SynMeter
1.0.0

[24 Nov 2024] Kami menambahkan synthesizer SOTA HP baru REaLTabFormer ke SynMeter! Cobalah!
[18 Sep 2024] Kami menambahkan synthesizer SOTA HP baru TabSyn ke SynMeter! Cobalah!
Buat lingkungan dan pengaturan conda baru:
conda create -n synmeter python==3.9
conda activate synmeter
pip install -r requirements.txt # install dependencies
pip install -e . # package the library Ubah kamus dasar di ./lib/info/ROOT_DIR :
ROOT_DIR = root_to_synmeter
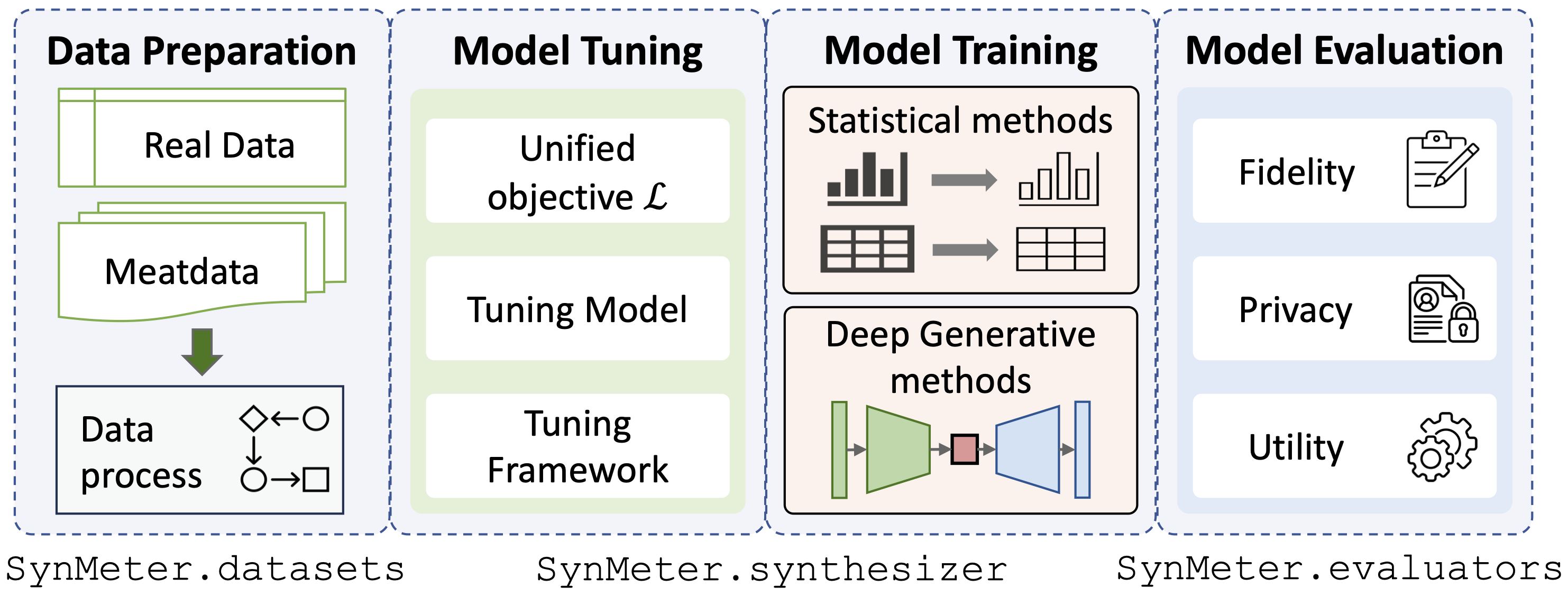
./dataset ../exp/evaluators .python scripts/tune_evaluator.py -d [dataset] -c [cuda]Kami menyediakan tujuan penyetelan terpadu untuk penyetelan model, sehingga semua jenis synthesizer dapat disetel hanya dengan satu perintah:
python scripts/tune_synthesizer.py -d [dataset] -m [synthesizer] -s [seed] -c [cuda] Setelah penyetelan, konfigurasi harus direkam ke /exp/dataset/synthesizer , SynMeter dapat menggunakannya untuk melatih dan menyimpan synthesizer:
python scripts/train_synthesizer.py -d [dataset] -m [synthesizer] -s [seed] -c [cuda]Menilai keakuratan data sintetik:
python scripts/eval_fidelity.py -d [dataset] -m [synthesizer] -s [seed] -t [target] Menilai privasi data sintetis:
python scripts/eval_privacy.py -d [dataset] -m [synthesizer] -s [seed]Menilai kegunaan data sintetis:
python scripts/eval_utility.py -d [dataset] -m [synthesizer] -s [seed] Hasil evaluasi harus disimpan dalam kamus yang sesuai /exp/dataset/synthesizer .
Salah satu keunggulan SynMeter adalah menyediakan cara termudah untuk menambahkan algoritma sintesis baru, diperlukan tiga langkah:
./synthesizer/my_synthesiszer./exp/base_config ../synthesizer , yang berisi tiga fungsi: train , sample , dan tune .Kemudian, Anda bebas menyetel, menjalankan, dan menguji synthesizer baru!
| Metode | Jenis | Keterangan | Referensi |
|---|---|---|---|
| MST | DP | Metode ini menggunakan model grafis probabilistik untuk mempelajari ketergantungan marginal berdimensi rendah untuk sintesis data. | Kertas, Kode |
| Sinkronisasi Pribadi | DP | Sintesis DP non-parametrik, yang memperbarui kumpulan data sintetik secara berulang agar sesuai dengan batas kebisingan target. | Kertas, Kode |
| Metode | Jenis | Keterangan | Referensi |
|---|---|---|---|
| CTGAN | HP | Jaringan permusuhan generatif bersyarat yang dapat menangani data tabular. | Kertas, Kode |
| PATE-GAN | DP | Metode ini menggunakan kerangka Private Aggregation of Teacher Ensembles (PATE) dan menerapkannya pada GAN. | Kertas, Kode |
| Metode | Jenis | Keterangan | Referensi |
|---|---|---|---|
| TVAE | HP | Jaringan VAE bersyarat yang dapat menangani data tabular. | Kertas, Kode |
| Metode | Jenis | Keterangan | Referensi |
|---|---|---|---|
| TabDDPM | HP | Gunakan model difusi untuk sintesis data tabular | Kertas, Kode |
| TabSyn | HP | Gunakan model difusi laten dan VAE untuk sintesis. | Kertas, Kode |
| Tabel Difusi | DP | Menghasilkan kumpulan data tabular dalam privasi diferensial. | Kertas, Kode |
| Metode | Jenis | Keterangan | Referensi |
|---|---|---|---|
| Besar | HP | Gunakan LLM untuk menyempurnakan kumpulan data tabel. | Kertas, Kode |
| REaLTabMantan | HP | Gunakan GPT-2 untuk mempelajari ketergantungan relasional data tabular. | Kertas, Kode |
Metrik fidelitas : kami menganggap jarak Wasserstein sebagai metrik fidelitas berprinsip, yang dihitung oleh semua marginal satu dan dua arah.
Metrik privasi : kami menyusun Skor Pengungkapan Keanggotaan (MDS) untuk mengukur risiko privasi keanggotaan dari penyintesis HP dan DP.
Metrik utilitas : kami menggunakan afinitas pembelajaran mesin dan kesalahan kueri untuk mengukur kegunaan data sintetis.
Silakan lihat makalah kami untuk detail dan penggunaan.
Banyak algoritma sintesis yang sangat baik dan perpustakaan sumber terbuka digunakan dalam proyek ini:


