EasyDetect
1.0.0

Kerangka Deteksi Halusinasi Multimodal yang Mudah Digunakan untuk MLLM
Ucapan Terima Kasih • Tolok Ukur • Demo • Ikhtisar • ModelZoo • Instalasi • Panduan Memulai • Kutipan
Pengakuan
Ringkasan
Halusinasi Multimodal Terpadu
Kumpulan Data: Statistik MHalluBench
Kerangka: Ilustrasi UniHD
ModelKebun Binatang
Instalasi
⏩Mulai cepat
Kutipan
17-05-2024 Makalah Deteksi Halusinasi Terpadu untuk Model Bahasa Besar Multimodal diterima oleh konferensi utama ACL 2024.
21-04-2024 Kami mengganti semua model dasar dalam demo dengan model terlatih kami sendiri, sehingga mengurangi waktu inferensi secara signifikan.
21-04-2024 Kami merilis model deteksi halusinasi sumber terbuka HalDet-LLAVA, yang dapat diunduh di huggingface, modelscope, dan wisemodel.
10-02-2024 Kami merilis demo EasyDetect .
05-02-2024 Kami merilis makalah:"Deteksi Halusinasi Terpadu untuk Model Bahasa Besar Multimodal" dengan tolok ukur baru MHaluBench! Kami menantikan komentar atau diskusi apa pun tentang topik ini :)
20-10-2023 Proyek EasyDetect telah diluncurkan dan sedang dikembangkan.
Sebagian implementasi proyek ini dibantu dan terinspirasi oleh perangkat halusinasi terkait termasuk FactTool, Woodpecker, dan lainnya. Repositori ini juga mendapat manfaat dari proyek publik dari mPLUG-Owl, MiniGPT-4, LLaVA, GroundingDINO, dan MAERec . Kami mengikuti lisensi yang sama untuk sumber terbuka dan berterima kasih atas kontribusinya kepada komunitas.
EasyDetect adalah paket sistematis yang diusulkan sebagai kerangka deteksi halusinasi yang mudah digunakan untuk Multimodal Large Language Models (MLLMs) seperti GPT-4V, Gemini, LlaVA dalam eksperimen penelitian Anda.
Prasyarat untuk deteksi terpadu adalah kategorisasi koheren dari kategori utama halusinasi dalam MLLM. Makalah kami secara dangkal mengkaji Taksonomi Halusinasi berikut dari perspektif terpadu:


Gambar 1: Deteksi halusinasi multimodal terpadu bertujuan untuk mengidentifikasi dan mendeteksi halusinasi yang bertentangan dengan modalitas di berbagai tingkatan seperti objek, atribut, dan adegan-teks, serta halusinasi yang bertentangan dengan fakta baik dalam gambar-ke-teks maupun teks-ke-gambar generasi.
Halusinasi yang Bertentangan dengan Modalitas. MLLM terkadang menghasilkan keluaran yang bertentangan dengan masukan dari modalitas lain, yang menyebabkan masalah seperti objek, atribut, atau teks adegan yang salah. Contoh pada Gambar (a) di atas mencakup MLLM yang mendeskripsikan seragam atlet secara tidak akurat, menampilkan konflik tingkat atribut karena terbatasnya kemampuan MLLM untuk mencapai keselarasan teks-gambar yang sangat detail.
Halusinasi yang Bertentangan Fakta. Keluaran dari MLLM mungkin bertentangan dengan pengetahuan faktual yang ada. Model image-to-text dapat menghasilkan narasi yang menyimpang dari konten sebenarnya dengan memasukkan fakta-fakta yang tidak relevan, sedangkan model text-to-image dapat menghasilkan visual yang gagal mencerminkan pengetahuan faktual yang terkandung dalam teks petunjuk. Perbedaan ini menggarisbawahi perjuangan MLLM untuk mempertahankan konsistensi faktual, yang merupakan tantangan signifikan dalam domain tersebut.
Deteksi terpadu halusinasi multimodal memerlukan pemeriksaan setiap pasangan gambar-teks a={v, x} , di mana v menunjukkan masukan visual yang diberikan ke MLLM, atau keluaran visual yang disintesis olehnya. Sejalan dengan itu, x menandakan respons tekstual yang dihasilkan MLLM berdasarkan v atau permintaan tekstual pengguna untuk mensintesis v . Dalam tugas ini, setiap x dapat berisi beberapa klaim, dilambangkan sebagai a untuk menentukan apakah itu "halusinasi" atau "non-halusinasi", memberikan alasan atas penilaian mereka berdasarkan definisi halusinasi yang diberikan. Deteksi halusinasi teks dari LLM menunjukkan sub-kasus dalam pengaturan ini, di mana v adalah nol.
Untuk memajukan lintasan penelitian ini, kami memperkenalkan tolok ukur meta-evaluasi MHaluBench, yang mencakup konten dari pembuatan gambar-ke-teks dan teks-ke-gambar, yang bertujuan untuk menilai secara ketat kemajuan dalam detektor halusinasi multimodal. Rincian statistik lebih lanjut tentang MHaluBench disediakan pada Gambar di bawah.
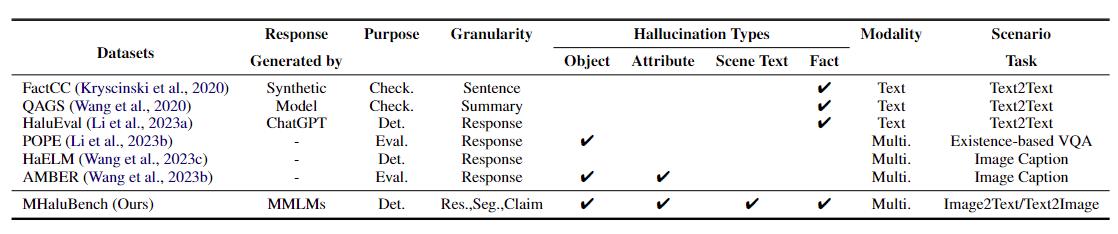
Tabel 1: Perbandingan tolok ukur sehubungan dengan pemeriksaan fakta atau evaluasi halusinasi yang ada. "Memeriksa." menunjukkan verifikasi konsistensi faktual, "Eval." menunjukkan evaluasi halusinasi yang dihasilkan oleh LLM berbeda, dan responsnya didasarkan pada LLM berbeda yang diuji, sedangkan "Det." mewujudkan evaluasi kemampuan detektor dalam mengidentifikasi halusinasi.
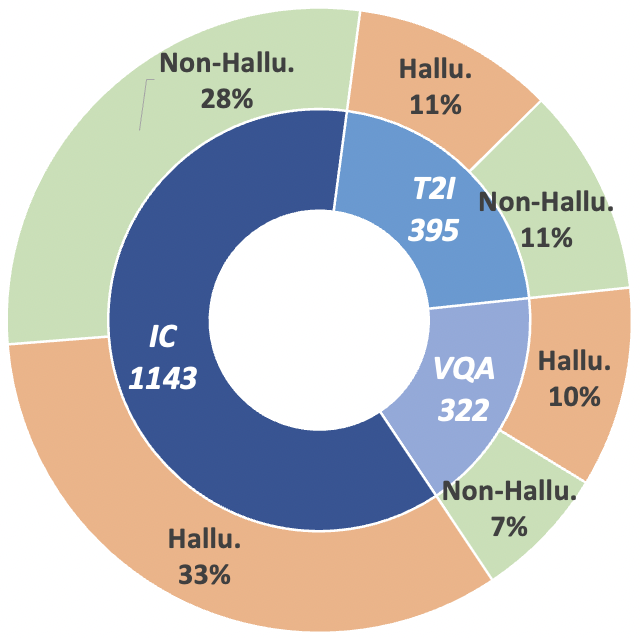
Gambar 2: Statistik data Tingkat Klaim MHaluBench. "IC" menandakan Keterangan Gambar dan "T2I" masing-masing menandakan sintesis Teks-ke-Gambar.
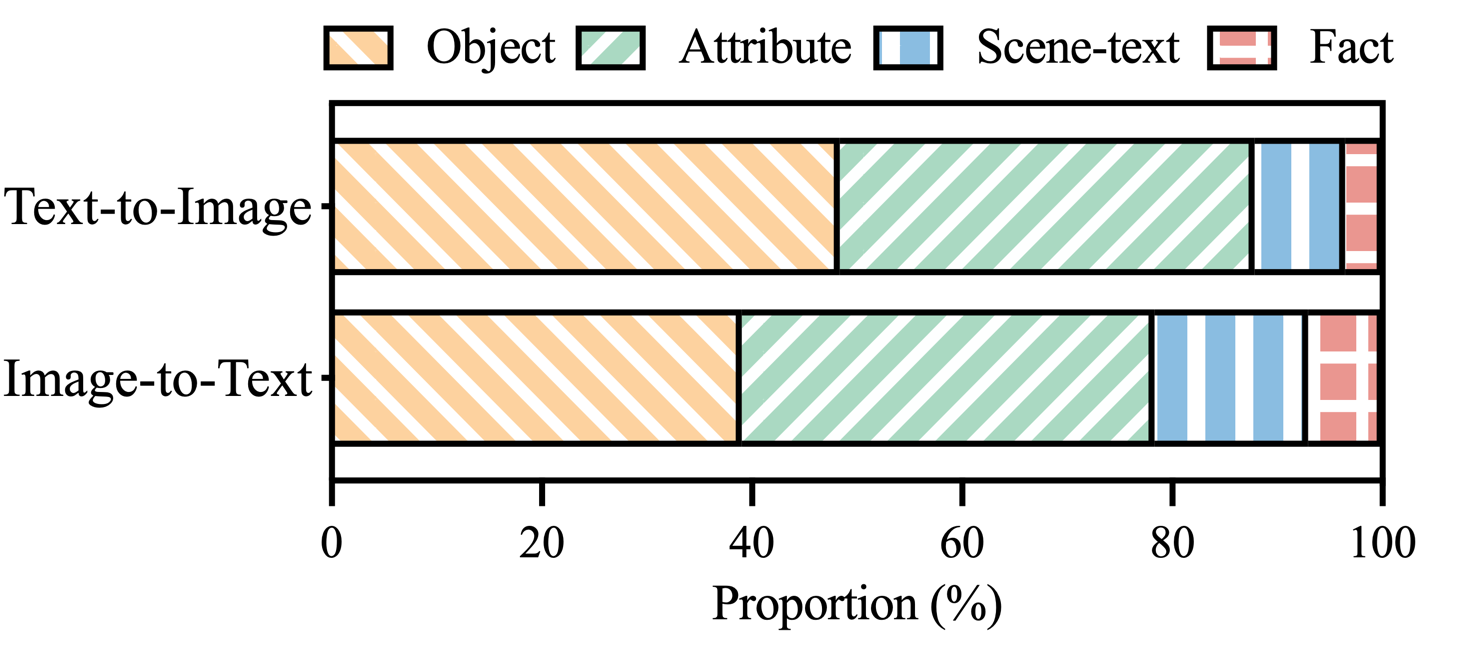
Gambar 3: Distribusi kategori halusinasi dalam klaim MHaluBench yang berlabel halusinasi.
Untuk mengatasi tantangan utama dalam deteksi halusinasi, kami memperkenalkan kerangka kerja terpadu pada Gambar 4 yang secara sistematis menangani identifikasi halusinasi multimodal untuk tugas gambar-ke-teks dan teks-ke-gambar. Kerangka kerja kami memanfaatkan kekuatan spesifik domain dari berbagai alat untuk mengumpulkan bukti multi-modal secara efisien untuk mengonfirmasi halusinasi.
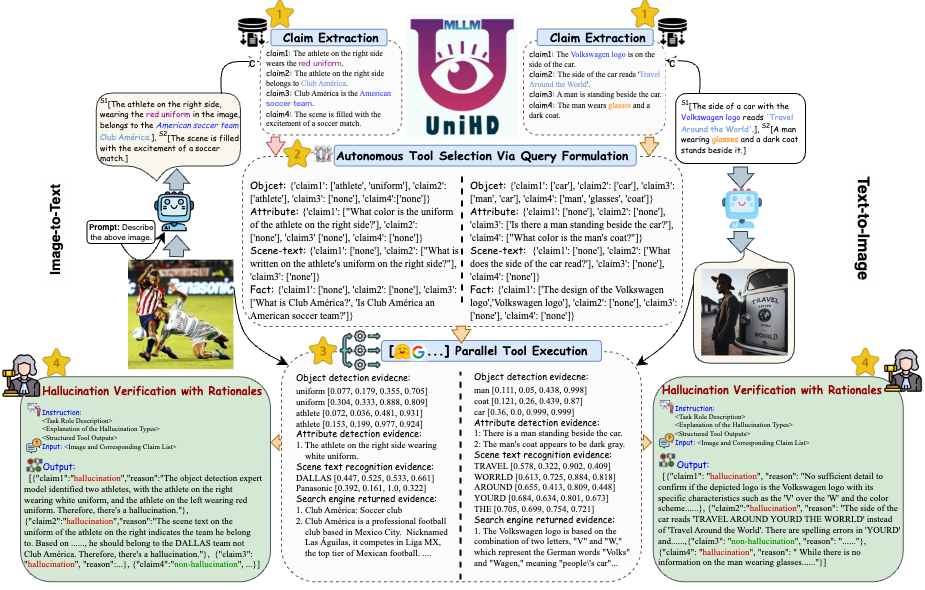
Gambar 4: Ilustrasi spesifik UniHD untuk deteksi halusinasi multimodal terpadu.
Anda dapat mengunduh dua versi HalDet-LLaVA, 7b dan 13b, pada tiga platform: HuggingFace, ModelScope, dan WiseModel.
| Memeluk Wajah | Lingkup Model | Model Bijaksana |
|---|---|---|
| HalDet-llava-7b | HalDet-llava-7b | HalDet-llava-7b |
| HalDet-llava-13b | HalDet-llava-13b | HalDet-llava-13b |
Hasil tingkat klaim pada dataset validasi
Self-Check (GPT-4V) berarti menggunakan GPT-4V dengan 0 atau 2 kasus
UniHD(GPT-4V/GPT-4o) berarti menggunakan GPT-4V/GPT-4o dengan 2-shot dan informasi alat
HalDet (LLAVA) berarti menggunakan LLAVA-v1.5 yang dilatih pada kumpulan data kereta kami
| jenis tugas | model | Acc | Rata-rata sebelumnya | Ingat rata-rata | Mac.F1 |
| gambar-ke-teks | Periksa Mandiri 0shot (GPV-4V) | 75.09 | 74,94 | 75.19 | 74,97 |
| Periksa Mandiri 2shot (GPV-4V) | 79.25 | 79.02 | 79.16 | 79.08 | |
| HalDet (LLAVA-7b) | 75.02 | 75.05 | 74.18 | 74.38 | |
| HalDet (LLAVA-13b) | 78.16 | 78.18 | 77.48 | 77.69 | |
| UniHD(GPT-4V) | 81.91 | 81.81 | 81.52 | 81.63 | |
| UniHD(GPT-4o) | 86.08 | 85,89 | 86.07 | 85,96 | |
| teks-ke-gambar | Periksa Mandiri 0shot (GPV-4V) | 76.20 | 79.31 | 75,99 | 75.45 |
| Periksa Mandiri 2shot (GPV-4V) | 80,76 | 81.16 | 80,69 | 80,67 | |
| HalDet (LLAVA-7b) | 67.35 | 69.31 | 67.50 | 66.62 | |
| HalDet (LLAVA-13b) | 74,74 | 76.68 | 74,88 | 74.34 | |
| UniHD(GPT-4V) | 85.82 | 85.83 | 85.83 | 85.82 | |
| UniHD(GPT-4o) | 89.29 | 89.28 | 89.28 | 89.28 |
Untuk melihat informasi lebih detail tentang HalDet-LLaVA dan dataset kereta api, silakan merujuk ke readme.
Instalasi untuk pengembangan lokal:
git clone https://github.com/zjunlp/EasyDetect.git cd EasyDetect pip install -r requirements.txt
Instalasi alat (GroundingDINO dan MAERec):
# install GroundingDINO git clone https://github.com/IDEA-Research/GroundingDINO.git cp -r GroundingDINO pipeline/GroundingDINO cd pipeline/GroundingDINO/ pip install -e . cd .. # install MAERec git clone https://github.com/Mountchicken/Union14M.git cp -r Union14M/mmocr-dev-1.x pipeline/mmocr cd pipeline/mmocr/ pip install -U openmim mim install mmengine mim install mmcv mim install mmdet pip install timm pip install -r requirements/albu.txt pip install -r requirements.txt pip install -v -e . cd .. mkdir weights cd weights wget -q https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth wget https://download.openmmlab.com/mmocr/textdet/dbnetpp/dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015/dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015_20221101_124139-4ecb39ac.pth -O dbnetpp.pth wget https://github.com/Mountchicken/Union14M/releases/download/Checkpoint/maerec_b_union14m.pth -O maerec_b.pth cd ..
Kami memberikan contoh kode bagi pengguna untuk memulai EasyDetect dengan cepat.
Pengguna dapat dengan mudah mengonfigurasi parameter EasyDetect di file yaml atau cukup dengan cepat menggunakan parameter default di file konfigurasi yang kami sediakan. Jalur file konfigurasi adalah EasyDetect/pipeline/config/config.yaml
openai: api_key: Masukkan kunci api openai Anda
base_url: Masukkan base_url, defaultnya adalah Tidak Ada
suhu: 0,2
max_tokens: 1024alat:
deteksi:groundingdino_config: jalur GroundingDINO_SwinT_OGC.pymodel_path: jalur groundingdino_swint_ogc.pthdevice: cuda:0BOX_TRESHOLD: 0.35TEXT_TRESHOLD: 0.25AREA_THRESHOLD: 0.001
ocr:dbnetpp_config: jalur dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015.pydbnetpp_path: jalur dbnetpp.pthmaerec_config: jalur maerec_b_union14m.pymaerec_path: jalur maerec_b.pthdevice: cuda:0content: word.numbercachefiles_path: jalur cache_files untuk menyimpan gambar sementaraBOX_TRESHOLD: 0.2TEXT_TRESHOLD: 0.25
google_serper:serper_api_key: Masukkan api serper Anda keynippet_cnt: 10prompts:claim_generate: pipeline/prompts/claim_generate.yaml
query_generate: saluran pipa/prompts/query_generate.yaml
verifikasi: pipeline/prompts/verify.yamlContoh Kode
from pipeline.run_pipeline import *pipeline = Pipeline()text = "Kafe pada gambar tersebut bernama "Hauptbahnhof""image_path = "./examples/058214af21a03013.jpg"type = "image-to-text"response,claim_list = pipeline .jalankan(teks=teks, jalur_gambar=jalur_gambar, tipe=tipe)cetak(respons)cetak(daftar_klaim)
Silakan kutip repositori kami jika Anda menggunakan EasyDetect dalam pekerjaan Anda.
@article{chen23factchd, author = {Xiang Chen dan Duanzheng Song dan Honghao Gui dan Chengxi Wang dan Ningyu Zhang dan Jiang Yong dan Fei Huang dan Chengfei Lv dan Dan Zhang dan Huajun Chen}, title = {FactCHD: Tolok Ukur Deteksi Halusinasi yang Bertentangan Fakta }, jurnal = {CoRR}, volume = {abs/2310.12086}, tahun = {2023}, url = {https://doi.org/10.48550/arXiv.2310.12086}, doi = {10.48550/ARXIV.2310.12086}, eprinttype = {arXiv}, eprint = {2310.12086}, biburl = {https://dblp.org/rec/journals/corr/abs-2310-12086.bib}, bibsource = {bibliografi ilmu komputer dblp, https://dblp.org}}@inproceedings{chen-etal-2024- unity-hallucination,title = "Deteksi Halusinasi Terpadu untuk Model Bahasa Besar Multimodal",author = "Chen, Xiang dan Wang, Chenxi dan Xue, Yida dan Zhang, Ningyu dan Yang, Xiaoyan dan Li, Qiang dan Shen, Yue dan Liang, Lei dan Gu, Jinjie dan Chen, Huajun",editor = "Ku, Lun-Wei dan Martins, Andre dan Srikumar, Vivek" ,booktitle = "Prosiding Pertemuan Tahunan ke-62 Asosiasi Linguistik Komputasi (Volume 1: Makalah Panjang)",bulan = Agustus,tahun = "2024",address = "Bangkok, Thailand",publisher = "Asosiasi Linguistik Komputasi",url = "https://aclanthology.org/2024.acl-long.178",pages = "3235--3252",
}Kami akan menawarkan pemeliharaan jangka panjang untuk memperbaiki bug, menyelesaikan masalah, dan memenuhi permintaan baru. Jadi jika Anda mempunyai masalah, silakan sampaikan masalahnya kepada kami.


