whisperX
3.1.1
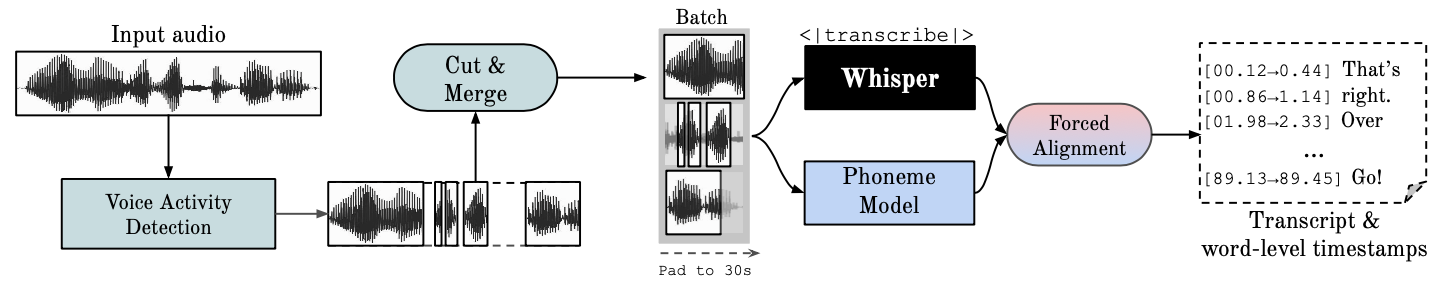
Repositori ini menyediakan pengenalan ucapan otomatis yang cepat (70x realtime dengan v2 besar) dengan stempel waktu tingkat kata dan diarisasi pembicara.
Whisper adalah model ASR yang dikembangkan oleh OpenAI, dilatih pada kumpulan data besar dengan beragam audio. Meskipun menghasilkan transkripsi yang sangat akurat, stempel waktu yang terkait berada pada tingkat pengucapan, bukan per kata, dan bisa menjadi tidak akurat dalam beberapa detik. Bisikan OpenAI pada dasarnya tidak mendukung batching.
ASR Berbasis Fonem Serangkaian model yang disempurnakan untuk mengenali unit ucapan terkecil yang membedakan satu kata dengan kata lainnya, misalnya elemen p dalam "ketuk". Contoh model yang populer adalah wav2vec2.0.
Penyelarasan Paksa mengacu pada proses di mana transkripsi ortografis diselaraskan dengan rekaman audio untuk secara otomatis menghasilkan segmentasi tingkat telepon.
Voice Activity Detection (VAD) adalah pendeteksi ada tidaknya ucapan manusia.
Diarisasi Pembicara adalah proses mempartisi aliran audio yang berisi ucapan manusia ke dalam segmen-segmen yang homogen sesuai dengan identitas masing-masing pembicara.
Eksekusi GPU memerlukan perpustakaan NVIDIA cuBLAS 11.x dan cuDNN 8.x untuk diinstal pada sistem. Silakan merujuk ke dokumentasi CTranslate2.
conda create --name whisperx python=3.10
conda activate whisperx
conda install pytorch==2.0.0 torchaudio==2.0.0 pytorch-cuda=11.8 -c pytorch -c nvidia
Lihat metode lainnya di sini.
pip install git+https://github.com/m-bain/whisperx.git
Jika sudah terinstal, perbarui paket ke komit terbaru
pip install git+https://github.com/m-bain/whisperx.git --upgrade
Jika ingin mengubah paket ini, kloning dan instal dalam mode yang dapat diedit:
$ git clone https://github.com/m-bain/whisperX.git
$ cd whisperX
$ pip install -e .
Anda mungkin juga perlu menginstal ffmpeg, karat, dll. Ikuti instruksi openAI di sini https://github.com/openai/whisper#setup.
Untuk mengaktifkan Speaker Diarization , sertakan token akses Hugging Face Anda (baca) yang dapat Anda hasilkan dari Sini setelah argumen --hf_token dan terima perjanjian pengguna untuk model berikut: Segmentation dan Speaker-Diarization-3.1 (jika Anda memilih untuk menggunakan Speaker -Diarisasi 2.x, ikuti persyaratan di sini.)
Catatan
Mulai 11 Oktober 2023, ada masalah umum terkait kinerja lambat dengan pyannote/Speaker-Diarization-3.0 di WhisperX. Hal ini disebabkan oleh konflik ketergantungan antara fast-whisper dan pyannote-audio 3.0.0. Silakan lihat masalah ini untuk detail selengkapnya dan kemungkinan solusi.
Jalankan bisikan pada segmen contoh (menggunakan parameter default, bisikan kecil) tambahkan --highlight_words True untuk memvisualisasikan pengaturan waktu kata dalam file .srt.
whisperx examples/sample01.wav
Hasil menggunakan WhisperX dengan penyelarasan paksa ke wav2vec2.0 besar:
Bandingkan ini dengan yang asli, di mana banyak transkripsi tidak sinkron:
Untuk meningkatkan akurasi stempel waktu, dengan mengorbankan memori GPU yang lebih tinggi, gunakan model yang lebih besar (model penyelarasan yang lebih besar ternyata tidak terlalu membantu, lihat kertas) misalnya
whisperx examples/sample01.wav --model large-v2 --align_model WAV2VEC2_ASR_LARGE_LV60K_960H --batch_size 4
Untuk memberi label pada transkrip dengan ID pembicara (tetapkan jumlah pembicara jika diketahui, misalnya --min_speakers 2 --max_speakers 2 ):
whisperx examples/sample01.wav --model large-v2 --diarize --highlight_words True
Untuk berjalan di CPU, bukan GPU (dan untuk berjalan di Mac OS X):
whisperx examples/sample01.wav --compute_type int8
Model penyelarasan fonem ASR bersifat khusus untuk bahasa , untuk bahasa yang diuji, model ini secara otomatis dipilih dari saluran pipa torchaudio atau pelukan. Cukup masukkan kode --language , dan gunakan bisikan --model large .
Saat ini model default disediakan untuk {en, fr, de, es, it, ja, zh, nl, uk, pt} . Jika bahasa yang terdeteksi tidak ada dalam daftar ini, Anda perlu mencari model ASR berbasis fonem dari hub model pelukan dan mengujinya pada data Anda.
whisperx --model large-v2 --language de examples/sample_de_01.wav
Lihat lebih banyak contoh dalam bahasa lain di sini.
import whisperx
import gc
device = "cuda"
audio_file = "audio.mp3"
batch_size = 16 # reduce if low on GPU mem
compute_type = "float16" # change to "int8" if low on GPU mem (may reduce accuracy)
# 1. Transcribe with original whisper (batched)
model = whisperx . load_model ( "large-v2" , device , compute_type = compute_type )
# save model to local path (optional)
# model_dir = "/path/"
# model = whisperx.load_model("large-v2", device, compute_type=compute_type, download_root=model_dir)
audio = whisperx . load_audio ( audio_file )
result = model . transcribe ( audio , batch_size = batch_size )
print ( result [ "segments" ]) # before alignment
# delete model if low on GPU resources
# import gc; gc.collect(); torch.cuda.empty_cache(); del model
# 2. Align whisper output
model_a , metadata = whisperx . load_align_model ( language_code = result [ "language" ], device = device )
result = whisperx . align ( result [ "segments" ], model_a , metadata , audio , device , return_char_alignments = False )
print ( result [ "segments" ]) # after alignment
# delete model if low on GPU resources
# import gc; gc.collect(); torch.cuda.empty_cache(); del model_a
# 3. Assign speaker labels
diarize_model = whisperx . DiarizationPipeline ( use_auth_token = YOUR_HF_TOKEN , device = device )
# add min/max number of speakers if known
diarize_segments = diarize_model ( audio )
# diarize_model(audio, min_speakers=min_speakers, max_speakers=max_speakers)
result = whisperx . assign_word_speakers ( diarize_segments , result )
print ( diarize_segments )
print ( result [ "segments" ]) # segments are now assigned speaker IDs Jika Anda tidak memiliki akses ke GPU Anda sendiri, gunakan tautan di atas untuk mencoba WhisperX.
Untuk detail spesifik mengenai batching dan penyelarasan, efek VAD, serta model penyelarasan yang dipilih, lihat kertas pracetak.
Untuk mengurangi kebutuhan memori GPU, coba salah satu langkah berikut (2. & 3. dapat memengaruhi kualitas):
--batch_size 4--model base yang lebih kecil--compute_type int8Perbedaan transkripsi dari bisikan openai:
--without_timestamps True , ini memastikan 1 forward pass per sampel dalam batch. Namun, hal ini dapat menyebabkan perbedaan dengan keluaran bisikan default.--condition_on_prev_text diatur ke False secara default (mengurangi halusinasi) Jika Anda multibahasa, cara utama Anda dapat berkontribusi pada proyek ini adalah dengan menemukan model fonem dalam pelukan (atau melatih model Anda sendiri) dan mengujinya dalam ucapan untuk bahasa target. Jika hasilnya terlihat bagus, kirimkan permintaan tarik dan beberapa contoh yang menunjukkan keberhasilannya.
Penemuan bug dan permintaan penarikan juga sangat dihargai agar proyek ini tetap berjalan, karena proyek ini sudah menyimpang dari cakupan penelitian aslinya.
Inisiasi multibahasa
Pemilihan model penyelarasan otomatis berdasarkan deteksi bahasa
Penggunaan ular piton
Menggabungkan diarisasi pembicara
Model flush, untuk sumber daya mem GPU yang rendah
Backend berbisik lebih cepat
Tambahkan max-line dll. lihat (bisikan openai utils.py)
Segmen tingkat kalimat (nltk toolbox)
Meningkatkan logika penyelarasan
perbarui contoh dengan diarisasi dan penyorotan kata
Output subtitle .ass <- bawa ini kembali (dihapus di v3)
Tambahkan kode benchmarking (TEDLIUM untuk spd/WER & segmentasi kata)
Izinkan silero-vad sebagai opsi VAD alternatif
Meningkatkan diarisasi (tingkat kata). Lebih sulit dari perkiraan pertama...
Hubungi [email protected] untuk pertanyaan.
Karya ini, dan PhD saya, didukung oleh VGG (Visual Geometry Group) dan Universitas Oxford.
Tentu saja, ini dibangun berdasarkan bisikan openAI. Meminjam kode penyelarasan penting dari tutorial PyTorch tentang penyelarasan paksa Dan menggunakan pyannote VAD / Diarisasi yang luar biasa https://github.com/pyannote/pyannote-audio
Model VAD & Diarisasi yang Berharga dari [pyannote audio][https://github.com/pyannote/pyannote-audio]
Backend yang bagus dari fast-whisper dan CTranslate2
Mereka yang telah mendukung pekerjaan ini secara finansial
Terakhir, terima kasih kepada kontributor OS proyek ini, yang menjaganya tetap berjalan dan mengidentifikasi bug.
@article { bain2022whisperx ,
title = { WhisperX: Time-Accurate Speech Transcription of Long-Form Audio } ,
author = { Bain, Max and Huh, Jaesung and Han, Tengda and Zisserman, Andrew } ,
journal = { INTERSPEECH 2023 } ,
year = { 2023 }
}

