shap
v0.46.0
SHAP (SHapley Additive exPlanations) adalah pendekatan teori permainan untuk menjelaskan keluaran model pembelajaran mesin apa pun. Ini menghubungkan alokasi kredit yang optimal dengan penjelasan lokal menggunakan nilai-nilai klasik Shapley dari teori permainan dan perluasannya yang terkait (lihat makalah untuk rincian dan kutipan).
SHAP dapat diinstal dari PyPI atau conda-forge:
bentuk instalasi pip atau conda install -c conda-forge bentuk
Meskipun SHAP dapat menjelaskan keluaran model pembelajaran mesin apa pun, kami telah mengembangkan algoritme tepat berkecepatan tinggi untuk metode ansambel pohon (lihat makalah Nature MI kami). Implementasi C++ yang cepat didukung untuk model XGBoost , LightGBM , CatBoost , scikit-learn dan pyspark tree:
import xgboost
import shap
# train an XGBoost model
X , y = shap . datasets . california ()
model = xgboost . XGBRegressor (). fit ( X , y )
# explain the model's predictions using SHAP
# (same syntax works for LightGBM, CatBoost, scikit-learn, transformers, Spark, etc.)
explainer = shap . Explainer ( model )
shap_values = explainer ( X )
# visualize the first prediction's explanation
shap . plots . waterfall ( shap_values [ 0 ])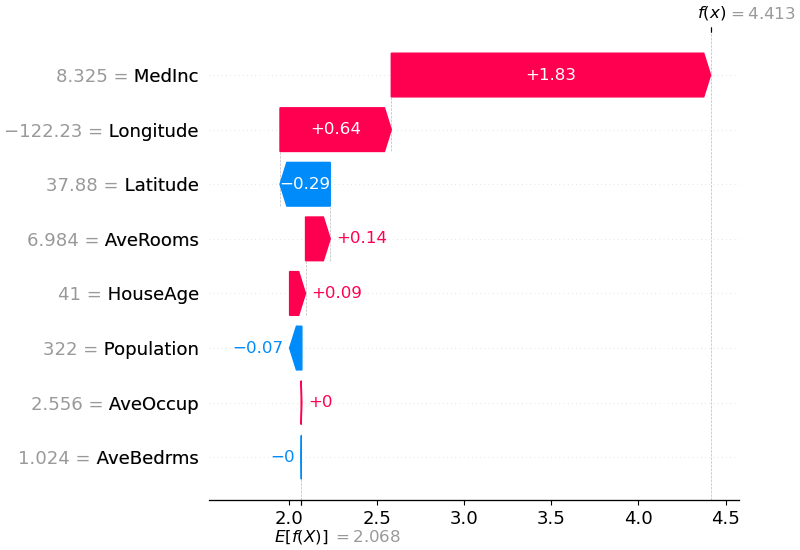
Penjelasan di atas menunjukkan fitur yang masing-masing berkontribusi untuk mendorong keluaran model dari nilai dasar (output model rata-rata selama kumpulan data pelatihan yang kami lewati) ke keluaran model. Fitur yang mendorong prediksi lebih tinggi ditampilkan dalam warna merah, fitur yang mendorong prediksi lebih rendah ditampilkan dalam warna biru. Cara lain untuk memvisualisasikan penjelasan yang sama adalah dengan menggunakan plot gaya (ini diperkenalkan dalam makalah Nature BME kami):
# visualize the first prediction's explanation with a force plot
shap . plots . force ( shap_values [ 0 ])
Jika kita mengambil banyak penjelasan force plot seperti yang ditunjukkan di atas, memutarnya 90 derajat, lalu menumpuknya secara horizontal, kita dapat melihat penjelasan untuk keseluruhan kumpulan data (di notebook, plot ini bersifat interaktif):
# visualize all the training set predictions
shap . plots . force ( shap_values [: 500 ])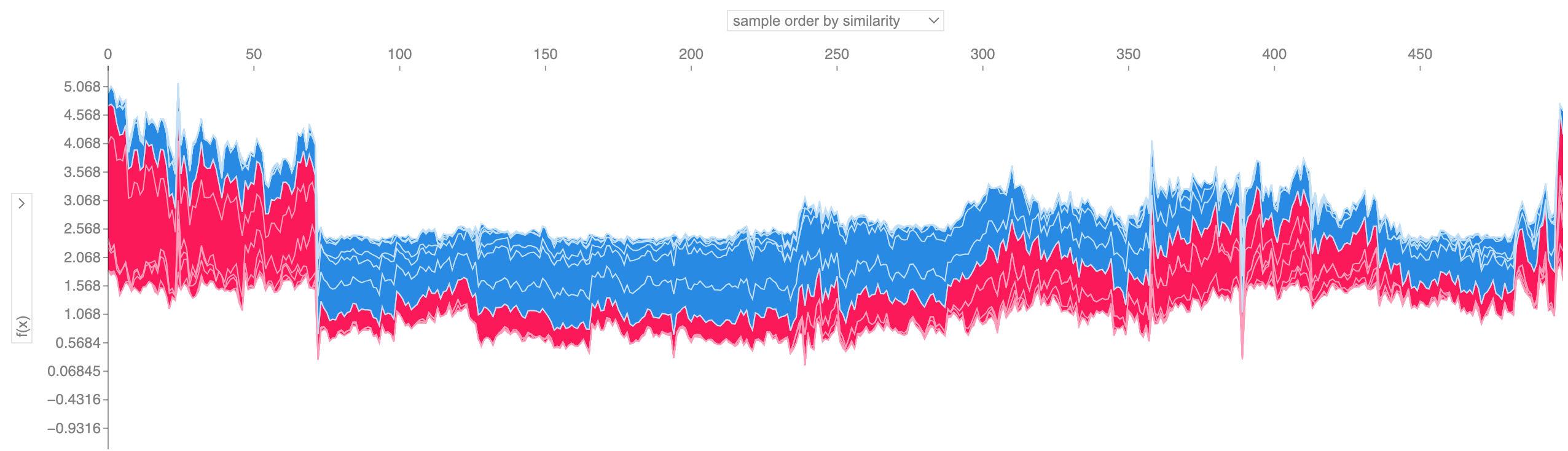
Untuk memahami bagaimana sebuah fitur mempengaruhi keluaran model, kita dapat memplot nilai SHAP fitur tersebut vs. nilai fitur untuk semua contoh dalam kumpulan data. Karena nilai SHAP mewakili tanggung jawab fitur atas perubahan keluaran model, plot di bawah mewakili perubahan prediksi harga rumah seiring perubahan garis lintang. Penyebaran vertikal pada satu nilai garis lintang mewakili efek interaksi dengan fitur lainnya. Untuk membantu mengungkapkan interaksi ini kita dapat mewarnai dengan fitur lain. Jika kita meneruskan seluruh penjelasan tensor ke argumen color , plot sebar akan memilih fitur terbaik untuk diwarnai. Dalam hal ini ia memilih garis bujur.
# create a dependence scatter plot to show the effect of a single feature across the whole dataset
shap . plots . scatter ( shap_values [:, "Latitude" ], color = shap_values )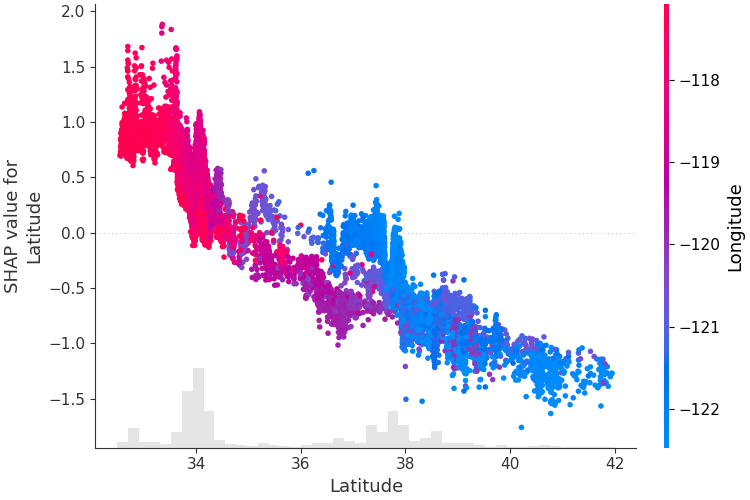
Untuk mendapatkan gambaran umum tentang fitur mana yang paling penting bagi suatu model, kita dapat memplot nilai SHAP setiap fitur untuk setiap sampel. Plot di bawah mengurutkan fitur berdasarkan jumlah besaran nilai SHAP pada seluruh sampel, dan menggunakan nilai SHAP untuk menunjukkan distribusi dampak setiap fitur terhadap keluaran model. Warna mewakili nilai fitur (merah tinggi, biru rendah). Hal ini misalnya menunjukkan bahwa pendapatan median yang lebih tinggi akan meningkatkan prediksi harga rumah.
# summarize the effects of all the features
shap . plots . beeswarm ( shap_values )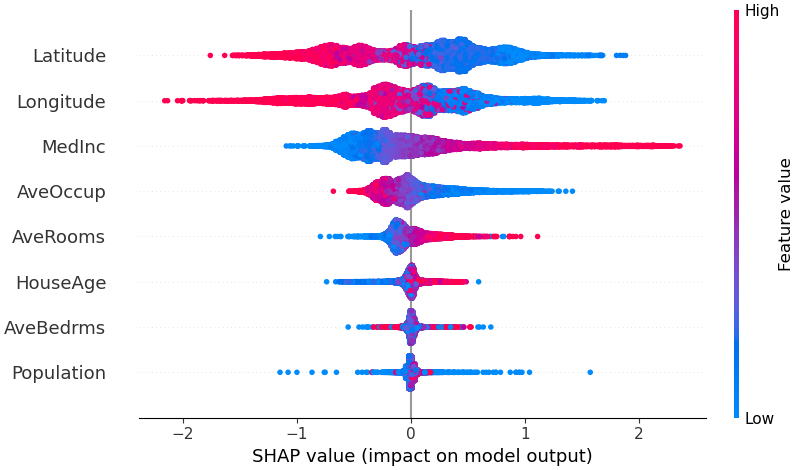
Kita juga dapat mengambil nilai absolut rata-rata dari nilai SHAP untuk setiap fitur untuk mendapatkan plot batang standar (menghasilkan batang bertumpuk untuk keluaran kelas jamak):
shap . plots . bar ( shap_values )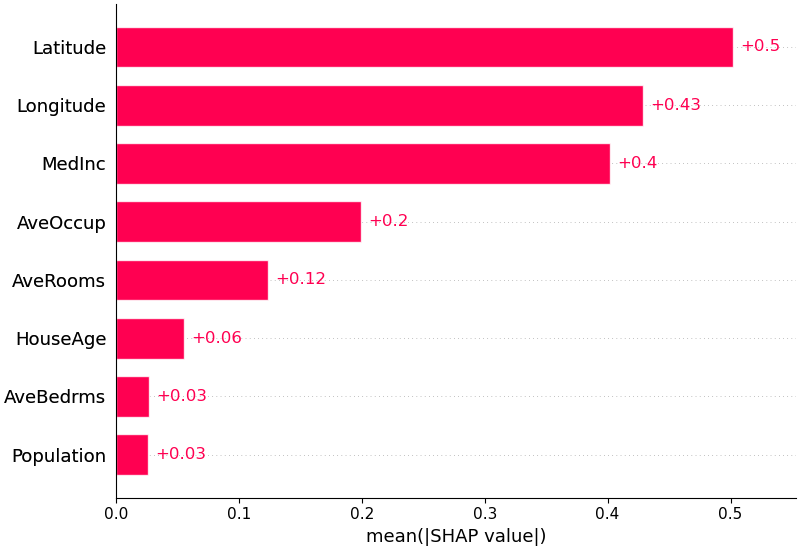
SHAP memiliki dukungan khusus untuk model bahasa alami seperti yang ada di perpustakaan transformator Hugging Face. Dengan menambahkan aturan koalisi pada nilai-nilai Shapley tradisional, kita dapat membentuk permainan yang menjelaskan model NLP modern yang besar dengan menggunakan sedikit evaluasi fungsi. Menggunakan fungsi ini semudah meneruskan pipa transformator yang didukung ke SHAP:
import transformers
import shap
# load a transformers pipeline model
model = transformers . pipeline ( 'sentiment-analysis' , return_all_scores = True )
# explain the model on two sample inputs
explainer = shap . Explainer ( model )
shap_values = explainer ([ "What a great movie! ...if you have no taste." ])
# visualize the first prediction's explanation for the POSITIVE output class
shap . plots . text ( shap_values [ 0 , :, "POSITIVE" ])Deep SHAP adalah algoritme perkiraan kecepatan tinggi untuk nilai SHAP dalam model pembelajaran mendalam yang dibangun berdasarkan koneksi dengan DeepLIFT yang dijelaskan dalam makalah SHAP NIPS. Implementasinya di sini berbeda dari DeepLIFT asli dengan menggunakan distribusi sampel latar belakang alih-alih nilai referensi tunggal, dan menggunakan persamaan Shapley untuk linierisasi komponen seperti maks, softmax, produk, divisi, dll. Perhatikan bahwa beberapa penyempurnaan ini juga telah dilakukan sejak diintegrasikan ke dalam DeepLIFT. Model TensorFlow dan model Keras yang menggunakan backend TensorFlow didukung (ada juga dukungan awal untuk PyTorch):
# ...include code from https://github.com/keras-team/keras/blob/master/examples/demo_mnist_convnet.py
import shap
import numpy as np
# select a set of background examples to take an expectation over
background = x_train [ np . random . choice ( x_train . shape [ 0 ], 100 , replace = False )]
# explain predictions of the model on four images
e = shap . DeepExplainer ( model , background )
# ...or pass tensors directly
# e = shap.DeepExplainer((model.layers[0].input, model.layers[-1].output), background)
shap_values = e . shap_values ( x_test [ 1 : 5 ])
# plot the feature attributions
shap . image_plot ( shap_values , - x_test [ 1 : 5 ])Plot di atas menjelaskan sepuluh keluaran (digit 0-9) untuk empat gambar berbeda. Piksel merah meningkatkan keluaran model sedangkan piksel biru menurunkan keluaran. Gambar masukan ditampilkan di sebelah kiri, dan sebagai latar belakang skala abu-abu yang hampir transparan di balik setiap penjelasan. Jumlah nilai SHAP sama dengan selisih antara keluaran model yang diharapkan (dirata-ratakan pada kumpulan data latar belakang) dan keluaran model saat ini. Perhatikan bahwa untuk gambar 'nol', bagian tengah yang kosong adalah penting, sedangkan untuk gambar 'empat', tidak adanya sambungan di bagian atas menjadikannya empat, bukan sembilan.
Gradien yang diharapkan menggabungkan ide dari Gradien Terintegrasi, SHAP, dan SmoothGrad ke dalam satu persamaan nilai yang diharapkan. Hal ini memungkinkan seluruh kumpulan data digunakan sebagai distribusi latar belakang (sebagai lawan dari nilai referensi tunggal) dan memungkinkan pemulusan lokal. Jika kita memperkirakan model dengan fungsi linier antara setiap sampel data latar belakang dan masukan saat ini yang akan dijelaskan, dan kita berasumsi fitur masukan bersifat independen, maka gradien yang diharapkan akan menghitung perkiraan nilai SHAP. Pada contoh di bawah ini kami telah menjelaskan bagaimana lapisan perantara ke-7 dari model ImageNet VGG16 memengaruhi probabilitas keluaran.
from keras . applications . vgg16 import VGG16
from keras . applications . vgg16 import preprocess_input
import keras . backend as K
import numpy as np
import json
import shap
# load pre-trained model and choose two images to explain
model = VGG16 ( weights = 'imagenet' , include_top = True )
X , y = shap . datasets . imagenet50 ()
to_explain = X [[ 39 , 41 ]]
# load the ImageNet class names
url = "https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json"
fname = shap . datasets . cache ( url )
with open ( fname ) as f :
class_names = json . load ( f )
# explain how the input to the 7th layer of the model explains the top two classes
def map2layer ( x , layer ):
feed_dict = dict ( zip ([ model . layers [ 0 ]. input ], [ preprocess_input ( x . copy ())]))
return K . get_session (). run ( model . layers [ layer ]. input , feed_dict )
e = shap . GradientExplainer (
( model . layers [ 7 ]. input , model . layers [ - 1 ]. output ),
map2layer ( X , 7 ),
local_smoothing = 0 # std dev of smoothing noise
)
shap_values , indexes = e . shap_values ( map2layer ( to_explain , 7 ), ranked_outputs = 2 )
# get the names for the classes
index_names = np . vectorize ( lambda x : class_names [ str ( x )][ 1 ])( indexes )
# plot the explanations
shap . image_plot ( shap_values , to_explain , index_names ) Prediksi untuk dua gambar masukan dijelaskan pada plot di atas. Piksel merah mewakili nilai SHAP positif yang meningkatkan probabilitas kelas, sedangkan piksel biru mewakili nilai SHAP negatif yang mengurangi probabilitas kelas. Dengan menggunakan ranked_outputs=2 kami hanya menjelaskan dua kelas yang paling mungkin untuk setiap masukan (hal ini membuat kami tidak perlu menjelaskan seluruh 1.000 kelas).
Kernel SHAP menggunakan regresi linier lokal berbobot khusus untuk memperkirakan nilai SHAP untuk model apa pun. Di bawah ini adalah contoh sederhana untuk menjelaskan SVM kelas jamak pada kumpulan data iris klasik.
import sklearn
import shap
from sklearn . model_selection import train_test_split
# print the JS visualization code to the notebook
shap . initjs ()
# train a SVM classifier
X_train , X_test , Y_train , Y_test = train_test_split ( * shap . datasets . iris (), test_size = 0.2 , random_state = 0 )
svm = sklearn . svm . SVC ( kernel = 'rbf' , probability = True )
svm . fit ( X_train , Y_train )
# use Kernel SHAP to explain test set predictions
explainer = shap . KernelExplainer ( svm . predict_proba , X_train , link = "logit" )
shap_values = explainer . shap_values ( X_test , nsamples = 100 )
# plot the SHAP values for the Setosa output of the first instance
shap . force_plot ( explainer . expected_value [ 0 ], shap_values [ 0 ][ 0 ,:], X_test . iloc [ 0 ,:], link = "logit" )Penjelasan di atas menunjukkan empat fitur yang masing-masing berkontribusi untuk mendorong keluaran model dari nilai dasar (rata-rata keluaran model pada kumpulan data pelatihan yang kami lewati) menuju nol. Jika ada fitur yang mendorong label kelas lebih tinggi, fitur tersebut akan ditampilkan dengan warna merah.
Jika kita mengambil banyak penjelasan seperti gambar di atas, memutarnya 90 derajat, lalu menumpuknya secara horizontal, kita bisa melihat penjelasan untuk keseluruhan dataset. Inilah yang kami lakukan di bawah ini untuk semua contoh pada set pengujian iris mata:
# plot the SHAP values for the Setosa output of all instances
shap . force_plot ( explainer . expected_value [ 0 ], shap_values [ 0 ], X_test , link = "logit" ) Nilai interaksi SHAP merupakan generalisasi nilai SHAP ke interaksi tingkat tinggi. Perhitungan cepat dan tepat dari interaksi berpasangan diimplementasikan untuk model pohon dengan shap.TreeExplainer(model).shap_interaction_values(X) . Ini mengembalikan matriks untuk setiap prediksi, dengan efek utama berada pada diagonal dan efek interaksi berada di luar diagonal. Nilai-nilai ini sering kali mengungkapkan hubungan tersembunyi yang menarik, seperti bagaimana peningkatan risiko kematian mencapai puncaknya pada pria pada usia 60 tahun (lihat buku catatan NHANES untuk rinciannya):
Buku catatan di bawah ini menunjukkan kasus penggunaan yang berbeda untuk SHAP. Lihat ke dalam direktori notebook di repositori jika Anda ingin mencoba bermain-main dengan notebook asli sendiri.
Implementasi Tree SHAP, algoritma yang cepat dan tepat untuk menghitung nilai SHAP untuk pohon dan kumpulan pohon.
Model kelangsungan hidup NHANES dengan nilai interaksi XGBoost dan SHAP - Menggunakan data kematian dari masa tindak lanjut selama 20 tahun, buku catatan ini menunjukkan cara menggunakan XGBoost dan shap untuk mengungkap hubungan faktor risiko yang kompleks.
Klasifikasi pendapatan sensus dengan LightGBM - Menggunakan kumpulan data pendapatan sensus dewasa standar, buku catatan ini melatih model pohon peningkat gradien dengan LightGBM dan kemudian menjelaskan prediksi menggunakan shap .
Prediksi Kemenangan League of Legends dengan XGBoost - Menggunakan kumpulan data Kaggle yang berisi 180.000 pertandingan peringkat dari League of Legends, kami melatih dan menjelaskan model pohon peningkatan gradien dengan XGBoost untuk memprediksi apakah seorang pemain akan memenangkan pertandingannya.
Implementasi Deep SHAP, algoritma yang lebih cepat (tetapi hanya perkiraan) untuk menghitung nilai SHAP untuk model pembelajaran mendalam yang didasarkan pada koneksi antara SHAP dan algoritma DeepLIFT.
Klasifikasi Digit MNIST dengan Keras - Menggunakan kumpulan data pengenalan tulisan tangan MNIST, notebook ini melatih jaringan saraf dengan Keras dan kemudian menjelaskan prediksi menggunakan shap .
Keras LSTM untuk Klasifikasi Sentimen IMDB - Buku catatan ini melatih LSTM dengan Keras pada kumpulan data analisis sentimen teks IMDB dan kemudian menjelaskan prediksi menggunakan shap .
Implementasi gradien yang diharapkan untuk memperkirakan nilai SHAP untuk model pembelajaran mendalam. Hal ini didasarkan pada hubungan antara SHAP dan algoritma Gradien Terintegrasi. GradientExplainer lebih lambat dari DeepExplainer dan membuat asumsi perkiraan yang berbeda.
Untuk model linier dengan fitur independen, kita dapat menghitung nilai SHAP yang tepat secara analitis. Kita juga dapat memperhitungkan korelasi fitur jika kita ingin memperkirakan matriks kovarians fitur. LinearExplainer mendukung kedua opsi ini.
Implementasi Kernel SHAP, metode model agnostik untuk memperkirakan nilai SHAP untuk model apa pun. Karena tidak membuat asumsi tentang tipe model, KernelExplainer lebih lambat dibandingkan algoritma spesifik tipe model lainnya.
Klasifikasi pendapatan sensus dengan scikit-learn - Menggunakan kumpulan data pendapatan sensus dewasa standar, buku catatan ini melatih pengklasifikasi k-tetangga terdekat menggunakan scikit-learn dan kemudian menjelaskan prediksi menggunakan shap .
Model ImageNet VGG16 dengan Keras - Jelaskan prediksi jaringan neural konvolusional VGG16 klasik untuk sebuah gambar. Ini bekerja dengan menerapkan metode Kernel SHAP model agnostik ke gambar tersegmentasi super-piksel.
Klasifikasi iris mata - Demonstrasi dasar menggunakan kumpulan data spesies iris yang populer. Ini menjelaskan prediksi dari enam model berbeda dalam scikit-learn menggunakan shap .
Buku catatan ini secara komprehensif mendemonstrasikan cara menggunakan fungsi dan objek tertentu.
shap.decision_plot dan shap.multioutput_decision_plot
shap.dependence_plot
KAPUR: Ribeiro, Marco Tulio, Sameer Singh, dan Carlos Guestrin. "Mengapa saya harus mempercayai Anda?: Menjelaskan prediksi pengklasifikasi apa pun." Prosiding Konferensi Internasional ACM SIGKDD ke-22 tentang Penemuan Pengetahuan dan Penambangan Data. ACM, 2016.
Nilai sampel Shapley: Strumbelj, Erik, dan Igor Kononenko. "Menjelaskan model prediksi dan prediksi individu dengan kontribusi fitur." Sistem Pengetahuan dan Informasi 41.3 (2014): 647-665.
DeepLIFT: Shrikumar, Avanti, Peyton Greenside, dan Anshul Kundaje. "Mempelajari fitur-fitur penting melalui penyebaran perbedaan aktivasi." arXiv pracetak arXiv:1704.02685 (2017).
QII: Datta, Anupam, Shayak Sen, dan Yair Zick. "Transparansi algoritmik melalui pengaruh masukan kuantitatif: Teori dan eksperimen dengan sistem pembelajaran." Keamanan dan Privasi (SP), Simposium IEEE 2016 tentang. IEEE, 2016.
Propagasi relevansi berdasarkan lapisan: Bach, Sebastian, dkk. "Tentang penjelasan berdasarkan piksel untuk keputusan pengklasifikasi non-linier dengan propagasi relevansi berdasarkan lapisan." PloS satu 10.7 (2015): e0130140.
Nilai regresi Shapley: Lipovetsky, Stan, dan Michael Conklin. "Analisis regresi dalam pendekatan teori permainan." Model Stochastic Terapan dalam Bisnis dan Industri 17.4 (2001): 319-330.
Penerjemah pohon: Saabas, Ando. Menafsirkan hutan acak. http://blog.datadive.net/interpreting-random-forests/
Algoritme dan visualisasi yang digunakan dalam paket ini terutama berasal dari penelitian di laboratorium Su-In Lee di Universitas Washington, dan Microsoft Research. Jika Anda menggunakan SHAP dalam penelitian Anda, kami sangat menghargai kutipan pada makalah yang sesuai:
force_plot dan aplikasi medis Anda dapat membaca/mengutip makalah Teknik Biomedis Alam kami (bibtex; akses gratis).

