Alat untuk Ekstensi Tesaurus menggunakan metode Propagasi Label. Dari korpus teks dan tesaurus yang sudah ada, menghasilkan saran untuk memperluas kumpulan sinonim yang ada. Alat ini dikembangkan selama Tesis Master " Propagasi Label untuk Ekstensi Tesaurus Hukum Perpajakan " di Ketua "Rekayasa Perangkat Lunak untuk Sistem Informasi Bisnis (sebis)", Universitas Teknik Munich (TUM).
Abstrak Tesis. Dengan meningkatnya digitalisasi, pencarian informasi harus mengatasi meningkatnya jumlah konten digital. Penyedia konten legal menginvestasikan banyak uang untuk membangun ontologi khusus domain seperti tesauri untuk mengambil dokumen relevan dalam jumlah yang meningkat secara signifikan. Sejak tahun 2002, banyak metode propagasi label telah dikembangkan misalnya untuk mengidentifikasi kelompok node serupa dalam grafik. Propagasi label adalah rangkaian algoritma pembelajaran mesin semi-supervisi berbasis grafik. Dalam tesis ini, kami akan menguji kesesuaian metode propagasi label untuk memperluas tesaurus dari domain hukum perpajakan. Grafik tempat propagasi label beroperasi adalah grafik kesamaan yang dibuat dari penyematan kata. Kami membahas proses dari ujung ke ujung dan melakukan beberapa studi parameter untuk memahami dampak hyper-parameter tertentu terhadap kinerja secara keseluruhan. Hasilnya kemudian dievaluasi dalam studi manual dan dibandingkan dengan pendekatan dasar.
Alat ini diimplementasikan menggunakan arsitektur pipa dan filter berikut:
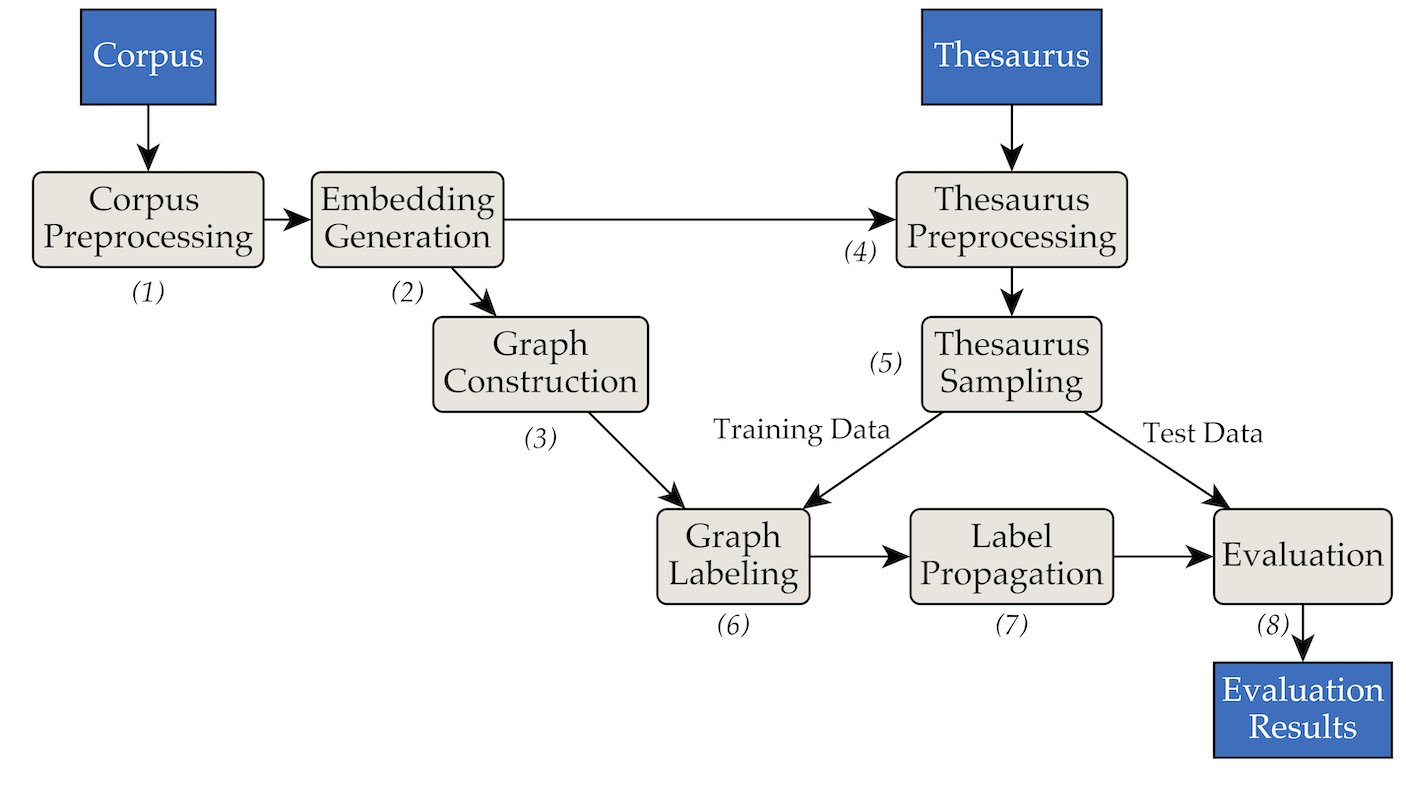
pipenv (Panduan Instalasi).pipenv install . data/RW40jsons , dan tesaurus di data/german_relat_pretty-20180605.json . Lihat Phase1.py dan Phase4.py untuk informasi tentang format file yang diharapkan.output/<PHASE_FOLDER>/<DATE> . Yang paling penting adalah 08_propagation_evaluation dan XX_runs . Di 08_propagation_evaluation , statistik evaluasi disimpan sebagai stats.json bersama dengan tabel yang berisi prediksi, pelatihan, dan set pengujian ( main.txt , dalam skrip lain paling sering disebut sebagai df_evaluation ). Di XX_runs , log proses disimpan. Jika beberapa proses dipicu melalui multi_runs.py (masing-masing dengan set pelatihan/pengujian yang berbeda), statistik gabungan dari semua proses individual juga disimpan sebagai all_stats.json . Melalui purew2v_parameter_studies.py, garis dasar vektor synset yang kami perkenalkan dalam tesis kami dapat dieksekusi. Ini memerlukan serangkaian penyematan kata dan satu atau beberapa pemisahan pelatihan/tes tesaurus. Lihat sample_commands.md sebagai contoh.
Di ipynbs , kami menyediakan beberapa buku catatan Jupyter teladan yang digunakan untuk menghasilkan (a) statistik, (b) diagram, dan (c) file Excel untuk evaluasi manual. Anda dapat menjelajahinya dengan menjalankan pipenv shell dan kemudian memulai Jupyter dengan jupyter notebook .
main.py atau multi_run.py .

