Kursus Model Bahasa Besar
? Ikuti saya di X • ? Memeluk Wajah • Blog • ? GNN langsung
Kursus LLM dibagi menjadi tiga bagian:
- ? Dasar-dasar LLM mencakup pengetahuan penting tentang matematika, Python, dan jaringan saraf.
- ?? Ilmuwan LLM berfokus pada membangun LLM terbaik dengan menggunakan teknik terbaru.
- ? Insinyur LLM berfokus pada pembuatan aplikasi berbasis LLM dan penerapannya.
Untuk versi interaktif kursus ini, saya membuat dua asisten LLM yang akan menjawab pertanyaan dan menguji pengetahuan Anda dengan cara yang dipersonalisasi:
- ? Asisten HuggingChat : Versi gratis menggunakan Mixtral-8x7B.
- ? Asisten ChatGPT : Membutuhkan akun premium.
buku catatan
Daftar buku catatan dan artikel yang berkaitan dengan model bahasa besar.
Peralatan
| Buku catatan | Keterangan | Buku catatan |
|---|
| ? Evaluasi Otomatis LLM | Evaluasi LLM Anda secara otomatis menggunakan RunPod | |
| ? Penggabungan Malas | Gabungkan model dengan mudah menggunakan MergeKit dalam satu klik. | |
| ? MalasAxolotl | Sempurnakan model di cloud menggunakan Axolotl dalam satu klik. | |
| ⚡ Kuantitas Otomatis | Hitung LLM dalam format GGUF, GPTQ, EXL2, AWQ, dan HQQ dalam satu klik. | |
| ? Model Pohon Keluarga | Visualisasikan pohon keluarga model gabungan. | |
| Ruang Nol | Secara otomatis membuat antarmuka obrolan Gradio menggunakan ZeroGPU gratis. | |
Penyempurnaan
| Buku catatan | Keterangan | Artikel | Buku catatan |
|---|
| Sempurnakan Llama 2 dengan QLoRA | Panduan langkah demi langkah untuk menyempurnakan Llama 2 dengan pengawasan di Google Colab. | Artikel | |
| Sempurnakan CodeLlama menggunakan Axolotl | Panduan menyeluruh tentang alat canggih untuk penyempurnaan. | Artikel | |
| Sempurnakan Mistral-7b dengan QLoRA | Penyempurnaan Mistral-7b yang diawasi di Google Colab tingkat gratis dengan TRL. | | |
| Sempurnakan Mistral-7b dengan DPO | Tingkatkan performa model yang diawasi dan disempurnakan dengan DPO. | Artikel | |
| Sempurnakan Llama 3 dengan ORPO | Penyempurnaan yang lebih murah dan cepat dalam satu tahap dengan ORPO. | Artikel | |
| Sempurnakan Llama 3.1 dengan Unsloth | Penyempurnaan terawasi yang sangat efisien di Google Colab. | Artikel | |
Kuantisasi
| Buku catatan | Keterangan | Artikel | Buku catatan |
|---|
| Pengantar Kuantisasi | Optimalisasi model bahasa besar menggunakan kuantisasi 8-bit. | Artikel | |
| Kuantisasi 4-bit menggunakan GPTQ | Hitung LLM sumber terbuka Anda sendiri untuk menjalankannya di perangkat keras konsumen. | Artikel | |
| Kuantisasi dengan GGUF dan llama.cpp | Hitung model Llama 2 dengan llama.cpp dan unggah versi GGUF ke HF Hub. | Artikel | |
| ExLlamaV2: Perpustakaan Tercepat untuk Menjalankan LLM | Hitung dan jalankan model EXL2 dan unggah ke HF Hub. | Artikel | |
Lainnya
| Buku catatan | Keterangan | Artikel | Buku catatan |
|---|
| Strategi Decoding dalam Model Bahasa Besar | Panduan pembuatan teks mulai dari penelusuran berkas hingga pengambilan sampel inti | Artikel | |
| Tingkatkan ChatGPT dengan Grafik Pengetahuan | Tingkatkan jawaban ChatGPT dengan grafik pengetahuan. | Artikel | |
| Gabungkan LLM dengan MergeKit | Buat model Anda sendiri dengan mudah, tidak perlu GPU! | Artikel | |
| Buat MoE dengan MergeKit | Gabungkan beberapa pakar menjadi satu frankenMoE | Artikel | |
| Buka sensor LLM apa pun dengan aliterasi | Menyempurnakan tanpa pelatihan ulang | Artikel | |
? Dasar-dasar LLM
Bagian ini memperkenalkan pengetahuan penting tentang matematika, Python, dan jaringan saraf. Anda mungkin tidak ingin memulai di sini tetapi merujuknya sesuai kebutuhan.
Beralih bagian
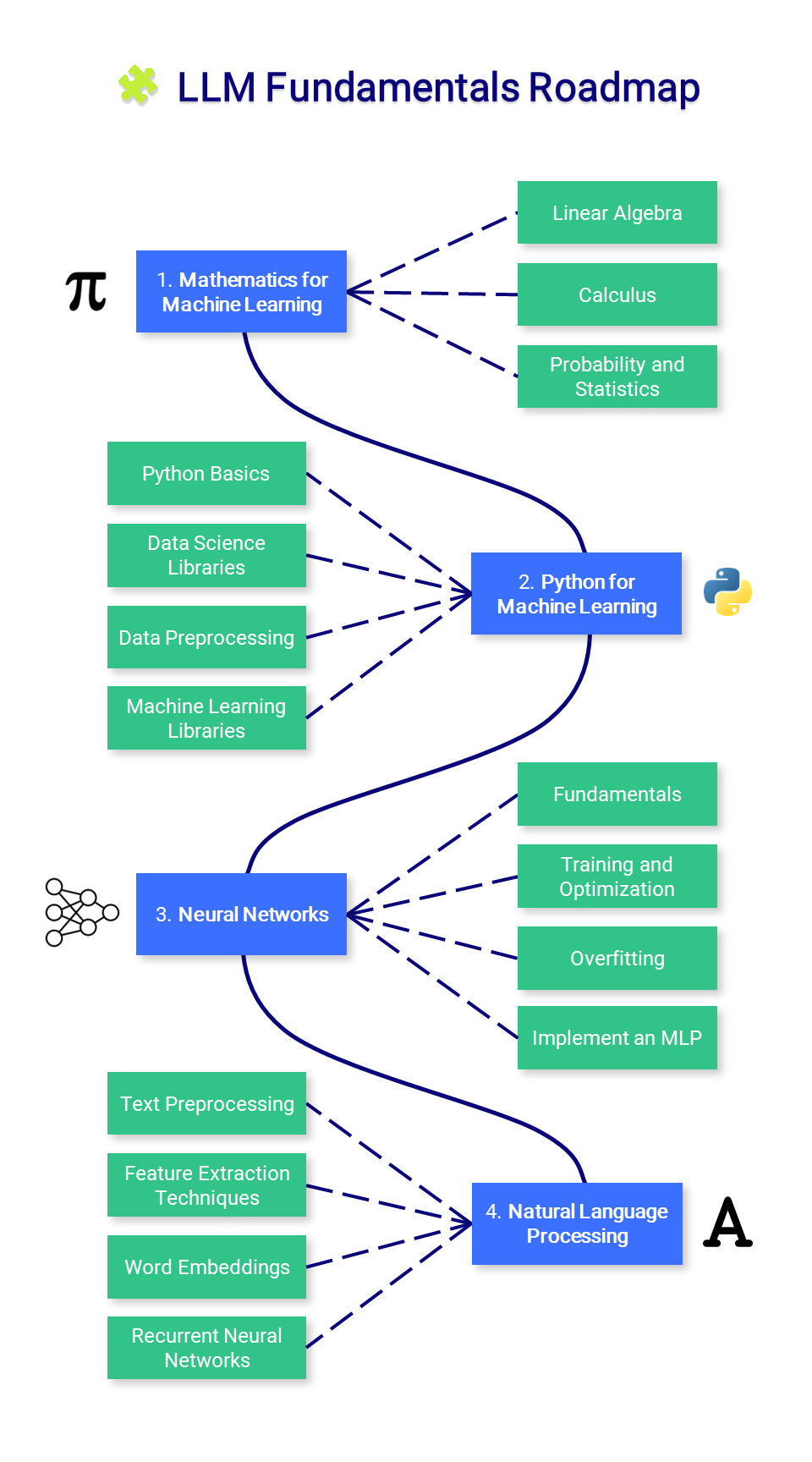
1. Matematika untuk Pembelajaran Mesin
Sebelum menguasai pembelajaran mesin, penting untuk memahami konsep matematika dasar yang mendukung algoritma ini.
- Aljabar Linier : Ini penting untuk memahami banyak algoritma, terutama yang digunakan dalam pembelajaran mendalam. Konsep utama meliputi vektor, matriks, determinan, nilai eigen dan vektor eigen, ruang vektor, dan transformasi linier.
- Kalkulus : Banyak algoritme pembelajaran mesin melibatkan optimalisasi fungsi berkelanjutan, yang memerlukan pemahaman tentang turunan, integral, limit, dan deret. Kalkulus multivariabel dan konsep gradien juga penting.
- Probabilitas dan Statistik : Ini penting untuk memahami bagaimana model belajar dari data dan membuat prediksi. Konsep utama mencakup teori probabilitas, variabel acak, distribusi probabilitas, ekspektasi, varians, kovarians, korelasi, pengujian hipotesis, interval kepercayaan, estimasi kemungkinan maksimum, dan inferensi Bayesian.
Sumber daya:
- 3Blue1Brown - Intisari Aljabar Linier: Rangkaian video yang memberikan intuisi geometris pada konsep-konsep ini.
- StatQuest dengan Josh Starmer - Dasar-Dasar Statistik: Menawarkan penjelasan sederhana dan jelas untuk banyak konsep statistik.
- Intuisi Statistik AP oleh Ms Aerin: Daftar artikel Medium yang memberikan intuisi di balik setiap distribusi probabilitas.
- Aljabar Linier Immersive: Interpretasi visual lain dari aljabar linier.
- Khan Academy - Aljabar Linier: Cocok untuk pemula karena menjelaskan konsep dengan cara yang sangat intuitif.
- Khan Academy - Kalkulus: Kursus interaktif yang mencakup semua dasar-dasar kalkulus.
- Khan Academy - Probabilitas dan Statistik: Menyampaikan materi dalam format yang mudah dipahami.
2. Python untuk Pembelajaran Mesin
Python adalah bahasa pemrograman yang kuat dan fleksibel yang sangat baik untuk pembelajaran mesin, berkat keterbacaan, konsistensi, dan ekosistem perpustakaan ilmu data yang kuat.
- Dasar-dasar Python : Pemrograman Python memerlukan pemahaman yang baik tentang sintaks dasar, tipe data, penanganan kesalahan, dan pemrograman berorientasi objek.
- Perpustakaan Ilmu Data : Mencakup keakraban dengan NumPy untuk operasi numerik, Pandas untuk manipulasi dan analisis data, Matplotlib dan Seaborn untuk visualisasi data.
- Pemrosesan Awal Data : Ini melibatkan penskalaan dan normalisasi fitur, penanganan data yang hilang, deteksi outlier, pengkodean data kategorikal, dan pemisahan data menjadi set pelatihan, validasi, dan pengujian.
- Perpustakaan Pembelajaran Mesin : Kemahiran dalam Scikit-learn, perpustakaan yang menyediakan berbagai pilihan algoritme pembelajaran yang diawasi dan tidak diawasi, sangatlah penting. Memahami cara mengimplementasikan algoritme seperti regresi linier, regresi logistik, pohon keputusan, hutan acak, k-nearest neighbour (K-NN), dan pengelompokan K-means adalah hal yang penting. Teknik reduksi dimensi seperti PCA dan t-SNE juga berguna untuk memvisualisasikan data berdimensi tinggi.
Sumber daya:
- Real Python: Sumber daya komprehensif dengan artikel dan tutorial untuk konsep Python pemula dan lanjutan.
- freeCodeCamp - Belajar Python: Video panjang yang memberikan pengenalan lengkap tentang semua konsep inti dalam Python.
- Buku Panduan Ilmu Data Python: Buku digital gratis yang merupakan sumber bagus untuk mempelajari panda, NumPy, Matplotlib, dan Seaborn.
- freeCodeCamp - Pembelajaran Mesin untuk Semua Orang: Pengenalan praktis berbagai algoritma pembelajaran mesin untuk pemula.
- Udacity - Pengantar Pembelajaran Mesin: Kursus gratis yang mencakup PCA dan beberapa konsep pembelajaran mesin lainnya.
3. Jaringan Syaraf Tiruan
Jaringan saraf adalah bagian mendasar dari banyak model pembelajaran mesin, khususnya dalam bidang pembelajaran mendalam. Untuk memanfaatkannya secara efektif, pemahaman komprehensif tentang desain dan mekanikanya sangat penting.
- Dasar : Ini termasuk memahami struktur jaringan saraf seperti lapisan, bobot, bias, dan fungsi aktivasi (sigmoid, tanh, ReLU, dll.)
- Pelatihan dan Optimasi : Biasakan diri Anda dengan propagasi mundur dan berbagai jenis fungsi kerugian, seperti Mean Squared Error (MSE) dan Cross-Entropy. Memahami berbagai algoritma optimasi seperti Gradient Descent, Stochastic Gradient Descent, RMSprop, dan Adam.
- Overfitting : Memahami konsep overfitting (di mana model berperforma baik pada data pelatihan tetapi buruk pada data yang tidak terlihat) dan mempelajari berbagai teknik regularisasi (dropout, regularisasi L1/L2, penghentian awal, augmentasi data) untuk mencegahnya.
- Menerapkan Multilayer Perceptron (MLP) : Bangun MLP, juga dikenal sebagai jaringan yang terhubung sepenuhnya, menggunakan PyTorch.
Sumber daya:
- 3Blue1Brown - Tapi apa itu Jaringan Neural?: Video ini memberikan penjelasan intuitif tentang jaringan saraf dan cara kerjanya.
- freeCodeCamp - Kursus Singkat Pembelajaran Mendalam: Video ini secara efisien memperkenalkan semua konsep terpenting dalam pembelajaran mendalam.
- Fast.ai - Pembelajaran Mendalam Praktis: Kursus gratis yang dirancang untuk orang-orang dengan pengalaman coding yang ingin belajar tentang pembelajaran mendalam.
- Patrick Loeber - Tutorial PyTorch: Serangkaian video untuk pemula lengkap yang belajar tentang PyTorch.
4. Pemrosesan Bahasa Alami (NLP)
NLP adalah cabang kecerdasan buatan yang menjembatani kesenjangan antara bahasa manusia dan pemahaman mesin. Dari pemrosesan teks sederhana hingga memahami nuansa linguistik, NLP memainkan peran penting dalam banyak aplikasi seperti terjemahan, analisis sentimen, chatbots, dan banyak lagi.
- Pemrosesan Awal Teks : Pelajari berbagai langkah prapemrosesan teks seperti tokenisasi (memisahkan teks menjadi kata atau kalimat), stemming (mereduksi kata ke bentuk akarnya), lemmatisasi (mirip dengan stemming tetapi mempertimbangkan konteksnya), penghentian penghapusan kata, dll.
- Teknik Ekstraksi Fitur : Memahami teknik mengubah data teks menjadi format yang dapat dipahami oleh algoritme pembelajaran mesin. Metode utama mencakup Bag-of-words (BoW), Term Frekuensi-Invers Dokumen Frekuensi (TF-IDF), dan n-gram.
- Penyematan Kata : Penyematan kata adalah jenis representasi kata yang memungkinkan kata-kata dengan makna serupa memiliki representasi serupa. Metode utama termasuk Word2Vec, GloVe, dan FastText.
- Jaringan Neural Berulang (RNN) : Memahami cara kerja RNN, sejenis jaringan saraf yang dirancang untuk bekerja dengan data urutan. Jelajahi LSTM dan GRU, dua varian RNN yang mampu mempelajari dependensi jangka panjang.
Sumber daya:
- RealPython - NLP dengan spaCy dengan Python: Panduan lengkap tentang perpustakaan spaCy untuk tugas NLP dengan Python.
- Kaggle - Panduan NLP: Beberapa buku catatan dan sumber daya untuk penjelasan langsung tentang NLP dengan Python.
- Jay Alammar - Ilustrasi Word2Vec: Referensi yang bagus untuk memahami arsitektur Word2Vec yang terkenal.
- Jake Tae - PyTorch RNN dari Awal: Implementasi model RNN, LSTM, dan GRU yang praktis dan sederhana di PyTorch.
- blog colah - Memahami Jaringan LSTM: Artikel yang lebih teoritis tentang jaringan LSTM.
?? Ilmuwan LLM
Bagian kursus ini berfokus pada pembelajaran bagaimana membangun LLM terbaik dengan menggunakan teknik terbaru.
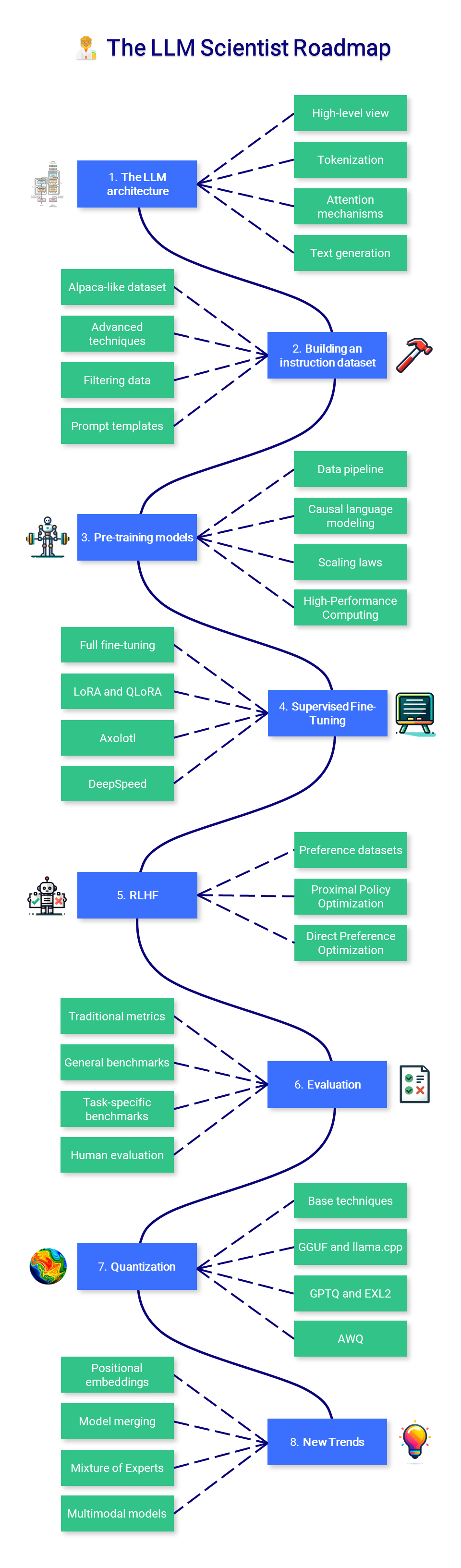
1. Arsitektur LLM
Meskipun pengetahuan mendalam tentang arsitektur Transformer tidak diperlukan, penting untuk memiliki pemahaman yang baik tentang masukan (token) dan keluaran (logit). Mekanisme perhatian vanilla adalah komponen penting lainnya yang harus dikuasai, karena versi yang lebih baik akan diperkenalkan nanti.
- Tampilan tingkat tinggi : Tinjau kembali arsitektur Transformer encoder-decoder, dan lebih khusus lagi arsitektur GPT khusus decoder, yang digunakan di setiap LLM modern.
- Tokenisasi : Memahami cara mengonversi data teks mentah ke dalam format yang dapat dipahami model, yang melibatkan pemisahan teks menjadi token (biasanya kata atau subkata).
- Mekanisme perhatian : Pahami teori di balik mekanisme perhatian, termasuk perhatian mandiri dan perhatian produk titik berskala, yang memungkinkan model untuk fokus pada bagian masukan yang berbeda saat menghasilkan keluaran.
- Pembuatan teks : Pelajari berbagai cara model dapat menghasilkan rangkaian keluaran. Strategi umum termasuk decoding serakah, pencarian berkas, pengambilan sampel top-k, dan pengambilan sampel inti.
Referensi :
- The Illustrated Transformer oleh Jay Alammar: Penjelasan visual dan intuitif tentang model Transformer.
- Ilustrasi GPT-2 oleh Jay Alammar: Yang lebih penting dari artikel sebelumnya, artikel ini berfokus pada arsitektur GPT, yang sangat mirip dengan Llama.
- Intro visual ke Transformers oleh 3Blue1Brown: Intro visual Transformers yang sederhana dan mudah dipahami
- Visualisasi LLM oleh Brendan Bycroft: Visualisasi 3D yang luar biasa tentang apa yang terjadi di dalam LLM.
- nanoGPT oleh Andrej Karpathy: Video YouTube berdurasi 2 jam untuk menerapkan kembali GPT dari awal (untuk pemrogram).
- Perhatian? Perhatian! oleh Lilian Weng: Perkenalkan perlunya perhatian dengan cara yang lebih formal.
- Strategi Decoding di LLM: Memberikan kode dan pengenalan visual tentang berbagai strategi decoding untuk menghasilkan teks.
2. Membangun kumpulan data instruksi
Meskipun mudah untuk menemukan data mentah dari Wikipedia dan situs web lain, sulit untuk mengumpulkan instruksi dan jawaban secara langsung. Seperti dalam pembelajaran mesin tradisional, kualitas kumpulan data akan secara langsung memengaruhi kualitas model, oleh karena itu kualitas model mungkin merupakan komponen terpenting dalam proses penyesuaian.
- Kumpulan data mirip alpaka : Hasilkan data sintetis dari awal dengan OpenAI API (GPT). Anda dapat menentukan benih dan perintah sistem untuk membuat kumpulan data yang beragam.
- Teknik tingkat lanjut : Pelajari cara meningkatkan kumpulan data yang ada dengan Evol-Instruct, cara menghasilkan data sintetis berkualitas tinggi seperti di makalah Orca dan phi-1.
- Memfilter data : Teknik tradisional yang melibatkan regex, menghapus hampir duplikat, berfokus pada jawaban dengan jumlah token yang banyak, dll.
- Templat cepat : Tidak ada cara standar yang sebenarnya untuk memformat instruksi dan jawaban, itulah sebabnya penting untuk mengetahui berbagai templat obrolan, seperti ChatML, Alpaca, dll.
Referensi :
- Mempersiapkan Kumpulan Data untuk Penyetelan Instruksi oleh Thomas Capelle: Eksplorasi kumpulan data Alpaca dan Alpaca-GPT4 dan cara memformatnya.
- Menghasilkan Kumpulan Data Instruksi Klinis oleh Solano Todeschini: Tutorial cara membuat kumpulan data instruksi sintetik menggunakan GPT-4.
- GPT 3.5 untuk klasifikasi berita oleh Kshitiz Sahay: Gunakan GPT 3.5 untuk membuat kumpulan data instruksi guna menyempurnakan Llama 2 untuk klasifikasi berita.
- Pembuatan kumpulan data untuk menyempurnakan LLM: Buku catatan yang berisi beberapa teknik untuk memfilter kumpulan data dan mengunggah hasilnya.
- Templat Obrolan oleh Matthew Carrigan: Halaman Hugging Face tentang templat cepat
3. Model pra-pelatihan
Pra-pelatihan adalah proses yang sangat panjang dan mahal, oleh karena itu hal ini tidak menjadi fokus kursus ini. Ada baiknya untuk memiliki pemahaman tertentu tentang apa yang terjadi selama pra-pelatihan, namun pengalaman langsung tidak diperlukan.
- Saluran data : Pra-pelatihan memerlukan kumpulan data yang sangat besar (misalnya, Llama 2 dilatih dengan 2 triliun token) yang perlu disaring, diberi token, dan disusun dengan kosakata yang telah ditentukan sebelumnya.
- Pemodelan bahasa kausal : Pelajari perbedaan antara pemodelan bahasa kausal dan bahasa bertopeng, serta fungsi kerugian yang digunakan dalam kasus ini. Untuk pra-pelatihan yang efisien, pelajari lebih lanjut tentang Megatron-LM atau gpt-neox.
- Hukum penskalaan : Hukum penskalaan menjelaskan performa model yang diharapkan berdasarkan ukuran model, ukuran kumpulan data, dan jumlah komputasi yang digunakan untuk pelatihan.
- Komputasi Berkinerja Tinggi : Di luar jangkauan sini, namun pengetahuan lebih lanjut tentang HPC sangat penting jika Anda berencana membuat LLM Anda sendiri dari awal (perangkat keras, beban kerja terdistribusi, dll.).
Referensi :
- LLMDataHub oleh Junhao Zhao: Daftar kumpulan data yang dikurasi untuk pra-pelatihan, penyesuaian, dan RLHF.
- Melatih model bahasa kausal dari awal dengan Hugging Face: Latih terlebih dahulu model GPT-2 dari awal menggunakan pustaka transformator.
- TinyLlama oleh Zhang et al.: Periksa proyek ini untuk mendapatkan pemahaman yang baik tentang bagaimana model Llama dilatih dari awal.
- Pemodelan bahasa kausal dengan Hugging Face: Jelaskan perbedaan antara pemodelan bahasa kausal dan bahasa terselubung serta cara menyempurnakan model DistilGPT-2 dengan cepat.
- Implikasi liar Chinchilla oleh para nostalgia: Diskusikan undang-undang penskalaan dan jelaskan apa artinya bagi LLM secara umum.
- BLOOM oleh BigScience: Halaman gagasan yang menjelaskan bagaimana model BLOOM dibangun, dengan banyak informasi berguna tentang bagian teknik dan masalah yang dihadapi.
- Buku Catatan OPT-175 oleh Meta: Catatan penelitian menunjukkan apa yang salah dan apa yang benar. Berguna jika Anda berencana untuk melakukan pra-pelatihan model bahasa yang sangat besar (dalam hal ini, parameter 175B).
- LLM 360: Kerangka kerja untuk LLM sumber terbuka dengan kode pelatihan dan persiapan data, data, metrik, dan model.
4. Penyempurnaan yang Diawasi
Model yang telah dilatih sebelumnya hanya dilatih pada tugas prediksi token berikutnya, itulah sebabnya model tersebut bukan asisten yang membantu. SFT memungkinkan Anda mengubahnya untuk merespons instruksi. Selain itu, ini memungkinkan Anda menyempurnakan model pada data apa pun (pribadi, tidak terlihat oleh GPT-4, dll.) dan menggunakannya tanpa harus membayar untuk API seperti OpenAI.
- Penyempurnaan penuh : Penyempurnaan penuh mengacu pada pelatihan semua parameter dalam model. Ini bukan teknik yang efisien, tetapi memberikan hasil yang sedikit lebih baik.
- LoRA : Teknik hemat parameter (PEFT) berdasarkan adaptor tingkat rendah. Daripada melatih semua parameter, kami hanya melatih adaptor ini.
- QLoRA : PEFT lain berdasarkan LoRA, yang juga mengkuantisasi bobot model dalam 4 bit dan memperkenalkan pengoptimal halaman untuk mengelola lonjakan memori. Gabungkan dengan Unsloth untuk menjalankannya secara efisien di notebook Colab gratis.
- Axolotl : Alat penyempurnaan yang mudah digunakan dan kuat yang digunakan di banyak model sumber terbuka canggih.
- DeepSpeed : Pra-pelatihan dan penyempurnaan LLM yang efisien untuk pengaturan multi-GPU dan multi-node (diimplementasikan di Axolotl).
Referensi :
- Panduan Pelatihan LLM Pemula oleh Alpin: Ikhtisar konsep dan parameter utama yang perlu dipertimbangkan ketika menyempurnakan LLM.
- Wawasan LoRA oleh Sebastian Raschka: Wawasan praktis tentang LoRA dan cara memilih parameter terbaik.
- Sempurnakan Model Llama 2 Anda Sendiri: Tutorial praktis tentang cara menyempurnakan model Llama 2 menggunakan pustaka Hugging Face.
- Padding Model Bahasa Besar oleh Benjamin Marie: Praktik terbaik untuk memasukkan contoh pelatihan untuk LLM kausal
- Panduan Pemula untuk Penyempurnaan LLM: Tutorial tentang cara menyempurnakan model CodeLlama menggunakan Axolotl.
5. Penyelarasan Preferensi
Setelah penyempurnaan yang diawasi, RLHF adalah langkah yang digunakan untuk menyelaraskan jawaban LLM dengan harapan manusia. Idenya adalah mempelajari preferensi dari umpan balik manusia (atau buatan), yang dapat digunakan untuk mengurangi bias, menyensor model, atau membuat mereka bertindak dengan cara yang lebih berguna. Ini lebih kompleks daripada SFT dan sering dianggap opsional.
- Kumpulan data preferensi : Kumpulan data ini biasanya berisi beberapa jawaban dengan semacam peringkat, yang membuatnya lebih sulit untuk dihasilkan dibandingkan kumpulan data instruksi.
- Pengoptimalan Kebijakan Proksimal : Algoritme ini memanfaatkan model penghargaan yang memprediksi apakah suatu teks tertentu diberi peringkat tinggi oleh manusia. Prediksi ini kemudian digunakan untuk mengoptimalkan model SFT dengan penalti berdasarkan divergensi KL.
- Optimasi Preferensi Langsung : DPO menyederhanakan proses dengan membingkai ulangnya sebagai masalah klasifikasi. Ia menggunakan model referensi, bukan model penghargaan (tidak memerlukan pelatihan) dan hanya memerlukan satu hyperparameter, sehingga lebih stabil dan efisien.
Referensi :
- Distilabel oleh Argilla : Alat luar biasa untuk membuat kumpulan data Anda sendiri. Ini dirancang khusus untuk kumpulan data preferensi tetapi juga dapat melakukan SFT.
- Pengantar Pelatihan LLM menggunakan RLHF oleh Ayush Thakur: Jelaskan mengapa RLHF diinginkan untuk mengurangi bias dan meningkatkan kinerja di LLM.
- Ilustrasi RLHF oleh Hugging Face: Pengenalan RLHF dengan pelatihan model penghargaan dan penyesuaian dengan pembelajaran penguatan.
- LLM Penyetelan Preferensi dengan Memeluk Wajah: Perbandingan algoritma DPO, IPO, dan KTO untuk melakukan penyelarasan preferensi.
- Pelatihan LLM: RLHF dan Alternatifnya oleh Sebastian Rashcka: Ikhtisar proses RLHF dan alternatif seperti RLAIF.
- Sempurnakan Mistral-7b dengan DPO: Tutorial untuk menyempurnakan model Mistral-7b dengan DPO dan mereproduksi NeuralHermes-2.5.
6. Evaluasi
Mengevaluasi LLM adalah bagian yang diremehkan, yang memakan waktu dan cukup dapat diandalkan. Tugas hilir Anda harus menentukan apa yang ingin Anda evaluasi, namun selalu ingat hukum Goodhart: "Ketika suatu ukuran menjadi target, maka itu tidak lagi menjadi ukuran yang baik."
- Metrik tradisional : Metrik seperti kebingungan dan skor BLEU tidak sepopuler sebelumnya karena memiliki kelemahan di sebagian besar konteks. Penting untuk memahaminya dan kapan bisa diterapkan.
- Tolok ukur umum : Berdasarkan Harness Evaluasi Model Bahasa, Papan Peringkat LLM Terbuka adalah tolok ukur utama untuk LLM tujuan umum (seperti ChatGPT). Ada tolok ukur populer lainnya seperti BigBench, MT-Bench, dll.
- Tolok ukur khusus tugas : Tugas seperti ringkasan, penerjemahan, dan menjawab pertanyaan memiliki tolok ukur, metrik, dan bahkan subdomain khusus (medis, keuangan, dll.), seperti PubMedQA untuk menjawab pertanyaan biomedis.
- Evaluasi manusia : Evaluasi yang paling dapat diandalkan adalah tingkat penerimaan oleh pengguna atau perbandingan yang dilakukan oleh manusia. Mencatat umpan balik pengguna selain jejak obrolan (misalnya, menggunakan LangSmith) membantu mengidentifikasi area potensial untuk perbaikan.
Referensi :
- Kebingungan model panjang tetap dengan Hugging Face: Ikhtisar kebingungan dengan kode untuk mengimplementasikannya dengan pustaka transformator.
- BLEU dengan risiko Anda sendiri oleh Rachael Tatman: Ikhtisar skor BLEU dan banyak permasalahannya beserta contohnya.
- Survei Evaluasi LLM oleh Chang dkk.: Makalah komprehensif tentang apa yang harus dievaluasi, di mana harus dievaluasi, dan bagaimana cara mengevaluasi.
- Papan Peringkat Chatbot Arena oleh lmsys: Peringkat Elo untuk LLM tujuan umum, berdasarkan perbandingan yang dibuat oleh manusia.
7. Kuantisasi
Kuantisasi adalah proses mengubah bobot (dan aktivasi) suatu model menggunakan presisi yang lebih rendah. Misalnya, bobot yang disimpan menggunakan 16 bit dapat diubah menjadi representasi 4-bit. Teknik ini menjadi semakin penting untuk mengurangi biaya komputasi dan memori yang terkait dengan LLM.
- Teknik dasar : Pelajari berbagai tingkat presisi (FP32, FP16, INT8, dll.) dan cara melakukan kuantisasi naif dengan teknik absmax dan titik nol.
- GGUF dan llama.cpp : Awalnya dirancang untuk berjalan pada CPU, llama.cpp dan format GGUF telah menjadi alat paling populer untuk menjalankan LLM pada perangkat keras tingkat konsumen.
- GPTQ dan EXL2 : GPTQ dan, lebih khusus lagi, format EXL2 menawarkan kecepatan luar biasa tetapi hanya dapat berjalan di GPU. Model juga membutuhkan waktu lama untuk dikuantisasi.
- AWQ : Format baru ini lebih akurat dibandingkan GPTQ (kebingungan lebih rendah) namun menggunakan lebih banyak VRAM dan belum tentu lebih cepat.
Referensi :
- Pengantar kuantisasi: Ikhtisar kuantisasi, kuantisasi absmax dan titik nol, dan LLM.int8() dengan kode.
- Mengkuantisasi model Llama dengan llama.cpp: Tutorial cara mengkuantisasi model Llama 2 menggunakan llama.cpp dan format GGUF.
- Kuantisasi LLM 4-bit dengan GPTQ: Tutorial cara mengkuantisasi LLM menggunakan algoritma GPTQ dengan AutoGPTQ.
- ExLlamaV2: Perpustakaan Tercepat untuk Menjalankan LLM: Panduan tentang cara mengkuantisasi model Mistral menggunakan format EXL2 dan menjalankannya dengan perpustakaan ExLlamaV2.
- Memahami Kuantisasi Berat Sadar Aktivasi oleh FriendliAI: Ikhtisar teknik AWQ dan manfaatnya.
8. Tren Baru
- Penyematan posisi : Pelajari cara LLM mengkodekan posisi, terutama skema pengkodean posisi relatif seperti RoPE. Terapkan YaRN (mengalikan matriks perhatian dengan faktor suhu) atau ALiBi (penalti perhatian berdasarkan jarak token) untuk memperluas panjang konteks.
- Penggabungan model : Menggabungkan model terlatih telah menjadi cara populer untuk menciptakan model berperforma tinggi tanpa penyesuaian apa pun. Pustaka mergekit yang populer mengimplementasikan metode penggabungan paling populer, seperti SLERP, DARE, dan TIES.
- Campuran Pakar : Mixtral mempopulerkan kembali arsitektur MoE berkat kinerjanya yang luar biasa. Secara paralel, jenis frankenMoE muncul di komunitas OSS dengan menggabungkan model seperti Phixtral, yang merupakan opsi yang lebih murah dan berkinerja baik.
- Model multimodal : Model ini (seperti CLIP, Stable Diffusion, atau LLaVA) memproses beberapa jenis input (teks, gambar, audio, dll.) dengan ruang penyematan terpadu, yang membuka aplikasi canggih seperti teks-ke-gambar.
Referensi :
- Memperluas RoPE oleh EleutherAI: Artikel yang merangkum berbagai teknik pengkodean posisi.
- Memahami YaRN oleh Rajat Chawla: Pengantar YaRN.
- Gabungkan LLM dengan mergekit: Tutorial tentang penggabungan model menggunakan mergekit.
- Penjelasan Campuran Pakar dengan Memeluk Wajah: Panduan lengkap tentang MoE dan cara kerjanya.
- Model Multimodal Besar oleh Chip Huyen: Tinjauan sistem multimodal dan sejarah terkini bidang ini.
? Insinyur LLM
Bagian kursus ini berfokus pada mempelajari cara membangun aplikasi yang didukung LLM yang dapat digunakan dalam produksi, dengan fokus pada penambahan model dan penerapannya.
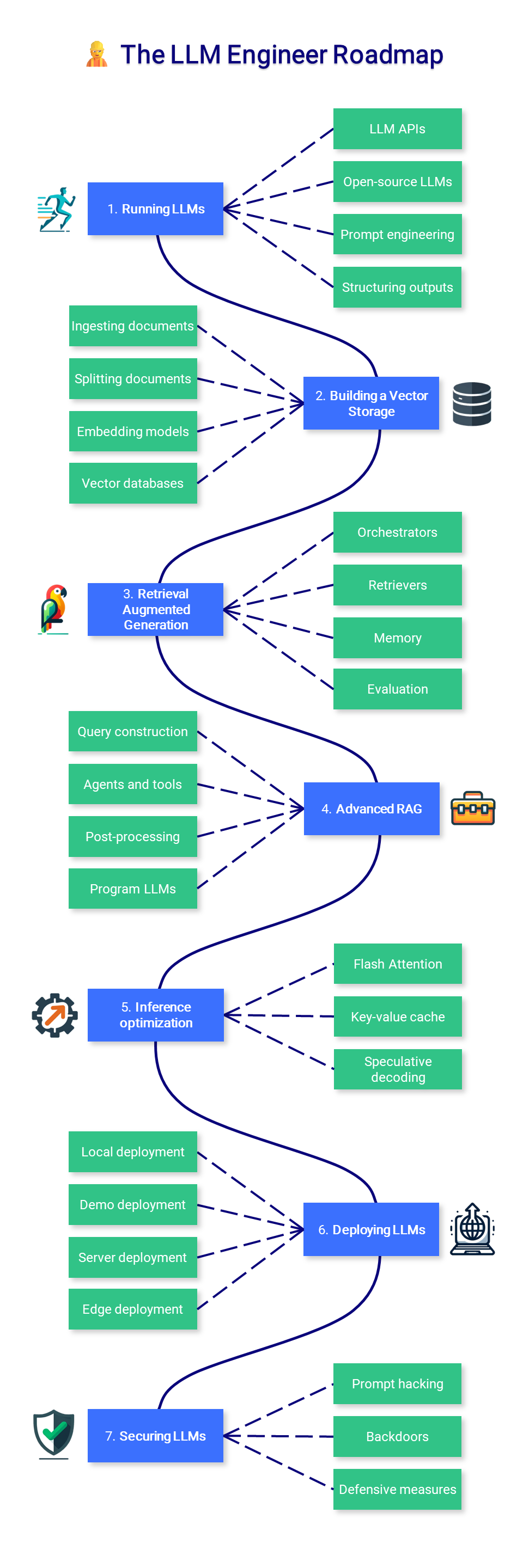
1. Menjalankan LLM
Menjalankan LLM bisa jadi sulit karena persyaratan perangkat keras yang tinggi. Bergantung pada kasus penggunaan Anda, Anda mungkin ingin menggunakan model melalui API (seperti GPT-4) atau menjalankannya secara lokal. Bagaimanapun, teknik dorongan dan panduan tambahan dapat meningkatkan dan membatasi keluaran aplikasi Anda.
- LLM API : API adalah cara mudah untuk menyebarkan LLM. Ruang ini dibagi antara LLM swasta (OpenAI, Google, Anthropic, Cohere, dll.) dan LLM sumber terbuka (OpenRouter, Hugging Face, Together AI, dll.).
- LLM sumber terbuka : Hugging Face Hub adalah tempat yang bagus untuk menemukan LLM. Anda dapat langsung menjalankan beberapa di antaranya di Hugging Face Spaces, atau mengunduh dan menjalankannya secara lokal di aplikasi seperti LM Studio atau melalui CLI dengan llama.cpp atau Ollama.
- Rekayasa cepat : Teknik umum mencakup dorongan zero-shot, dorongan beberapa tembakan, rantai pemikiran, dan ReAct. Mereka bekerja lebih baik dengan model yang lebih besar, namun dapat disesuaikan dengan model yang lebih kecil.
- Menyusun keluaran : Banyak tugas memerlukan keluaran terstruktur, seperti templat ketat atau format JSON. Perpustakaan seperti LMQL, Garis Besar, Panduan, dll. dapat digunakan untuk memandu pembuatan dan menghormati struktur tertentu.
Referensi :
- Jalankan LLM secara lokal dengan LM Studio oleh Nisha Arya: Panduan singkat tentang cara menggunakan LM Studio.
- Panduan teknik cepat oleh DAIR.AI: Daftar lengkap teknik cepat beserta contohnya
- Garis Besar - Mulai Cepat: Daftar teknik pembuatan terpandu yang diaktifkan oleh Garis Besar.
- LMQL - Ikhtisar: Pengantar bahasa LMQL.
2. Membangun Penyimpanan Vektor
Membuat penyimpanan vektor adalah langkah pertama untuk membangun alur Retrieval Augmented Generation (RAG). Dokumen dimuat, dipecah, dan potongan yang relevan digunakan untuk menghasilkan representasi vektor (embeddings) yang disimpan untuk digunakan di masa mendatang selama inferensi.
- Menyerap dokumen : Pemuat dokumen adalah pembungkus praktis yang dapat menangani banyak format: PDF, JSON, HTML, Markdown, dll. Mereka juga dapat langsung mengambil data dari beberapa database dan API (GitHub, Reddit, Google Drive, dll.).
- Memisahkan dokumen : Pemisah teks memecah dokumen menjadi bagian-bagian yang lebih kecil dan bermakna secara semantik. Daripada memisahkan teks setelah n karakter, lebih baik memisahkannya berdasarkan header atau secara rekursif, dengan beberapa metadata tambahan.
- Model penyematan : Model penyematan mengubah teks menjadi representasi vektor. Hal ini memungkinkan pemahaman bahasa yang lebih dalam dan lebih bernuansa, yang penting untuk melakukan pencarian semantik.
- Basis data vektor : Basis data vektor (seperti Chroma, Pinecone, Milvus, FAISS, Annoy, dll.) dirancang untuk menyimpan vektor yang disematkan. Mereka memungkinkan pengambilan data yang 'paling mirip' secara efisien dengan kueri berdasarkan kesamaan vektor.
Referensi :
- LangChain - Pemisah teks: Daftar pemisah teks berbeda yang diterapkan di LangChain.
- Pustaka Kalimat Transformers: Pustaka populer untuk menyematkan model.
- Papan Peringkat MTEB: Papan Peringkat untuk menyematkan model.
- 5 Database Vektor Teratas oleh Moez Ali: Perbandingan database vektor terbaik dan terpopuler.
3. Pengambilan Generasi Augmented
Dengan RAG, LLM mengambil dokumen kontekstual dari database untuk meningkatkan keakuratan jawaban mereka. RAG adalah cara populer untuk menambah pengetahuan model tanpa penyesuaian apa pun.
- Orchestrator : Orchestrator (seperti LangChain, LlamaIndex, FastRAG, dll.) adalah kerangka kerja populer untuk menghubungkan LLM Anda dengan alat, database, memori, dll. dan meningkatkan kemampuannya.
- Retriever : Instruksi pengguna tidak dioptimalkan untuk pengambilan. Teknik yang berbeda (misalnya, multi-query retriever, HyDE, dll.) dapat diterapkan untuk menyusun ulang/memperluasnya dan meningkatkan kinerja.
- Memori : Untuk mengingat instruksi dan jawaban sebelumnya, LLM dan chatbot seperti ChatGPT menambahkan riwayat ini ke jendela konteksnya. Buffer ini dapat ditingkatkan dengan peringkasan (misalnya menggunakan LLM yang lebih kecil), penyimpanan vektor + RAG, dll.
- Evaluasi : Kita perlu mengevaluasi tahap pengambilan dokumen (ketepatan konteks dan penarikan kembali) dan tahap pembuatan (kesetiaan dan relevansi jawaban). Ini dapat disederhanakan dengan alat Ragas dan DeepEval.
Referensi :
- Llamaindex - Konsep tingkat tinggi: Konsep utama yang perlu diketahui saat membangun jaringan pipa RAG.
- Biji Pinus - Augmentasi Pengambilan: Ikhtisar proses augmentasi pengambilan.
- LangChain - Tanya Jawab dengan RAG: Tutorial langkah demi langkah untuk membangun pipeline RAG pada umumnya.
- LangChain - Jenis memori: Daftar berbagai jenis memori dengan penggunaan yang relevan.
- Pipeline RAG - Metrik: Ikhtisar metrik utama yang digunakan untuk mengevaluasi pipeline RAG.
4. RAG tingkat lanjut
Aplikasi kehidupan nyata mungkin memerlukan pipeline yang kompleks, termasuk database SQL atau grafik, serta pemilihan alat dan API yang relevan secara otomatis. Teknik-teknik canggih ini dapat meningkatkan solusi dasar dan menyediakan fitur tambahan.
- Konstruksi kueri : Data terstruktur yang disimpan dalam database tradisional memerlukan bahasa kueri tertentu seperti SQL, Cypher, metadata, dll. Kita dapat langsung menerjemahkan instruksi pengguna ke dalam kueri untuk mengakses data dengan konstruksi kueri.
- Agen dan alat : Agen menambah LLM dengan secara otomatis memilih alat yang paling relevan untuk memberikan jawaban. Alat-alat ini bisa sesederhana menggunakan Google atau Wikipedia, atau lebih rumit seperti penerjemah Python atau Jira.
- Pasca-pemrosesan : Langkah terakhir yang memproses masukan yang diumpankan ke LLM. Hal ini meningkatkan relevansi dan keragaman dokumen yang diambil dengan pemeringkatan ulang, penggabungan RAG, dan klasifikasi.
- Program LLM : Kerangka kerja seperti DSPy memungkinkan Anda mengoptimalkan perintah dan bobot berdasarkan evaluasi otomatis dengan cara terprogram.
Referensi :
- LangChain - Konstruksi Kueri: Postingan blog tentang berbagai jenis konstruksi kueri.
- LangChain - SQL: Tutorial tentang cara berinteraksi dengan database SQL dengan LLM, yang melibatkan Text-to-SQL dan agen SQL opsional.
- Pinecone - Agen LLM: Pengenalan agen dan alat dengan berbagai jenis.
- Agen Otonom yang Didukung LLM oleh Lilian Weng: Artikel yang lebih teoretis tentang agen LLM.
- LangChain - RAG OpenAI: Ikhtisar strategi RAG yang digunakan oleh OpenAI, termasuk pasca-pemrosesan.
- DSPy dalam 8 Langkah: Panduan tujuan umum untuk DSPy yang memperkenalkan modul, tanda tangan, dan pengoptimal.
5. Optimasi inferensi
Pembuatan teks adalah proses mahal yang memerlukan perangkat keras mahal. Selain kuantisasi, berbagai teknik telah diusulkan untuk memaksimalkan throughput dan mengurangi biaya inferensi.
- Flash Attention : Optimalisasi mekanisme perhatian untuk mengubah kompleksitasnya dari kuadrat menjadi linier, mempercepat pelatihan dan inferensi.
- Cache nilai kunci : Memahami cache nilai kunci dan peningkatan yang diperkenalkan di Multi-Query Attention (MQA) dan Grouped-Query Attention (GQA).
- Penguraian kode spekulatif : Gunakan model kecil untuk menghasilkan draf yang kemudian ditinjau oleh model yang lebih besar untuk mempercepat pembuatan teks.
Referensi :
- Inferensi GPU dengan Memeluk Wajah: Jelaskan cara mengoptimalkan inferensi pada GPU.
- Inferensi LLM oleh Databricks: Praktik terbaik tentang cara mengoptimalkan inferensi LLM dalam produksi.
- Mengoptimalkan LLM untuk Kecepatan dan Memori dengan Memeluk Wajah: Jelaskan tiga teknik utama untuk mengoptimalkan kecepatan dan memori, yaitu kuantisasi, Flash Attention, dan inovasi arsitektur.
- Assisted Generation by Hugging Face: Decoding spekulatif versi HF, ini adalah postingan blog yang menarik tentang cara kerjanya dengan kode untuk mengimplementasikannya.
6. Menyebarkan LLM
Menerapkan LLM dalam skala besar adalah suatu prestasi teknis yang memerlukan banyak cluster GPU. Dalam skenario lain, demo dan aplikasi lokal dapat dicapai dengan kompleksitas yang jauh lebih rendah.
- Penerapan lokal : Privasi adalah keunggulan penting yang dimiliki LLM sumber terbuka dibandingkan LLM pribadi. Server LLM lokal (LM Studio, Ollama, oobabooga, kobold.cpp, dll.) memanfaatkan keunggulan ini untuk mendukung aplikasi lokal.
- Penerapan demo : Kerangka kerja seperti Gradio dan Streamlit berguna untuk membuat prototipe aplikasi dan berbagi demo. Anda juga dapat dengan mudah meng -host mereka secara online, misalnya menggunakan ruang wajah memeluk.
- Penyebaran Server : Menyebarkan LLMS pada skala membutuhkan cloud (lihat juga SkyPilot) atau infrastruktur on-prem dan seringkali memanfaatkan kerangka kerja pembuatan teks yang dioptimalkan seperti TGI, VLLM, dll.
- Penyebaran tepi : Dalam lingkungan yang terbatas, kerangka kerja berkinerja tinggi seperti MLC LLM dan MNN-LLM dapat menggunakan LLM di browser web, Android, dan iOS.
Referensi :
- StreamLit - Bangun Aplikasi LLM Dasar: Tutorial untuk membuat aplikasi seperti chatgpt dasar menggunakan streamlit.
- HF LLM Container Inferensi: Menyebarkan LLMS di Amazon Sagemaker menggunakan wadah inferensi Face.
- Blog Philschmid oleh Philipp Schmid: Koleksi artikel berkualitas tinggi tentang penyebaran LLM menggunakan Amazon Sagemaker.
- Mengoptimalkan latensi oleh Hamel Husain: Perbandingan TGI, VLLM, Ctranslate2, dan MLC dalam hal throughput dan latensi.
7. Mengamankan LLMS
Selain masalah keamanan tradisional yang terkait dengan perangkat lunak, LLM memiliki kelemahan unik karena cara mereka dilatih dan diminta.
- Peretasan Prompt : Teknik yang berbeda terkait dengan rekayasa cepat, termasuk injeksi prompt (instruksi tambahan untuk membajak jawaban model), data/bocor prompt (ambil data/prompt aslinya), dan jailbreak (craft meminta untuk mem -bypass fitur keselamatan).
- Backdoors : Vektor serangan dapat menargetkan data pelatihan itu sendiri, dengan meracuni data pelatihan (misalnya, dengan informasi palsu) atau membuat pintu belakang (pemicu rahasia untuk mengubah perilaku model selama inferensi).
- Langkah -langkah defensif : Cara terbaik untuk melindungi aplikasi LLM Anda adalah menguji mereka terhadap kerentanan ini (misalnya, menggunakan tim merah dan cek seperti garak) dan mengamati mereka dalam produksi (dengan kerangka kerja seperti Langfuse).
Referensi :
- OWASP LLM Top 10 oleh Hego Wiki: Daftar 10 kerentanan paling kritik yang terlihat dalam aplikasi LLM.
- Primer injeksi cepat oleh Joseph Thacker: Panduan pendek yang didedikasikan untuk injeksi cepat untuk insinyur.
- Keamanan LLM oleh @LLM_SEC: Daftar sumber daya yang luas yang terkait dengan keamanan LLM.
- Red Teaming LLMS oleh Microsoft: Panduan tentang Cara Melakukan Tim Merah dengan LLMS.
Ucapan Terima Kasih
Peta jalan ini terinspirasi oleh peta jalan Devops yang sangat baik dari Milan Milanović dan Romano Roth.
Terima kasih khusus kepada:
- Thomas Thelen karena memotivasi saya untuk membuat peta jalan
- André Frade atas masukan dan ulasannya tentang draft pertama
- Dino Dunn untuk menyediakan sumber daya tentang keamanan LLM
- Magdalena Kuhn untuk meningkatkan bagian "evaluasi manusia"
- Odoverdose untuk menyarankan video 3blue1brown tentang Transformers
Penafian: Saya tidak berafiliasi dengan sumber apa pun yang tercantum di sini.


