Kode ini dibuat berdasarkan model pembelajaran mendalam Image to BEV yang sudah ada sebelumnya, berdasarkan makalah Menerjemahkan Gambar Ke Peta. Kode ini ditulis menggunakan python 3.7. dan dilatih pada kumpulan data nuScenes. Silakan merujuk ke ReadMe repositori untuk mengetahui dependensi dan kumpulan data yang akan diinstal.
Langkah pertama adalah membuat folder bernama "menerjemahkan-gambar-ke-peta-utama" dan mengunduh semua file ke dalamnya. Kemudian, karena ukuran file yang besar, pos pemeriksaan terbaru dari pelatihan kami dan kumpulan data mini nuScenes yang digunakan untuk validasi dapat diunduh dari Google Drive ini. Folder-folder ini harus ditambahkan langsung ke direktori "translator-images-into-maps-main".
Di bawah ini adalah daftar perpustakaan yang diperlukan untuk repo ini:
opencv
numpy
pyquaternion
shapely
lmdb
nuscenes-devkit
pillow
matplotlib
torchvision
descartes
scipy
tensorboard
scikit-image
cv2
Untuk menggunakan fungsi repositori ini, argumen baris perintah berikut mungkin perlu diubah:
--name: name of the experiment
--video-name: name of the video file within the video root and without extension
--savedir: directory to save experiments to
--val-interval: number of epochs between validation runs
--root: directory of the repository
--video-root: absolute directory to the video input
--nusc-version: nuscenes version (either “v1.0-mini” or “v1.0-trainval” for the full US dataset)
--train-split: training split (either “train_mini" or “train_roddick” for the full US dataset)
--val-split: validation split (either “val_mini" or “val_roddick” for the full US dataset)
--data-size: percentage of dataset to train on
--epochs: number of epochs to train for
--batch-size: batch size
--cuda-available: environment used (0 for cpu, 1 for cuda)
--iou: iou metric used (0 for iou, 1 for diou)
Untuk melatih model, argumen baris perintah berikut dapat dimodifikasi:
--optimizer: optimizer for gradient descent to run during training. Default: adam
--lr: learning rate. Default: 5e-5
--momentum: momentum for Stochastic gradient descent. Default: 0.9
--weight-decay: weight decay. Default: 1e-4
--lr-decay: learning rate decay. Default: 0.99
Kumpulan data NuScenes Mini dan Lengkap dapat ditemukan di lokasi berikut:
NuScene Mini:
NuScenes Lengkap AS:
Karena kumpulan data NuScene mini dan lengkap tidak memiliki format input gambar yang sama (lmdb atau png), beberapa modifikasi perlu diterapkan pada kode untuk menggunakan salah satunya:
mini menjadi false untuk menggunakan kumpulan data mini serta jalur args dan pemisahan dalam file train.py , validation.py dan inference.py . data = nuScenesMaps (
root = args . root ,
split = args . val_split ,
grid_size = args . grid_size ,
grid_res = args . grid_res ,
classes = args . load_classes_nusc ,
dataset_size = args . data_size ,
desired_image_size = args . desired_image_size ,
mini = True ,
gt_out_size = ( 200 , 200 ),
)
loader = DataLoader (
data ,
batch_size = args . batch_size ,
shuffle = False ,
num_workers = 0 ,
collate_fn = src . data . collate_funcs . collate_nusc_s ,
drop_last = True ,
pin_memory = True
)data_loader.py : # if mini:
image_input_key = pickle . dumps ( id , protocol = 3 )
with self . images_db . begin () as txn :
value = txn . get ( key = image_input_key )
image = Image . open ( io . BytesIO ( value )). convert ( mode = 'RGB' )
# else:
# original_nusenes_dir = "/work/scitas-share/datasets/Vita/civil-459/NuScenes_full/US/samples/CAM_FRONT"
# new_cam_path = os.path.join(original_nusenes_dir, Path(cam_path).name)
# image = Image.open(new_cam_path).convert(mode='RGB')Pos pemeriksaan terlatih dapat ditemukan di sini:
Pos pemeriksaan harus disimpan dalam /pretrained_models/27_04_23_11_08 dari direktori root repositori ini. Jika Anda ingin memuatnya dari direktori lain, harap ubah argumen berikut:
- - savedir = "pretrained_models" # Careful, this path is relative in validation.py but global in train.py
- - name = "27_04_23_11_08"Untuk melatih scitas, Anda perlu meluncurkan skrip berikut dari direktori root:
sbatch job.script.sh
Untuk berlatih secara lokal di CPU:
python3 train.py
Pastikan untuk menyesuaikan skrip dengan argumen baris perintah Anda.
Untuk memvalidasi performa model di scitas:
sbatch job.validate.sh
Untuk berlatih secara lokal di CPU:
python3 validate.py
Pastikan untuk menyesuaikan skrip dengan argumen baris perintah Anda.
Untuk menyimpulkan video di scitas:
sbatch job.evaluate.sh
Untuk berlatih secara lokal di CPU:
python3 inference.py
Pastikan untuk menyesuaikan skrip dengan argumen baris perintah Anda, terutama:
--batch-size // 1 for the test videos
--video-name
--video-root
Proyek ini dibuat dalam konteks kursus Pembelajaran Mendalam untuk Kendaraan Otonom CIVIL-459, yang diajarkan oleh Profesor Alexandre Alahi di EPFL. Kami diawasi oleh mahasiswa doktoral Yuejiang Liu. Tujuan utama dari proyek kursus ini adalah untuk mengembangkan model pembelajaran mendalam yang dapat digunakan pada sistem autopilot Tesla. Sedangkan untuk kelompok kami, kami telah mempelajari transformasi dari gambar kamera monokuler menjadi pandangan mata burung. Hal ini dapat dilakukan dengan menggunakan segmentasi semantik untuk mengklasifikasikan elemen seperti mobil, trotoar, pejalan kaki, dan cakrawala.
Selama penelitian kami tentang gambar Monokuler hingga model pembelajaran mendalam BEV, kami memperhatikan bahwa informasi mengenai pejalan kaki hilang selama segmentasi, sehingga menghasilkan klasifikasi yang buruk. Seperti terlihat pada gambar di bawah, ketika dievaluasi, model yang kami pilih mencapai rata-rata 25,7% IoU (Intersection over Union) pada 14 kelas objek pada dataset nuScenes. Akurasi prediksi untuk kendaraan yang dapat dikendarai adalah baik (74,5%), dan cukup buruk untuk sepeda, pembatas jalan, dan trailer. Namun keakuratan prediksi untuk pejalan kaki (9,5%) masih terlalu rendah. Ketelitian yang rendah tersebut dapat menimbulkan kecelakaan jika seseorang menyeberang jalan tanpa berada di persimpangan.

Informasi lebih lanjut tentang penelitian kami dapat ditemukan di Drive.
Karena buruknya deteksi pejalan kaki tampaknya menjadi masalah yang paling mendesak pada model yang dilatih saat ini, kami bertujuan untuk meningkatkan akurasi dengan melihat fungsi kerugian yang lebih sesuai, dan melatih model baru pada kumpulan data nuScenes.
Model yang kami buat dilatih menggunakan
Masalah lain dengan
Itu
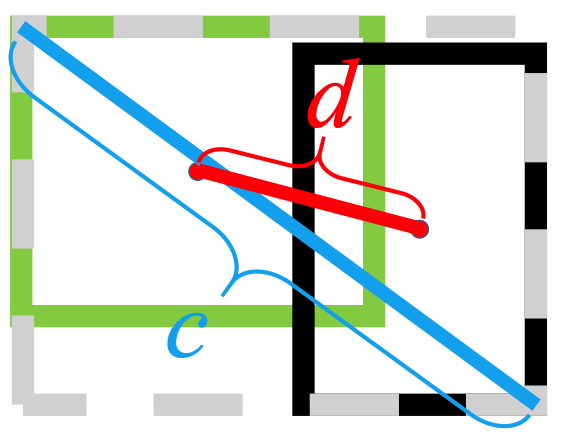
Ia menggunakan norma L2 untuk meminimalkan jarak antara kotak prediksi dan kotak target, dan menyatu jauh lebih cepat daripada kotak target

Peregangan Horisontal

Peregangan Vertikal
Selain itu, kerugian DIoU memperkenalkan istilah regularisasi yang mendorong konvergensi yang lancar.
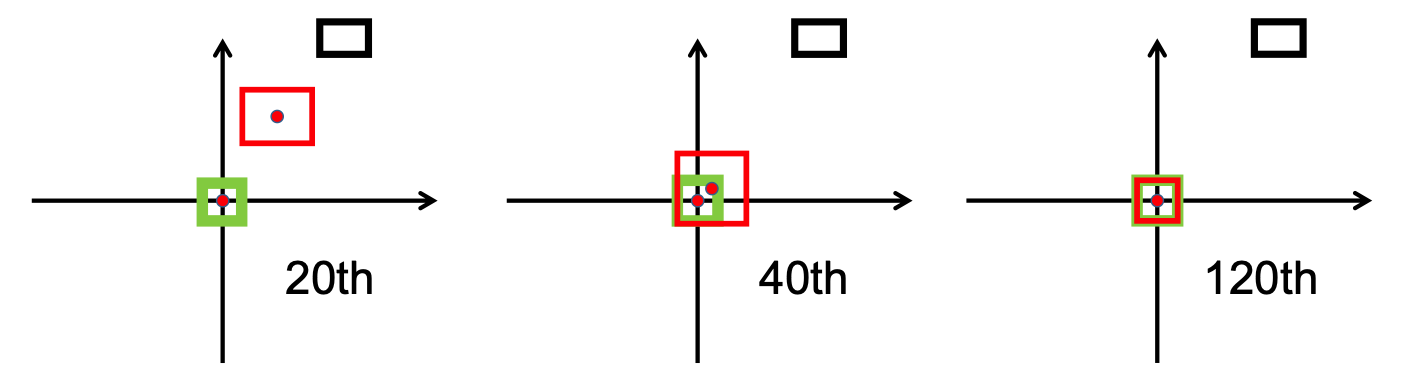
Seperti terlihat pada gambar berikut,
Setelah tahap penelitian, kami menerapkan bbox_overlaps_diou di file /src/utils.py , dengan menggunakan
Fungsi ini kemudian digunakan untuk menghitung multiskala compute_multiscale_iou dari file yang sama. Untuk setiap kelas, iou ) dihitung berdasarkan ukuran batch. Output dari fungsi ini adalah kamus iou_dict yang berisi multiskala
Kami kemudian menggunakan nilai-nilai ini di train.py , di mana val-interval . Nilai-nilai ini juga digunakan di validation.py yang digunakan untuk menampilkan kerugian dan
Kami melatih model pada kumpulan data NuScenes yang dimulai dengan checkpoint-008.pth.gz yang disediakan, sekali dengan
Kontribusi lainnya adalah format visualisasi baru untuk membedakan kelas dengan lebih baik dengan semua label dan nilai IoU yang sesuai. Ini diterapkan dalam file visualization.py .
Terakhir, kami berupaya menerapkan mode yang akan mengambil video .mp4 sebagai masukan dan menguraikannya menjadi bingkai gambar individual. Ini kemudian akan dievaluasi oleh model dan kita dapat memvisualisasikan hasil segmentasi di file inference.py .
Untuk mendapatkan gambaran awal tentang strategi pelatihan model ini, pertama-tama kami memutuskan untuk melatihnya pada kumpulan data mini NuScenes. Mulai dari checkpoint-008.pth.gz , kami dapat melatih dua model yang berbeda dalam metrik IoU yang digunakan (IoU untuk satu model dan DIoU untuk model lainnya). Hasil yang diperoleh pada mini batch NuScenes setelah 10 epoch pelatihan disajikan pada tabel di bawah.

Setelah melihat hasil-hasil ini, kami mengamati bahwa kelas pejalan kaki, yang menjadi dasar hipotesis kami, tidak memberikan hasil yang konklusif sama sekali. Oleh karena itu, kami menyimpulkan bahwa kumpulan data mini tidak mencukupi kebutuhan kami dan memutuskan untuk memindahkan pelatihan kami ke kumpulan data lengkap di Scitas.
Setelah melatih model baru kami (dengan DIoU atau IoU) dari checkpoint-008.pth.gz selama 8 periode baru, kami mengamati hasil yang menjanjikan. Dengan tujuan membandingkan performa model yang baru dilatih ini, kami melakukan langkah validasi pada kumpulan data mini. Visualisasi hasil gambar kumpulan data ini disediakan di bawah ini.
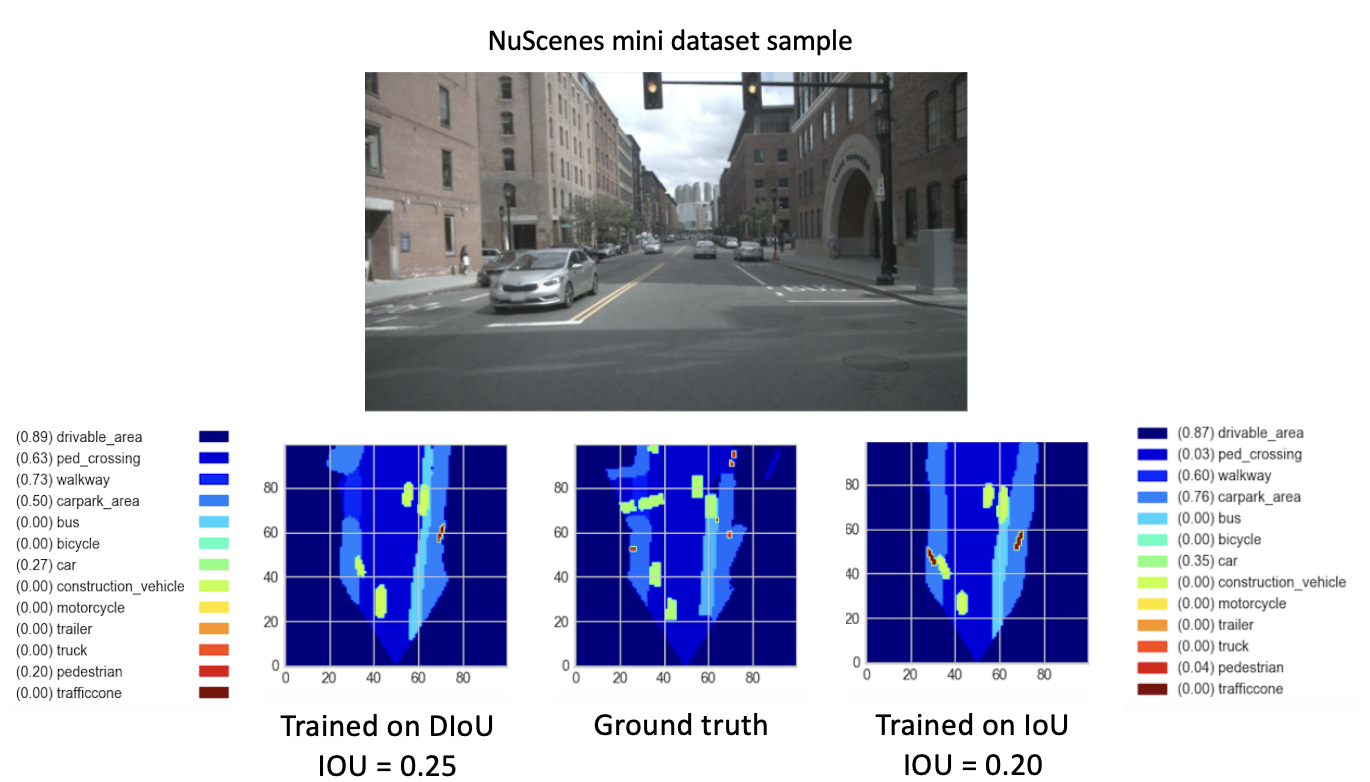
Di sini, itu

Hasil ini akhirnya menunjukkan kinerja yang lebih baik
Sekarang kita memiliki model terlatih, kita dapat menggunakannya untuk memprediksi BEV menggunakan masukan gambar atau video apa pun. Meskipun ambisi kami adalah menerapkan metode kami dalam demo akhir kursus, sayangnya peta pandangan sekilas yang kami simpulkan tidak cukup baik. Gambar di bawah ini menunjukkan hasil inferensi pada salah satu video pengujian yang disediakan (lihat video pengujian).

Kami yakin kurangnya kinerja inferensi ini disebabkan oleh parameter berikut:
Meskipun bagian dari
Salah satu pilihannya adalah menerapkan
Itu
Lebih jauh lagi, menurut penelitian yang dilakukan oleh makalah ini [2], kesalahan regresi untuk CIoU terdegradasi lebih cepat daripada yang lain, dan akan menyatu ke
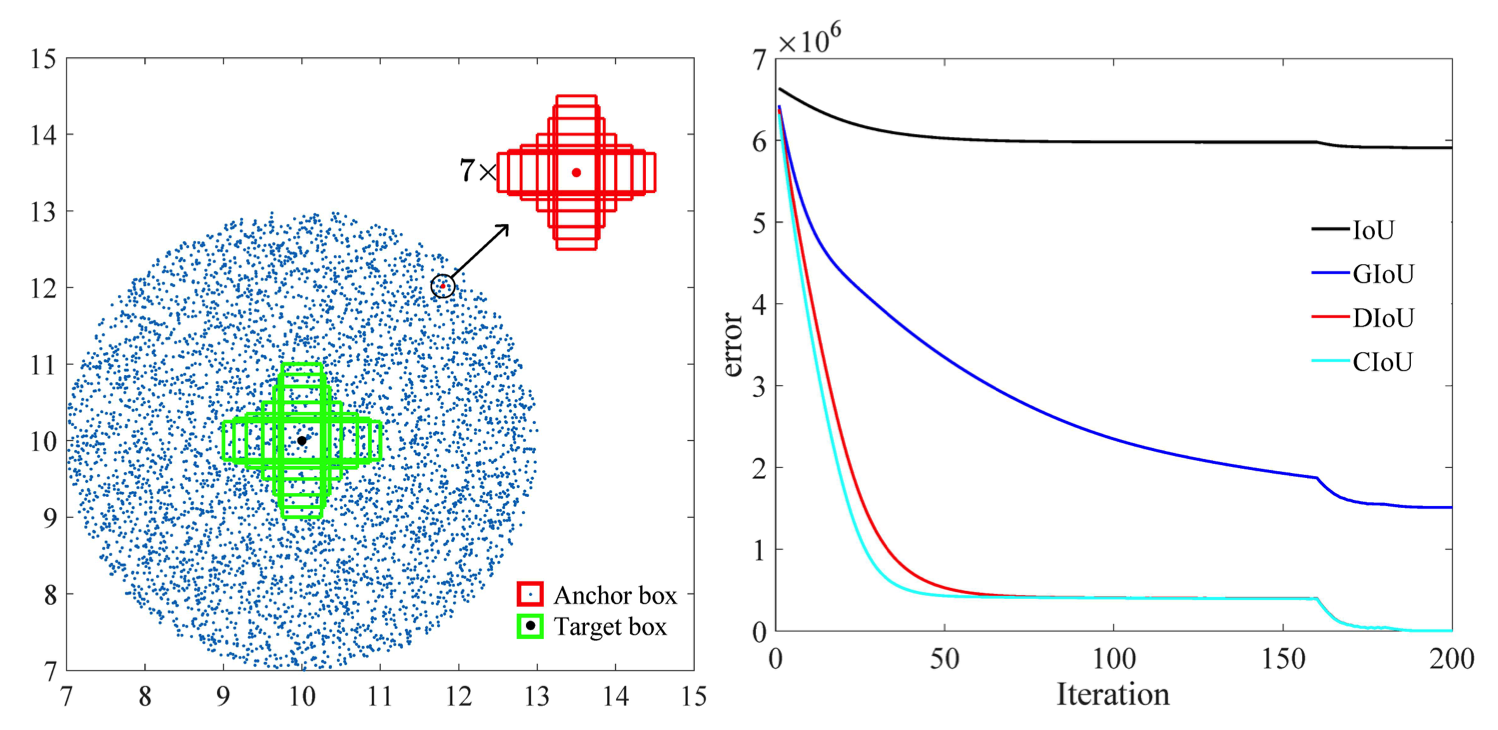
Pilihan lainnya adalah melatih kumpulan data yang kaya akan lingkungan ramai untuk mendapatkan representasi pejalan kaki dan sepeda yang lebih baik.
Terakhir, untuk benar-benar memvalidasi hipotesis kami, validasi yang dijalankan pada kumpulan data NuScenes lengkap dapat dilakukan dan IoU pejalan kaki dari kedua model dapat dibandingkan.
[1] Zhaohui Zheng, Ping Wang, Wei Liu, Jinze Li, Rongguang Ye, Dongwei Ren (2020). Kerugian Jarak-IoU: Pembelajaran Lebih Cepat dan Lebih Baik untuk Regresi Bounding Box https://arxiv.org/pdf/1911.08287.pdf
[2] Zhaohui Zheng, Ping Wang, Dongwei Ren, Wei Liu, Rongguang Ye, Qinghua Hu, Wangmeng Zuo (2021). Meningkatkan Faktor Geometris dalam Pembelajaran Model dan Inferensi untuk Deteksi Objek dan Segmentasi Instance https://arxiv.org/pdf/2005.03572.pdf


