

Robot baru di kota: SO-100

Kami baru saja menambahkan tutorial baru tentang cara membuat robot yang lebih terjangkau, dengan harga $110 per lengan!
Ajari dia keterampilan baru dengan menunjukkan beberapa gerakan hanya dengan laptop.
Lalu saksikan robot buatan Anda bertindak secara mandiri?
Ikuti tautan ke tutorial lengkap untuk SO-100.
LeRobot: AI tercanggih untuk robotika dunia nyata
? LeRobot bertujuan untuk menyediakan model, kumpulan data, dan alat untuk robotika dunia nyata di PyTorch. Tujuannya adalah untuk menurunkan hambatan masuk ke bidang robotika sehingga semua orang dapat berkontribusi dan mendapatkan manfaat dari berbagi kumpulan data dan model yang telah dilatih sebelumnya.
? LeRobot berisi pendekatan canggih yang telah terbukti dapat ditransfer ke dunia nyata dengan fokus pada pembelajaran imitasi dan pembelajaran penguatan.
? LeRobot sudah menyediakan serangkaian model terlatih, kumpulan data dengan demonstrasi yang dikumpulkan manusia, dan lingkungan simulasi untuk memulai tanpa merakit robot. Dalam beberapa minggu mendatang, rencananya adalah untuk menambah lebih banyak dukungan untuk robotika dunia nyata pada robot yang paling terjangkau dan mampu di luar sana.
? LeRobot menghosting model dan kumpulan data yang telah dilatih sebelumnya di halaman komunitas Hugging Face ini: huggingface.co/lerobot
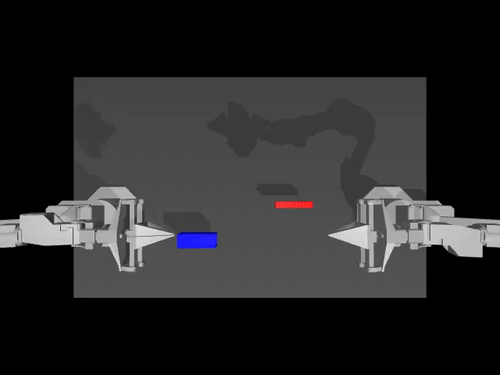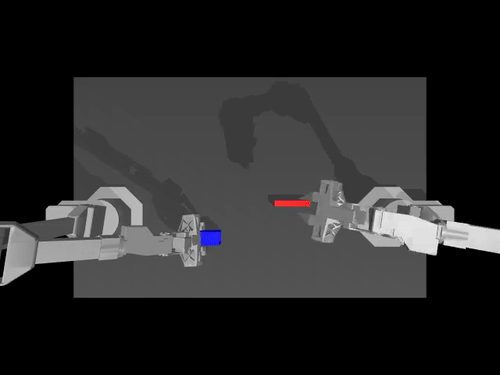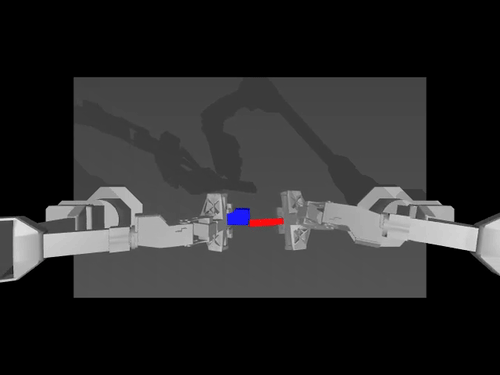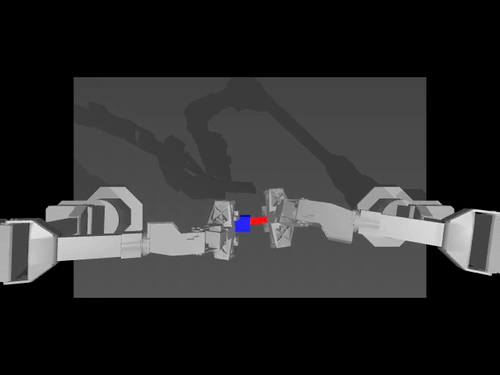 |  |  |
| Kebijakan ACT di ALOHA env | Kebijakan TDMPC pada SimXArm env | Kebijakan difusi di PushT env |
Unduh kode sumber kami:
git clone https://github.com/huggingface/lerobot.git
cd lerobot Buat lingkungan virtual dengan Python 3.10 dan aktifkan, misalnya dengan miniconda :
conda create -y -n lerobot python=3.10
conda activate lerobotInstal? LeRobot:
pip install -e .CATATAN: Tergantung pada platform Anda, Jika Anda menemukan kesalahan build apa pun selama langkah ini, Anda mungkin perlu menginstal
cmakedanbuild-essentialuntuk membangun beberapa dependensi kami. Di linux:sudo apt-get install cmake build-essential
Untuk simulasi, ? LeRobot hadir dengan lingkungan gimnasium yang dapat diinstal sebagai tambahan:
Misalnya, untuk menginstal ? LeRobot dengan aloha dan pusht, gunakan:
pip install -e " .[aloha, pusht] "Untuk menggunakan Bobot dan Bias dalam pelacakan eksperimen, masuklah
wandb login(catatan: Anda juga harus mengaktifkan WandB di konfigurasi. Lihat di bawah.)
.
├── examples # contains demonstration examples, start here to learn about LeRobot
| └── advanced # contains even more examples for those who have mastered the basics
├── lerobot
| ├── configs # contains hydra yaml files with all options that you can override in the command line
| | ├── default.yaml # selected by default, it loads pusht environment and diffusion policy
| | ├── env # various sim environments and their datasets: aloha.yaml, pusht.yaml, xarm.yaml
| | └── policy # various policies: act.yaml, diffusion.yaml, tdmpc.yaml
| ├── common # contains classes and utilities
| | ├── datasets # various datasets of human demonstrations: aloha, pusht, xarm
| | ├── envs # various sim environments: aloha, pusht, xarm
| | ├── policies # various policies: act, diffusion, tdmpc
| | ├── robot_devices # various real devices: dynamixel motors, opencv cameras, koch robots
| | └── utils # various utilities
| └── scripts # contains functions to execute via command line
| ├── eval.py # load policy and evaluate it on an environment
| ├── train.py # train a policy via imitation learning and/or reinforcement learning
| ├── control_robot.py # teleoperate a real robot, record data, run a policy
| ├── push_dataset_to_hub.py # convert your dataset into LeRobot dataset format and upload it to the Hugging Face hub
| └── visualize_dataset.py # load a dataset and render its demonstrations
├── outputs # contains results of scripts execution: logs, videos, model checkpoints
└── tests # contains pytest utilities for continuous integration
Lihat contoh 1 yang mengilustrasikan cara menggunakan kelas kumpulan data kami yang secara otomatis mengunduh data dari hub Hugging Face.
Anda juga dapat memvisualisasikan episode secara lokal dari kumpulan data di hub dengan menjalankan skrip kami dari baris perintah:
python lerobot/scripts/visualize_dataset.py
--repo-id lerobot/pusht
--episode-index 0 atau dari kumpulan data di folder lokal dengan variabel lingkungan root DATA_DIR (dalam kasus berikut, kumpulan data akan dicari di ./my_local_data_dir/lerobot/pusht )
DATA_DIR= ' ./my_local_data_dir ' python lerobot/scripts/visualize_dataset.py
--repo-id lerobot/pusht
--episode-index 0 Ini akan membuka rerun.io dan menampilkan aliran kamera, status robot, dan tindakan, seperti ini:
Skrip kami juga dapat memvisualisasikan kumpulan data yang disimpan di server jauh. Lihat python lerobot/scripts/visualize_dataset.py --help untuk instruksi lebih lanjut.
LeRobotDataset Kumpulan data dalam format LeRobotDataset sangat mudah digunakan. Itu dapat dimuat dari repositori di hub Hugging Face atau folder lokal hanya dengan misalnya dataset = LeRobotDataset("lerobot/aloha_static_coffee") dan dapat diindeks seperti kumpulan data Hugging Face dan PyTorch lainnya. Misalnya dataset[0] akan mengambil kerangka temporal tunggal dari kumpulan data yang berisi observasi dan tindakan sebagai tensor PyTorch yang siap untuk dimasukkan ke model.
Kekhususan LeRobotDataset adalah, daripada mengambil satu frame berdasarkan indeksnya, kita dapat mengambil beberapa frame berdasarkan hubungan temporalnya dengan frame yang diindeks, dengan mengatur delta_timestamps ke daftar waktu relatif terhadap frame yang diindeks. Misalnya, dengan delta_timestamps = {"observation.image": [-1, -0.5, -0.2, 0]} seseorang dapat mengambil, untuk indeks tertentu, 4 bingkai: 3 bingkai "sebelumnya" 1 detik, 0,5 detik, dan 0,2 detik sebelum frame yang diindeks, dan frame yang diindeks itu sendiri (sesuai dengan entri 0). Lihat contoh 1_load_lerobot_dataset.py untuk detail lebih lanjut tentang delta_timestamps .
Di balik terpalnya, format LeRobotDataset memanfaatkan beberapa cara untuk membuat serial data yang dapat berguna untuk dipahami jika Anda berencana untuk bekerja lebih dekat dengan format ini. Kami mencoba membuat format kumpulan data yang fleksibel namun sederhana yang akan mencakup sebagian besar jenis fitur dan kekhususan yang ada dalam pembelajaran penguatan dan robotika, dalam simulasi dan di dunia nyata, dengan fokus pada kamera dan keadaan robot tetapi dengan mudah diperluas ke jenis sensorik lainnya. masukan selama dapat diwakili oleh tensor.
Berikut adalah detail penting dan organisasi struktur internal LeRobotDataset tipikal yang dibuat dengan dataset = LeRobotDataset("lerobot/aloha_static_coffee") . Fitur persisnya akan berubah dari satu set data ke set data lainnya, tetapi bukan aspek utamanya:
dataset attributes:
├ hf_dataset: a Hugging Face dataset (backed by Arrow/parquet). Typical features example:
│ ├ observation.images.cam_high (VideoFrame):
│ │ VideoFrame = {'path': path to a mp4 video, 'timestamp' (float32): timestamp in the video}
│ ├ observation.state (list of float32): position of an arm joints (for instance)
│ ... (more observations)
│ ├ action (list of float32): goal position of an arm joints (for instance)
│ ├ episode_index (int64): index of the episode for this sample
│ ├ frame_index (int64): index of the frame for this sample in the episode ; starts at 0 for each episode
│ ├ timestamp (float32): timestamp in the episode
│ ├ next.done (bool): indicates the end of en episode ; True for the last frame in each episode
│ └ index (int64): general index in the whole dataset
├ episode_data_index: contains 2 tensors with the start and end indices of each episode
│ ├ from (1D int64 tensor): first frame index for each episode — shape (num episodes,) starts with 0
│ └ to: (1D int64 tensor): last frame index for each episode — shape (num episodes,)
├ stats: a dictionary of statistics (max, mean, min, std) for each feature in the dataset, for instance
│ ├ observation.images.cam_high: {'max': tensor with same number of dimensions (e.g. `(c, 1, 1)` for images, `(c,)` for states), etc.}
│ ...
├ info: a dictionary of metadata on the dataset
│ ├ codebase_version (str): this is to keep track of the codebase version the dataset was created with
│ ├ fps (float): frame per second the dataset is recorded/synchronized to
│ ├ video (bool): indicates if frames are encoded in mp4 video files to save space or stored as png files
│ └ encoding (dict): if video, this documents the main options that were used with ffmpeg to encode the videos
├ videos_dir (Path): where the mp4 videos or png images are stored/accessed
└ camera_keys (list of string): the keys to access camera features in the item returned by the dataset (e.g. `["observation.images.cam_high", ...]`)
LeRobotDataset diserialkan menggunakan beberapa format file yang tersebar luas untuk setiap bagiannya, yaitu:
safetensorsafetensor Kumpulan data dapat diunggah/diunduh dari hub HuggingFace dengan lancar. Untuk bekerja pada kumpulan data lokal, Anda dapat mengatur variabel lingkungan DATA_DIR ke folder kumpulan data akar Anda seperti yang diilustrasikan pada bagian visualisasi kumpulan data di atas.
Lihat contoh 2 yang mengilustrasikan cara mengunduh kebijakan yang telah dilatih sebelumnya dari hub Hugging Face, dan menjalankan evaluasi pada lingkungan terkait.
Kami juga menyediakan skrip yang lebih mumpuni untuk memparalelkan evaluasi pada beberapa lingkungan selama peluncuran yang sama. Berikut ini contoh model terlatih yang dihosting di lerobot/diffusion_pusht:
python lerobot/scripts/eval.py
-p lerobot/diffusion_pusht
eval.n_episodes=10
eval.batch_size=10Catatan: Setelah melatih kebijakan Anda sendiri, Anda dapat mengevaluasi kembali pos pemeriksaan dengan:
python lerobot/scripts/eval.py -p {OUTPUT_DIR}/checkpoints/last/pretrained_model Lihat python lerobot/scripts/eval.py --help untuk instruksi lebih lanjut.
Lihat contoh 3 yang mengilustrasikan cara melatih model menggunakan pustaka inti kami dengan python, dan contoh 4 yang menunjukkan cara menggunakan skrip pelatihan kami dari baris perintah.
Secara umum, Anda dapat menggunakan skrip pelatihan kami untuk melatih kebijakan apa pun dengan mudah. Berikut contoh pelatihan kebijakan ACT tentang lintasan yang dikumpulkan manusia di lingkungan simulasi Aloha untuk tugas penyisipan:
python lerobot/scripts/train.py
policy=act
env=aloha
env.task=AlohaInsertion-v0
dataset_repo_id=lerobot/aloha_sim_insertion_human Direktori eksperimen dibuat secara otomatis dan akan muncul dengan warna kuning di terminal Anda. Sepertinya outputs/train/2024-05-05/20-21-12_aloha_act_default . Anda dapat menentukan direktori eksperimen secara manual dengan menambahkan argumen ini ke perintah train.py python:
hydra.run.dir=your/new/experiment/dir Di direktori eksperimen akan ada folder bernama checkpoints yang memiliki struktur berikut:
checkpoints
├── 000250 # checkpoint_dir for training step 250
│ ├── pretrained_model # Hugging Face pretrained model dir
│ │ ├── config.json # Hugging Face pretrained model config
│ │ ├── config.yaml # consolidated Hydra config
│ │ ├── model.safetensors # model weights
│ │ └── README.md # Hugging Face model card
│ └── training_state.pth # optimizer/scheduler/rng state and training step Untuk melanjutkan pelatihan dari pos pemeriksaan, Anda dapat menambahkan ini ke perintah train.py python:
hydra.run.dir=your/original/experiment/dir resume=trueIni akan memuat model terlatih, pengoptimal, dan status penjadwal untuk pelatihan. Untuk informasi lebih lanjut silakan lihat tutorial kami tentang dimulainya kembali pelatihan di sini.
Untuk menggunakan Wandb untuk mencatat kurva pelatihan dan evaluasi, pastikan Anda telah menjalankan wandb login sebagai langkah penyiapan satu kali. Kemudian, saat menjalankan perintah pelatihan di atas, aktifkan WandB di konfigurasi dengan menambahkan:
wandb.enable=trueTautan ke log Wandb untuk proses juga akan muncul dengan warna kuning di terminal Anda. Berikut adalah contoh tampilannya di browser Anda. Silakan periksa juga di sini untuk penjelasan beberapa metrik yang umum digunakan dalam log.

Catatan: Untuk efisiensi, selama pelatihan setiap pos pemeriksaan dievaluasi dalam jumlah episode yang sedikit. Anda dapat menggunakan eval.n_episodes=500 untuk mengevaluasi lebih banyak episode daripada default. Atau, setelah pelatihan, Anda mungkin ingin mengevaluasi kembali pos pemeriksaan terbaik Anda di lebih banyak episode atau mengubah pengaturan evaluasi. Lihat python lerobot/scripts/eval.py --help untuk instruksi lebih lanjut.
Kami telah mengatur file konfigurasi kami (ditemukan di lerobot/configs ) sedemikian rupa sehingga mereka mereproduksi hasil SOTA dari varian model tertentu dalam karya aslinya masing-masing. Cukup berjalan:
python lerobot/scripts/train.py policy=diffusion env=pushtmereproduksi hasil SOTA untuk Kebijakan Difusi pada tugas PushT.
Kebijakan yang telah dilatih sebelumnya, beserta detail reproduksi, dapat ditemukan di bagian "Model" di https://huggingface.co/lerobot.
Jika Anda ingin berkontribusi? LeRobot, silakan lihat panduan kontribusi kami.
Untuk menambahkan himpunan data ke hub, Anda perlu masuk menggunakan token akses tulis, yang dapat dihasilkan dari pengaturan Wajah Memeluk:
huggingface-cli login --token ${HUGGINGFACE_TOKEN} --add-to-git-credential Lalu arahkan ke folder kumpulan data mentah Anda (misalnya data/aloha_static_pingpong_test_raw ), dan dorong kumpulan data Anda ke hub dengan:
python lerobot/scripts/push_dataset_to_hub.py
--raw-dir data/aloha_static_pingpong_test_raw
--out-dir data
--repo-id lerobot/aloha_static_pingpong_test
--raw-format aloha_hdf5 Lihat python lerobot/scripts/push_dataset_to_hub.py --help untuk instruksi lebih lanjut.
Jika format set data Anda tidak didukung, terapkan format Anda sendiri di lerobot/common/datasets/push_dataset_to_hub/${raw_format}_format.py dengan menyalin contoh seperti pusht_zarr, umi_zarr, aloha_hdf5, atau xarm_pkl.
Setelah Anda melatih suatu kebijakan, Anda dapat mengunggahnya ke hub Wajah Memeluk menggunakan id hub yang terlihat seperti ${hf_user}/${repo_name} (misalnya lerobot/diffusion_pusht).
Anda harus terlebih dahulu menemukan folder pos pemeriksaan yang terletak di dalam direktori eksperimen Anda (misalnya outputs/train/2024-05-05/20-21-12_aloha_act_default/checkpoints/002500 ). Di dalamnya ada direktori pretrained_model yang seharusnya berisi:
config.json : Versi serial konfigurasi kebijakan (mengikuti konfigurasi kelas data kebijakan).model.safetensors : Satu set parameter torch.nn.Module , disimpan dalam format Hugging Face Safetensors.config.yaml : Konfigurasi pelatihan Hydra terkonsolidasi yang berisi konfigurasi kebijakan, lingkungan, dan kumpulan data. Konfigurasi kebijakan harus sama persis dengan config.json . Konfigurasi lingkungan berguna bagi siapa saja yang ingin mengevaluasi kebijakan Anda. Konfigurasi kumpulan data hanya berfungsi sebagai jejak kertas untuk reproduktifitas.Untuk mengunggahnya ke hub, jalankan perintah berikut:
huggingface-cli upload ${hf_user} / ${repo_name} path/to/pretrained_modelLihat eval.py untuk contoh bagaimana orang lain dapat menggunakan kebijakan Anda.
Contoh cuplikan kode untuk membuat profil evaluasi kebijakan:
from torch . profiler import profile , record_function , ProfilerActivity
def trace_handler ( prof ):
prof . export_chrome_trace ( f"tmp/trace_schedule_ { prof . step_num } .json" )
with profile (
activities = [ ProfilerActivity . CPU , ProfilerActivity . CUDA ],
schedule = torch . profiler . schedule (
wait = 2 ,
warmup = 2 ,
active = 3 ,
),
on_trace_ready = trace_handler
) as prof :
with record_function ( "eval_policy" ):
for i in range ( num_episodes ):
prof . step ()
# insert code to profile, potentially whole body of eval_policy function Jika mau, Anda dapat mengutip karya ini dengan:
@misc { cadene2024lerobot ,
author = { Cadene, Remi and Alibert, Simon and Soare, Alexander and Gallouedec, Quentin and Zouitine, Adil and Wolf, Thomas } ,
title = { LeRobot: State-of-the-art Machine Learning for Real-World Robotics in Pytorch } ,
howpublished = " url{https://github.com/huggingface/lerobot} " ,
year = { 2024 }
}Selain itu, jika Anda menggunakan salah satu arsitektur kebijakan, model terlatih, atau kumpulan data tertentu, disarankan untuk mengutip penulis asli dari karya tersebut seperti yang tercantum di bawah ini:
@article { chi2024diffusionpolicy ,
author = { Cheng Chi and Zhenjia Xu and Siyuan Feng and Eric Cousineau and Yilun Du and Benjamin Burchfiel and Russ Tedrake and Shuran Song } ,
title = { Diffusion Policy: Visuomotor Policy Learning via Action Diffusion } ,
journal = { The International Journal of Robotics Research } ,
year = { 2024 } ,
} @article { zhao2023learning ,
title = { Learning fine-grained bimanual manipulation with low-cost hardware } ,
author = { Zhao, Tony Z and Kumar, Vikash and Levine, Sergey and Finn, Chelsea } ,
journal = { arXiv preprint arXiv:2304.13705 } ,
year = { 2023 }
} @inproceedings { Hansen2022tdmpc ,
title = { Temporal Difference Learning for Model Predictive Control } ,
author = { Nicklas Hansen and Xiaolong Wang and Hao Su } ,
booktitle = { ICML } ,
year = { 2022 }
} @article { lee2024behavior ,
title = { Behavior generation with latent actions } ,
author = { Lee, Seungjae and Wang, Yibin and Etukuru, Haritheja and Kim, H Jin and Shafiullah, Nur Muhammad Mahi and Pinto, Lerrel } ,
journal = { arXiv preprint arXiv:2403.03181 } ,
year = { 2024 }
}

