

MPIRE , kependekan dari MultiProcessing Is Real Easy, adalah paket Python untuk multiprosesor. MPIRE lebih cepat di sebagian besar skenario, mengemas lebih banyak fitur, dan umumnya lebih ramah pengguna dibandingkan paket multiprosesor default. Ini menggabungkan peta yang mudah digunakan seperti fungsi multiprocessing.Pool dengan manfaat menggunakan objek bersama multiprocessing.Process copy-on-write, bersama dengan status pekerja yang mudah digunakan, wawasan pekerja, fungsi init dan exit pekerja, batas waktu, dan fungsionalitas bilah kemajuan.
Dokumentasi lengkap tersedia di https://sybrenjansen.github.io/mpire/.
map / map_unordered / imap / imap_unordered / apply / apply_asyncfork )rich dan notebook didukung)daemonMPIRE diuji di Linux, macOS, dan Windows. Untuk pengguna Windows dan macOS, ada beberapa peringatan kecil yang diketahui, yang didokumentasikan dalam bab Pemecahan Masalah.
Melalui pip (PyPi):
pip install mpireMPIRE juga tersedia melalui conda-forge:
conda install -c conda-forge mpire Misalkan Anda memiliki fungsi yang memakan waktu yang menerima beberapa masukan dan mengembalikan hasilnya. Fungsi sederhana seperti ini dikenal sebagai masalah paralel yang memalukan, yaitu fungsi yang memerlukan sedikit atau tanpa usaha untuk mengubahnya menjadi tugas paralel. Memparalelkan fungsi sederhana semudah mengimpor multiprocessing dan menggunakan kelas multiprocessing.Pool :
import time
from multiprocessing import Pool
def time_consuming_function ( x ):
time . sleep ( 1 ) # Simulate that this function takes long to complete
return ...
with Pool ( processes = 5 ) as pool :
results = pool . map ( time_consuming_function , range ( 10 )) MPIRE dapat digunakan hampir sebagai pengganti multiprocessing . Kami menggunakan kelas mpire.WorkerPool dan memanggil salah satu fungsi map yang tersedia:
from mpire import WorkerPool
with WorkerPool ( n_jobs = 5 ) as pool :
results = pool . map ( time_consuming_function , range ( 10 )) Perbedaan dalam kodenya kecil: tidak perlu mempelajari sintaksis multiprosesor yang benar-benar baru, jika Anda terbiasa dengan vanilla multiprocessing . Namun, fungsionalitas tambahan yang tersedia inilah yang membedakan MPIRE.
Misalkan kita ingin mengetahui status tugas saat ini: berapa banyak tugas yang diselesaikan, berapa lama sebelum pekerjaan siap? Ini semudah mengatur parameter progress_bar ke True :
with WorkerPool ( n_jobs = 5 ) as pool :
results = pool . map ( time_consuming_function , range ( 10 ), progress_bar = True )Dan itu akan menampilkan bilah kemajuan tqdm yang diformat dengan baik.
MPIRE juga menawarkan dasbor, yang mana Anda perlu menginstal dependensi tambahan. Lihat Dasbor untuk informasi lebih lanjut.
Catatan: Objek bersama copy-on-write hanya tersedia untuk metode awal fork . Untuk threading objek dibagikan apa adanya. Untuk metode awal lainnya, objek yang dibagikan disalin satu kali untuk setiap pekerja, yang masih bisa lebih baik daripada satu kali per tugas.
Jika Anda memiliki satu atau lebih objek yang ingin Anda bagikan di antara semua pekerja, Anda dapat menggunakan opsi copy-on-write shared_objects dari MPIRE. MPIRE akan meneruskan objek ini hanya satu kali untuk setiap pekerja tanpa penyalinan/serialisasi. Hanya ketika Anda mengubah objek dalam fungsi pekerja, objek tersebut akan mulai disalin untuk pekerja tersebut.
def time_consuming_function ( some_object , x ):
time . sleep ( 1 ) # Simulate that this function takes long to complete
return ...
def main ():
some_object = ...
with WorkerPool ( n_jobs = 5 , shared_objects = some_object ) as pool :
results = pool . map ( time_consuming_function , range ( 10 ), progress_bar = True )Lihat shared_objects untuk detail selengkapnya.
Pekerja dapat diinisialisasi menggunakan fitur worker_init . Bersama worker_state Anda dapat memuat model, atau mengatur koneksi database, dll.:
def init ( worker_state ):
# Load a big dataset or model and store it in a worker specific worker_state
worker_state [ 'dataset' ] = ...
worker_state [ 'model' ] = ...
def task ( worker_state , idx ):
# Let the model predict a specific instance of the dataset
return worker_state [ 'model' ]. predict ( worker_state [ 'dataset' ][ idx ])
with WorkerPool ( n_jobs = 5 , use_worker_state = True ) as pool :
results = pool . map ( task , range ( 10 ), worker_init = init ) Demikian pula, Anda dapat menggunakan worker_exit untuk membiarkan MPIRE memanggil fungsi setiap kali pekerja dihentikan. Anda bahkan dapat membiarkan fungsi keluar ini memberikan hasil, yang dapat diperoleh nanti. Lihat bagian pekerja_init dan pekerja_keluar untuk informasi lebih lanjut.
Ketika pengaturan multiprosesor Anda tidak berfungsi seperti yang Anda inginkan dan Anda tidak tahu apa penyebabnya, ada fungsi wawasan pekerja. Ini akan memberi Anda wawasan tentang pengaturan Anda, tetapi tidak akan memprofilkan fungsi yang Anda jalankan (ada perpustakaan lain untuk itu). Sebaliknya, ini memprofilkan waktu mulai pekerja, waktu tunggu dan waktu kerja. Ketika fungsi init dan exit pekerja disediakan, maka akan mengatur waktunya juga.
Mungkin Anda mengirimkan banyak data melalui antrean tugas, yang membuat waktu tunggu bertambah. Apa pun masalahnya, Anda dapat mengaktifkan dan mengambil wawasan masing-masing menggunakan tanda enable_insights dan fungsi mpire.WorkerPool.get_insights :
with WorkerPool ( n_jobs = 5 , enable_insights = True ) as pool :
results = pool . map ( time_consuming_function , range ( 10 ))
insights = pool . get_insights ()Lihat wawasan pekerja untuk contoh yang lebih detail dan hasil yang diharapkan.
Batas waktu dapat diatur secara terpisah untuk fungsi target, worker_init , worker_exit . Ketika batas waktu telah ditetapkan dan tercapai, TimeoutError akan muncul:
def init ():
...
def exit_ ():
...
# Will raise TimeoutError, provided that the target function takes longer
# than half a second to complete
with WorkerPool ( n_jobs = 5 ) as pool :
pool . map ( time_consuming_function , range ( 10 ), task_timeout = 0.5 )
# Will raise TimeoutError, provided that the worker_init function takes longer
# than 3 seconds to complete or the worker_exit function takes longer than
# 150.5 seconds to complete
with WorkerPool ( n_jobs = 5 ) as pool :
pool . map ( time_consuming_function , range ( 10 ), worker_init = init , worker_exit = exit_ ,
worker_init_timeout = 3.0 , worker_exit_timeout = 150.5 ) Saat menggunakan threading sebagai metode awal MPIRE tidak akan dapat mengganggu fungsi tertentu, seperti time.sleep .
Lihat batas waktu untuk detail selengkapnya.
MPIRE telah diukur pada tiga tolok ukur berbeda: komputasi numerik, komputasi stateful, dan inisialisasi yang mahal. Detail selengkapnya tentang tolok ukur ini dapat ditemukan di postingan blog ini. Semua kode untuk tolok ukur ini dapat ditemukan di proyek ini.
Singkatnya, alasan utama mengapa MPIRE lebih cepat adalah:
fork tersedia, kita dapat menggunakan objek bersama copy-on-write, yang mengurangi kebutuhan untuk menyalin objek yang perlu dibagikan melalui proses anakGrafik berikut menunjukkan hasil rata-rata yang dinormalisasi dari ketiga tolok ukur. Hasil untuk tolok ukur individual dapat ditemukan di postingan blog. Benchmark dijalankan pada mesin Linux dengan 20 core, dengan hyperthreading dinonaktifkan dan RAM 200GB. Untuk setiap tugas, eksperimen dijalankan dengan jumlah proses/pekerja yang berbeda dan hasilnya dirata-ratakan selama 5 kali proses.
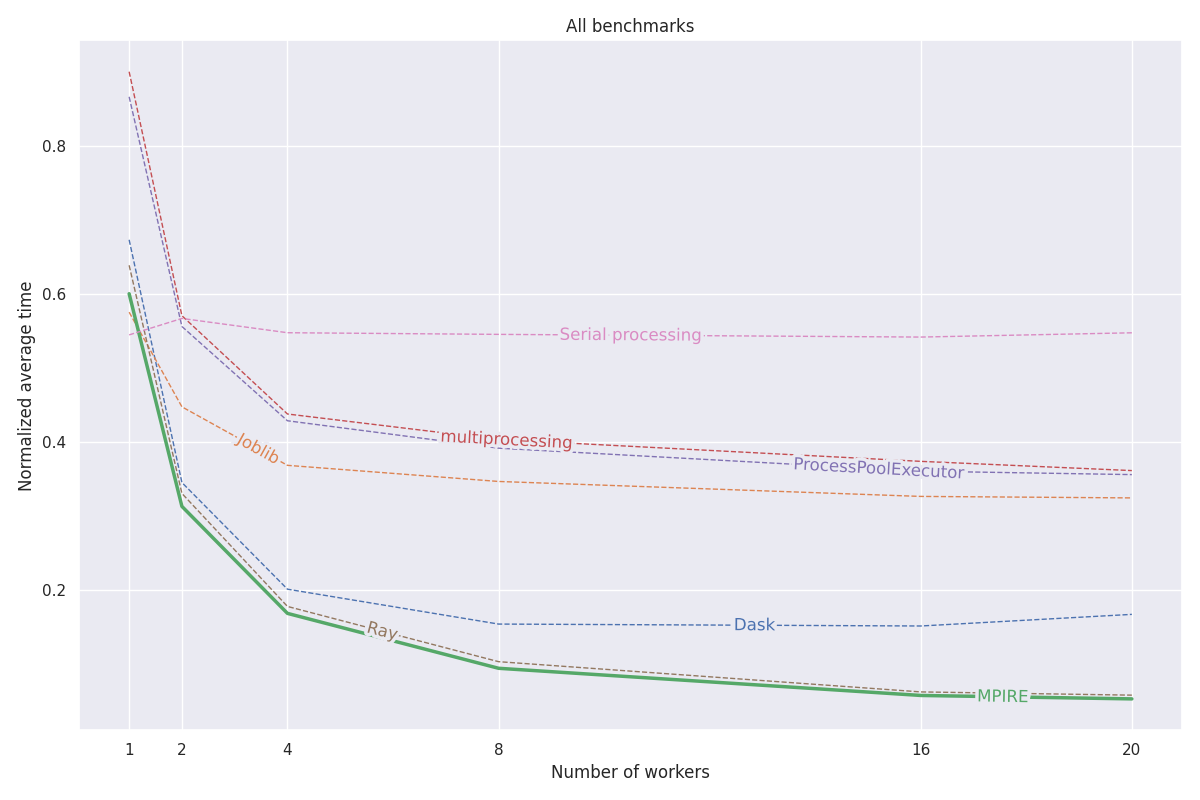
Lihat dokumentasi lengkap di https://sybrenjansen.github.io/mpire/ untuk informasi tentang semua fitur MPIRE lainnya.
Jika Anda ingin membuat dokumentasi sendiri, silakan instal dependensi dokumentasi dengan menjalankan:
pip install mpire[docs]atau
pip install .[docs]Dokumentasi kemudian dapat dibuat dengan menggunakan Python <= 3.9 dan mengeksekusi:
python setup.py build_docs Dokumentasi juga dapat dibuat langsung dari folder docs . Dalam hal ini MPIRE harus diinstal dan tersedia di lingkungan kerja Anda saat ini. Kemudian jalankan:
make html di folder docs .


