Sistem Manajemen Metro
Proyek Kursus Musim Semi SUSTech 2024 CS307 - Principles of Database System Dipimpin oleh Yuxin MA
Shenzhen-Metro
├── Project1 # part 1 of project (database design and data import)
│ ├── ShenzhenMetroDatabaseDesign
│ │ ├── src
│ │ │ ├── main
│ │ │ │ ├── java # import script in java
│ │ │ │ ├── resources # data in json
│ │ │ │ └── sql # ddl
│ └── ShenzhenMetroDatabaseDesignPython
│ ├── import_script.py # import script in python
│ └── resources # data in json
├── Project2 # part 2 of project (building an api)
│ ├── DataImport # updated data import
│ │ ├── src
│ │ │ ├── main
│ │ │ │ ├── java # updated import script in java
│ │ │ │ ├── resources # updated data
│ │ │ │ └── sql # updated ddl
│ └── ShenzhenMetro # spring boot project
│ ├── src
│ │ ├── main
│ │ │ ├── java # backend logic
│ │ │ │ └── com/sustech/cs307/project2/shenzhenmetro
│ │ │ │ ├── ShenzhenMetroApplication.java # main application driver
│ │ │ │ ├── controller # api route mapping
│ │ │ │ ├── dto # dto between client and server
│ │ │ │ ├── object # orm between database tables and application code
│ │ │ │ ├── repository # interfaces for data access
│ │ │ │ └── service # service layer containing business logic
│ │ │ └── resources # frontend logic
│ │ │ ├── application.properties # configuration file for spring boot application
│ │ │ ├── static
│ │ │ │ ├── assets
│ │ │ │ │ ├── css
│ │ │ │ │ ├── img
│ │ │ │ │ ├── js
│ │ │ │ │ └── vendor
│ │ │ │ │ ├── aos
│ │ │ │ │ ├── bootstrap
│ │ │ │ │ ├── bootstrap-icons
│ │ │ │ │ ├── glightbox
│ │ │ │ │ └── swiper
│ │ │ │ └── index.html # main html
│ │ │ └── templates
│ │ │ ├── buses
│ │ │ │ ├── create_bus.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_bus.html
│ │ │ ├── landmarks
│ │ │ │ ├── create_landmark.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_landmark.html
│ │ │ ├── lineDetails
│ │ │ │ ├── create_line_detail.html
│ │ │ │ ├── index.html
│ │ │ │ ├── navigate_routes.html
│ │ │ │ └── search_line_detail.html
│ │ │ ├── lines
│ │ │ │ ├── create_line.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_line.html
│ │ │ ├── ongoingRides
│ │ │ │ └── index.html
│ │ │ ├── rides
│ │ │ │ ├── create_ride.html
│ │ │ │ ├── filter_ride.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_ride.html
│ │ │ ├── stations
│ │ │ │ ├── create_station.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_station.html
│ │ │ └── users
│ │ │ ├── card.html
│ │ │ └── passenger.html
└── README.md
Bagian pertama dari proyek ini terutama tentang merancang skema database yang memenuhi prinsip-prinsip database relasional berdasarkan latar belakang data yang disediakan. Setelah tahap desain selesai, kami menulis skrip untuk mengimpor kumpulan data besar tersebut. Untuk memastikan keakuratan data yang diimpor, kami harus melakukan beberapa pernyataan kueri dan memeriksa hasil kueri pada hari pembelaan. Selain itu, kami juga menjalankan beberapa eksperimen dengan data untuk mendapatkan wawasan yang luar biasa, seperti yang ditunjukkan nanti.
[Baca persyaratan detailnya]
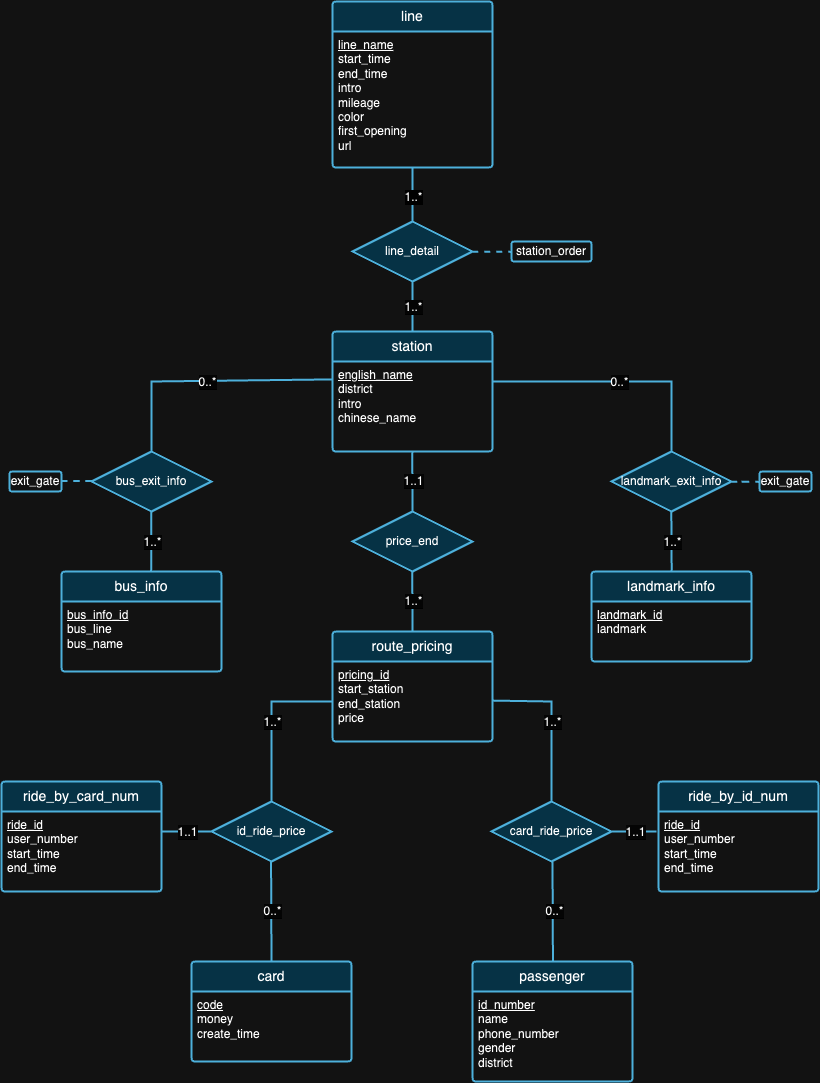
Kami percaya bahwa tidak ada desain database yang sempurna. Faktanya, terdapat kekurangan pada desain yang kami usulkan pada diagram ER di atas. Setelah melihat kumpulan data dan latar belakang setiap kumpulan data, kami harap Anda dapat mencoba menemukan sendiri kekurangan desain! :)
Catatan : Untuk interpretasi gambar,
| PENGENAL | sistem operasi | Kepingan | Ingatan | SSD | Peralatan |
|---|---|---|---|---|---|
| 1 | macOS Sonoma 14.4.1 | Apple M3 Pro | 18GB | 1 TB | IDEA 2024.1 (CE), PyCharm 2023.3.4 (CE), Datagrip 2024.1 |
| 2 | Windows 11 Rumah 23H2 | Intel(R) Core(TM) i9-12900H Generasi ke-12 | 32GB | 1 TB | IDE 2024.1 (CE), Pegangan Data 2024.1 |
| 3 | Ubuntu 22.04.4 (VM) | Apple M1 Pro | 16GB | 512GB | IDE 2024.1 (CE), Pegangan Data 2024.1 |
Experiment 1: Different Import Methods Metode 1 (skrip asli): Metode ini menggunakan perpustakaan java.sql . Pertama, kami membuat koneksi ke server PostgreSQL kami. Lalu kita membaca semua data dari file JSON. Selanjutnya, kami mengulangi setiap datum dan membuat PreparedStatement untuk setiap pernyataan penyisipan. Terakhir, kita memanggil metode executeUpdate() untuk mengeksekusi setiap pernyataan satu per satu.
Metode 2 (skrip yang dioptimalkan): Metode ini juga memanfaatkan perpustakaan java.sql dan menggunakan algoritma pembacaan data yang sama seperti Metode 1. Bedanya sekarang kita menggunakan metode executeBatch() . Jadi kami mengulangi seluruh data, membuat setiap pernyataan penyisipan dengan PreparedStatement , dan menambahkan setiap PreparedStatement ke batch untuk eksekusi batch.
Metode 3 (menjalankan file .sql): Kami menggunakan program Java untuk menghasilkan pernyataan penyisipan SQL dan menuliskannya ke dalam file .sql dengan menggunakan algoritma pembacaan data yang sama yang disebutkan di atas. Kemudian kita jalankan file tersebut di DataGrip.
Karena kami menggunakan algoritme pembacaan data yang sama di ketiga metode, kami akan menggunakan waktu proses rata-rata untuk pengujian berikutnya. Kami awalnya mengumpulkan tiga waktu proses yang berbeda — 504 mdtk, 546 mdtk, dan 552 mdtk — dan menghitung waktu proses rata-rata 534 mdtk.
| Lingkungan Pengujian | Metode | Waktu Baca Rata-rata (ms) | Waktu Tulis (ms) | Total Waktu (md) | Throughput (pernyataan) |
|---|---|---|---|---|---|
| 1 | 1 | 534 | 206396 | 206930 | 8636.91 |
| 1 | 2 | 534 | 2114 | 2648 | 97632.92 |
| 1 | 3 | 534 | 13581 | 14115 | 15197.41 |
Tabel 2 mengilustrasikan berbagai metrik kinerja di berbagai metode, dengan Metode 2 menunjukkan throughput tertinggi dan Metode 1 memiliki total waktu paling lambat. Hal ini menjadikan Metode 2 sebagai metode pengujian standar dalam percobaan mendatang.
Experiment 2: Data Import with Different Data VolumesMengelola dan mengimpor data dengan volume yang bervariasi merupakan aspek penting untuk memastikan kinerja, skalabilitas, dan keandalan sistem database.
Sebelum proses impor, kami melihat bahwa data 'ride' memiliki volume yang lebih besar dibandingkan data lainnya. Berdasarkan ide ini, kami memutuskan untuk menguji impor data dengan volume berbeda hanya di ride.json . Karena bobot data tidak konsisten, mengimpor volume yang lebih sedikit untuk tabel lainnya mungkin mengakibatkan masalah serius karena konektivitas antar tabel.
Awalnya, kami memulai dengan mengimpor data lengkap (volume 100%) untuk semua tabel lainnya kecuali tabel rides_by_id_num dan rides_by_card_num untuk memastikan konsistensi desain kami. Untuk mengelola hal ini secara efektif, kami mengadopsi strategi impor bertahap untuk data ride , dimulai dengan 20% subset data, yang setara dengan 20.000 catatan. Fase awal ini memungkinkan kami menilai dampaknya terhadap kinerja sistem dan melakukan penyesuaian yang diperlukan pada proses impor tanpa mengorbankan stabilitas database. Setelah validasi dan penyesuaian kinerja berhasil, kami melanjutkan dengan mengimpor 50% data, dan terakhir, sisanya untuk menyelesaikan impor data 100%. Perhatikan bahwa kami menggunakan Metode 2 untuk semua impor karena ini adalah yang tercepat.
| Lingkungan Pengujian | Metode | Volume | Waktu Baca (ms) | Waktu Tulis (ms) | Total Waktu (md) | Jumlah Pernyataan | Throughput (pernyataan) |
|---|---|---|---|---|---|---|---|
| 1 | 2 | 20% | 507 | 808 | 1315 | 80165 | 99214.11 |
| 1 | 2 | 50% | 521 | 1338 | 1859 | 130849 | 97794.47 |
| 1 | 2 | 100% | 534 | 2114 | 2648 | 203502 | 96263.95 |
Dari Tabel 3, seiring bertambahnya volume data (dari 20% menjadi 50% dan menjadi 100%), waktu baca dan tulis cenderung meningkat, sehingga total waktu pengoperasian menjadi lebih lama. Namun angka-angka ini tidak memberikan arti yang berarti karena kita mempunyai volume impor yang berbeda. Jika kita melihat jumlah throughput, throughput (pernyataan/s) secara bertahap menurun seiring bertambahnya volume data, yang menunjukkan bahwa sistem menjadi kurang efisien dalam memproses pernyataan seiring dengan meningkatnya beban kerja.
Experiment 3: Data Import on Different Operating SystemsDalam menguji proses impor data pada OS yang berbeda, kami menggunakan metode impor tercepat, yaitu Metode 2, dengan volume impor 100%.
Perhatikan bahwa saat menjalankan skrip impor Java di Linux melalui mesin virtual, penting untuk mempertimbangkan kerugian yang tidak adil pada kinerja dan alokasi sumber daya, karena virtualisasi dapat menimbulkan overhead dan mempengaruhi efisiensi sistem.
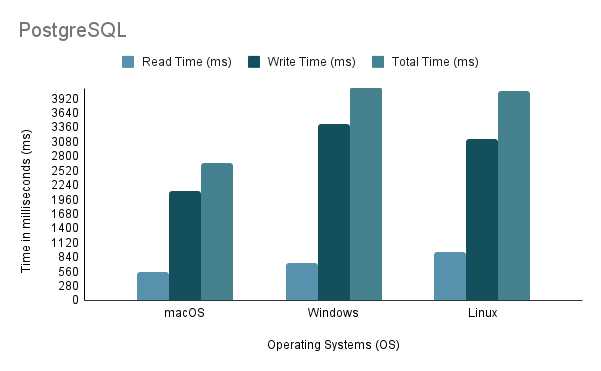
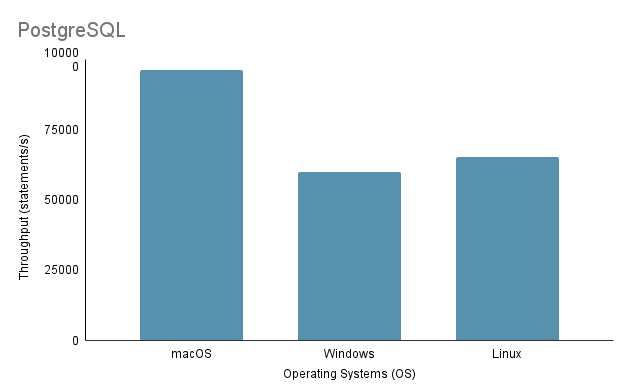
Berdasarkan analisis di atas, terlihat jelas bahwa Environment 1 (macOS) menunjukkan performa terbaik dengan total waktu terpendek sebesar 2648 ms dan throughput tertinggi sebesar 97.632,92 pernyataan/s. Sebaliknya, Lingkungan 2 (Windows) adalah yang paling lambat dengan total waktu 4117 ms dan throughput terendah sebesar 60.669,02 pernyataan/s. Perlu dicatat bahwa Linux Ubuntu, saat dijalankan sebagai VM, masih mengungguli Windows bare-metal.
Experiment 4: Data Import with Various Programming LanguagesDalam percobaan ini, kami menggunakan Metode 2 yang disebutkan di atas untuk kode Java karena ini adalah yang tercepat. Sedangkan untuk Python, kami menulis metode impor yang memanfaatkan Psycopg2 untuk berkomunikasi dengan server database PostgreSQL.
| Lingkungan Pengujian | Bahasa Pemrograman | Waktu Baca (ms) | Waktu Tulis (ms) | Total Waktu (md) | Throughput (pernyataan) |
|---|---|---|---|---|---|
| 1 | Jawa | 534 | 2114 | 2648 | 96263.95 |
| 1 | ular piton | 390 | 7237 | 7627 | 28119.66 |
Data dari Tabel 4 menunjukkan bahwa Java mengungguli Python dalam hal kecepatan dan throughput, yang menunjukkan efisiensinya yang unggul untuk operasi baca-tulis.
Experiment 5: Data Import on Different DatabasesKami mengembangkan tiga metode impor yang berbeda untuk PostgreSQL dan MySQL, namun kami hanya menjalankan eksperimen pada Metode 2 karena ini adalah pilihan pengembang untuk mengimpor data. Baik PostgreSQL dan MySQL memiliki desain implementasi database yang serupa (dari segi DDL) dan desain kode impor yang serupa.
| Lingkungan Pengujian | Metode | Basis data | Waktu Baca (ms) | Waktu Tulis (ms) | Total Waktu (md) | Throughput (pernyataan) |
|---|---|---|---|---|---|---|
| 1 | 2 | PostgreSQL | 534 | 2114 | 2648 | 96263.95 |
| 1 | 2 | MySQL | 534 | 42315 | 42849 | 4809.22 |
Meskipun keduanya merupakan database berbasis SQL, PostgreSQL kira-kira 16 kali lebih cepat dalam hal waktu penulisan. Hal ini mungkin disebabkan oleh perbedaan dalam arsitektur mesin database dan implementasi driver ( postgresql-42.2.5.jar untuk PostgreSQL dan mysql-connector-j-8.3.0.jar untuk MySQL).
Bagian 2 dari proyek ini berfokus pada penyediaan fungsionalitas dasar untuk mengakses sistem database dengan membangun perpustakaan backend yang memaparkan serangkaian antarmuka pemrograman aplikasi (API). Perhatikan bahwa ada juga kumpulan data tambahan yang perlu diimpor, sehingga memerlukan implementasi database yang diperbarui (dapat ditemukan di ./Project2/DataImport ).
[Baca persyaratan detailnya]
./Project2/DataImport/src/main/sql/ddl.sql./Project2/DataImport/src/main/java/ImportScript.java./Project2/ShenzhenMetro ) dengan Maven (disarankan IntelliJ IDEA IDE)

