Candle adalah framework ML minimalis untuk Rust dengan fokus pada performa (termasuk dukungan GPU) dan kemudahan penggunaan. Coba demo online kami: bisikan, LLaMA2, T5, yolo, Segmen Apa Pun.
Pastikan Anda telah memasang candle-core dengan benar seperti dijelaskan dalam Instalasi .
Mari kita lihat cara menjalankan perkalian matriks sederhana. Tulis yang berikut ke file myapp/src/main.rs Anda:
use candle_core :: { Device , Tensor } ;
fn main ( ) -> Result < ( ) , Box < dyn std :: error :: Error > > {
let device = Device :: Cpu ;
let a = Tensor :: randn ( 0f32 , 1. , ( 2 , 3 ) , & device ) ? ;
let b = Tensor :: randn ( 0f32 , 1. , ( 3 , 4 ) , & device ) ? ;
let c = a . matmul ( & b ) ? ;
println ! ( "{c}" ) ;
Ok ( ( ) )
} cargo run harus menampilkan bentuk tensor Tensor[[2, 4], f32] .
Setelah menginstal candle dengan dukungan Cuda, cukup tentukan device yang akan menggunakan GPU:
- let device = Device::Cpu;
+ let device = Device::new_cuda(0)?;Untuk contoh lebih lanjut, silakan lihat bagian berikut.
Demo online ini sepenuhnya dijalankan di browser Anda:
Kami juga menyediakan beberapa contoh berbasis baris perintah menggunakan model canggih:
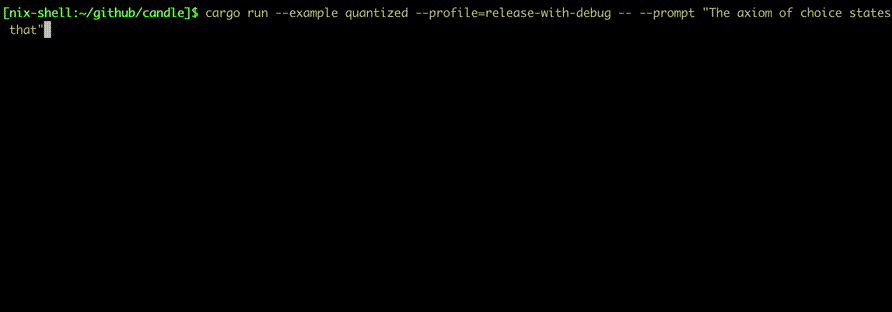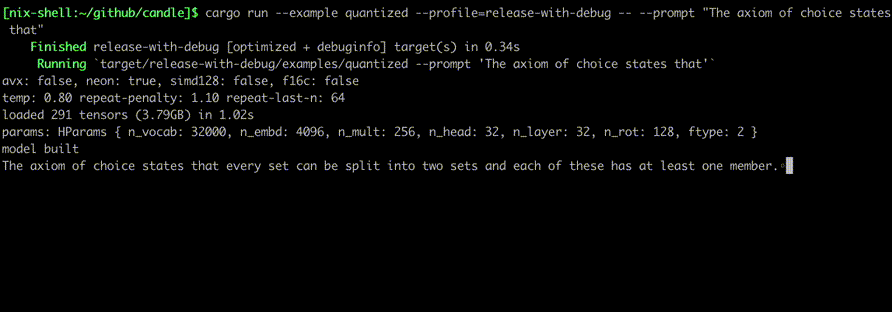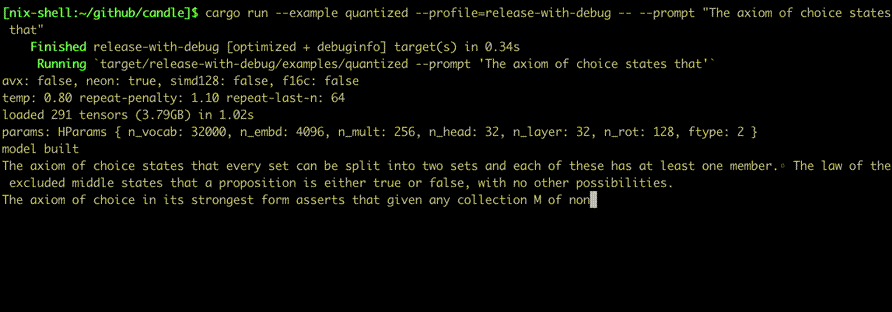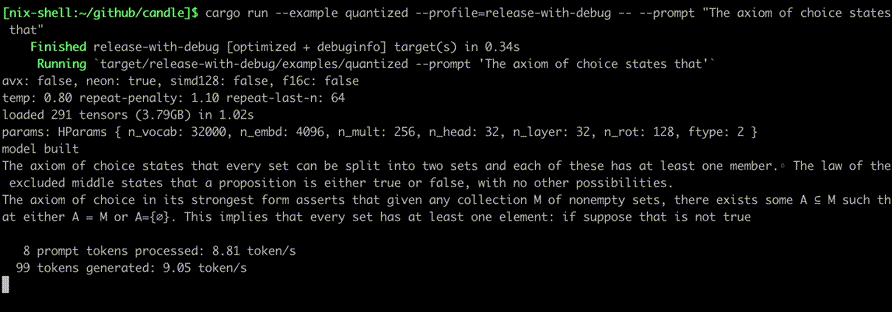





Jalankan mereka menggunakan perintah seperti:
cargo run --example quantized --release
Untuk menggunakan CUDA, tambahkan --features cuda ke baris perintah contoh. Jika Anda telah menginstal cuDNN, gunakan --features cudnn untuk mempercepat lebih banyak lagi.
Ada juga beberapa contoh wasm untuk bisikan dan llama2.c. Anda dapat membuatnya dengan trunk atau mencobanya secara online: Whisper, llama2, T5, Phi-1.5, dan Phi-2, Segment Anything Model.
Untuk LLaMA2, jalankan perintah berikut untuk mengambil file bobot dan memulai server pengujian:
cd candle-wasm-examples/llama2-c
wget https://huggingface.co/spaces/lmz/candle-llama2/resolve/main/model.bin
wget https://huggingface.co/spaces/lmz/candle-llama2/resolve/main/tokenizer.json
trunk serve --release --port 8081Lalu buka http://localhost:8081/.
candle-tutorial : Tutorial yang sangat mendetail yang menunjukkan cara mengonversi model PyTorch ke Candle.candle-lora : Implementasi LoRA yang efisien dan ergonomis untuk Candle. candle-lora punyaoptimisers : Kumpulan pengoptimal termasuk SGD dengan momentum, AdaGrad, AdaDelta, AdaMax, NAdam, RAdam, dan RMSprop.candle-vllm : Platform efisien untuk inferensi dan melayani LLM lokal termasuk server API yang kompatibel dengan OpenAI.candle-ext : Pustaka ekstensi ke Candle yang menyediakan fungsi PyTorch yang saat ini tidak tersedia di Candle.candle-coursera-ml : Implementasi algoritma ML dari kursus Spesialisasi Pembelajaran Mesin Coursera.kalosm : Kerangka meta multi-modal di Rust untuk berinteraksi dengan model lokal terlatih dengan dukungan untuk pembangkitan terkontrol, sampler khusus, database vektor dalam memori, transkripsi audio, dan banyak lagi.candle-sampling : Teknik pengambilan sampel untuk Lilin.gpt-from-scratch-rs : Port dari tutorial Let's build GPT karya Andrej Karpathy di YouTube yang menampilkan API Lilin pada masalah mainan.candle-einops : Implementasi karat murni dari perpustakaan python einops.atoma-infer : Pustaka Rust untuk inferensi cepat dalam skala besar, memanfaatkan FlashAttention2 untuk komputasi perhatian yang efisien, PagedAttention untuk manajemen memori cache KV yang efisien, dan dukungan multi-GPU. Ini kompatibel dengan api OpenAI.Jika Anda memiliki tambahan pada daftar ini, silakan kirimkan permintaan penarikan.
Lembar contekan:
| Menggunakan PyTorch | Menggunakan Lilin | |
|---|---|---|
| Penciptaan | torch.Tensor([[1, 2], [3, 4]]) | Tensor::new(&[[1f32, 2.], [3., 4.]], &Device::Cpu)? |
| Penciptaan | torch.zeros((2, 2)) | Tensor::zeros((2, 2), DType::F32, &Device::Cpu)? |
| Pengindeksan | tensor[:, :4] | tensor.i((.., ..4))? |
| Operasi | tensor.view((2, 2)) | tensor.reshape((2, 2))? |
| Operasi | a.matmul(b) | a.matmul(&b)? |
| Hitung | a + b | &a + &b |
| Perangkat | tensor.to(device="cuda") | tensor.to_device(&Device::new_cuda(0)?)? |
| Tipe D | tensor.to(dtype=torch.float16) | tensor.to_dtype(&DType::F16)? |
| Penghematan | torch.save({"A": A}, "model.bin") | candle::safetensors::save(&HashMap::from([("A", A)]), "model.safetensors")? |
| Memuat | weights = torch.load("model.bin") | candle::safetensors::load("model.safetensors", &device) |
TensorSasaran inti Candle adalah memungkinkan inferensi tanpa server . Kerangka kerja pembelajaran mesin lengkap seperti PyTorch berukuran sangat besar, sehingga membuat pembuatan instance pada cluster menjadi lambat. Candle memungkinkan penerapan biner ringan.
Kedua, Candle memungkinkan Anda menghapus Python dari beban kerja produksi. Overhead Python dapat sangat mengganggu kinerja, dan GIL adalah sumber sakit kepala yang terkenal.
Akhirnya, Rust itu keren! Banyak ekosistem HF yang sudah memiliki Rust crates, seperti safetensor dan tokenizer.
dfdx adalah peti yang tangguh, dengan bentuk yang disertakan dalam tipe. Hal ini mencegah banyak sakit kepala dengan membuat kompiler langsung mengeluh tentang ketidakcocokan bentuk. Namun, kami menemukan bahwa beberapa fitur masih memerlukan setiap malam, dan menulis kode bisa menjadi sedikit menakutkan bagi para ahli non-karat.
Kami memanfaatkan dan berkontribusi pada peti inti lainnya selama waktu proses, jadi semoga kedua peti dapat saling mengambil manfaat.
burn adalah peti umum yang dapat memanfaatkan banyak backend sehingga Anda dapat memilih mesin terbaik untuk beban kerja Anda.
tch-rs Mengikat ke perpustakaan obor di Rust. Sangat serbaguna, tetapi mereka membawa seluruh perpustakaan obor ke dalam runtime. Kontributor utama tch-rs juga terlibat dalam pengembangan candle .
Jika Anda mendapatkan beberapa simbol yang hilang saat mengkompilasi biner/tes menggunakan fitur mkl atau akselerasi, misalnya untuk mkl Anda mendapatkan:
= note: /usr/bin/ld: (....o): in function `blas::sgemm':
.../blas-0.22.0/src/lib.rs:1944: undefined reference to `sgemm_' collect2: error: ld returned 1 exit status
= note: some `extern` functions couldn't be found; some native libraries may need to be installed or have their path specified
= note: use the `-l` flag to specify native libraries to link
= note: use the `cargo:rustc-link-lib` directive to specify the native libraries to link with Cargo
atau untuk mempercepat:
Undefined symbols for architecture arm64:
"_dgemm_", referenced from:
candle_core::accelerate::dgemm::h1b71a038552bcabe in libcandle_core...
"_sgemm_", referenced from:
candle_core::accelerate::sgemm::h2cf21c592cba3c47 in libcandle_core...
ld: symbol(s) not found for architecture arm64
Hal ini kemungkinan disebabkan oleh hilangnya tanda linker yang diperlukan untuk mengaktifkan perpustakaan mkl. Anda dapat mencoba menambahkan yang berikut ini untuk mkl di bagian atas biner Anda:
extern crate intel_mkl_src ;atau untuk mempercepat:
extern crate accelerate_src ; Error: request error: https://huggingface.co/meta-llama/Llama-2-7b-hf/resolve/main/tokenizer.json: status code 401
Hal ini mungkin terjadi karena Anda tidak diizinkan menggunakan model LLaMA-v2. Untuk memperbaikinya, Anda harus mendaftar di hub wajah pelukan, menerima ketentuan model LLaMA-v2, dan menyiapkan token autentikasi Anda. Lihat edisi #350 untuk lebih jelasnya.
In file included from kernels/flash_fwd_launch_template.h:11:0,
from kernels/flash_fwd_hdim224_fp16_sm80.cu:5:
kernels/flash_fwd_kernel.h:8:10: fatal error: cute/algorithm/copy.hpp: No such file or directory
#include <cute/algorithm/copy.hpp>
^~~~~~~~~~~~~~~~~~~~~~~~~
compilation terminated.
Error: nvcc error while compiling:
cutlass disediakan sebagai submodul git sehingga Anda mungkin ingin menjalankan perintah berikut untuk memeriksanya dengan benar.
git submodule update --init /usr/include/c++/11/bits/std_function.h:530:146: error: parameter packs not expanded with ‘...’:
Ini adalah bug di gcc-11 yang dipicu oleh kompiler Cuda. Untuk memperbaikinya, instal versi gcc lain yang didukung - misalnya gcc-10, dan tentukan jalur ke compiler di variabel lingkungan NVCC_CCBIN.
env NVCC_CCBIN=/usr/lib/gcc/x86_64-linux-gnu/10 cargo ...
Couldn't compile the test.
---- .candle-booksrcinferencehub.md - Using_the_hub::Using_in_a_real_model_ (line 50) stdout ----
error: linking with `link.exe` failed: exit code: 1181
//very long chain of linking
= note: LINK : fatal error LNK1181: cannot open input file 'windows.0.48.5.lib'
Pastikan Anda menautkan semua perpustakaan asli yang mungkin berlokasi di luar target proyek, misalnya, untuk menjalankan tes mdbook, Anda harus menjalankan:
mdbook test candle-book -L .targetdebugdeps `
-L native=$env:USERPROFILE.cargoregistrysrcindex.crates.io-6f17d22bba15001fwindows_x86_64_msvc-0.42.2lib `
-L native=$env:USERPROFILE.cargoregistrysrcindex.crates.io-6f17d22bba15001fwindows_x86_64_msvc-0.48.5lib
Hal ini mungkin disebabkan oleh model yang dimuat dari /mnt/c , detail lebih lanjut tentang stackoverflow.
Anda dapat mengatur RUST_BACKTRACE=1 untuk diberikan jejak balik ketika kesalahan lilin dihasilkan.
Jika Anda menemukan kesalahan seperti ini called Result::unwrap() on an value: LoadLibraryExW { source: Os { code: 126, kind: Uncategorized, message: "The specified module could not be found." } } di jendela. Untuk memperbaikinya, salin dan ganti nama 3 file ini (pastikan berada di jalurnya). Jalurnya bergantung pada versi cuda Anda. c:WindowsSystem32nvcuda.dll -> cuda.dll c:Program FilesNVIDIA GPU Computing ToolkitCUDAv12.4bincublas64_12.dll -> cublas.dll c:Program FilesNVIDIA GPU Computing ToolkitCUDAv12.4bincurand64_10.dll -> curand.dll


