nmt
1.0.0
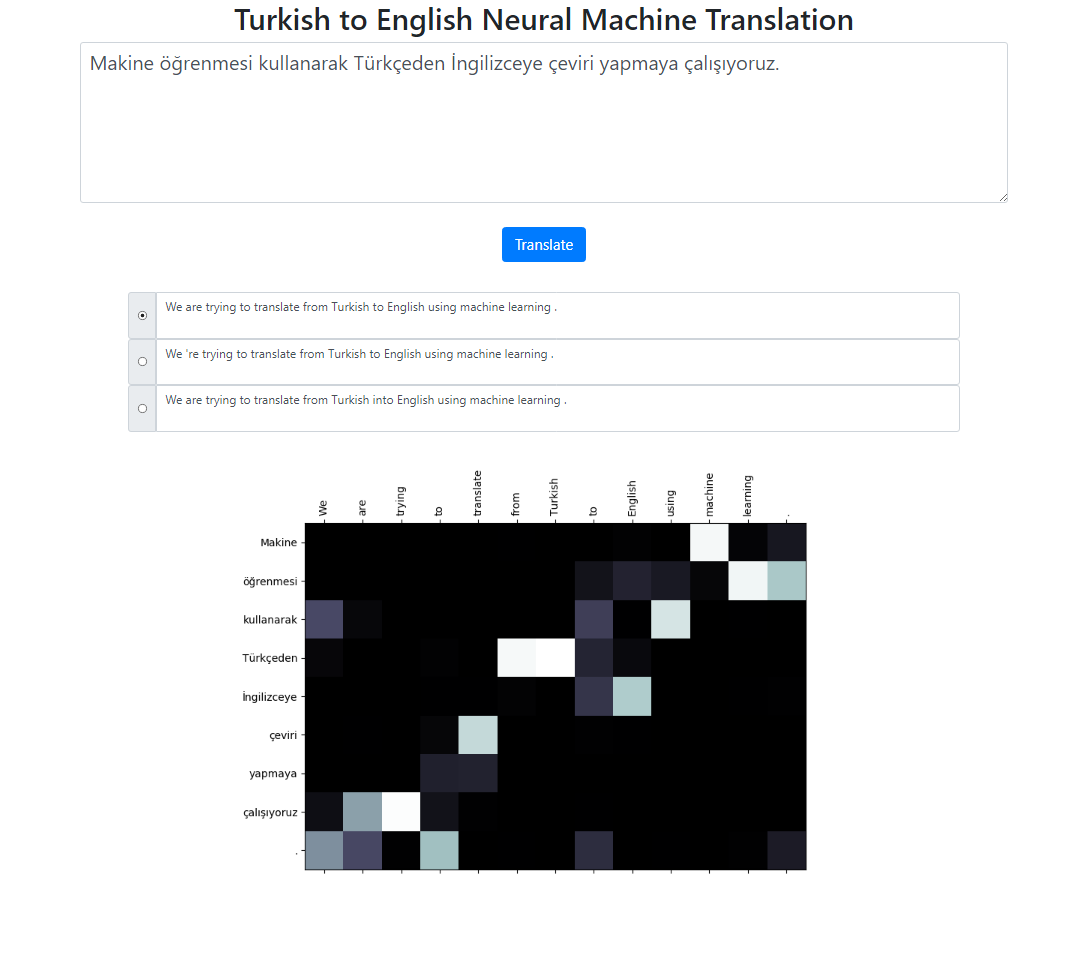
Repositori ini mengimplementasikan sistem Terjemahan Mesin Neural Bahasa Turki ke Bahasa Inggris menggunakan model Seq2Seq + Global Attention. Ada juga aplikasi Flask yang bisa Anda jalankan secara lokal. Anda dapat memasukkan teks, menerjemahkan dan memeriksa hasil serta visualisasi perhatian. Kami menjalankan pencarian berkas dengan ukuran berkas 3 di latar belakang dan mengembalikan urutan yang paling mungkin diurutkan berdasarkan skor relatifnya.
Kumpulan data untuk proyek ini diambil dari sini. Saya telah menggunakan korpus Tatoeba. Saya telah menghapus beberapa duplikat yang ditemukan di data. Saya juga melakukan pretoken pada kumpulan data tersebut. Versi final dapat ditemukan di folder data.
Untuk memberi token pada kalimat Turki, saya telah menggunakan RegexpTokenizer nltk.
puncts_kecuali_apostrofe = '!"#$%&()*+,-./:;<=>?@[]^_`{|}~'TOKENIZE_PATTERN = fr"[{puncts_kecuali_apostrophe}]|w+|['w ]+"regex_tokenizer = RegexpTokenizer(pattern=TOKENIZE_PATTERN)text = "Titanic 15 Nisan pazartesi saat 02:20'de battı."tokenized_text = regex_tokenizer.tokenize(text)print(" ".join(tokenized_text))# Output: Titanic 15 Nisan pazartesi saat 02 : 20 'de battı .# Properti pemisahan ini pada "02 : 20" berbeda dengan tokenizer bahasa Inggris.# Kita bisa menangani situasi tersebut. Tapi saya ingin membuatnya tetap sederhana dan lihat apakah # distribusi perhatian pada kata-kata tersebut selaras dengan token bahasa Inggris.# Kasus serupa juga sering terjadi pada tanggal seperti dalam contoh ini: 02/09/2019Untuk memberi token pada kalimat bahasa Inggris, saya menggunakan model bahasa Inggris spacy.
en_nlp = spacy.load('en_core_web_sm')text = "Titanic tenggelam pukul 02:20 hari Senin, 15 April."tokenized_text = en_nlp.tokenizer(text)print(" ".join([tok.text for tok in tokenized_text ]))# Keluaran: Titanic tenggelam pada pukul 02:20 pada hari Senin, 15 April.Kalimat Turki dan Inggris diharapkan berada dalam dua file berbeda.
file: train.tr tr_sent_1 tr_sent_2 tr_sent_3 ... file: train.en en_sent_1 en_sent_2 en_sent_3 ...
Silakan jalankan python train.py -h untuk daftar argumen lengkap.
Sample usage: python train.py --train_data train.tr train.en --valid_data valid.tr valid.en --n_epochs 30 --batch_size 32 --embedding_dim 256 --hidden_size 256 --num_layers 2 --bidirectional --dropout_p 0.3 --device cuda
Untuk menghitung skor biru tingkat korpus.
usage: test.py [-h] --model_file MODEL_FILE --valid_data VALID_DATA [VALID_DATA ...] Neural Machine Translation Testing optional arguments: -h, --help show this help message and exit --model_file MODEL_FILE Model File --valid_data VALID_DATA [VALID_DATA ...] Validation_data Sample Usage: python test.py --model_file model.bin --validation_data valid.tr valid.en
Untuk menjalankan aplikasi secara lokal, jalankan:
python app.py
Pastikan jalur model Anda di file config.py ditentukan dengan benar.
Berkas model
File kosakata
Menggunakan unit subkata (untuk bahasa Turki dan Inggris)
Mekanisme perhatian yang berbeda (mempelajari parameter perhatian yang berbeda)
Kode kerangka untuk proyek ini diambil dari Kursus NLP Stanford: CS224n


