wikisearch
1.0.0
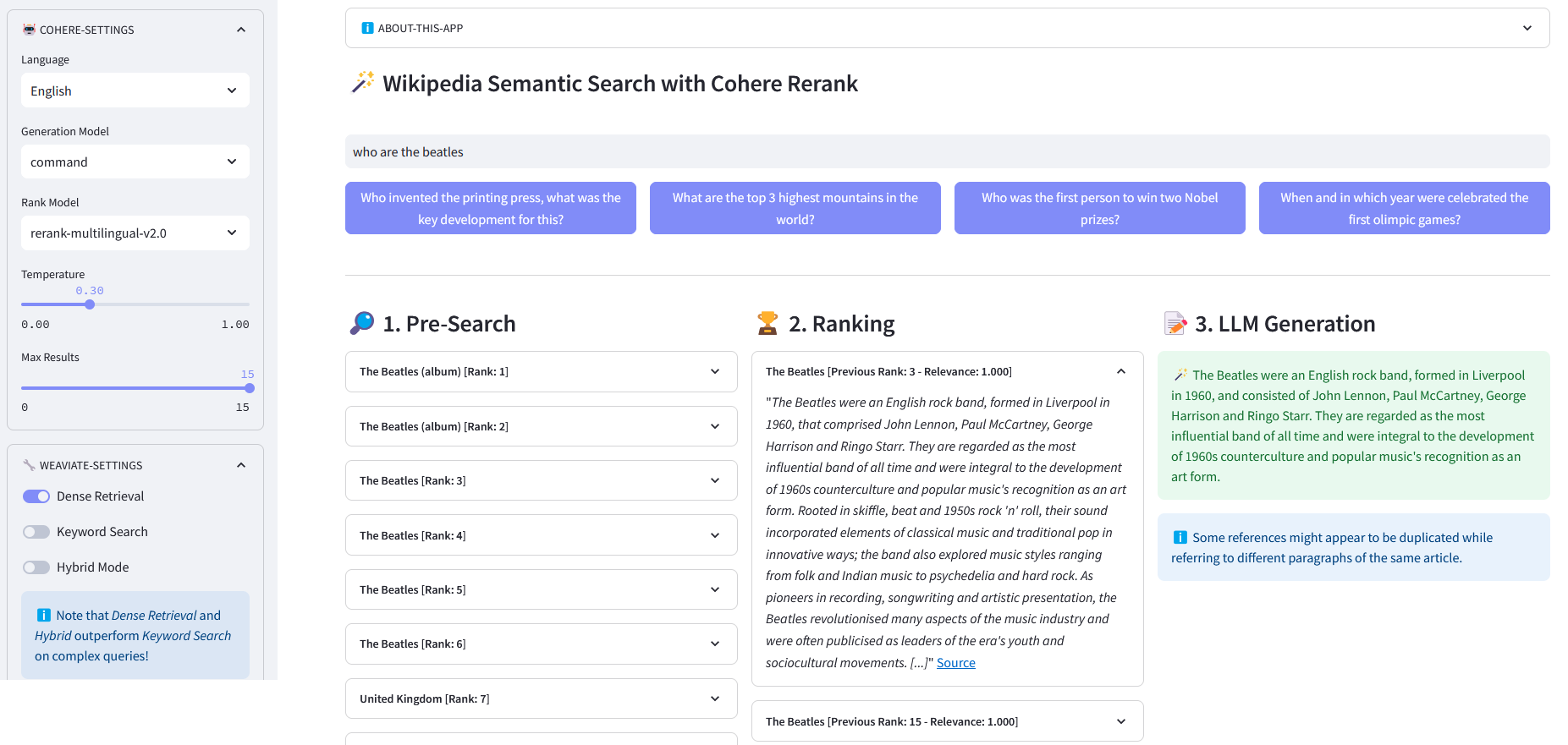
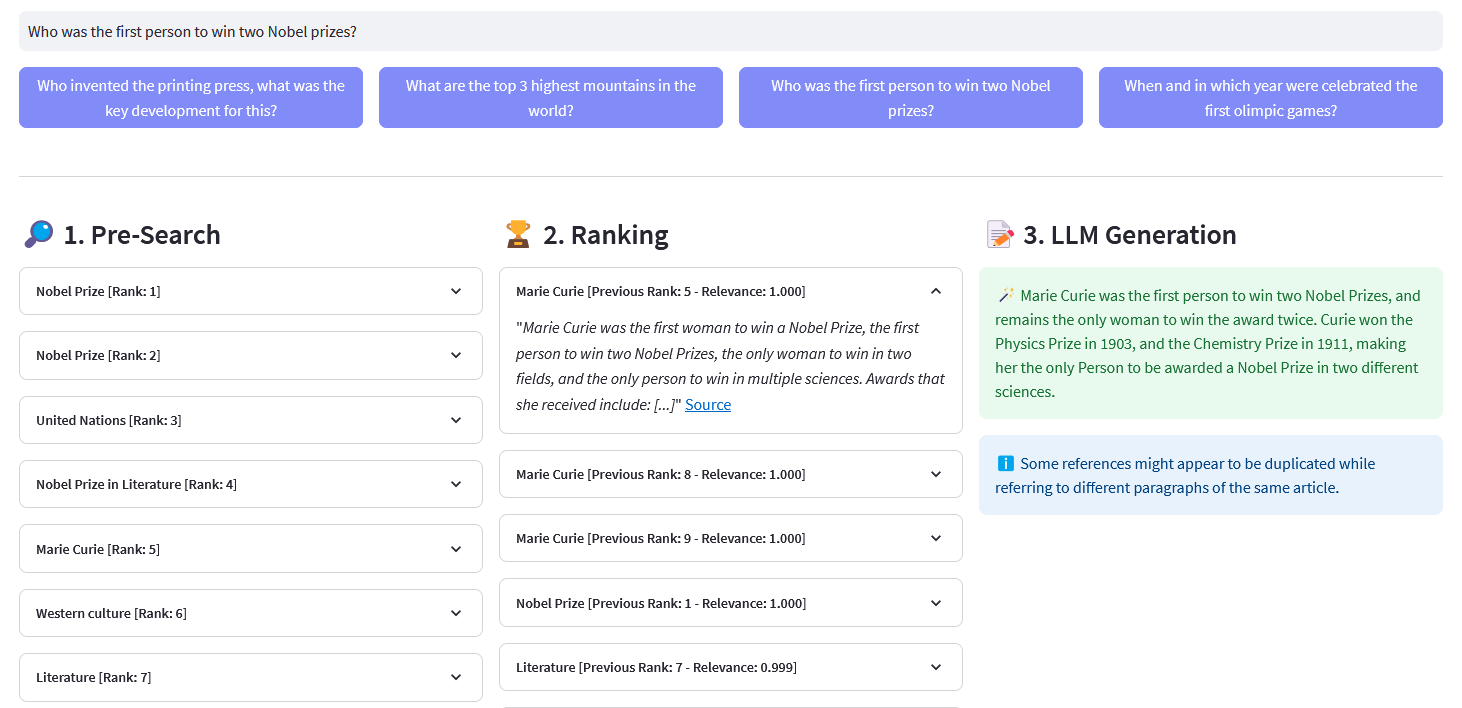
Aplikasi Streamlit untuk Pencarian Semantik Multibahasa pada lebih dari 10 juta dokumen Wikipedia yang divektorkan dalam penyematan oleh Weaviate. Implementasi ini didasarkan pada blog Cohere ´Menggunakan LLM untuk Pencarian´ dan buku catatannya yang sesuai. Hal ini memungkinkan untuk membandingkan kinerja pencarian kata kunci , pengambilan padat , dan pencarian hibrid untuk menanyakan kumpulan data Wikipedia. Hal ini lebih lanjut menunjukkan penggunaan Cohere Rerank untuk meningkatkan akurasi hasil, dan Cohere Generate untuk memberikan respons berdasarkan hasil pemeringkatan tersebut.
Pencarian semantik mengacu pada algoritma pencarian yang mempertimbangkan maksud dan makna kontekstual dari frasa pencarian ketika menghasilkan hasil, bukan hanya berfokus pada pencocokan kata kunci. Ini memberikan hasil yang lebih akurat dan relevan dengan memahami semantik, atau makna, di balik kueri.
Penyematan adalah vektor (daftar) angka floating point yang mewakili data seperti kata, kalimat, dokumen, gambar, atau audio. Representasi numerik tersebut menangkap konteks, hierarki, dan kesamaan data. Mereka dapat digunakan untuk tugas-tugas hilir seperti klasifikasi, pengelompokan, deteksi outlier, dan pencarian semantik.
Basis data vektor, seperti Weaviate, dibuat khusus untuk mengoptimalkan penyimpanan dan kemampuan kueri untuk penyematan. Dalam praktiknya, database vektor menggunakan kombinasi berbagai algoritma yang semuanya berpartisipasi dalam pencarian Approximate Nearest Neighbor (ANN). Algoritme ini mengoptimalkan pencarian melalui hashing, kuantisasi, atau pencarian berbasis grafik.
Pra-Pencarian : Pra-Pencarian pada penyematan Wikipedia dengan pencocokan kata kunci , pengambilan padat , atau pencarian hibrid :
Pencocokan Kata Kunci: mencari objek yang mengandung istilah pencarian di propertinya. Hasilnya dinilai berdasarkan fungsi BM25F:
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_bm25(self, query, lang='en', top_n=10) -> list:""" Melakukan kata kunci pencarian (pengambilan jarang) di Artikel Wikipedia menggunakan embeddings yang disimpan di Weaviate. Parameter: - query (str): Permintaan pencarian (str, opsional): Bahasa artikel. Defaultnya adalah 'en'. - top_n (int, opsional): Jumlah hasil teratas yang akan dikembalikan. Defaultnya adalah 10. Pengembalian: - daftar: Daftar artikel teratas berdasarkan BM25F penilaian """logging.info("with_bm25()")where_filter = {"path": ["lang"],"operator": "Equal","valueString": lang}response = (self.weaviate.query.get("Artikel", self.WIKIPEDIA_PROPERTIES)
.with_bm25(kueri=kueri)
.dengan_di mana(dimana_filter)
.with_limit(top_n)
.Mengerjakan()
)respon balik["data"]["Dapatkan"]["Artikel"]Pengambilan Padat: temukan objek yang paling mirip dengan teks mentah (tidak divektorkan):
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_neartext(self, query, lang='en', top_n=10) -> list:""" Melakukan semantik pencarian (pengambilan padat) di Artikel Wikipedia menggunakan embeddings yang disimpan di Weaviate. Parameter: - query (str): Permintaan pencarian. opsional): Bahasa artikel. Defaultnya adalah 'en'. - top_n (int, opsional): Jumlah hasil teratas yang akan dikembalikan. Defaultnya adalah 10. Pengembalian: - daftar: Daftar artikel teratas berdasarkan kesamaan semantik. ""logging.info("with_neartext()")nearText = {"konsep": [kueri]
}where_filter = {"path": ["lang"],"operator": "Equal","valueString": lang}response = (self.weaviate.query.get("Artikel", self.WIKIPEDIA_PROPERTIES)
.with_near_text(nearText)
.dengan_di mana(di mana_filter)
.with_limit(top_n)
.Mengerjakan()
)balas tanggapan['data']['Dapatkan']['Artikel']Pencarian Hibrid: menghasilkan hasil berdasarkan kombinasi hasil tertimbang dari pencarian kata kunci (bm25) dan pencarian vektor.
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_hybrid(self, query, lang='en', top_n=10) -> list:""" Melakukan hybrid mencari di Artikel Wikipedia menggunakan embeddings yang disimpan di Weaviate. Parameter: - query (str): Permintaan pencarian. - lang (str, opsional): Bahasa artikel adalah 'en'. - top_n (int, opsional): Jumlah hasil teratas yang akan dikembalikan. Defaultnya adalah 10. Pengembalian: - daftar: Daftar artikel teratas berdasarkan penilaian hibrid. ")where_filter = {"path": ["lang"],"operator": "Equal","valueString": lang}response = (self.weaviate.query.get("Artikel", mandiri.WIKIPEDIA_PROPERTIES)
.with_hybrid(kueri=kueri)
.dengan_di mana(di mana_filter)
.with_limit(top_n)
.Mengerjakan()
)respon balik["data"]["Dapatkan"]["Artikel"]ReRank : Cohere Rerank mengatur ulang Pra-Pencarian dengan menetapkan skor relevansi untuk setiap hasil Pra-Pencarian berdasarkan kueri pengguna. Dibandingkan dengan penelusuran semantik berbasis penyematan, penelusuran ini memberikan hasil penelusuran yang lebih baik — terutama untuk kueri yang kompleks dan spesifik domain.
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def rerank(mandiri, kueri, dokumen, top_n=10, model='rerank-english-v2.0') -> dict:""" Memberi peringkat ulang daftar tanggapan menggunakan API pemeringkatan Cohere. Parameter: - query (str): Permintaan pencarian. - dokumen (daftar): Daftar dokumen untuk dirangking ulang. - top_n (int, opsional): Jumlah hasil peringkat ulang teratas yang akan dikembalikan. Defaultnya adalah 10. - model: Model yang digunakan untuk menentukan peringkat ulang. Defaultnya adalah 'rerank-english-v2.0'. dict: Mengurutkan ulang dokumen dari API Cohere. """return self.cohere.rerank(query=query, document=documents, top_n=top_n, model=model)
Sumber: Cohere
Pembuatan Jawaban : Cohere Generate menyusun respons berdasarkan hasil pemeringkatan.
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_llm(mandiri, konteks, kueri, suhu=0,2, model="command", lang="english") -> list:prompt = f""" Gunakan informasi yang disediakan di bawah ini untuk menjawab pertanyaan di akhir. / Sertakan beberapa fakta aneh atau relevan yang diambil dari konteksnya. / Hasilkan jawaban dalam bahasa kueri. Jika Anda tidak dapat menentukan bahasa kueri, gunakan {lang} / Jika jawaban pertanyaan tidak terdapat dalam informasi yang diberikan, buatlah "Jawabannya tidak sesuai konteks". -- Pertanyaan: {query} """return self.cohere.generate(prompt=prompt,num_generasi=1,max_tokens=1000,temperature=temperature,model=model,
)Kloning repositori:
[email protected]:dcarpintero/wikisearch.git
Membuat dan Mengaktifkan Lingkungan Virtual:
Windows: py -m venv .venv .venvscriptsactivate macOS/Linux python3 -m venv .venv source .venv/bin/activate
Instal dependensi:
pip install -r requirements.txt
Luncurkan Aplikasi Web
streamlit run ./app.py
Aplikasi Web Demo diterapkan ke Streamlit Cloud dan tersedia di https://wikisearch.streamlit.app/
Cohere Rerank
Awan yang Disederhanakan
Arsip Penyematan: Jutaan Penyematan Artikel Wikipedia dalam Banyak Bahasa
Menggunakan LLM untuk Pencarian dengan Pengambilan Padat dan Pemeringkatan Ulang
Basis Data Vektor
Pencarian Vektor Weaviate
Weaviate Pencarian BM25
Pencarian Hibrid Weaviate


