efektivitas pendekatan kami. Pekerjaan di masa depan akan fokus pada peningkatan kinerja real-time dan menyempurnakan kontrol ekspresi, yang selanjutnya memperluas aplikasi kerangka kerja dalam animasi potret.
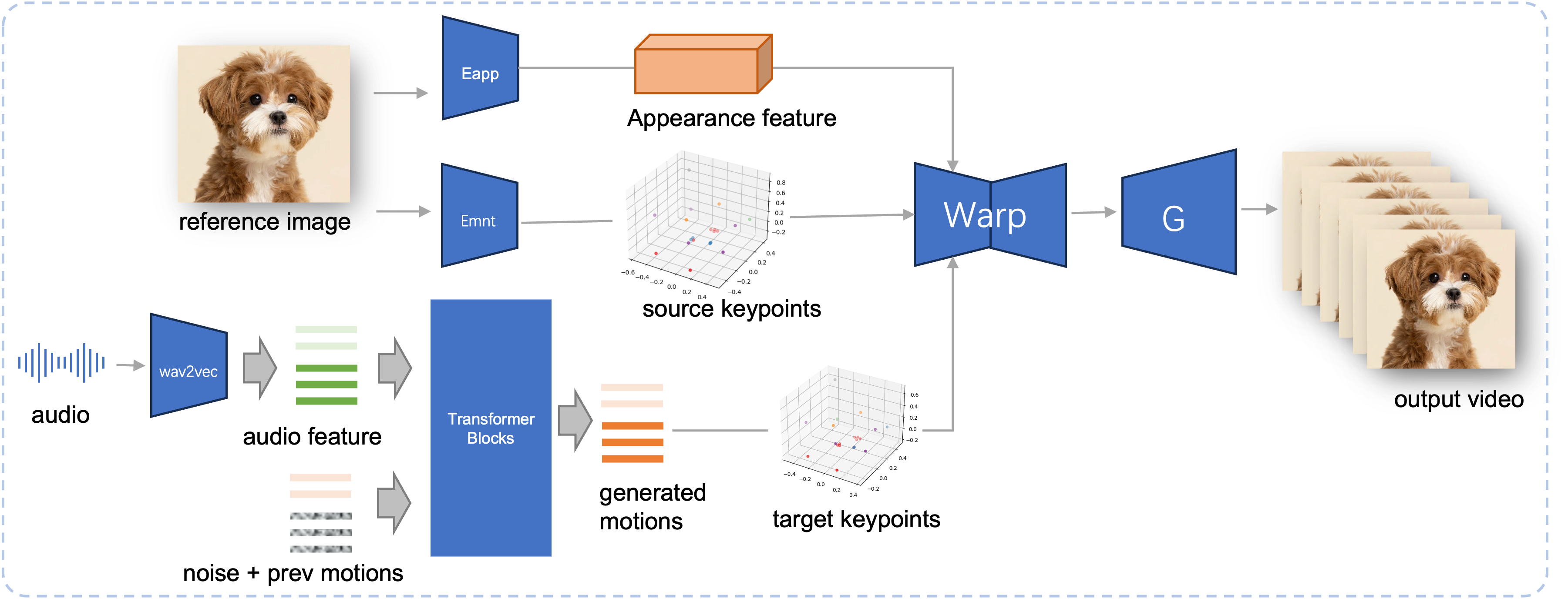
Pipa Inferensi dari JoyVASA yang diusulkan. Dengan adanya gambar referensi, pertama-tama kami mengekstrak fitur tampilan wajah 3D menggunakan encoder tampilan di LivePortrait, dan juga serangkaian titik kunci 3D yang dipelajari menggunakan encoder gerakan. Untuk masukan ucapan, fitur audio awalnya diekstraksi menggunakan encoder wav2vec2. Urutan gerakan yang digerakkan oleh audio kemudian diambil sampelnya menggunakan model difusi yang dilatih pada tahap kedua dengan cara jendela geser. Dengan menggunakan titik kunci 3D dari gambar referensi, dan sampel urutan gerakan target, titik kunci target dihitung. Terakhir, fitur tampilan wajah 3D dibengkokkan berdasarkan titik kunci sumber dan target dan dirender oleh generator untuk menghasilkan video keluaran akhir.
Persyaratan sistem:
Ubuntu:
Diuji pada Ubuntu 20.04, Cuda 11.3
GPU yang diuji: A100
jendela:
Diuji pada Windows 11, CUDA 12.1
GPU yang diuji: Laptop RTX 4060 GPU VRAM 8GB
Ciptakan lingkungan:
# 1. Buat lingkungan dasarconda buat -n joyvasa python=3.10 -y conda mengaktifkan joyvasa # 2. Instal persyaratanpip install -r persyaratan.txt# 3. Instal ffmpegsudo apt-get update sudo apt-get install ffmpeg -y# 4. Instal MultiScaleDeformableAttentioncd src/utils/dependencies/XPose/models/UniPose/ops python setup.py build installcd - # sama dengan cd ../../../../../../../
Pastikan Anda telah menginstal git-lfs dan mengunduh semua pos pemeriksaan berikut ke pretrained_weights :
git lfs instal git klon https://huggingface.co/jdh-algo/JoyVASA
Kami mendukung dua jenis encoder audio, termasuk wav2vec2-base, dan hubert-chinese.
Jalankan perintah berikut untuk mengunduh beban terlatih hubert-china:
git lfs instal git clone https://huggingface.co/TencentGameMate/chinese-hubert-base
Untuk mendapatkan bobot terlatih berbasis wav2vec2, jalankan perintah berikut:
git lfs instal git clone https://huggingface.co/facebook/wav2vec2-base-960h
Catatan
Model pembuatan gerakan dengan encoder wav2vec2 akan didukung nanti.
# !pip install -U "huggingface_hub[cli]"huggingface-cli unduh KwaiVGI/LivePortrait --local-dir pretrained_weights --exclude "*.git*" "README.md" "docs"
Merujuk ke Liveportrait untuk metode pengunduhan lebih lanjut.
pretrained_weights Direktori pretrained_weights terakhir akan terlihat seperti ini:
./pretrained_weights/
├── insightface
│ └── models
│ └── buffalo_l
│ ├── 2d106det.onnx
│ └── det_10g.onnx
├── JoyVASA
│ ├── motion_generator
│ │ └── iter_0020000.pt
│ └── motion_template
│ └── motion_template.pkl
├── liveportrait
│ ├── base_models
│ │ ├── appearance_feature_extractor.pth
│ │ ├── motion_extractor.pth
│ │ ├── spade_generator.pth
│ │ └── warping_module.pth
│ ├── landmark.onnx
│ └── retargeting_models
│ └── stitching_retargeting_module.pth
├── liveportrait_animals
│ ├── base_models
│ │ ├── appearance_feature_extractor.pth
│ │ ├── motion_extractor.pth
│ │ ├── spade_generator.pth
│ │ └── warping_module.pth
│ ├── retargeting_models
│ │ └── stitching_retargeting_module.pth
│ └── xpose.pth
├── TencentGameMate:chinese-hubert-base
│ ├── chinese-hubert-base-fairseq-ckpt.pt
│ ├── config.json
│ ├── gitattributes
│ ├── preprocessor_config.json
│ ├── pytorch_model.bin
│ └── README.md
└── wav2vec2-base-960h
├── config.json
├── feature_extractor_config.json
├── model.safetensors
├── preprocessor_config.json
├── pytorch_model.bin
├── README.md
├── special_tokens_map.json
├── tf_model.h5
├── tokenizer_config.json
└── vocab.jsonCatatan
Folder TencentGameMate:chinese-hubert-base di Windows harus diganti namanya menjadi chinese-hubert-base .
Hewan:
inferensi python.py -r aset/examples/imgs/joyvasa_001.png -a aset/examples/audios/joyvasa_001.wav --animation_mode animal --cfg_scale 2.0
Manusia:
python inference.py -r aset/examples/imgs/joyvasa_003.png -a aset/examples/audios/joyvasa_003.wav --animation_mode manusia --cfg_scale 2.0
Anda dapat mengubah cfg_scale untuk mendapatkan hasil dengan ekspresi dan pose yang berbeda.
Catatan
Mode Animasi dan Gambar Referensi yang tidak cocok dapat mengakibatkan hasil yang salah.
Gunakan perintah berikut untuk memulai demo web:
aplikasi python.py
Demo akan dibuat di http://127.0.0.1:7862.
Jika menurut Anda pekerjaan kami bermanfaat, mohon pertimbangkan untuk mengutip kami:
@misc{cao2024joyvasaportraitanimalimage,
title={JoyVASA: Portrait and Animal Image Animation with Diffusion-Based Audio-Driven Facial Dynamics and Head Motion Generation},
author={Xuyang Cao and Guoxin Wang and Sheng Shi and Jun Zhao and Yang Yao and Jintao Fei and Minyu Gao},
year={2024},
eprint={2411.09209},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2411.09209},
}Kami ingin mengucapkan terima kasih kepada para kontributor repositori LivePortrait, Open Facevid2vid, InsightFace, X-Pose, DiffPoseTalk, Hallo, wav2vec 2.0, Chinese Speech Pretrain, Q-Align, Syncnet, dan VBench, atas penelitian terbuka dan kerja luar biasa mereka.


