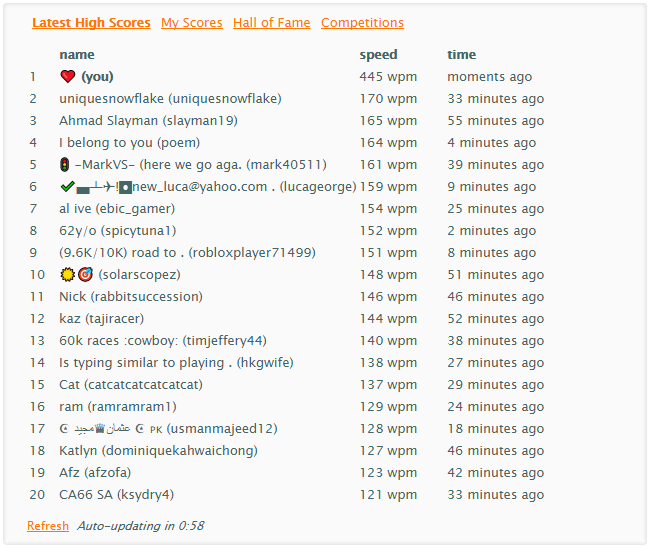
Repo ini berisi skrip yang saya gunakan untuk mengalahkan game mengetik online, menduduki puncak papan peringkat dengan WPM yang tidak manusiawi hampir 450.
Saya tidak menyarankan penggunaan skrip ini pada typeracer, ini melanggar TOS (akun Anda akan diblokir, seperti akun saya) dan mencemari papan peringkat untuk pemain sungguhan lainnya. Sebaliknya, saya menganggap proyek ini hanya sebagai eksperimen dan pengalaman pembelajaran yang menarik.
Bagi siapa pun yang penasaran, saya telah menguraikan setiap langkah prosesnya di bawah ini. Perhatikan bahwa metode khusus ini mungkin tidak lagi berfungsi di masa mendatang karena typeracer mungkin (dan harus) mengubah prosedur validasi pengguna. Saya dapat mengonfirmasi bahwa skrip ini berfungsi mulai 16-02-2020.
Sebenarnya mengetik balapan secara otomatis semudah mengekstraksi teks dari DOM dan mengirimkan rangkaian peristiwa penting JavaScript yang tepat.
Meskipun kecepatan balapan Anda ditentukan oleh interval waktu antara penekanan tombol palsu (yang bisa sangat rendah), tampaknya jika suatu saat WPM Anda melampaui 450, Anda akan dikeluarkan dari permainan. Jadi ada batas atas WPM yang dapat diperoleh skrip. Untuk mencapai 445 WPM (tertinggi yang bisa saya dapatkan), penekanan tombol dipisahkan oleh interval waktu acak antara 22,5 md dan 26,5 md.
Setelah WPM yang cukup tinggi (>100) Anda disajikan dengan captcha gambar yang tidak memiliki bentuk tekstual murni di mana pun di sisi klien - inilah tantangan sebenarnya.
Untuk memvalidasi skor Anda, Anda harus dapat menyelesaikan captcha dalam waktu tertentu dan dengan akurasi yang cukup tinggi (~95% atau lebih tinggi). Captcha selalu berisi 5 baris teks melengkung (miring dan sinusoidal), dengan tanda hitam menutupi gambar.

Captcha yang khas
Proses pengisian captcha relatif panjang, berantakan, probabilistik, spekulatif, dan manual, namun hanya perlu diselesaikan satu kali saja, sehingga saya tidak berniat menyederhanakan prosesnya.
Sebelum membaca gambar, skrip melakukan beberapa pra-pemrosesan menggunakan kanvas HTML sementara untuk memudahkan pengenalan teks. Secara khusus, gambar dipindai untuk mencari piksel apa pun yang cukup gelap sehingga berpotensi menjadi bagian dari tanda hitam. Ketika sebuah piksel ditemukan, piksel tersebut diubah untuk mewakili warna yang sama dengan latar belakang pada titik tersebut dalam gambar.

Gambar captcha yang sama setelah pra-pemrosesan
Setelah prosedur ini diterapkan, saya juga berusaha membalikkan efek lengkungan sinisoidal. Hal ini cukup efektif dalam meningkatkan keterbacaan gambar tertentu, namun periode efek pembengkokan sebenarnya bervariasi beberapa piksel antar gambar. Bahkan menerapkan efek offset beberapa piksel secara signifikan mengurangi keterbacaan di akhir gambar karena gelombang menjadi keluar fase. Jadi, saya memutuskan untuk menghapus bagian pra-pemrosesan ini.
Langkah selanjutnya adalah mengirimkan gambar pra-proses yang telah kita buat ke perpustakaan OCR (Optical Character Recognition) yang disebut Tesseract. Untuk mengizinkan seluruh skrip berjalan di dalam browser, skrip menggunakan port JS dari perpustakaan yang tersedia di sini.
Setelah beberapa detik, Tesseract akan mengembalikan potongan teks dengan akurasi biasanya antara 65% dan 85%.
Analisis teks yang dikembalikan oleh Tesseract mengungkapkan beberapa kesalahan umum yang dapat saya balikkan secara manual dengan beberapa manipulasi string.
Ini terdiri dari berbagai pergantian karakter seperti
Setelah langkah sebelumnya selesai, teks dimasukkan ke dalam kotak teks yang digunakan untuk melengkapi captcha. Pada titik ini, akurasi teks masih belum cukup tinggi untuk lolos captcha, namun masih ada waktu untuk melakukan pengeditan manual dengan waktu luang sekitar 3-5 detik.
Untuk membantu proses ini, kesalahan ejaan sederhana dapat dengan mudah diperbaiki menggunakan pemeriksa ejaan bawaan browser (klik kanan, pilih kata yang disarankan dari daftar).
Dengan menerapkan semua langkah ini, saya hanya perlu sekitar setengah lusin kali mencoba untuk mendapatkan akurasi yang memuaskan captcha.