tiny cuda nn
Version 1.6
Ini adalah kerangka kerja kecil dan mandiri untuk melatih dan menanyakan jaringan saraf. Yang paling menonjol, ini berisi perceptron multi-layer (kertas teknis) yang "menyatu sepenuhnya" secepat kilat, pengkodean hash multiresolusi serbaguna (kertas teknis), serta dukungan untuk berbagai pengkodean input, kerugian, dan pengoptimal lainnya.
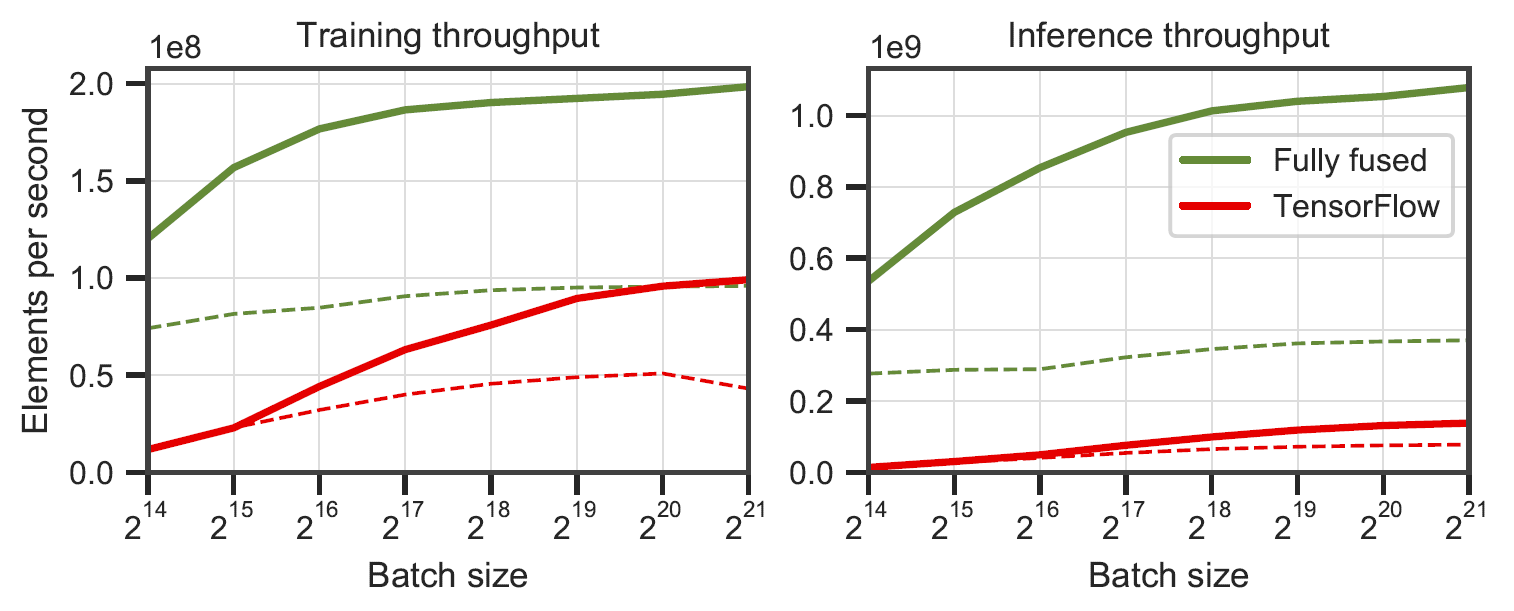 Jaringan yang sepenuhnya menyatu vs. TensorFlow v2.5.0 dengan XLA. Diukur pada 64 (garis padat) dan 128 (garis putus-putus) neuron perceptron multi-lapis lebar pada RTX 3090. Dihasilkan oleh
Jaringan yang sepenuhnya menyatu vs. TensorFlow v2.5.0 dengan XLA. Diukur pada 64 (garis padat) dan 128 (garis putus-putus) neuron perceptron multi-lapis lebar pada RTX 3090. Dihasilkan oleh benchmarks/bench_ours.cu dan benchmarks/bench_tensorflow.py menggunakan data/config_oneblob.json .
Jaringan saraf CUDA kecil memiliki C++/CUDA API sederhana:
# include < tiny-cuda-nn/common.h >
// Configure the model
nlohmann::json config = {
{ " loss " , {
{ " otype " , " L2 " }
}},
{ " optimizer " , {
{ " otype " , " Adam " },
{ " learning_rate " , 1e-3 },
}},
{ " encoding " , {
{ " otype " , " HashGrid " },
{ " n_levels " , 16 },
{ " n_features_per_level " , 2 },
{ " log2_hashmap_size " , 19 },
{ " base_resolution " , 16 },
{ " per_level_scale " , 2.0 },
}},
{ " network " , {
{ " otype " , " FullyFusedMLP " },
{ " activation " , " ReLU " },
{ " output_activation " , " None " },
{ " n_neurons " , 64 },
{ " n_hidden_layers " , 2 },
}},
};
using namespace tcnn ;
auto model = create_from_config(n_input_dims, n_output_dims, config);
// Train the model (batch_size must be a multiple of tcnn::BATCH_SIZE_GRANULARITY)
GPUMatrix< float > training_batch_inputs (n_input_dims, batch_size);
GPUMatrix< float > training_batch_targets (n_output_dims, batch_size);
for ( int i = 0 ; i < n_training_steps; ++i) {
generate_training_batch (&training_batch_inputs, &training_batch_targets); // <-- your code
float loss;
model. trainer -> training_step (training_batch_inputs, training_batch_targets, &loss);
std::cout << " iteration= " << i << " loss= " << loss << std::endl;
}
// Use the model
GPUMatrix< float > inference_inputs (n_input_dims, batch_size);
generate_inputs (&inference_inputs); // <-- your code
GPUMatrix< float > inference_outputs (n_output_dims, batch_size);
model.network-> inference (inference_inputs, inference_outputs);Kami menyediakan contoh aplikasi di mana fungsi gambar (x,y) -> (R,G,B) dipelajari. Itu dapat dijalankan melalui
tiny-cuda-nn$ ./build/mlp_learning_an_image data/images/albert.jpg data/config_hash.jsonmenghasilkan gambar setiap beberapa langkah pelatihan. Setiap 1000 langkah akan memakan waktu lebih dari 1 detik dengan konfigurasi default pada RTX 4090.
| 10 langkah | 100 langkah | 1000 langkah | Gambar referensi |
|---|---|---|---|
 |  |  |  |
n_neurons atau menggunakan CutlassMLP (kompatibilitas lebih baik tetapi lebih lambat).Jika Anda menggunakan Linux, instal paket berikut
sudo apt-get install build-essential git Kami juga merekomendasikan menginstal CUDA di /usr/local/ dan menambahkan instalasi CUDA ke PATH Anda. Misalnya, jika Anda memiliki CUDA 11.4, tambahkan yang berikut ini ke ~/.bashrc Anda
export PATH= " /usr/local/cuda-11.4/bin: $PATH "
export LD_LIBRARY_PATH= " /usr/local/cuda-11.4/lib64: $LD_LIBRARY_PATH " Mulailah dengan mengkloning repositori ini dan semua submodulnya menggunakan perintah berikut:
$ git clone --recursive https://github.com/nvlabs/tiny-cuda-nn
$ cd tiny-cuda-nnKemudian, gunakan CMake untuk membangun proyek: (di Windows, ini harus ada di command prompt pengembang)
tiny-cuda-nn$ cmake . -B build -DCMAKE_BUILD_TYPE=RelWithDebInfo
tiny-cuda-nn$ cmake --build build --config RelWithDebInfo -j Jika kompilasi gagal tanpa alasan yang jelas atau memakan waktu lebih dari satu jam, Anda mungkin kehabisan memori. Coba jalankan perintah di atas tanpa -j dalam hal ini.
tiny-cuda-nn hadir dengan ekstensi PyTorch yang memungkinkan penggunaan MLP cepat dan pengkodean masukan dari dalam konteks Python. Pengikatan ini bisa jauh lebih cepat daripada implementasi penuh Python; khususnya untuk pengkodean hash multiresolusi.
Meskipun demikian, biaya overhead Python/PyTorch bisa sangat besar jika ukuran batchnya kecil. Misalnya, dengan ukuran batch 64k, contoh
mlp_learning_an_imageyang dibundel ~2x lebih lambat melalui PyTorch dibandingkan CUDA asli. Dengan ukuran batch 256k dan lebih tinggi (default), kinerjanya jauh lebih dekat.
Mulailah dengan menyiapkan lingkungan Python 3.X dengan PyTorch versi terbaru yang mendukung CUDA. Lalu, panggil
pip install git+https://github.com/NVlabs/tiny-cuda-nn/ # subdirectory=bindings/torchAlternatifnya, jika Anda ingin menginstal dari klon lokal tiny-cuda-nn , aktifkan
tiny-cuda-nn$ cd bindings/torch
tiny-cuda-nn/bindings/torch$ python setup.py installJika berhasil, Anda dapat menggunakan model tiny-cuda-nn seperti pada contoh berikut:
import commentjson as json
import tinycudann as tcnn
import torch
with open ( "data/config_hash.json" ) as f :
config = json . load ( f )
# Option 1: efficient Encoding+Network combo.
model = tcnn . NetworkWithInputEncoding (
n_input_dims , n_output_dims ,
config [ "encoding" ], config [ "network" ]
)
# Option 2: separate modules. Slower but more flexible.
encoding = tcnn . Encoding ( n_input_dims , config [ "encoding" ])
network = tcnn . Network ( encoding . n_output_dims , n_output_dims , config [ "network" ])
model = torch . nn . Sequential ( encoding , network ) Lihat samples/mlp_learning_an_image_pytorch.py sebagai contoh.
Berikut adalah ringkasan komponen kerangka ini. Dokumentasi JSON mencantumkan opsi konfigurasi.
| Jaringan | ||
|---|---|---|
| MLP yang menyatu sepenuhnya | src/fully_fused_mlp.cu | Implementasi secepat kilat dari perceptron multi-layer kecil (MLP). |
| MLP CUTLASS | src/cutlass_mlp.cu | MLP berdasarkan rutinitas GEMM CUTLASS. Lebih lambat dibandingkan sepenuhnya menyatu, namun menangani jaringan yang lebih besar dan masih cukup cepat. |
| Pengkodean masukan | ||
|---|---|---|
| Gabungan | include/tiny-cuda-nn/encodings/composite.h | Memungkinkan pembuatan beberapa pengkodean. Dapat, misalnya, digunakan untuk merakit pengkodean Neural Radiance Caching [Müller et al. 2021]. |
| Frekuensi | include/tiny-cuda-nn/encodings/frequency.h | NeRF [Mildenhall dkk. 2020] pengkodean posisi diterapkan secara merata ke semua dimensi. |
| jaringan | include/tiny-cuda-nn/encodings/grid.h | Pengkodean berdasarkan grid multiresolusi yang dapat dilatih. Digunakan untuk Primitif Grafik Neural Instan [Müller et al. 2022]. Grid dapat didukung oleh tabel hash, penyimpanan padat, atau penyimpanan ubin. |
| Identitas | include/tiny-cuda-nn/encodings/identity.h | Membiarkan nilai-nilai tidak tersentuh. |
| Satu gumpalan | include/tiny-cuda-nn/encodings/oneblob.h | Dari Pengambilan Sampel Pentingnya Neural [Müller et al. 2019] dan Variasi Kontrol Neural [Müller et al. 2020]. |
| Harmonis Bola | include/tiny-cuda-nn/encodings/spherical_harmonics.h | Pengkodean ruang frekuensi yang lebih cocok untuk vektor arah dibandingkan vektor arah komponen. |
| Gelombang Segitiga | include/tiny-cuda-nn/encodings/triangle_wave.h | Alternatif berbiaya rendah untuk pengkodean NeRF. Digunakan dalam Neural Radiance Caching [Müller et al. 2021]. |
| Kerugian | ||
|---|---|---|
| L1 | include/tiny-cuda-nn/losses/l1.h | Kerugian L1 standar. |
| Relatif L1 | include/tiny-cuda-nn/losses/l1.h | Kerugian L1 relatif dinormalisasi oleh prediksi jaringan. |
| PETA | include/tiny-cuda-nn/losses/mape.h | Rata-rata persentase kesalahan absolut (MAPE). Sama seperti Relatif L1, tetapi dinormalisasi oleh target. |
| SMAPE | include/tiny-cuda-nn/losses/smape.h | Kesalahan persentase absolut rata-rata simetris (SMAPE). Sama seperti Relatif L1, tetapi dinormalisasi berdasarkan rata-rata prediksi dan target. |
| L2 | include/tiny-cuda-nn/losses/l2.h | Kerugian L2 standar. |
| Relatif L2 | include/tiny-cuda-nn/losses/relative_l2.h | Kehilangan L2 relatif dinormalisasi dengan prediksi jaringan [Lehtinen et al. 2018]. |
| Pencahayaan L2 Relatif | include/tiny-cuda-nn/losses/relative_l2_luminance.h | Sama seperti di atas, tetapi dinormalisasi dengan kecerahan prediksi jaringan. Hanya berlaku jika prediksi jaringan adalah RGB. Digunakan dalam Neural Radiance Caching [Müller et al. 2021]. |
| Entropi Silang | include/tiny-cuda-nn/losses/cross_entropy.h | Kerugian lintas entropi standar. Hanya berlaku jika prediksi jaringan berupa PDF. |
| Perbedaan | include/tiny-cuda-nn/losses/variance_is.h | Kerugian varians standar. Hanya berlaku jika prediksi jaringan berupa PDF. |
| Pengoptimal | ||
|---|---|---|
| adam | include/tiny-cuda-nn/optimizers/adam.h | Implementasi Adam [Kingma dan Ba 2014], digeneralisasikan ke AdaBound [Luo et al. 2019]. |
| kota baru | include/tiny-cuda-nn/optimizers/lookahead.h | Implementasi Novograd [Ginsburg dkk. 2019]. |
| SGD | include/tiny-cuda-nn/optimizers/sgd.h | Penurunan gradien stokastik standar (SGD). |
| Sampo | include/tiny-cuda-nn/optimizers/shampoo.h | Implementasi pengoptimal Shampo urutan ke-2 [Gupta et al. 2018] dengan pengoptimalan yang dikembangkan sendiri serta yang dilakukan oleh Anil dkk. [2020]. |
| Rata-rata | include/tiny-cuda-nn/optimizers/average.h | Membungkus pengoptimal lain dan menghitung rata-rata bobot linier selama N iterasi terakhir. Rata-rata hanya digunakan untuk inferensi (tidak dimasukkan kembali ke dalam pelatihan). |
| Berkelompok | include/tiny-cuda-nn/optimizers/batched.h | Membungkus pengoptimal lain, memanggil pengoptimal bersarang setiap N langkah pada gradien rata-rata. Memiliki efek yang sama seperti meningkatkan ukuran batch tetapi hanya memerlukan jumlah memori yang konstan. |
| Gabungan | include/tiny-cuda-nn/optimizers/composite.h | Memungkinkan penggunaan beberapa pengoptimal pada parameter berbeda. |
| EMA | include/tiny-cuda-nn/optimizers/average.h | Membungkus pengoptimal lain dan menghitung rata-rata pergerakan eksponensial dari bobotnya. Rata-rata hanya digunakan untuk inferensi (tidak dimasukkan kembali ke dalam pelatihan). |
| Peluruhan Eksponensial | include/tiny-cuda-nn/optimizers/exponential_decay.h | Menggabungkan pengoptimal lain dan melakukan peluruhan kecepatan pembelajaran eksponensial sedikit demi sedikit. |
| Lihat ke depan | include/tiny-cuda-nn/optimizers/lookahead.h | Membungkus pengoptimal lain, mengimplementasikan algoritma lookahead [Zhang et al. 2019]. |
Kerangka kerja ini dilisensikan di bawah lisensi 3-klausul BSD. Silakan lihat LICENSE.txt untuk detailnya.
Jika Anda menggunakannya dalam penelitian Anda, kami sangat menghargai kutipan melalui
@software { tiny-cuda-nn ,
author = { M"uller, Thomas } ,
license = { BSD-3-Clause } ,
month = { 4 } ,
title = { {tiny-cuda-nn} } ,
url = { https://github.com/NVlabs/tiny-cuda-nn } ,
version = { 1.7 } ,
year = { 2021 }
}Untuk pertanyaan bisnis, silakan kunjungi situs web kami dan kirimkan formulir: Lisensi Penelitian NVIDIA
Kerangka kerja ini antara lain mendukung publikasi-publikasi berikut:
Primitif Grafik Neural Instan dengan Pengkodean Hash Multiresolusi
Thomas Müller, Alex Evans, Christoph Schied, Alexander Keller
Transaksi ACM pada Grafik ( SIGGRAPH ), Juli 2022
Situs Web / Kertas / Kode / Video / BibTeX
Mengekstraksi Model 3D Segitiga, Bahan, dan Pencahayaan Dari Gambar
Jacob Munkberg, Jon Hasselgren, Tianchang Shen, Jun Gao, Wenzheng Chen, Alex Evans, Thomas Müller, Sanja Fidler
CVPR (Lisan) , Juni 2022
Situs Web / Makalah / Video / BibTeX
Caching Neural Radiance Waktu Nyata untuk Penelusuran Jalur
Thomas Müller, Fabrice Rousselle, Jan Novák, Alexander Keller
Transaksi ACM pada Grafik ( SIGGRAPH ), Agustus 2021
Makalah / Pembicaraan GTC / Video / Penampil hasil interaktif / BibTeX
Serta perangkat lunak berikut:
NerfAcc: Kotak Alat Aklerasi NeRF Umum
Ruilong Li, Matthew Tancik, Angjoo Kanazawa
https://github.com/KAIR-BAIR/nerfacc
Nerfstudio: Kerangka Pengembangan Bidang Neural Radiance
Matthew Tancik*, Ethan Weber*, Evonne Ng*, Ruilong Li, Brent Yi, Terrance Wang, Alexander Kristoffersen, Jake Austin, Kamyar Salahi, Abhik Ahuja, David McAllister, Angjoo Kanazawa
https://github.com/nerfstudio-project/nerfstudio
Silakan membuat permintaan penarikan jika publikasi atau perangkat lunak Anda tidak tercantum.
Terima kasih khusus ditujukan kepada penulis NRC atas diskusi yang bermanfaat dan kepada Nikolaus Binder yang telah menyediakan sebagian infrastruktur framework ini, serta bantuan dalam memanfaatkan TensorCores dari dalam CUDA.


