Repositori ini berisi kode PyTorch untuk Motif, yang melatih agen AI di NetHack dengan fungsi hadiah yang berasal dari preferensi LLM.
Motif: Motivasi Intrinsik dari Umpan Balik Kecerdasan Buatan
oleh Martin Klissarov* & Pierluca D'Oro*, Shagun Sodhani, Roberta Raileanu, Pierre-Luc Bacon, Pascal Vincent, Amy Zhang dan Mikael Henaff
Motif memunculkan preferensi Model Bahasa Besar (LLM) pada pasangan observasi yang diberi teks dari kumpulan data interaksi yang dikumpulkan di NetHack. Secara otomatis, ini menyaring akal sehat LLM menjadi fungsi penghargaan yang digunakan untuk melatih agen dengan pembelajaran penguatan.
Untuk memfasilitasi perbandingan, kami menyediakan kurva pelatihan dalam file acar motif_results.pkl , yang berisi kamus dengan tugas sebagai kuncinya. Untuk setiap tugas, kami menyediakan daftar langkah waktu dan pengembalian rata-rata untuk Motif dan garis dasar, untuk beberapa benih.
Seperti yang diilustrasikan pada gambar berikut, Motif menampilkan tiga fase:
Kami merinci setiap fase dengan menyediakan kumpulan data, perintah, dan hasil mentah yang diperlukan untuk mereproduksi eksperimen di makalah.
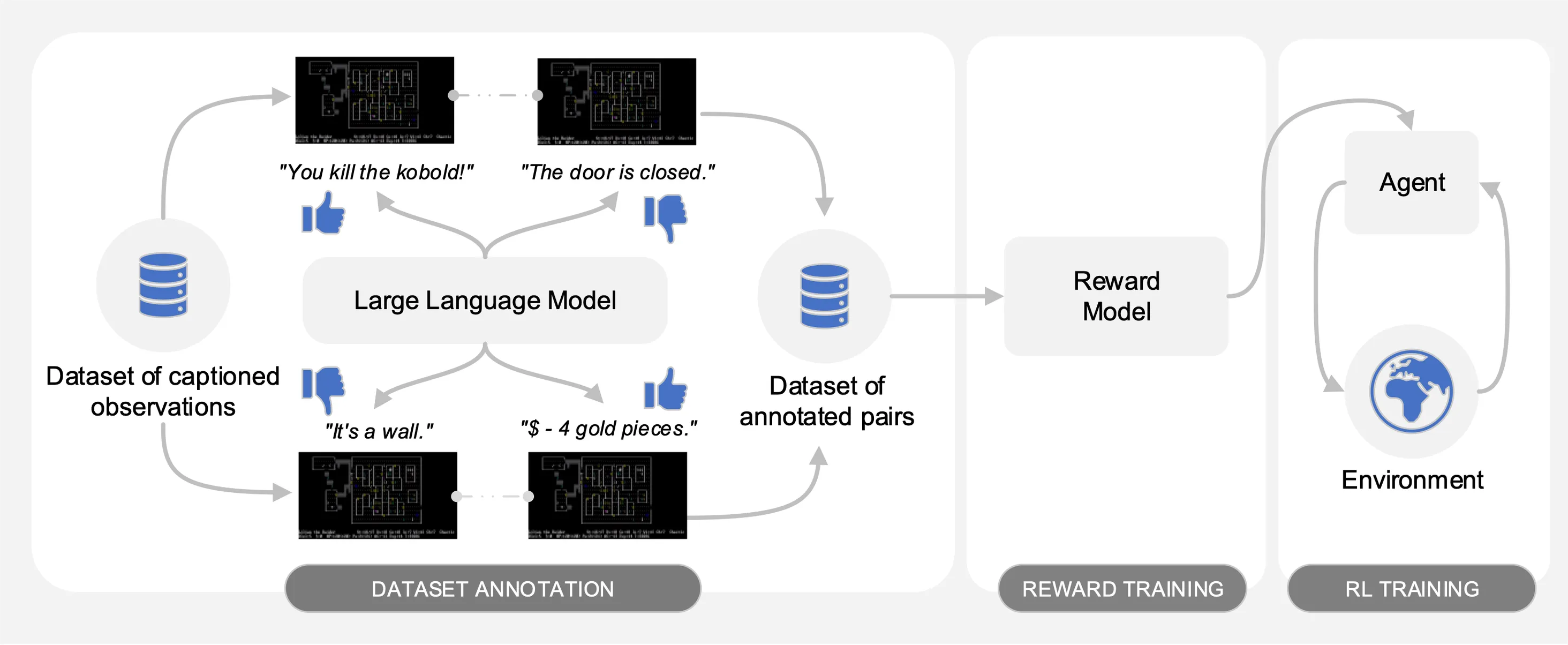
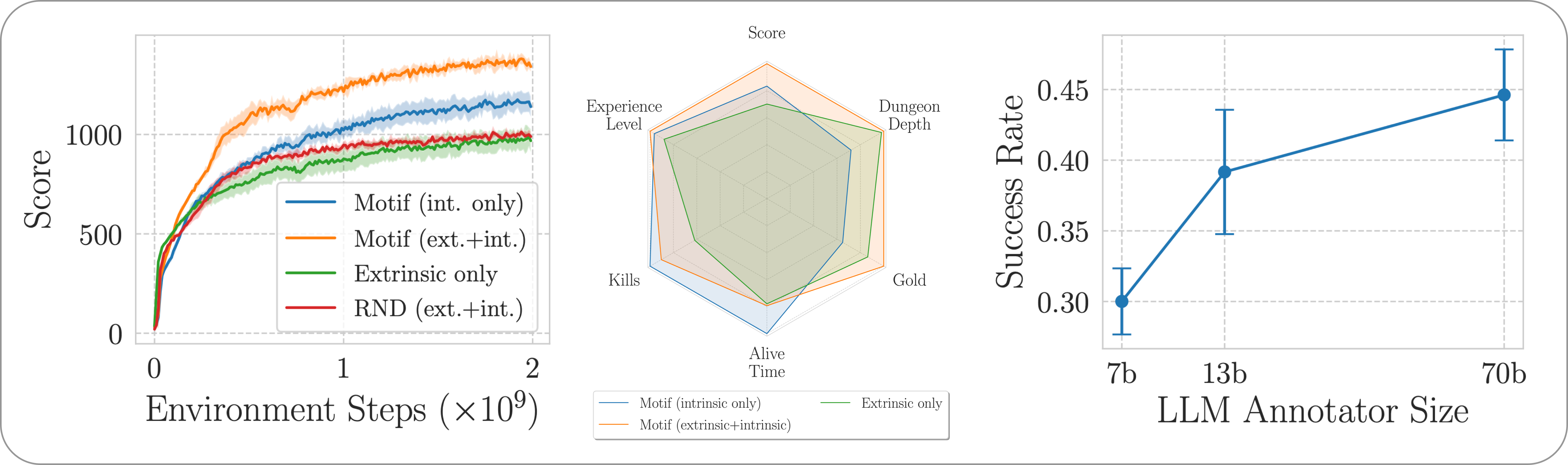
Kami mengevaluasi kinerja Motif pada game NetHack yang menantang, terbuka, dan dihasilkan secara prosedural melalui Lingkungan Pembelajaran NetHack. Kami menyelidiki bagaimana Motif sebagian besar menghasilkan perilaku intuitif yang selaras dengan manusia, yang dapat dikendalikan dengan mudah melalui modifikasi cepat, serta properti penskalaannya.

Untuk menginstal dependensi yang diperlukan untuk keseluruhan pipeline, cukup jalankan pip install -r requirements.txt .
Untuk fase pertama, kami menggunakan kumpulan data observasi berpasangan dengan keterangan (yaitu, pesan dari game) yang dikumpulkan oleh agen yang dilatih dengan pembelajaran penguatan untuk memaksimalkan skor game. Kami menyediakan dataset di repositori ini. Kami menyimpan bagian-bagian yang berbeda ke dalam direktori motif_dataset_zipped , yang dapat dibuka ritsletingnya menggunakan perintah berikut.
cat motif_dataset_zipped/motif_dataset_part_* > motif_dataset.zip; unzip motif_dataset.zip; rm motif_dataset.zip
Kumpulan data yang kami sediakan menampilkan serangkaian preferensi yang diberikan oleh model Llama 2, yang terdapat dalam direktori preference/ , menggunakan petunjuk berbeda yang dijelaskan di makalah. Nama file .npy yang berisi anotasi mengikuti templat llama{size}b_msg_{instruction}_{version} , dengan size adalah ukuran LLM dari himpunan {7,13,70} , instruction adalah instruksi yang diperkenalkan ke prompt yang diberikan ke LLM dari set {defaultgoal, zeroknowledge, combat, gold, stairs} , version adalah versi template prompt yang akan digunakan dari set {default, reworded} . Di sini kami memberikan ringkasan anotasi yang tersedia:
| Anotasi | Kasus penggunaan dari kertas |
|---|---|
llama70b_msg_defaultgoal_default | Eksperimen utama |
llama70b_msg_combat_default | Mengarah ke perilaku The Monster Slayer |
llama70b_msg_gold_default | Mengarahkan perilaku Pengumpul Emas |
llama70b_msg_stairs_default | Mengarah ke arah perilaku The Descender |
llama7b_msg_defaultgoal_default | Eksperimen penskalaan |
llama13b_msg_defaultgoal_default | Eksperimen penskalaan |
llama70b_msg_zeroknowledge_default | Eksperimen cepat tanpa pengetahuan |
llama70b_msg_defaultgoal_reworded | Eksperimen penulisan ulang yang cepat |
Untuk membuat anotasi, kami menggunakan vLLM dan versi obrolan Llama 2. jika Anda ingin membuat anotasi sendiri dengan Llama 2 atau mereproduksi proses anotasi kami, pastikan untuk dapat mengunduh model dengan mengikuti instruksi resmi (bisa memerlukan waktu beberapa hari untuk mendapatkan akses ke bobot model).
Skrip anotasi mengasumsikan kumpulan data akan dianotasi dalam potongan berbeda menggunakan argumen n-annotation-chunks . Hal ini memungkinkan proses yang dapat diparalelkan bergantung pada ketersediaan sumber daya, dan kuat untuk dimulai ulang/preemption. Untuk menjalankan dengan satu potongan (yaitu, untuk memproses seluruh kumpulan data), dan membuat anotasi dengan templat prompt default dan spesifikasi tugas, jalankan perintah berikut.
python -m scripts.annotate_pairs_dataset --directory motif_dataset
--prompt-version default --goal-key defaultgoal
--n-annotation-chunks 1 --chunk-number 0
--llm-size 70 --num-gpus 8
Perhatikan bahwa perilaku default melanjutkan proses anotasi dengan menambahkan anotasi ke file yang menentukan konfigurasi, kecuali jika ditunjukkan lain dengan tanda --ignore-existing . Nama file '.npy' yang dibuat untuk anotasi juga dapat dipilih secara manual dengan menggunakan flag --custom-annotator-string . Dimungkinkan untuk membuat anotasi menggunakan --llm-size 7 dan --llm-size 13 menggunakan satu GPU dengan memori 32GB. Anda dapat membuat anotasi menggunakan --llm-size 70 dengan node 8-GPU. Di sini kami memberikan perkiraan kasar waktu anotasi dengan GPU NVIDIA V100s 32G, untuk kumpulan data 100 ribu pasangan, yang secara kasar seharusnya dapat mereproduksi sebagian besar hasil kami (yang diperoleh dengan 500 ribu pasangan).
| Model | Sumber daya untuk diberi anotasi |
|---|---|
| Lama 2 7b | ~32 jam GPU |
| Lama 2 13b | ~40 jam GPU |
| Lama 2 70b | ~72 jam GPU |
Pada fase kedua, kami menyaring preferensi LLM menjadi fungsi penghargaan melalui entropi silang. Untuk meluncurkan pelatihan reward dengan hyperparameter default, gunakan perintah berikut.
python -m scripts.train_reward --batch_size 1024 --num_workers 40
--reward_lr 1e-5 --num_epochs 10 --seed 777
--dataset_dir motif_dataset --annotator llama70b_msg_defaultgoal_default
--experiment standard_reward --train_dir train_dir/reward_saving_dir
Fungsi reward akan dilatih melalui anotasi annotator yang terletak di --dataset_dir . Fungsi yang dihasilkan kemudian akan disimpan di train_dir di bawah subfolder --experiment .
Terakhir, kami melatih agen dengan fungsi penghargaan yang dihasilkan melalui pembelajaran penguatan. Untuk melatih agen pada tugas NetHackScore-v1 , dengan hyperparameter default yang digunakan untuk eksperimen yang menggabungkan imbalan intrinsik dan ekstrinsik, Anda dapat menggunakan perintah berikut.
python -m scripts.main --algo APPO --env nle_fixed_eat_action --num_workers 24
--num_envs_per_worker 20 --batch_size 4096 --reward_scale 0.1 --obs_scale 255.0
--train_for_env_steps 2_000_000_000 --save_every_steps 10_000_000
--keep_checkpoints 5 --stats_avg 1000 --seed 777 --reward_dir train_dir/reward_saving_dir/standard_reward/
--experiment standard_motif --train_dir train_dir/rl_saving_dir
--extrinsic_reward 0.1 --llm_reward 0.1 --reward_encoder nle_torchbeast_encoder
--root_env NetHackScore-v1 --beta_count_exponent 3 --eps_threshold_quantile 0.5
Untuk mengubah tugas, cukup ubah argumen --root_env . Tabel berikut secara eksplisit menyatakan nilai yang diperlukan agar sesuai dengan eksperimen yang disajikan di makalah. Tugas NetHackScore-v1 dipelajari dengan nilai extrinsic_reward menjadi 0.1 , sementara semua tugas lainnya mengambil nilai 10.0 , untuk memberi insentif kepada agen untuk mencapai tujuan.
| Lingkungan | root_env |
|---|---|
| skor | NetHackScore-v1 |
| tangga | NetHackStaircase-v1 |
| tangga (tingkat 3) | NetHackStaircaseLvl3-v1 |
| tangga (tingkat 4) | NetHackStaircaseLvl4-v1 |
| peramal | NetHackOracle-v1 |
| oracle-sadar | NetHackOracleSober-v1 |
Selain itu, jika Anda ingin melatih agen hanya menggunakan imbalan intrinsik yang berasal dari LLM namun tidak ada imbalan dari lingkungan, cukup setel --extrinsic_reward 0.0 . Dalam eksperimen intrinsik khusus hadiah, kami menghentikan episode hanya jika agen mati, bukan saat agen mencapai tujuan. Lingkungan yang dimodifikasi ini disebutkan dalam tabel berikut.
| Lingkungan | root_env |
|---|---|
| tangga (tingkat 3) - hanya intrinsik | NetHackStaircaseLvl3Continual-v1 |
| tangga (tingkat 4) - hanya intrinsik | NetHackStaircaseLvl4Continual-v1 |
Kami juga menyediakan skrip untuk memvisualisasikan agen RL terlatih Anda. Hal ini dapat memberikan wawasan penting tentang perilakunya, namun juga akan menghasilkan pesan teratas untuk setiap episode, yang dapat membantu memahami apa yang coba dioptimalkan. Anda hanya perlu menjalankan perintah berikut.
python -m scripts.visualize --train_dir train_dir/rl_saving_dir --experiment standard_motif
Jika Anda mengembangkan karya kami atau merasa bermanfaat, silakan kutip menggunakan bibtex berikut.
@article{klissarovdoro2023motif,
title={Motif: Intrinsic Motivation From Artificial Intelligence Feedback},
author={Klissarov, Martin and D’Oro, Pierluca and Sodhani, Shagun and Raileanu, Roberta and Bacon, Pierre-Luc and Vincent, Pascal and Zhang, Amy and Henaff, Mikael},
year={2023},
month={9},
journal={arXiv preprint arXiv:2310.00166}
}
Mayoritas Motif dilisensikan di bawah CC-BY-NC, namun sebagian proyek tersedia di bawah persyaratan lisensi terpisah: pabrik sampel dilisensikan di bawah lisensi MIT.


