synthetic data generator
0.2.3
Ganti Bahasa: 简体中文 | Dokumen API Terbaru | Peta Jalan | Bergabunglah dengan Grup WeChat
Contoh Colab: LLM: Sintesis Data | LLM: Inferensi di Luar Tabel | CTGAN dengan Tingkat Miliaran Data yang didukung
Synthetic Data Generator (SDG) adalah kerangka kerja khusus yang dirancang untuk menghasilkan data tabular terstruktur berkualitas tinggi.
Data sintetis tidak berisi informasi sensitif apa pun, namun tetap mempertahankan karakteristik penting dari data asli, sehingga dikecualikan dari peraturan privasi seperti GDPR dan ADPPA.
Data sintetis berkualitas tinggi dapat digunakan dengan aman di berbagai domain termasuk berbagi data, pelatihan dan debugging model, pengembangan dan pengujian sistem, dll.
Kami sangat senang menerima Anda di sini dan menantikan kontribusi Anda, mulailah proyek ini melalui Panduan Ikhtisar Berkontribusi ini!
Pencapaian dan jadwal utama kami saat ini adalah sebagai berikut:
21 Nov 2024: 1) Integrasi Model - Kami telah mengintegrasikan model GaussianCopula ke dalam Sistem Pemroses Data kami. Lihat contoh kode di PR ini; 2) Kualitas Sintetis - Kami menerapkan deteksi otomatis hubungan kolom data dan mengizinkan spesifikasi hubungan, meningkatkan kualitas data sintetis (Contoh Kode); 3) Peningkatan Kinerja - Kami secara signifikan mengurangi penggunaan memori GaussianCopula saat menangani data diskrit, memungkinkan pelatihan pada ribuan entri data kategorikal dengan pengaturan 2C4G !
30 Mei 2024: Modul Pemroses Data resmi digabungkan. Modul ini akan: 1) membantu SDG mengonversi format beberapa kolom data (seperti kolom Tanggal dan Waktu) sebelum dimasukkan ke dalam model (agar tidak diperlakukan sebagai tipe diskrit), dan secara terbalik mengonversi data yang dihasilkan model ke dalam format asli ; 2) melakukan pra-pemrosesan dan pasca-pemrosesan yang lebih disesuaikan pada berbagai tipe data; 3) dengan mudah menangani masalah seperti nilai nol pada data asli; 4) mendukung sistem plug-in.
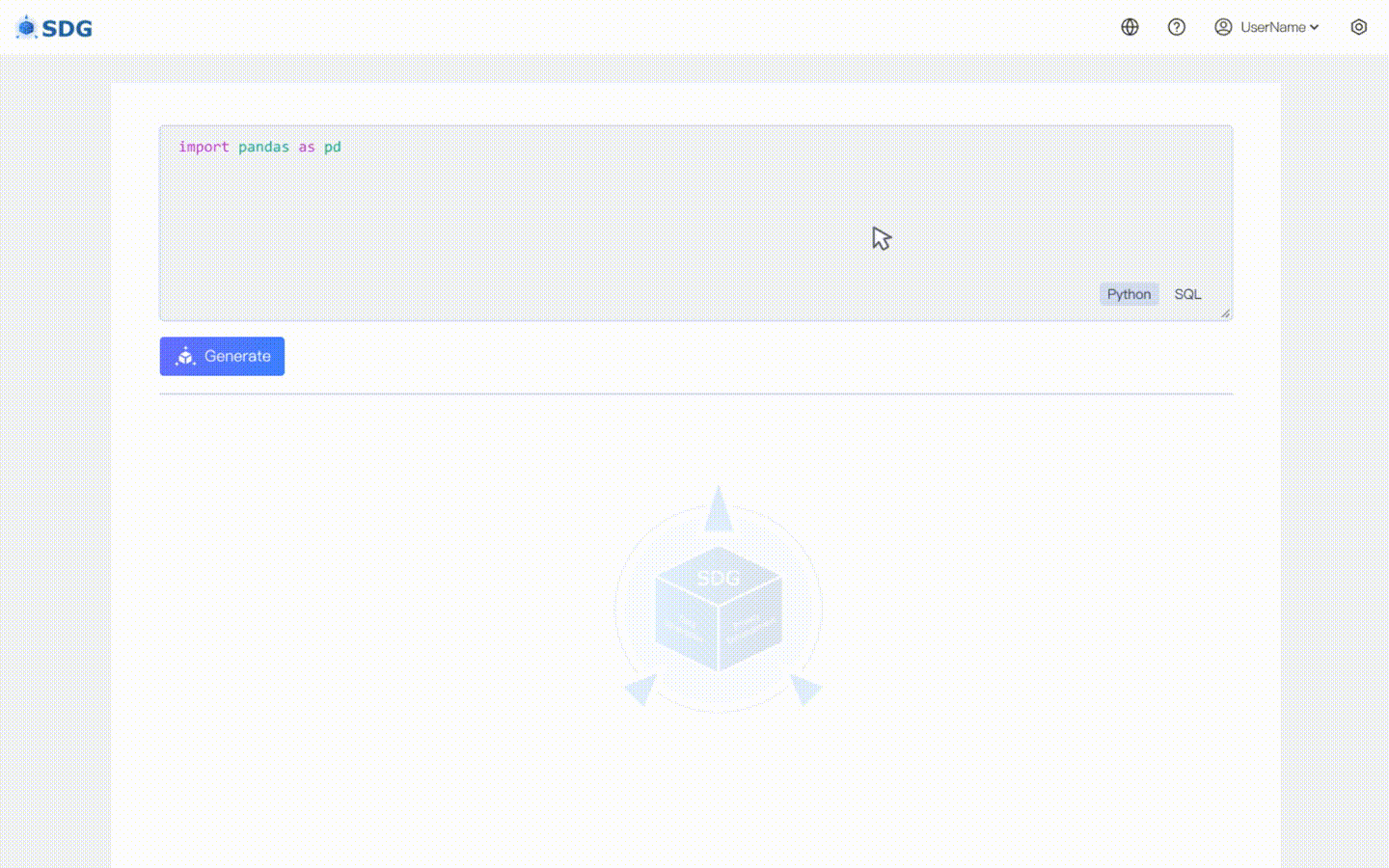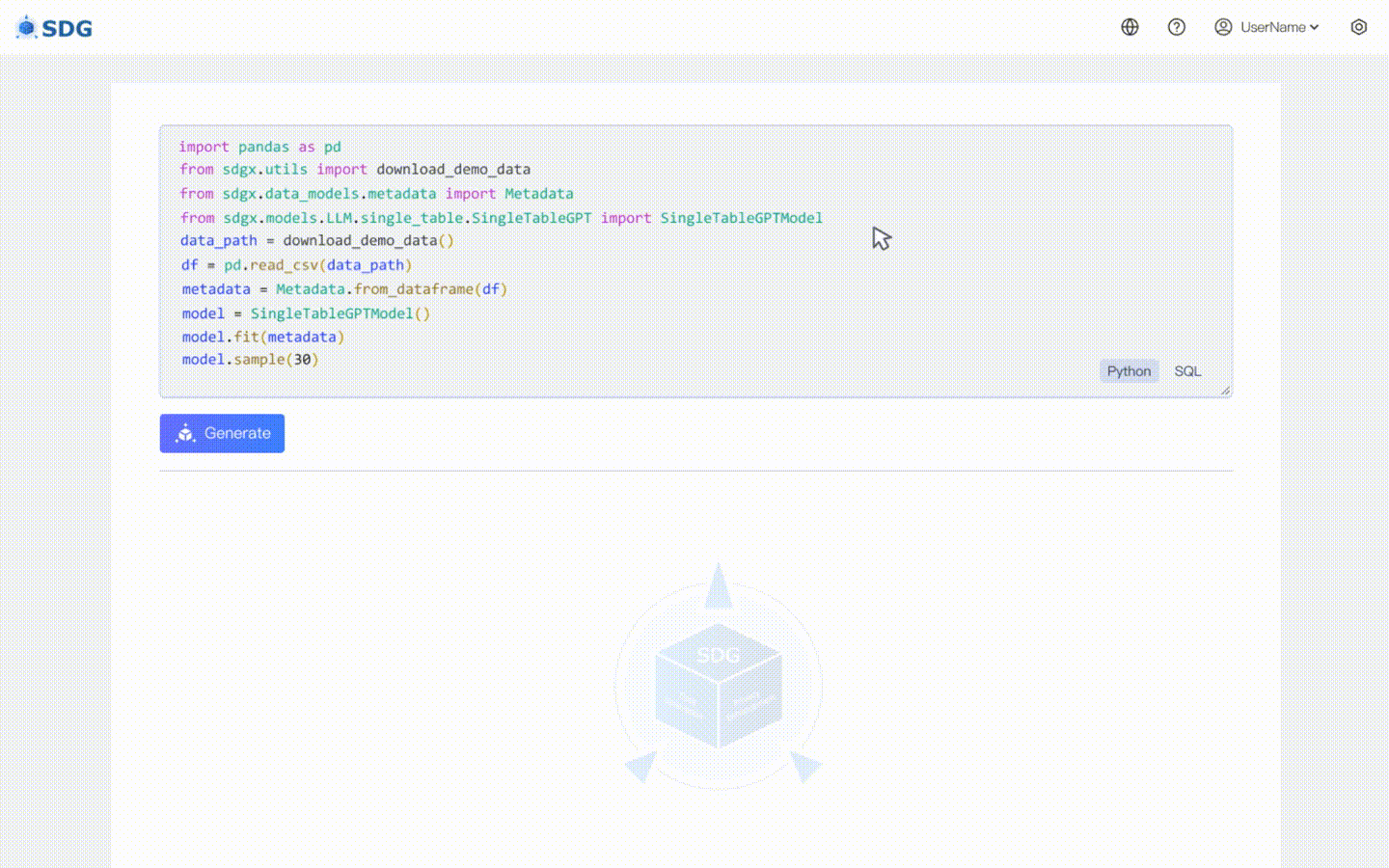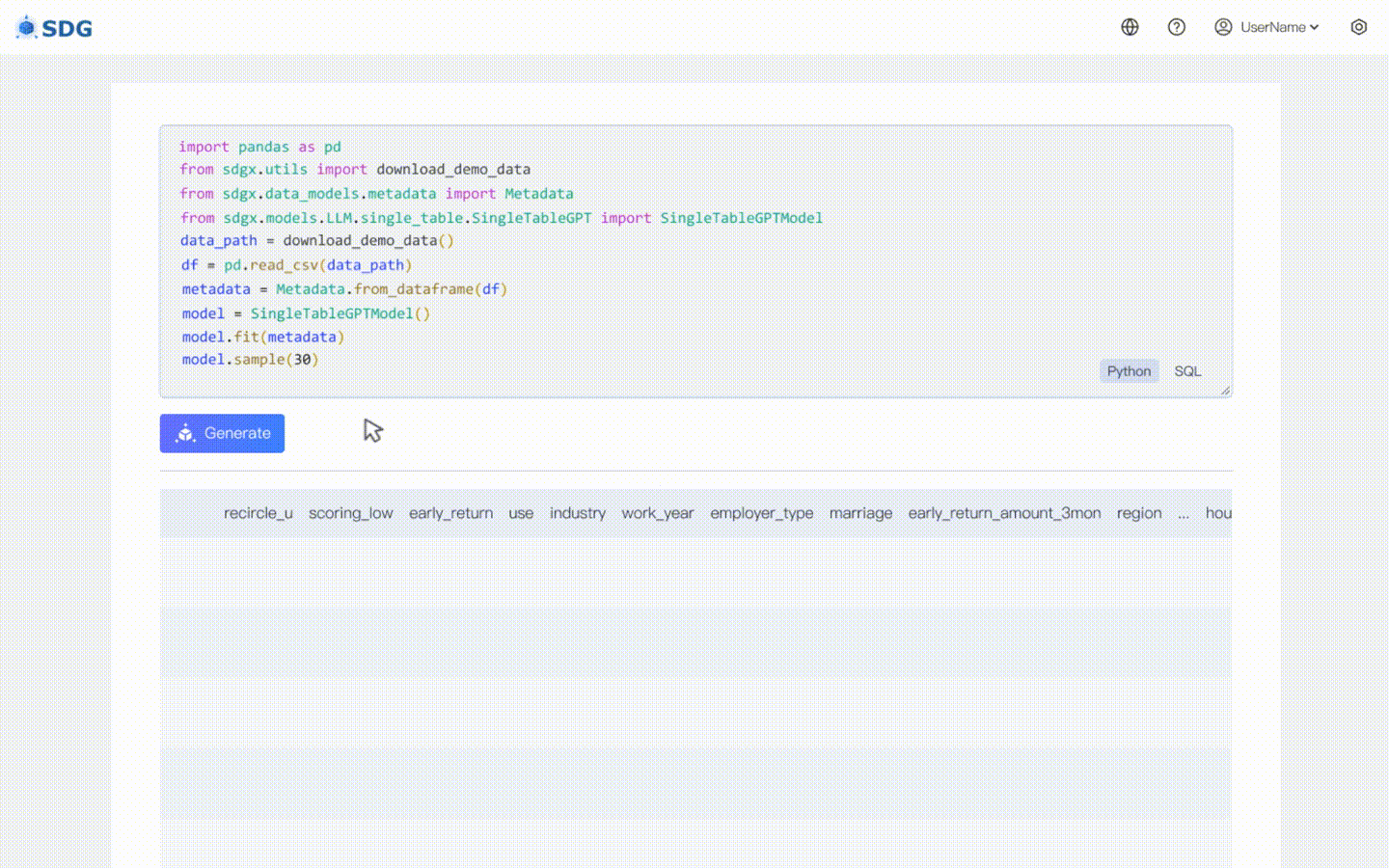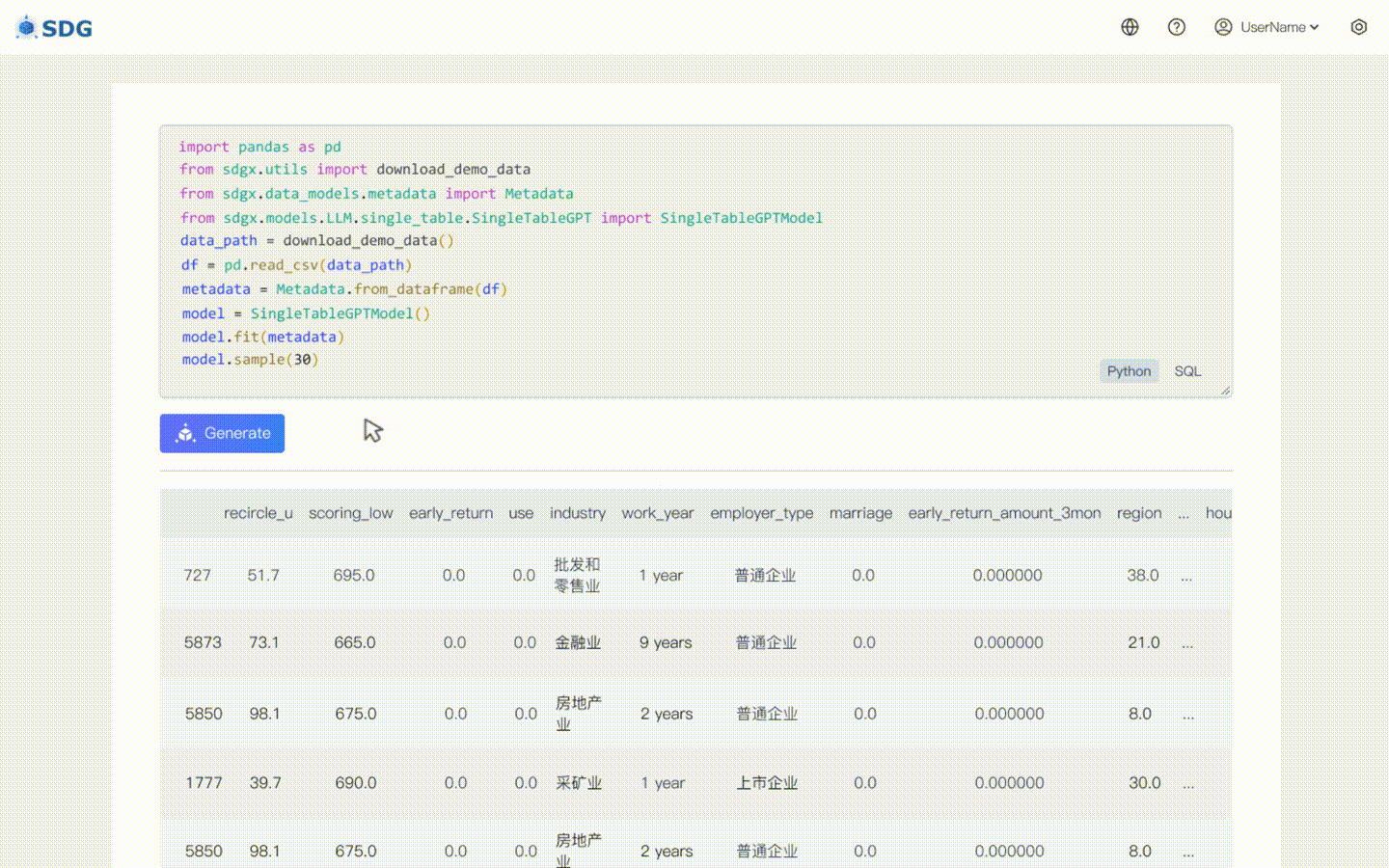
20 Februari 2024: model sintesis data tabel tunggal berdasarkan LLM disertakan, lihat contoh colab: LLM: Sintesis Data dan LLM: Inferensi Fitur di Luar Tabel.
7 Februari 2024: Kami meningkatkan sdgx.data_models.metadata untuk mendukung informasi metadata yang menjelaskan tabel tunggal dan beberapa tabel, mendukung beberapa tipe data, mendukung inferensi tipe data otomatis. lihat contoh colab: Metadata Tabel Tunggal SDG。
20 Des 2023: v0.1.0 dirilis, model CTGAN yang mendukung miliaran kemampuan pemrosesan data disertakan, lihat tolok ukur kami terhadap SDV, di mana SDG mencapai konsumsi memori yang lebih sedikit dan menghindari error selama pelatihan. Untuk penggunaan khusus, lihat contoh colab: CTGAN yang didukung Miliaran Data Tingkat.
10 Agustus 2023: Baris pertama kode SDG diterapkan.
LLM telah lama digunakan untuk memahami dan menghasilkan berbagai jenis data. Faktanya, LLM juga memiliki kemampuan tertentu dalam pembuatan data tabular. Selain itu, ia memiliki beberapa kemampuan yang tidak dapat dicapai dengan cara tradisional (berdasarkan metode GAN atau metode statistik).
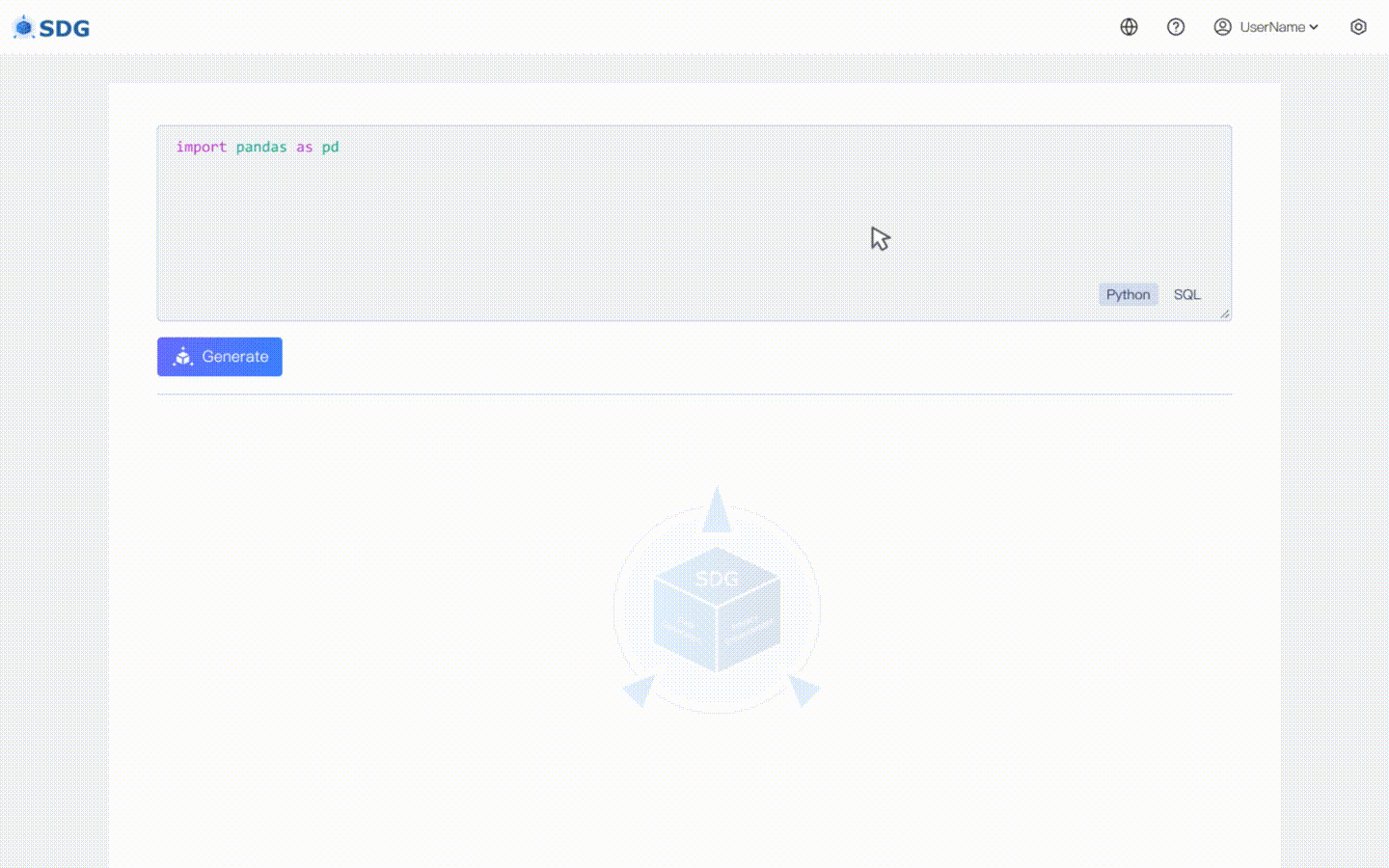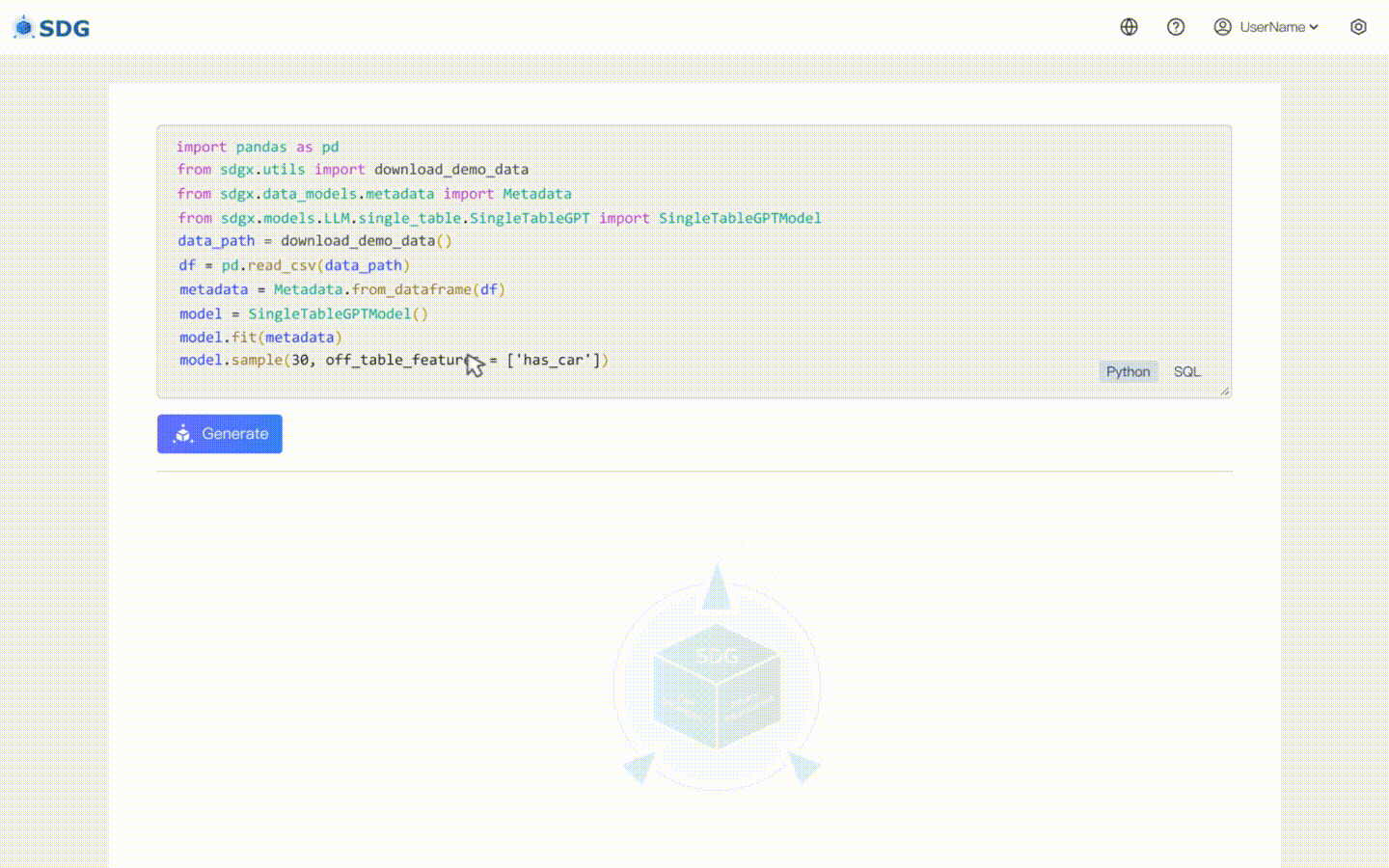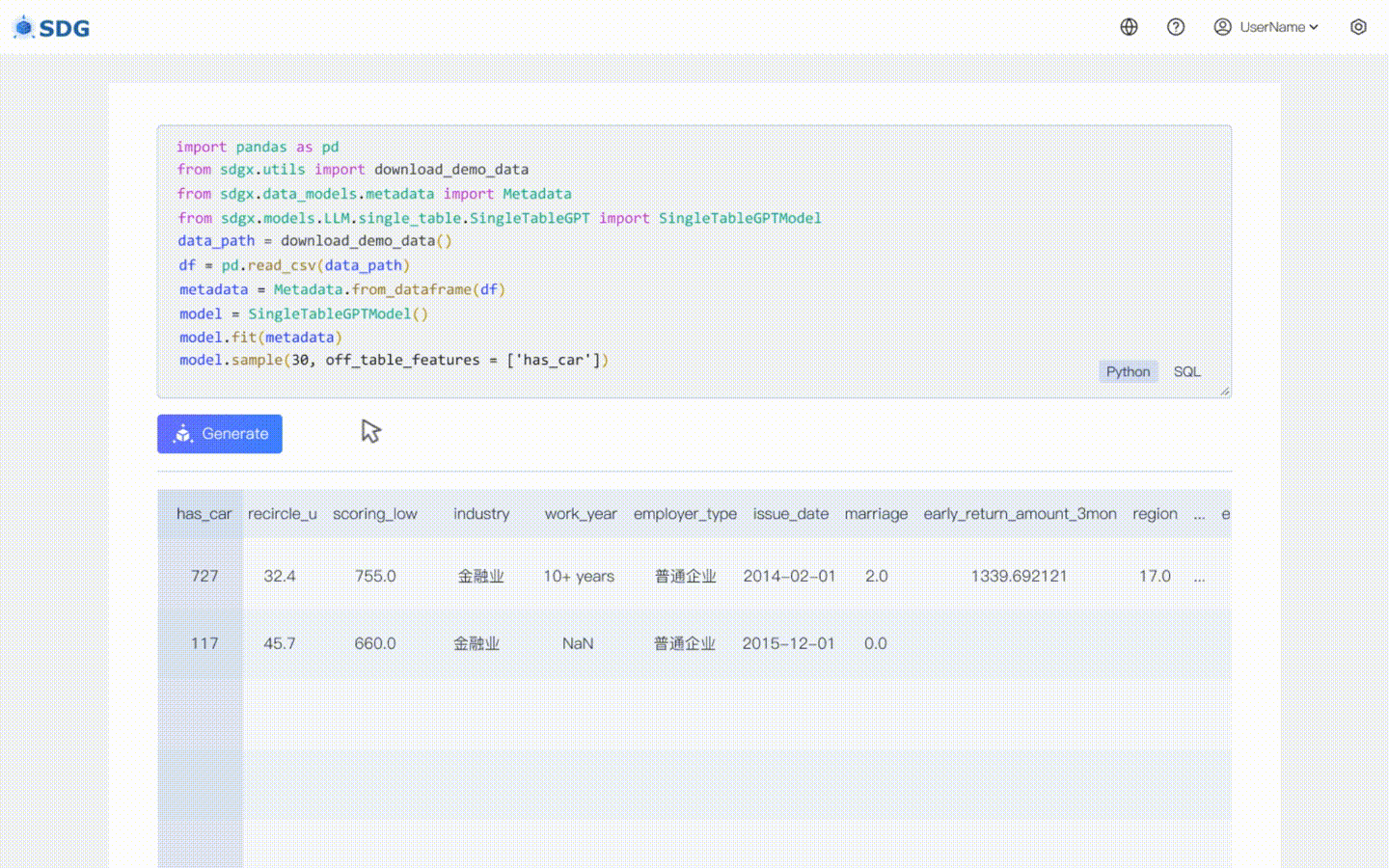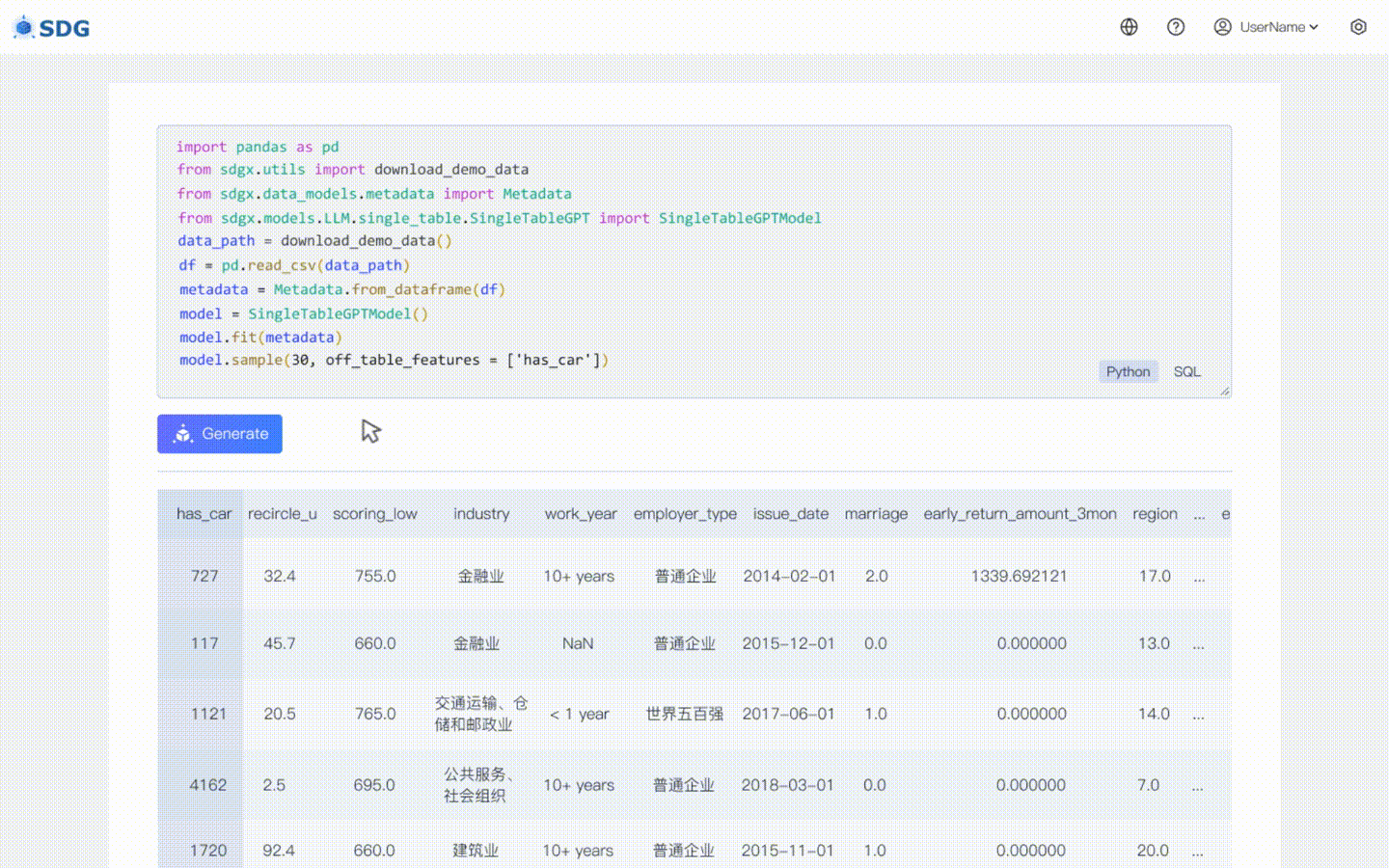
sdgx.models.LLM.single_table.gpt.SingleTableGPTModel kami mengimplementasikan dua fitur baru:
Tidak diperlukan data pelatihan, data sintetis dapat dihasilkan berdasarkan data metadata, lihat di contoh colab kami.
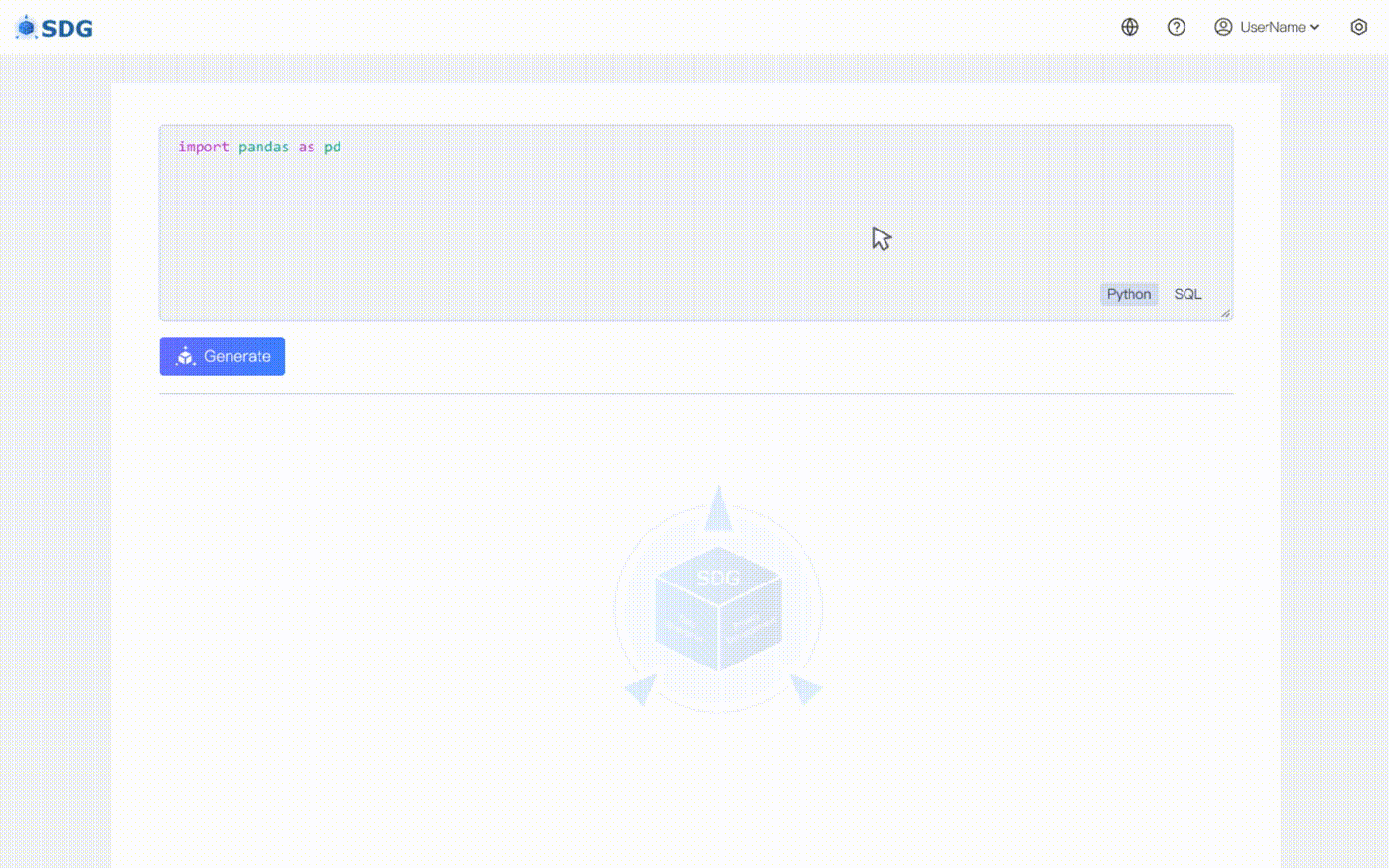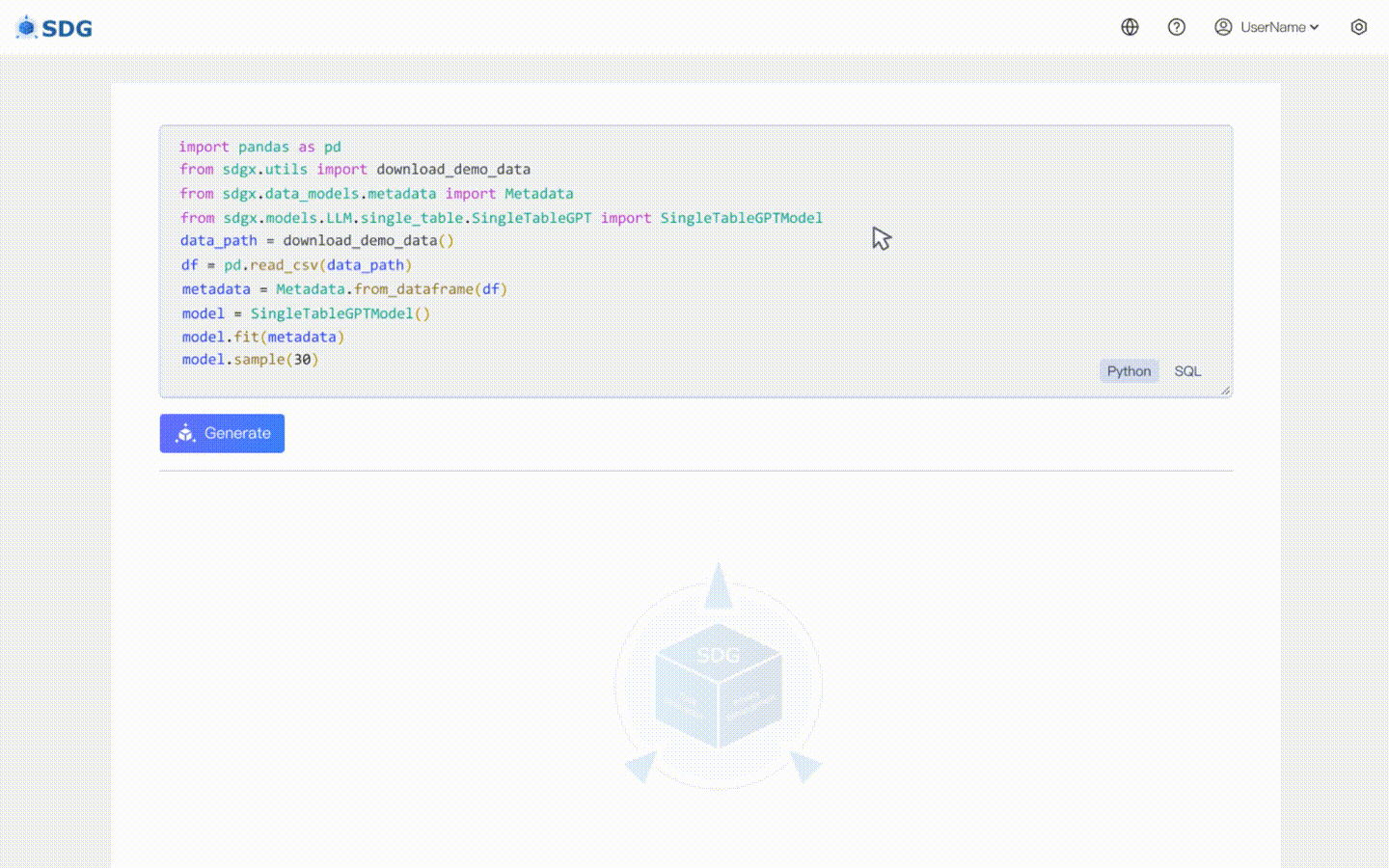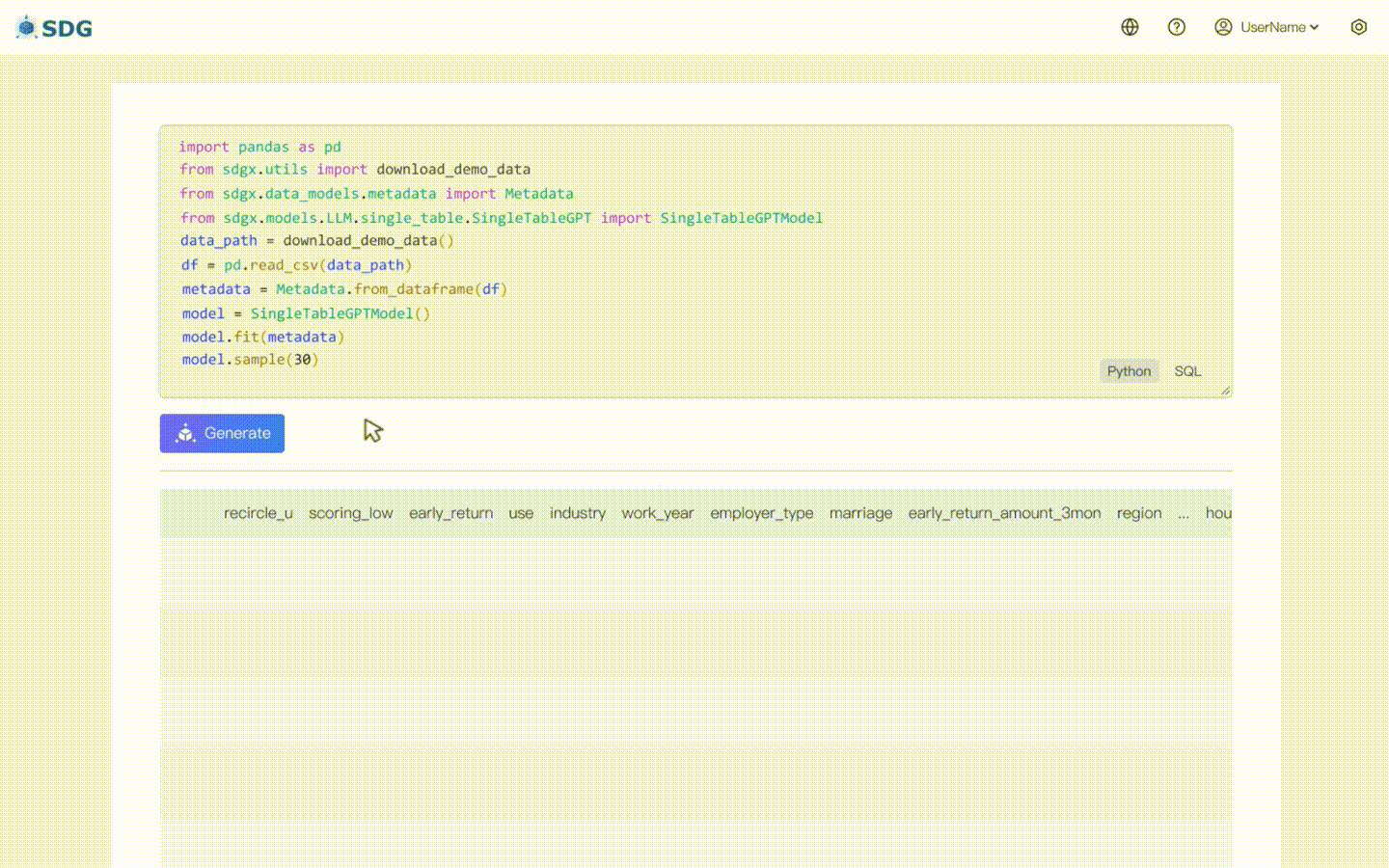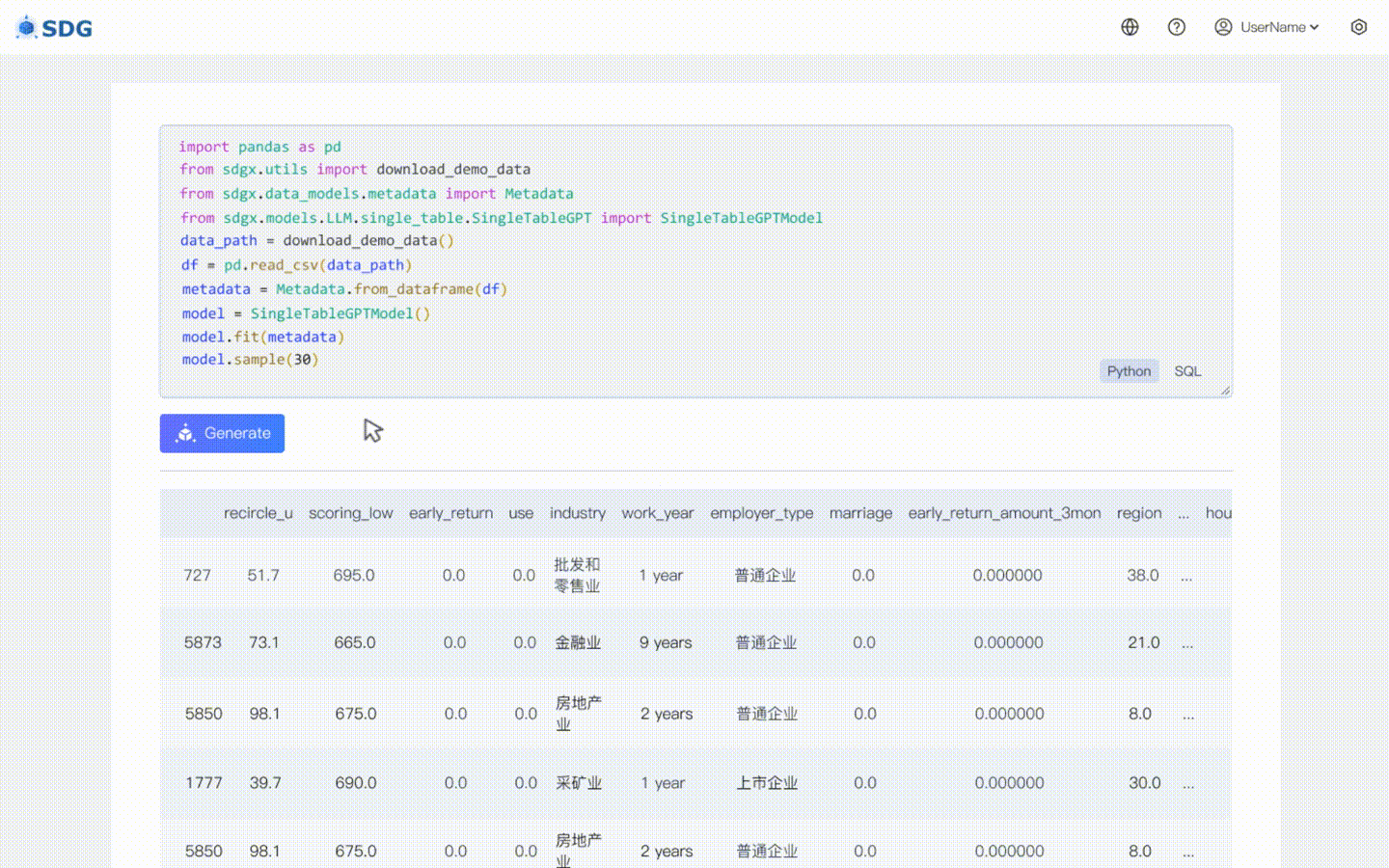
Menyimpulkan data kolom baru berdasarkan data yang ada di tabel dan pengetahuan yang dikuasai LLM, lihat di contoh colab kami.
Kemajuan teknologi:
Mendukung berbagai algoritma sintesis data statistik, model pembuatan data sintetis berbasis LLM juga terintegrasi;
Dioptimalkan untuk data besar, secara efektif mengurangi konsumsi memori;
Terus memantau kemajuan terkini di dunia akademis dan industri, dan memperkenalkan dukungan untuk algoritme dan model terbaik secara tepat waktu.
Peningkatan privasi:
SDG mendukung privasi diferensial, anonimisasi, dan metode lain untuk meningkatkan keamanan data sintetis.
Mudah untuk diperluas:
Mendukung perluasan model, pemrosesan data, konektor data, dll. dalam bentuk paket plug-in.
Anda dapat menggunakan gambar yang dibuat sebelumnya untuk merasakan fitur-fitur terbaru dengan cepat.
buruh pelabuhan menarik idsteam/sdgx:terbaru
pip instal sdgx
Gunakan SDG dengan menginstalnya melalui kode sumber.
git clone [email protected]:hitsz-ids/synthetic-data-generator.git pip install .# Atau instal dari gitpip install git+https://github.com/hitsz-ids/synthetic-data-generator.git
from sdgx.data_connectors.csv_connector import CsvConnectorfrom sdgx.models.ml.single_table.ctgan import CTGANSynthesizerModelfrom sdgx.synthesizer import Synthesizerfrom sdgx.utils import download_demo_data# Ini akan mengunduh data demo ke ./datasetdataset_csv = download_demo_data()# Buat konektor data untuk csv filedata_connector = CsvConnector(path=dataset_csv)# Inisialisasi synthesizer, gunakan CTGAN modelsynthesizer = Synthesizer(model=CTGANSynthesizerModel(epochs=1), # Untuk demodata_connector=data_connector cepat, )# Sesuaikan modelsynthesizer.fit()# Samplesampled_data = synthesizer.sample(1000)print(sampled_data)
Data nyata adalah sebagai berikut:
>>> data_connector.read() usia kelas kerja fnlwgt pendidikan ... capitalloss jam per minggu kelas negara asal0 2 Pemerintah negara bagian 77516 Sarjana ... 0 2 Amerika Serikat <=50K1 3 Wiraswasta-bukan-inc 83311 Sarjana .. 0 0 0 Amerika Serikat <=50K2 2 Swasta 215646 lulusan HS ... 0 2 Amerika Serikat <=50K3 3 Swasta 234721 11 ... 0 2 Amerika Serikat <=50K4 1 Swasta 338409 Sarjana ... 0 2 Kuba <=50K... ... ... ... ... ... . .. ... ... ...48837 2 Swasta 215419 Sarjana ... 0 2 Amerika Serikat <=50K48838 4 NaN 321403 Lulusan HS ... 0 2 Amerika Serikat <=50K48839 2 Swasta 374983 Sarjana ... 0 3 Amerika Serikat <=50K48840 2 Swasta 83891 Sarjana ... 0 2 Amerika Serikat <=50K48841 1 Wiraswasta 182148 Sarjana . .. 0 3 Amerika Serikat >50K[48842 baris x 15 kolom]
Data sintetis adalah sebagai berikut:
>>> sampled_data usia kelas kerja fnlwgt pendidikan ... capitalloss jamperminggu kelas negara asal0 1 NaN 28219 Beberapa perguruan tinggi ... 0 2 Puerto-Riko <=50K1 2 Swasta 250166 Lulusan HS ... 0 2 Amerika Serikat >50K2 2 Swasta 50304 Lulusan HS ... 0 2 Amerika Serikat <=50K3 4 Swasta 89318 Sarjana ... 0 2 Puerto-Riko >50K4 1 Swasta 172149 Sarjana ... 0 3 Amerika Serikat <=50K.. ... ... ... ... ... ... ... ... ...995 2 NaN 208938 Sarjana ... 0 1 Amerika Serikat <=50K996 2 Swasta 166416 Sarjana ... 2 2 Amerika Serikat <=50K997 2 NaN 336022 Lulusan HS ... 0 1 Amerika Serikat <=50K998 3 Swasta 198051 Magister ... 0 2 Amerika Serikat >50K999 1 NaN 41973 Lulusan HS ... 0 2 Amerika Serikat <= 50K[1000 baris x 15 kolom]
CTGAN:Pemodelan Data Tabular menggunakan GAN Bersyarat
C3-TGAN: C3-TGAN- Sintesis Data Tabular Terkendali dengan Korelasi Eksplisit dan Batasan Properti
TVAE:Pemodelan Data Tabular menggunakan GAN Bersyarat
table-GAN:Sintesis Data berdasarkan Jaringan Adversarial Generatif
CTAB-GAN:CTAB-GAN: Sintesis Data Tabel yang Efektif
OCT-GAN: OCT-GAN: GAN Tabular Bersyarat berbasis ODE Neural
Proyek SDG diprakarsai oleh Institut Keamanan Data, Institut Teknologi Harbin . Jika Anda tertarik dengan proyek luar, selamat datang untuk bergabung dengan komunitas kami. Kami menyambut organisasi, tim, dan individu yang memiliki komitmen yang sama dengan kami terhadap perlindungan dan keamanan data melalui sumber terbuka:
Baca KONTRIBUSI sebelum membuat draf permintaan penarikan.
Kirimkan masalah dengan melihat View Good First Issue atau kirimkan Permintaan Tarik.
Bergabunglah dengan Grup WeChat kami melalui kode QR.