EasyOCR
v1.7.2
OCR siap pakai dengan 80+ bahasa yang didukung dan semua skrip penulisan populer termasuk: Latin, Cina, Arab, Dewanagari, Sirilik, dll.
Coba Demo di situs web kami
Terintegrasi ke dalam Huggingface Spaces? menggunakan Gradio. Cobalah Demo Web:
24 September 2024 - Versi 1.7.2
Baca semua catatan rilis



Instal menggunakan pip
Untuk rilis stabil terbaru:
pip install easyocrUntuk rilis pengembangan terbaru:
pip install git+https://github.com/JaidedAI/EasyOCR.git Catatan 1: Untuk Windows, silakan instal torch dan torchvision terlebih dahulu dengan mengikuti petunjuk resmi di sini https://pytorch.org. Di situs web pytorch, pastikan untuk memilih versi CUDA yang Anda miliki. Jika Anda ingin menjalankan pada mode CPU saja, pilih CUDA = None .
Catatan 2: Kami juga menyediakan Dockerfile di sini.
import easyocr
reader = easyocr . Reader ([ 'ch_sim' , 'en' ]) # this needs to run only once to load the model into memory
result = reader . readtext ( 'chinese.jpg' )Outputnya akan dalam format daftar, setiap item mewakili kotak pembatas, masing-masing teks terdeteksi dan tingkat kepercayaan.
[([[189, 75], [469, 75], [469, 165], [189, 165]], '愚园路' , 0.3754989504814148),
([[86, 80], [134, 80], [134, 128], [86, 128]], '西' , 0.40452659130096436),
([[517, 81], [565, 81], [565, 123], [517, 123]], '东' , 0.9989598989486694),
([[78, 126], [136, 126], [136, 156], [78, 156]], ' 315 ' , 0.8125889301300049),
([[514, 126], [574, 126], [574, 156], [514, 156]], ' 309 ' , 0.4971577227115631),
([[226, 170], [414, 170], [414, 220], [226, 220]], ' Yuyuan Rd. ' , 0.8261902332305908),
([[79, 173], [125, 173], [125, 213], [79, 213]], ' W ' , 0.9848111271858215),
([[529, 173], [569, 173], [569, 213], [529, 213]], ' E ' , 0.8405593633651733)] Catatan 1: ['ch_sim','en'] adalah daftar bahasa yang ingin Anda baca. Anda bisa melewati beberapa bahasa sekaligus namun tidak semua bahasa bisa digunakan secara bersamaan. Bahasa Inggris kompatibel dengan semua bahasa dan bahasa yang memiliki karakter yang sama biasanya kompatibel satu sama lain.
Catatan 2: Selain jalur file chinese.jpg , Anda juga dapat meneruskan objek gambar OpenCV (array numpy) atau file gambar sebagai byte. URL ke gambar mentah juga dapat diterima.
Catatan 3: Baris reader = easyocr.Reader(['ch_sim','en']) digunakan untuk memuat model ke dalam memori. Dibutuhkan beberapa waktu tetapi hanya perlu dijalankan sekali.
Anda juga dapat mengatur detail=0 untuk keluaran yang lebih sederhana.
reader . readtext ( 'chinese.jpg' , detail = 0 )Hasil:
[ '愚园路' , '西' , '东' , ' 315 ' , ' 309 ' , ' Yuyuan Rd. ' , ' W ' , ' E ' ]Bobot model untuk bahasa yang dipilih akan diunduh secara otomatis atau Anda dapat mengunduhnya secara manual dari hub model dan meletakkannya di folder '~/.EasyOCR/model'
Jika Anda tidak memiliki GPU, atau GPU Anda memiliki memori rendah, Anda dapat menjalankan model dalam mode CPU-only dengan menambahkan gpu=False .
reader = easyocr . Reader ([ 'ch_sim' , 'en' ], gpu = False )Untuk informasi lebih lanjut, baca tutorial dan Dokumentasi API.
$ easyocr -l ch_sim en -f chinese.jpg --detail=1 --gpu=TrueUntuk model pengenalan, Baca di sini.
Untuk model deteksi (CRAFT), Baca di sini.
reader = easyocr . Reader ([ 'en' ], detection = 'DB' , recognition = 'Transformer' )Idenya adalah untuk dapat memasukkan model canggih apa pun ke dalam EasyOCR. Ada banyak orang jenius yang mencoba membuat model deteksi/pengenalan yang lebih baik, namun kami tidak mencoba menjadi jenius di sini. Kami hanya ingin agar karya mereka dapat diakses dengan cepat oleh publik… gratis. (yah, kami yakin sebagian besar orang jenius ingin karya mereka menciptakan dampak positif secepat/sebesar mungkin) Alurnya harus seperti diagram di bawah ini. Slot abu-abu adalah pengganti untuk modul biru muda yang dapat diubah.
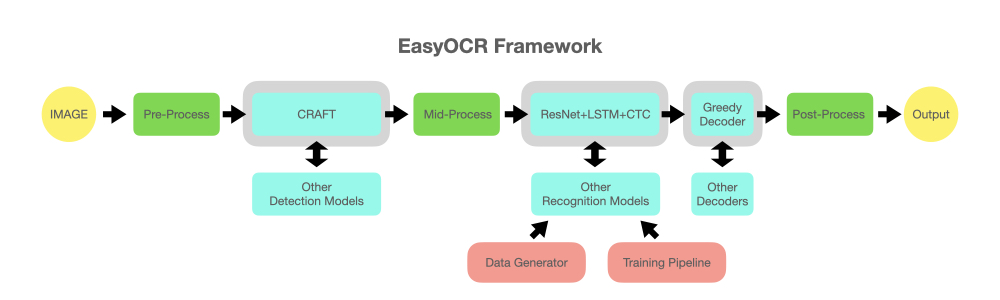
Proyek ini didasarkan pada penelitian dan kode dari beberapa makalah dan repositori sumber terbuka.
Semua pelaksanaan pembelajaran mendalam didasarkan pada Pytorch. ❤️
Eksekusi pendeteksian menggunakan algoritma CRAFT dari repositori resmi ini dan makalahnya (Terima kasih @YoungminBaek dari @clovaai). Kami juga menggunakan model terlatih mereka. Skrip pelatihan disediakan oleh @gmuffiness.
Model pengenalannya adalah CRNN (kertas). Ini terdiri dari 3 komponen utama: ekstraksi fitur (saat ini kami menggunakan Resnet) dan VGG, pelabelan urutan (LSTM) dan decoding (CTC). Alur pelatihan untuk eksekusi pengenalan adalah versi modifikasi dari kerangka kerja tolok ukur pengenalan teks dalam. (Terima kasih @ku21fan dari @clovaai) Repositori ini adalah permata yang layak mendapat pengakuan lebih.
Kode pencarian beam didasarkan pada repositori ini dan blognya. (Terima kasih @githubharald)
Sintesis data didasarkan pada TextRecognitionDataGenerator. (Terima kasih @Belval)
Dan bacaan bagus tentang CTC dari distill.pub di sini.
Mari bersama-sama memajukan umat manusia dengan menyediakan AI bagi semua orang!
3 cara untuk berkontribusi:
Pembuat kode: Silakan kirim PR untuk bug/perbaikan kecil. Untuk yang lebih besar, diskusikan dengan kami dengan membuka isu terlebih dahulu. Ada daftar kemungkinan masalah bug/perbaikan yang ditandai dengan 'PR SELAMAT DATANG'.
Pengguna: Beri tahu kami manfaat EasyOCR bagi Anda/organisasi Anda untuk mendorong pengembangan lebih lanjut. Posting juga kasus kegagalan di Bagian Masalah untuk membantu meningkatkan model masa depan.
Pemimpin teknologi/Guru: Jika menurut Anda perpustakaan ini bermanfaat, silakan sebarkan! (Lihat postingan Yann Lecun tentang EasyOCR)
Untuk meminta bahasa baru, kami ingin Anda mengirimkan PR dengan 2 file berikut:
Jika bahasa Anda memiliki unsur unik (seperti 1. Arab: karakter berubah bentuk ketika ditempelkan + menulis dari kanan ke kiri 2. Thailand: Beberapa karakter harus berada di atas garis dan beberapa di bawah), mohon didik kami sebaik mungkin kemampuan Anda dan/atau memberikan tautan yang bermanfaat. Penting untuk memperhatikan detail untuk mencapai sistem yang benar-benar berfungsi.
Terakhir, harap dipahami bahwa prioritas kami adalah bahasa populer atau kumpulan bahasa yang memiliki sebagian besar karakter yang sama (beri tahu kami juga jika hal ini berlaku untuk bahasa Anda). Kami memerlukan waktu setidaknya satu minggu untuk mengembangkan model baru, jadi Anda mungkin harus menunggu beberapa saat hingga model baru tersebut dirilis.
Lihat Daftar bahasa dalam pengembangan
Karena keterbatasan sumber daya, masalah yang lebih lama dari 6 bulan akan ditutup secara otomatis. Silakan buka kembali terbitan jika itu penting.
Untuk Dukungan Perusahaan, Jaided AI menawarkan layanan lengkap untuk sistem OCR/AI khusus mulai dari implementasi, pelatihan/penyempurnaan, dan penerapan. Klik di sini untuk menghubungi kami.


