LARS
v2.0-beta8:

LARS adalah aplikasi yang memungkinkan Anda menjalankan LLM (Model Bahasa Besar) secara lokal di perangkat Anda, mengunggah dokumen Anda sendiri, dan terlibat dalam percakapan yang menjadikan LLM mendasarkan tanggapannya pada konten yang Anda unggah. Landasan ini membantu meningkatkan akurasi dan mengurangi masalah umum berupa ketidakakuratan atau "halusinasi" yang disebabkan oleh AI. Teknik ini umumnya dikenal sebagai "Retrieval Augmented Generation", atau RAG.
Ada banyak aplikasi desktop untuk menjalankan LLM secara lokal, dan LARS bertujuan untuk menjadi aplikasi LLM sumber terbuka utama yang berpusat pada RAG. Untuk mencapai tujuan ini, LARS membawa konsep RAG lebih jauh lagi dengan menambahkan kutipan terperinci pada setiap jawaban, memberi Anda nama dokumen spesifik, nomor halaman, penyorotan teks, dan gambar yang relevan dengan pertanyaan Anda, dan bahkan menghadirkan pembaca dokumen langsung di dalam jawaban. jendela respons. Meskipun semua kutipan tidak selalu ada untuk setiap respons, idenya adalah untuk memunculkan setidaknya beberapa kombinasi kutipan untuk setiap respons RAG dan hal tersebut umumnya terjadi.
Video Demonstrasi Fitur LARS
Python v3.10.x atau lebih tinggi: https://www.python.org/downloads/
Obor Py:
Jika Anda berencana menggunakan GPU untuk menjalankan LLM, pastikan untuk menginstal driver GPU dan toolkit CUDA/ROCm yang sesuai untuk pengaturan Anda, dan baru kemudian lanjutkan dengan pengaturan PyTorch di bawah
Unduh dan instal versi PyTorch yang sesuai untuk sistem Anda: https://pytorch.org/get-started/locally/
Kloning repositori:
git clone https://github.com/abgulati/LARS
cd LARS
GitHub Settings -> Developer settings (located on the bottom left!) -> Personal access tokensInstal dependensi Python:
Windows melalui PIP:
pip install -r .requirements.txt
Linux melalui PIP:
pip3 install -r ./requirements.txt
Catatan tentang Azure: Beberapa perpustakaan Azure yang diperlukan TIDAK tersedia di platform MacOS! Oleh karena itu, file persyaratan terpisah disertakan untuk MacOS, tidak termasuk pustaka berikut:
macOS:
pip3 install -r ./requirements_mac.txt
Kembali ke Daftar Isi
Setelah menginstal, jalankan LARS menggunakan:
cd web_app
python app.py # Use 'python3' on Linux/macOS
Navigasikan ke http://localhost:5000/ di browser Anda
Semua direktori aplikasi yang diperlukan oleh LARS sekarang akan dibuat pada disk
Server HF-Waitress akan secara otomatis memulai dan akan mengunduh LLM (Microsoft Phi-3-Mini-Instruct-44) saat pertama kali dijalankan, yang mungkin memakan waktu cukup lama tergantung pada kecepatan koneksi internet Anda
Pada kueri pertama, model penyematan (all-mpnet-base-v2) akan diunduh dari HuggingFace Hub, yang akan memakan waktu singkat
Kembali ke Daftar Isi
Di Windows:
Unduh Microsoft Visual Studio Build Tools 2022 dari Situs Resmi - "Alat untuk Visual Studio"
CATATAN: Saat memasang di atas, pastikan untuk memilih komponen berikut:
Desktop development with C++
# Then from the "Optional" category on the right, make sure to select the following:
MSVC C++ x64/x86 build tools
C++ CMake tools for Windows
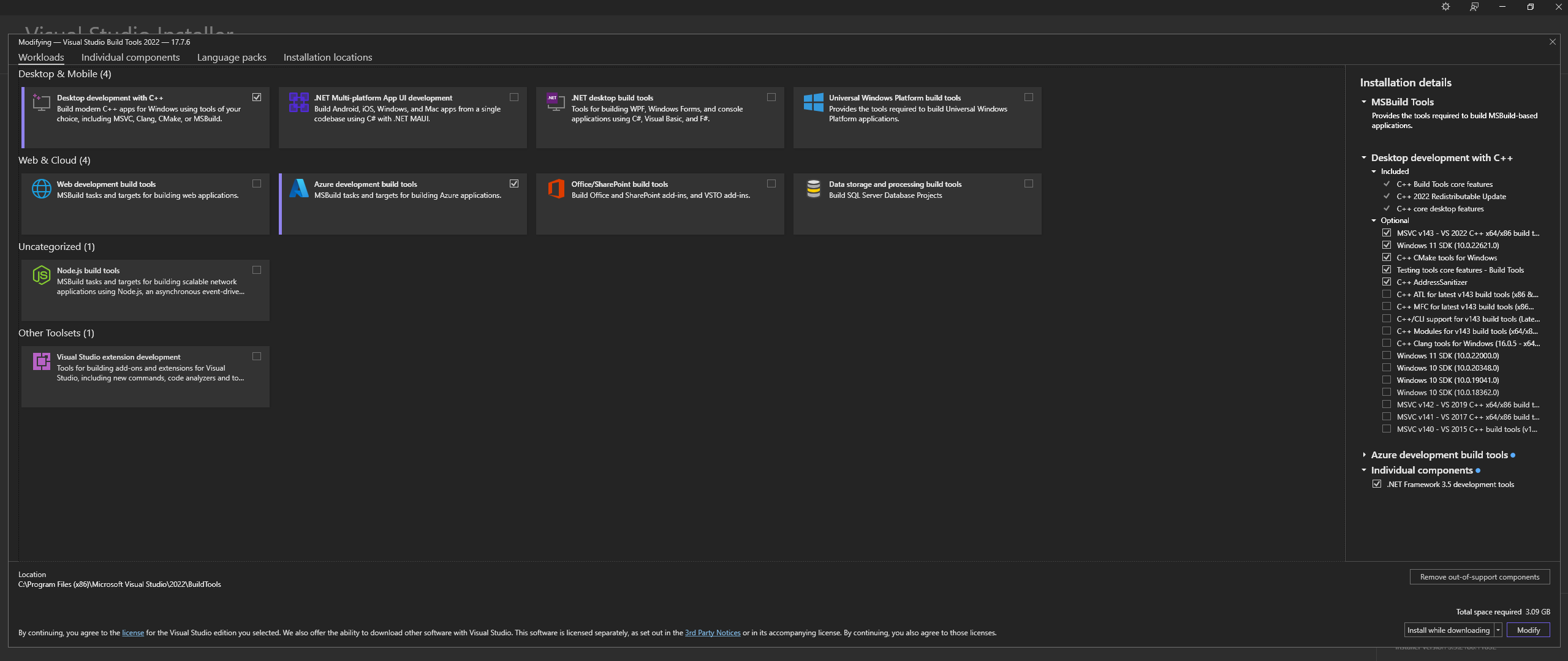
Desktop development with C++ dan Opsional MSVC and C++ CMake dipilih seperti diuraikan di atasDi Linux (berbasis Ubuntu dan Debian), instal paket berikut:
sudo apt-get update
sudo apt-get install -y software-properties-common build-essential libffi-dev libssl-dev cmake
Unduh dari Repo Resmi:
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
Instal CMAKE di Windows dari Situs Resmi
C:Program FilesCMakebinBangun llama.cpp dengan CMAKE:
Catatan: Untuk kompilasi yang lebih cepat, tambahkan argumen -j untuk menjalankan beberapa pekerjaan secara paralel. Misalnya, cmake --build build --config Release -j 8 akan menjalankan 8 pekerjaan secara paralel.
Bangun dengan CUDA:
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES="52;61;70;75;80;86"
cmake --build build --config Release
cmake -B build
cmake --build build --config Release
Jika Anda menghadapi masalah saat mencoba menjalankan CMake -B build , periksa langkah-langkah Pemecahan Masalah Instalasi CMake yang ekstensif di bawah ini
Tambahkan ke JALUR:
path_to_cloned_repollama.cppbuildbinRelease
Verifikasi Instalasi melalui terminal:
llama-server
Instal Driver GPU Nvidia
Instal Nvidia CUDA Toolkit - LARS dibuat dan diuji dengan v12.2 dan v12.4
Verifikasi Instalasi melalui terminal:
nvcc -V
nvidia-smi
Perbaikan CMAKE-CUDA (Sangat Penting!):
Salin keempat file dari direktori berikut:
C:Program FilesNVIDIA GPU Computing ToolkitCUDAv12.2extrasvisual_studio_integrationMSBuildExtensions
dan Tempelkan ke direktori berikut:
C:Program Files (x86)Microsoft Visual Studio2022BuildToolsMSBuildMicrosoftVCv170BuildCustomizations
Ini adalah ketergantungan opsional, namun sangat disarankan - Hanya PDF yang didukung jika pengaturan ini tidak selesai
jendela:
Unduh dari Situs Resmi
Tambahkan ke PATH, baik melalui:
Pengaturan Sistem Lanjutan -> Variabel Lingkungan -> Variabel Sistem -> EDIT Variabel PATH -> Tambahkan di bawah ini (ubah sesuai lokasi instalasi Anda):
C:Program FilesLibreOfficeprogram
Atau melalui PowerShell:
Set PATH=%PATH%;C:Program FilesLibreOfficeprogram
Linux berbasis Ubuntu & Debian - Unduh dari Situs Resmi atau instal melalui terminal:
sudo apt-get update
sudo apt-get install -y libreoffice
Fedora dan distro berbasis RPM lainnya - Unduh dari Situs Resmi atau instal melalui terminal:
sudo dnf update
sudo dnf install libreoffice
MacOS - Unduh dari Situs Resmi atau instal melalui Homebrew:
brew install --cask libreoffice
Verifikasi Instalasi:
Di Windows dan MacOS: Jalankan aplikasi LibreOffice
Di Linux melalui terminal:
libreoffice --version
LARS menggunakan pustaka Python pdf2image untuk mengonversi setiap halaman dokumen menjadi gambar seperti yang diperlukan untuk OCR. Perpustakaan ini pada dasarnya adalah pembungkus utilitas Poppler yang menangani proses konversi.
jendela:
Unduh dari Repo Resmi
Tambahkan ke PATH, baik melalui:
Pengaturan Sistem Lanjutan -> Variabel Lingkungan -> Variabel Sistem -> EDIT Variabel PATH -> Tambahkan di bawah ini (ubah sesuai lokasi instalasi Anda):
path_to_installationpoppler_versionLibrarybin
Atau melalui PowerShell:
Set PATH=%PATH%;path_to_installationpoppler_versionLibrarybin
Linux:
sudo apt-get update
sudo apt-get install -y poppler-utils wget
Ini adalah ketergantungan opsional - Tesseract-OCR tidak digunakan secara aktif di LARS tetapi metode untuk menggunakannya ada dalam kode sumber
jendela:
Unduh Tesseract-OCR untuk Windows melalui UB-Mannheim
Tambahkan ke PATH, baik melalui:
Pengaturan Sistem Lanjutan -> Variabel Lingkungan -> Variabel Sistem -> EDIT Variabel PATH -> Tambahkan di bawah ini (ubah sesuai lokasi instalasi Anda):
C:Program FilesTesseract-OCR
Atau melalui PowerShell:
Set PATH=%PATH%;C:Program FilesTesseract-OCR
Kembali ke Daftar Isi
LARS telah dibuat dan diuji dengan Python v3.11.x
Instal Python v3.11.x di Windows:
Unduh v3.11.9 dari Situs Resmi
Selama instalasi, pastikan Anda mencentang "Tambahkan Python 3.11 ke PATH" atau menambahkannya secara manual nanti, baik melalui:
Pengaturan Sistem Lanjutan -> Variabel Lingkungan -> Variabel Sistem -> EDIT Variabel PATH -> Tambahkan di bawah ini (ubah sesuai lokasi instalasi Anda):
C:Usersuser_nameAppDataLocalProgramsPythonPython311
Atau melalui PowerShell:
Set PATH=%PATH%;C:Usersuser_nameAppDataLocalProgramsPythonPython311
Instal Python v3.11.x di Linux (berbasis Ubuntu dan Debian):
sudo add-apt-repository ppa:deadsnakes/ppa -y
sudo apt-get update
sudo apt-get install -y python3.11 python3.11-venv python3.11-dev
sudo python3.11 -m ensurepip
Verifikasi Instalasi melalui terminal:
python3 --version
Jika Anda mengalami kesalahan dengan pip install , coba yang berikut ini:
Hapus nomor versi:
==version.number , misalnya:urllib3==2.0.4urllib3Membuat dan menggunakan lingkungan virtual Python:
Disarankan untuk menggunakan lingkungan virtual untuk menghindari konflik dengan proyek Python lainnya
jendela:
Buat lingkungan virtual Python (venv):
python -m venv larsenv
Aktifkan, dan selanjutnya gunakan, venv:
.larsenvScriptsactivate
Nonaktifkan venv setelah selesai:
deactivate
Linux dan MacOS:
Buat lingkungan virtual Python (venv):
python3 -m venv larsenv
Aktifkan, dan selanjutnya gunakan, venv:
source larsenv/bin/activate
Nonaktifkan venv setelah selesai:
deactivate
Jika masalah terus berlanjut, pertimbangkan untuk membuka masalah di repositori LARS GitHub untuk mendapatkan dukungan.
CMake nmake failed saat mencoba membangun llama.cpp seperti di bawah ini: 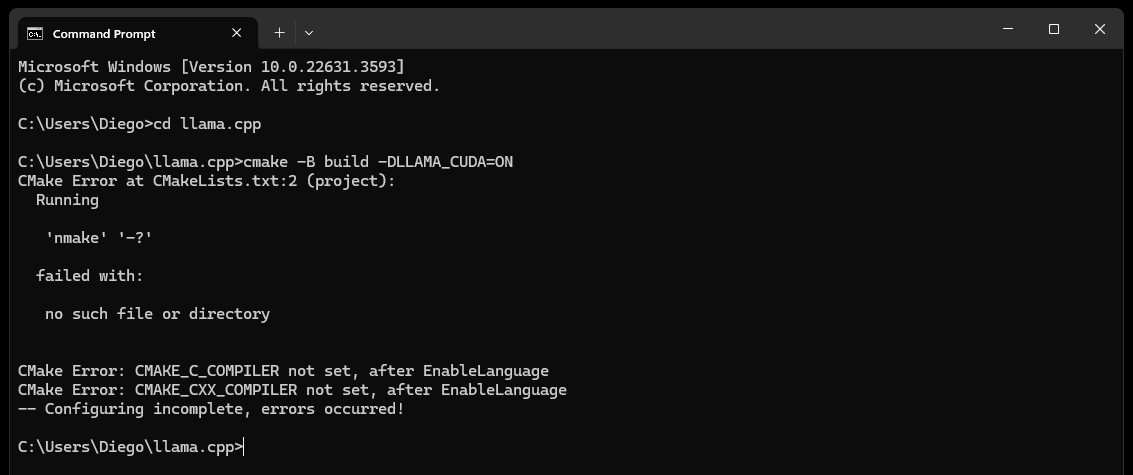
Hal ini biasanya menunjukkan masalah dengan alat pembangunan Microsoft Visual Studio Anda, karena CMake tidak dapat menemukan alat nmake, yang merupakan bagian dari alat pembangunan Microsoft Visual Studio. Coba langkah-langkah di bawah ini untuk mengatasi masalah ini:
Pastikan Alat Pembuatan Visual Studio Diinstal:
Pastikan Anda telah menginstal alat pembuatan Visual Studio, termasuk nmake. Anda dapat menginstal alat ini melalui Penginstal Visual Studio dengan memilih Desktop development with C++ , dan Opsional MSVC and C++ CMake
Periksa Langkah 0 pada bagian Dependensi, khususnya tangkapan layar di dalamnya
Periksa Variabel Lingkungan:
C:Program Files (x86)Microsoft Visual Studio2019CommunityVCAuxiliaryBuild
C:Program Files (x86)Microsoft Visual Studio2019CommunityCommon7IDE
C:Program Files (x86)Microsoft Visual Studio2019CommunityCommon7Tools
Gunakan Prompt Perintah Pengembang:
Buka "Prompt Perintah Pengembang untuk Visual Studio" yang menyiapkan variabel lingkungan yang diperlukan untuk Anda
Anda dapat menemukan prompt ini dari menu Start di bawah Visual Studio
Setel Generator CMake:
cmake -G "NMake Makefiles" -B build -DLLAMA_CUDA=ON
Jika masalah terus berlanjut, pertimbangkan untuk membuka masalah di repositori LARS GitHub untuk mendapatkan dukungan.
Akhirnya (setelah sekitar 60 detik) Anda akan melihat peringatan di halaman yang menunjukkan kesalahan:
Failed to start llama.cpp local-server
Hal ini menunjukkan bahwa proses pertama telah selesai, semua direktori aplikasi telah dibuat, namun tidak ada LLM yang ada di direktori models dan sekarang dapat dipindahkan ke direktori tersebut.
Pindahkan LLM Anda (format file apa pun yang didukung oleh llama.cpp, sebaiknya GGUF) ke direktori models yang baru dibuat, yang secara default terletak di lokasi berikut:
C:/web_app_storage/models/app/storage/models/app/models Setelah Anda menempatkan LLM Anda di direktori models yang sesuai di atas, segarkan http://localhost:5000/
Anda akan sekali lagi menerima peringatan kesalahan yang menyatakan Failed to start llama.cpp local-server setelah sekitar 60 detik
Ini karena LLM Anda sekarang perlu dipilih di menu Settings LARS
Terima peringatannya dan klik ikon roda gigi Settings di kanan atas
Di tab LLM Selection , pilih LLM Anda dan format Prompt-Template yang sesuai dari dropdown yang sesuai
Ubah Pengaturan Lanjutan untuk mengatur dengan benar opsi GPU , Context-Length , dan secara opsional, batas pembuatan token ( Maximum tokens to predict ) untuk LLM yang Anda pilih
Tekan Save dan jika penyegaran otomatis tidak terpicu, segarkan halaman secara manual
Jika semua langkah telah dijalankan dengan benar, pengaturan pertama kali telah selesai, dan LARS siap digunakan
LARS juga akan mengingat pengaturan LLM Anda untuk penggunaan selanjutnya
Kembali ke Daftar Isi
Format Dokumen yang Didukung:
Jika LibreOffice diinstal dan ditambahkan ke PATH seperti yang dirinci pada Langkah 4 di bagian Dependensi, format berikut ini didukung:
Jika LibreOffice tidak diatur, hanya PDF yang didukung
Opsi OCR untuk Ekstraksi Teks:
LARS menyediakan tiga metode untuk mengekstraksi teks dari dokumen, mengakomodasi berbagai jenis dan kualitas dokumen:
Ekstraksi Teks Lokal: Menggunakan PyPDF2 untuk ekstraksi teks yang efisien dari PDF yang tidak dipindai. Ideal untuk pemrosesan cepat ketika akurasi tinggi tidak penting, atau pemrosesan lokal sepenuhnya diperlukan.
Azure ComputerVision OCR - Meningkatkan akurasi ekstraksi teks dan mendukung dokumen yang dipindai. Berguna untuk menangani tata letak dokumen standar. Menawarkan tingkat gratis yang cocok untuk uji coba awal dan penggunaan volume rendah, dibatasi hingga 5.000 transaksi/bulan dengan 20 transaksi/menit.
Azure AI Document Intelligence OCR - Terbaik untuk dokumen dengan struktur kompleks seperti tabel. Parser khusus di LARS mengoptimalkan proses ekstraksi.
CATATAN:
Opsi Azure OCR di sebagian besar kasus menimbulkan biaya API dan tidak dipaketkan dengan LARS.
Tingkat gratis terbatas untuk ComputerVision OCR tersedia seperti yang ditautkan di atas. Layanan ini secara keseluruhan lebih murah tetapi lebih lambat dan mungkin tidak berfungsi untuk tata letak dokumen non-standar (selain A4 dll).
Pertimbangkan jenis dokumen dan kebutuhan akurasi Anda saat memilih opsi OCR.
LLM:
Hanya LLM lokal yang saat ini didukung
Menu Settings menyediakan banyak pilihan bagi pengguna listrik untuk mengkonfigurasi dan mengubah LLM melalui tab LLM Selection
Catatan jika menggunakan llama.cpp: Sangat Penting: Pilih format template prompt yang sesuai untuk LLM yang Anda jalankan
LLM yang dilatih untuk format templat cepat berikut saat ini didukung melalui llama.cpp:
Sesuaikan pengaturan konfigurasi Inti melalui Advanced Settings (memicu pemuatan ulang LLM dan penyegaran halaman):
Sesuaikan pengaturan untuk mengubah perilaku respons kapan saja:
Menyematkan model dan Database Vektor:
Empat model penyematan disediakan di LARS:
Kecuali penyematan Azure-OpenAI, semua model lainnya berjalan sepenuhnya secara lokal dan gratis. Saat pertama kali dijalankan, model ini akan diunduh dari HuggingFace Hub. Ini adalah pengunduhan satu kali dan selanjutnya akan hadir secara lokal.
Pengguna dapat beralih di antara model penyematan ini kapan saja melalui tab VectorDB & Embedding Models di menu Settings
Tabel yang Dimuat Dokumen: Di menu Settings , sebuah tabel ditampilkan untuk model penyematan yang dipilih yang menampilkan daftar dokumen yang disematkan ke database vektor terkait. Jika dokumen dimuat beberapa kali, dokumen tersebut akan memiliki beberapa entri dalam tabel ini, yang dapat berguna untuk men-debug masalah apa pun.
Menghapus VectorDB: Gunakan tombol Reset dan berikan konfirmasi untuk menghapus database vektor yang dipilih. Tindakan ini akan membuat vectorDB baru pada disk untuk model penyematan yang dipilih. VectorDB lama masih dipertahankan dan dapat dikembalikan dengan memodifikasi file config.json secara manual.
Edit Perintah Sistem:
System-Prompt berfungsi sebagai instruksi kepada LLM untuk keseluruhan percakapan
LARS memberi pengguna kemampuan untuk mengedit System-Prompt melalui menu Settings dengan memilih opsi Custom dari dropdown di tab System Prompt
Perubahan pada System-Prompt akan memulai obrolan baru
Paksa Aktifkan/Nonaktifkan RAG:
Melalui menu Settings , pengguna dapat mengaktifkan atau menonaktifkan paksa RAG (Retrieval Augmented Generation – penggunaan konten dari dokumen Anda untuk meningkatkan respons yang dihasilkan LLM) kapan pun diperlukan
Hal ini sering berguna untuk tujuan mengevaluasi tanggapan LLM di kedua skenario
Menonaktifkan paksa juga akan menonaktifkan fitur atribusi
Pengaturan default, yang menggunakan NLP untuk menentukan kapan RAG harus dan tidak boleh dilakukan, adalah opsi yang disarankan
Pengaturan ini dapat diubah kapan saja
Riwayat Obrolan:
Gunakan menu riwayat obrolan di kiri atas untuk menelusuri dan melanjutkan percakapan sebelumnya
Sangat-Penting: Berhati-hatilah terhadap ketidakcocokan templat saat melanjutkan percakapan sebelumnya! Gunakan ikon Information di kanan atas untuk memastikan LLM yang digunakan dalam percakapan sebelumnya, dan LLM yang sedang digunakan, keduanya didasarkan pada format templat cepat yang sama!
Peringkat pengguna:
Setiap respons dapat dinilai pada skala 5 poin oleh pengguna kapan saja
Data peringkat disimpan dalam database chat-history.db SQLite3 yang terletak di direktori aplikasi:
C:/web_app_storage/app/storage/appData pemeringkatan sangat berharga untuk evaluasi dan penyempurnaan alat untuk alur kerja Anda
Anjuran dan Larangan:
Kembali ke Daftar Isi
Jika obrolan berjalan kacau, atau ada respons aneh yang muncul, coba mulai New Chat melalui menu di kiri atas
Alternatifnya, mulai obrolan baru hanya dengan menyegarkan halaman
Jika ada masalah dengan kutipan atau kinerja RAG, coba atur ulang vectorDB seperti yang dijelaskan pada Langkah 4 Panduan Pengguna Umum di atas
Jika ada masalah aplikasi yang muncul dan tidak terselesaikan hanya dengan memulai obrolan baru atau memulai ulang LARS, coba hapus file config.json dengan mengikuti langkah-langkah di bawah ini:
CTRL+Cconfig.json yang terletak di LARS/web_app (direktori yang sama dengan app.py )Untuk masalah data dan kutipan parah apa pun yang tidak terselesaikan bahkan dengan mengatur ulang VectorDB seperti yang dijelaskan pada Langkah 4 Panduan Pengguna Umum di atas, lakukan langkah-langkah berikut:
CTRL+CC:/web_app_storage/app/storage/appJika masalah terus berlanjut, pertimbangkan untuk membuka masalah di repositori LARS GitHub untuk mendapatkan dukungan.
Kembali ke Daftar Isi
LARS telah diadaptasi ke lingkungan penerapan container Docker melalui dua gambar terpisah seperti di bawah ini:
Keduanya memiliki persyaratan yang berbeda, dengan penerapan yang lebih sederhana, namun kinerja inferensinya jauh lebih lambat karena CPU dan memori DDR bertindak sebagai penghambat.
Meskipun tidak diwajibkan secara eksplisit, beberapa pengalaman dengan container Docker dan pemahaman tentang konsep containerisasi dan virtualisasi akan sangat membantu di bagian ini!
Dimulai dengan langkah-langkah penyiapan umum untuk keduanya:
Menginstal Docker
CPU Anda harus mendukung virtualisasi dan harus diaktifkan di BIOS/UEFI sistem Anda
Unduh dan instal Docker Desktop
Jika di Windows, Anda mungkin perlu menginstal Subsistem Windows untuk Linux jika belum ada. Untuk melakukannya, buka PowerShell sebagai Administrator dan jalankan perintah berikut:
wsl --install
Pastikan Docker Desktop aktif dan berjalan, lalu buka Command Prompt/Terminal dan jalankan perintah berikut untuk memastikan Docker diinstal dan berjalan dengan benar:
docker ps
Buat volume penyimpanan Docker, yang akan dilampirkan ke kontainer LARS saat runtime:
Membuat volume penyimpanan untuk digunakan dengan wadah LARS sangat menguntungkan karena memungkinkan Anda meningkatkan wadah LARS ke versi yang lebih baru, atau beralih antara varian wadah CPU & GPU sambil mempertahankan semua pengaturan, riwayat obrolan, dan basis data vektor dengan lancar .
Jalankan perintah berikut di Command Prompt/Terminal:
docker volume create lars_storage_volue
Volume ini akan dilampirkan ke kontainer LARS nanti saat runtime, untuk saat ini lanjutkan membuat image LARS dalam langkah-langkah di bawah ini.
Di Command Prompt/Terminal, jalankan perintah berikut:
git clone https://github.com/abgulati/LARS # skip if already done
cd LARS # skip if already done
cd dockerized
docker build -t lars-no-gpu .
# Once the build is complete, run the container:
docker run -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-no-gpu
Setelah selesai, Navigasikan ke http://localhost:5000/ di browser Anda dan ikuti sisa Langkah Pengoperasian Pertama dan Panduan Pengguna
Bagian Pemecahan Masalah juga berlaku untuk Container-LARS
Persyaratan (selain Docker):
Compatible Nvidia GPU(s)
Nvidia GPU drivers
Nvidia CUDA Toolkit v12.2
Untuk Linux, Anda sudah siap dengan hal di atas, jadi lewati langkah berikutnya dan langsung menuju ke langkah membangun dan menjalankan lebih jauh di bawah
Jika menggunakan Windows, dan jika ini adalah pertama kalinya Anda menjalankan wadah GPU Nvidia di Docker, bersiaplah karena ini akan menjadi perjalanan yang menyenangkan (atau tiga minuman favorit sangat disarankan!)
Mempertaruhkan redundansi yang ekstrim, sebelum melanjutkan, pastikan dependensi berikut ada:
Compatible Nvidia GPU(s)
Nvidia GPU drivers
Nvidia CUDA Toolkit v12.2
Docker Desktop
Windows Subsystem for Linux (WSL)
Lihat bagian Ketergantungan Nvidia CUDA dan bagian Pengaturan Docker di atas jika tidak yakin
Jika hal di atas ada dan sudah diatur, Anda dapat melanjutkan
Buka aplikasi Microsoft Store di PC Anda, lalu unduh & instal Ubuntu 22.04.3 LTS (harus sesuai dengan versi pada baris 2 di dockerfile)
Ya, Anda membaca kanan atas: unduh dan instal Ubuntu dari aplikasi toko Microsoft, lihat tangkapan layar di bawah:
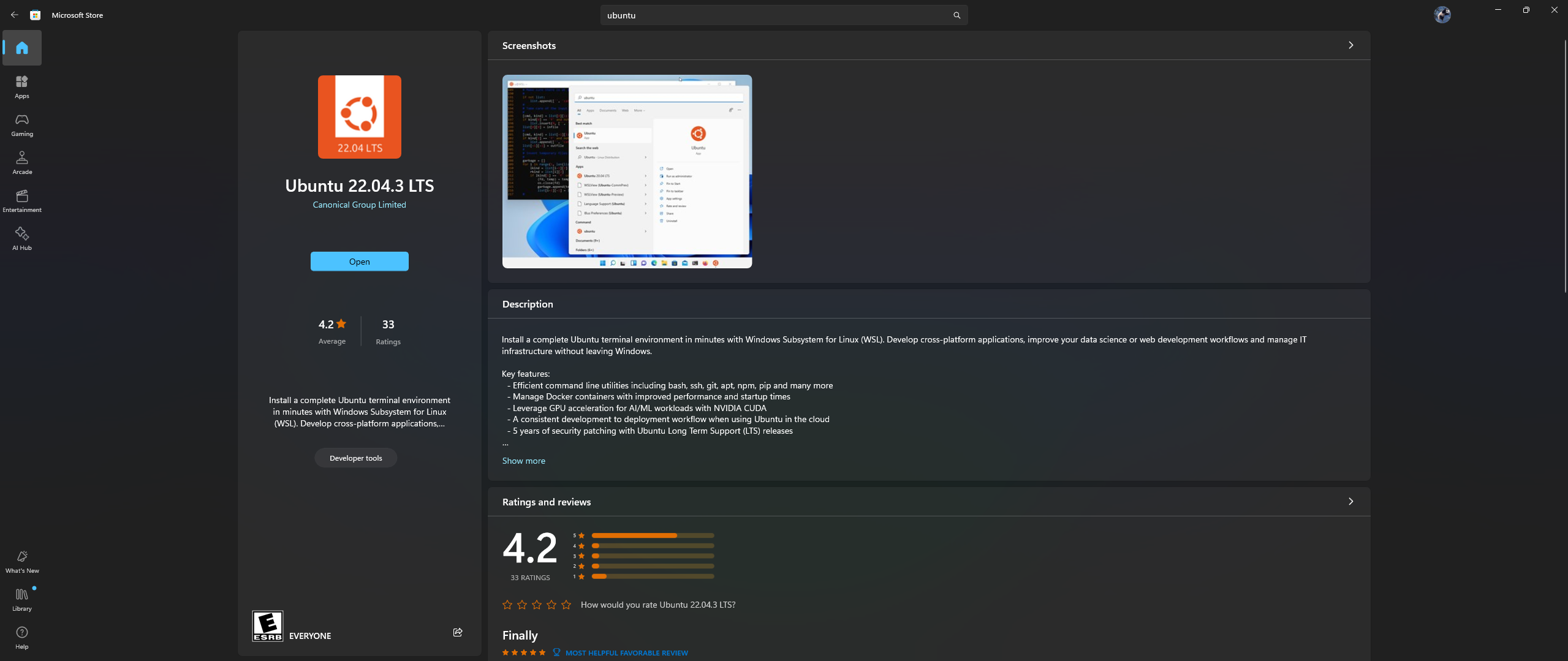
Sekarang saatnya menginstal Nvidia Container Toolkit di Ubuntu, ikuti langkah-langkah di bawah ini untuk melakukannya:
Luncurkan shell Ubuntu di Windows dengan mencari Ubuntu di menu Start setelah instalasi di atas selesai
Di baris perintah Ubuntu yang terbuka, lakukan langkah-langkah berikut:
Konfigurasikan repositori produksi:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list |
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' |
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
Perbarui daftar paket dari repositori & Instal Paket Nvidia Container Toolkit:
sudo apt-get update && apt-get install -y nvidia-container-toolkit
Konfigurasikan runtime container dengan menggunakan perintah nvidia-ctk, yang memodifikasi file /etc/docker/daemon.json sehingga Docker dapat menggunakan Nvidia Container Runtime:
sudo nvidia-ctk runtime configure --runtime=docker
Mulai ulang daemon Docker:
sudo systemctl restart docker
Sekarang pengaturan Ubuntu Anda selesai, saatnya menyelesaikan Integrasi WSL dan Docker:
Buka jendela PowerShell baru dan atur instalasi Ubuntu ini sebagai default WSL:
wsl --list
wsl --set-default Ubuntu-22.04 # if not already marked as Default
Arahkan ke Docker Desktop -> Settings -> Resources -> WSL Integration -> Periksa integrasi Default & Ubuntu 22.04. Lihat tangkapan layar di bawah ini:
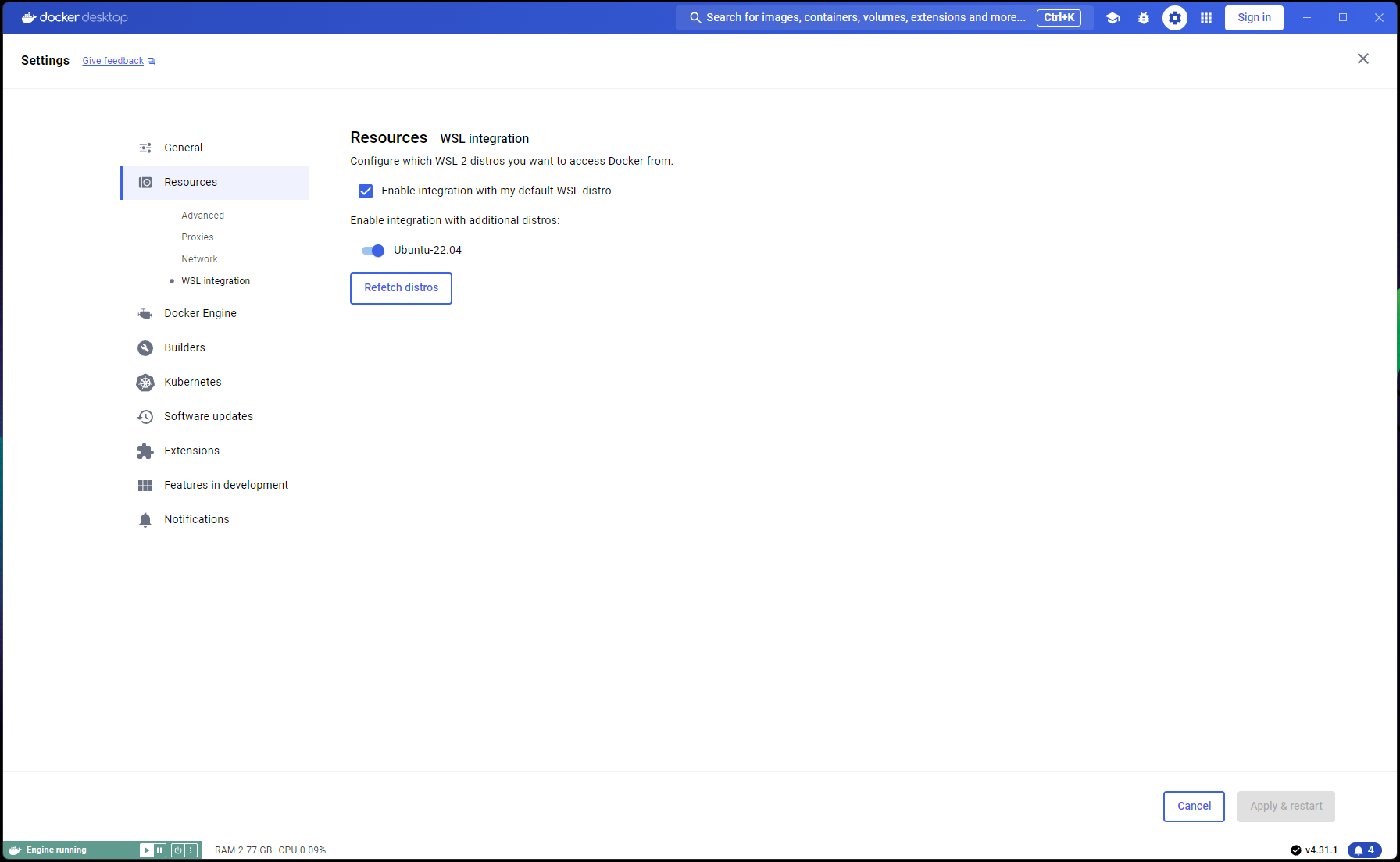
Sekarang jika semuanya telah dilakukan dengan benar, Anda siap untuk membangun dan menjalankan container!
Di Command Prompt/Terminal, jalankan perintah berikut:
git clone https://github.com/abgulati/LARS # skip if already done
cd LARS # skip if already done
cd dockerized_nvidia_cuda_gpu
docker build -t lars-nvcuda .
# Once the build is complete, run the container:
docker run --gpus all -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-nvcuda
Setelah selesai, Navigasikan ke http://localhost:5000/ di browser Anda dan ikuti sisa Langkah Pengoperasian Pertama dan Panduan Pengguna
Bagian Pemecahan Masalah juga berlaku untuk Container-LARS
Jika Anda mengalami kesalahan terkait Jaringan, terutama yang berkaitan dengan repositori paket yang tidak tersedia saat membangun kontainer, ini adalah masalah jaringan di pihak Anda yang sering kali berkaitan dengan masalah Firewall
Di Windows, navigasikan ke Control PanelSystem and SecurityWindows Defender FirewallAllowed apps , atau cari Firewall di Start-Menu dan buka Allow an app through the firewall dan pastikan ```Docker Desktop Backend`` diizinkan melalui
Saat pertama kali Anda menjalankan LARS, model penyematan pengubah kalimat akan diunduh
Di lingkungan dalam container, pengunduhan ini terkadang dapat menimbulkan masalah dan mengakibatkan kesalahan saat Anda mengajukan pertanyaan
Jika ini terjadi, cukup buka menu Pengaturan LARS: Settings->VectorDB & Embedding Models dan ubah Model Penyematan menjadi BGE-Base atau BGE-Large, ini akan memaksa memuat ulang dan mengunduh ulang
Setelah selesai, lanjutkan untuk mengajukan pertanyaan lagi dan responsnya akan muncul seperti biasa
Anda dapat beralih kembali ke model penyematan pengubah kalimat dan masalah ini akan teratasi
Sebagaimana dinyatakan dalam bagian Pemecahan Masalah di atas, model penyematan diunduh saat LARS pertama kali dijalankan
Yang terbaik adalah menyimpan status penampung sebelum mematikannya sehingga langkah pengunduhan ini tidak perlu diulangi setiap kali penampung diluncurkan lagi.
Untuk melakukannya, buka Command Prompt/Terminal lain dan lakukan perubahan SEBELUM menutup container LARS yang sedang berjalan:
docker ps # note the container_id here
docker commit <container_ID> <new_image_name> # for new_image_name, I simply add 'pfr', for 'post-first-run' to the current image name, example: lars-nvcuda-pfr
Ini akan membuat gambar yang diperbarui yang dapat Anda gunakan pada proses berikutnya:
docker run --gpus all -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-nvcuda-pfr
CATATAN: Setelah melakukan hal di atas, jika Anda memeriksa ruang yang digunakan oleh gambar dengan docker images , Anda akan melihat banyak ruang yang digunakan. TAPI, jangan menganggap ukuran di sini secara harfiah! Ukuran yang ditampilkan untuk setiap gambar mencakup ukuran total semua lapisannya, namun banyak dari lapisan tersebut yang digunakan bersama di antara gambar, terutama jika gambar tersebut didasarkan pada gambar dasar yang sama atau jika satu gambar merupakan versi khusus dari gambar lainnya. Untuk melihat berapa banyak ruang disk yang sebenarnya digunakan oleh image Docker Anda, gunakan:
docker system df
Kembali ke Daftar Isi
| Kategori | Tugas | Status |
|---|---|---|
| Perbaikan bug: | Bahaya pembuatan file teks Zero-Byte - Kadang-kadang jika OCR/Ekstraksi Teks dari dokumen masukan gagal, file .txt 0B mungkin tertinggal yang menyebabkan upaya percobaan ulang lebih lanjut untuk meyakini bahwa file telah dimuat | ? Tugas Masa Depan |
| Fitur Praktis: | Berpusat pada kemudahan penggunaan: | |
| Tombol UI tingkat gratis Azure CV-OCR | ✅ Selesai pada 8 Juni 2024 | |
| Hapus Obrolan | ? Tugas Masa Depan | |
| Ganti Nama Obrolan | ? Tugas Masa Depan | |
| Skrip Instalasi PowerShell | ? Tugas Masa Depan | |
| Skrip Instalasi Linux | ? Tugas Masa Depan | |
| Backend inferensi LLM Ollama sebagai alternatif untuk llama.cpp | ? Tugas Masa Depan | |
| Integrasi layanan OCR dari penyedia cloud lainnya (GCP, AWS, OCI, dll.) | ? Tugas Masa Depan | |
| Tombol UI untuk mengabaikan ekstrak teks sebelumnya saat mengunggah dokumen | ? Tugas Masa Depan | |
| Modal-popup untuk unggahan file: mencerminkan opsi ekstraksi teks dari pengaturan, penulisan ulang global pada pengiriman, beralih ke pengaturan tetap | ? Tugas Masa Depan | |
| Berpusat pada kinerja: | ||
| Dukungan Nvidia TensorRT-LLM AWQ | ? Tugas Masa Depan | |
| Tugas Penelitian: | Selidiki Nvidia TensorRT-LLM: Memerlukan pembuatan mesin TRT AWQ-LLM khusus untuk GPU target, NvTensorRT-LLM adalah ekosistemnya sendiri dan hanya berfungsi pada Python v3.10. | ✅ Selesai pada 13 Juni 2024 |
| OCR lokal dengan Vision LLM: MS-TrOCR (selesai), Kosmos-2.5 (Prioritas tinggi), Llava, Florence-2 | ? Pembaruan 5 Juli 2024 Sedang Berlangsung | |
| Peningkatan RAG: Re-ranker, RAPTOR, T-RAG | ? Tugas Masa Depan | |
| Selidiki integrasi GraphDB: menggunakan LLM untuk mengekstrak data hubungan entitas dari dokumen dan mengisi, memperbarui & memelihara GraphDB | ? Tugas Masa Depan |
Kembali ke Daftar Isi
Saya berharap LARS memberikan manfaat dalam pekerjaan Anda, dan saya mengundang Anda untuk mendukung pengembangan berkelanjutannya! Jika Anda menghargai alat ini dan ingin berkontribusi pada penyempurnaannya di masa mendatang, pertimbangkan untuk memberikan donasi. Dukungan Anda membantu saya untuk terus meningkatkan LARS dan menambahkan fitur baru.
Cara Berdonasi Untuk memberikan donasi, silakan gunakan tautan berikut ke PayPal saya:
Donasi melalui PayPal
Kontribusi Anda sangat dihargai dan akan digunakan untuk mendanai upaya pengembangan lebih lanjut.
Kembali ke Daftar Isi


