BLIVA
1.0.0
Wenbo Hu*, Yifan Xu*, Yi Li, Weiyue Li, Zeyuan Chen, dan Zhuowen Tu. *Kontribusi Setara
UC San Diego , Coinbase Global, Inc.
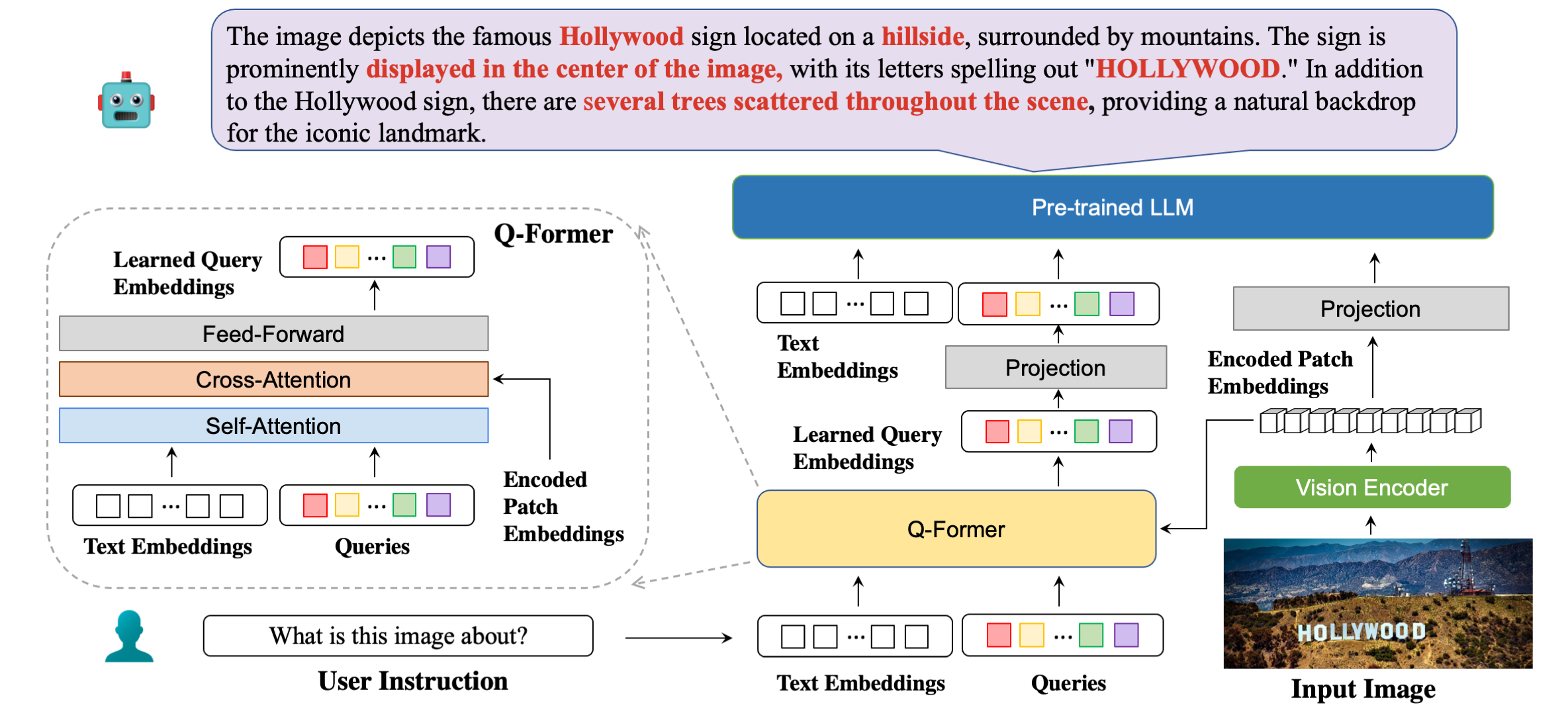
Arsitektur model kami secara detail dengan contoh tanggapan.
| Metode | STVQA | OCRVQA | TeksVQA | DokumenVQA | InfoVQA | BaganQA | ESTVQA | FUNSD | SROIE | POIE | Rata-rata |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Buka Flamingo | 19.32 | 27.82 | 29.08 | 5.05 | 14.99 | 9.12 | 28.20 | 0,85 | 0,12 | 2.12 | 13.67 |
| BLIP2-OPT | 13.36 | 10.58 | 21.18 | 0,82 | 8.82 | 7.44 | 27.02 | 0,00 | 0,00 | 0,02 | 8.92 |
| BLIP2-FLanT5XXL | 21.38 | 30.28 | 30.62 | 4.00 | 10.17 | 7.20 | 42.46 | 1.19 | 0,20 | 2.52 | 15.00 |
| MiniGPT4 | 14.02 | 11.52 | 18.72 | 2.97 | 13.32 | 4.32 | 28.36 | 1.19 | 0,04 | 1.31 | 9.58 |
| LLaVA | 22.93 | 15.02 | 28.30 | 4.40 | 13.78 | 7.28 | 33.48 | 1.02 | 0,12 | 2.09 | 12.84 |
| mPLUG-Burung Hantu | 26.32 | 35.00 | 37.44 | 6.17 | 16.46 | 9.52 | 49.68 | 1.02 | 0,64 | 3.26 | 18.56 |
| InstruksikanBLIP (FLANT5XXL) | 26.22 | 55.04 | 36.86 | 4.94 | 10.14 | 8.16 | 43.84 | 1.36 | 0,50 | 1.91 | 18.90 |
| InstruksikanBLIP (Vicuna-7B) | 28.64 | 47.62 | 39.60 | 5.89 | 13.10 | 5.52 | 47.66 | 0,85 | 0,64 | 2.66 | 19.22 |
| BLIVA (FLANT5XXL) | 28.24 | 61.34 | 39.36 | 5.22 | 10.82 | 9.28 | 45.66 | 1.53 | 0,50 | 2.39 | 20.43 |
| BLIVA (Vicuna-7B) | 29.08 | 65.38 | 42.18 | 6.24 | 13.50 | 8.16 | 48.14 | 1.02 | 0,88 | 2.91 | 21.75 |
| Metode | VSR | IkonQA | TeksVQA | Visdial | Flickr30K | Hm | VizWiz | MSRVTT |
|---|---|---|---|---|---|---|---|---|
| Flamingo-3B | - | - | 30.1 | - | 60.6 | - | - | - |
| Flamingo-9B | - | - | 31.8 | - | 61.5 | - | - | - |
| Flamingo-80B | - | - | 35.0 | - | 67.2 | - | - | - |
| MiniGPT-4 | 50,65 | - | 18.56 | - | - | 29.0 | 34.78 | - |
| LLaVA | 56.3 | - | 37,98 | - | - | 9.2 | 36.74 | - |
| BLIP-2 (Vicuna-7B) | 50.0 | 39.7 | 40.1 | 44.9 | 74.9 | 50.2 | 49.34 | 4.17 |
| InstruksikanBLIP (Vicuna-7B) | 54.3 | 43.1 | 50.1 | 45.2 | 82.4 | 54.8 | 43.3 | 18.7 |
| BLIVA (Vicuna-7B) | 62.2 | 44.88 | 57.96 | 45.63 | 87.1 | 55.6 | 42.9 | 23.81 |
conda create -n bliva python=3.9
conda activate blivagit clone https://github.com/mlpc-ucsd/BLIVA
cd BLIVA
pip install -e . BLIVA Vicuna 7B
Model versi Vicuna kami dirilis di sini. Unduh bobot model kami dan tentukan jalur dalam konfigurasi model di sini, di baris 8.
LLM yang kami gunakan adalah versi v0.1 dari Vicuna-7B. Untuk menyiapkan beban Vicuna, silakan lihat instruksi kami di sini. Kemudian, atur jalur ke bobot vicuna di file konfigurasi model di sini, di Baris 21.
BLIVA FlanT5 XXL (Tersedia untuk Penggunaan Komersial)
Model versi FlanT5 dirilis di sini. Unduh bobot model kami dan tentukan jalur dalam konfigurasi model di sini, di baris 8.
Bobot LLM untuk Flant5 akan secara otomatis mulai diunduh dari huggingface saat menjalankan kode inferensi kami.
Untuk menjawab satu pertanyaan dari gambar, jalankan kode evaluasi berikut. Misalnya,
python evaluate.py --answer_qs
--model_name bliva_vicuna
--img_path images/example.jpg
--question " what is this image about? "Kami juga mendukung jawaban pertanyaan pilihan ganda, yang sama seperti yang kami gunakan untuk tugas evaluasi di kertas. Untuk memberikan daftar pilihan, itu harus berupa string yang dipisahkan dengan koma. Misalnya,
python evaluate.py --answer_mc
--model_name bliva_vicuna
--img_path images/mi6.png
--question " Which genre does this image belong to? "
--candidates " play, tv show, movie " Demo kami tersedia untuk umum di sini. Untuk menjalankan demo kami secara lokal di mesin Anda. Berlari:
python demo.pySetelah mengunduh kumpulan data pelatihan dan menentukan jalurnya dalam konfigurasi kumpulan data, kami siap untuk pelatihan. Kami menggunakan 8x A6000 Ada dalam eksperimen kami. Harap sesuaikan hyperparamter sesuai dengan sumber daya GPU Anda. Transformator mungkin memerlukan waktu sekitar 2 menit untuk memuat model, memberikan waktu bagi model untuk memulai pelatihan. Berikut kami berikan contoh traning versi BLIVA Vicuna, versi Flant5 mengikuti format yang sama.
torchrun --nnodes=1 --nproc_per_node=8
train.py
--cfg-path train_configs/pretrain_bliva_vicuna.yamltorchrun --nnodes=1 --nproc_per_node=8
train.py
--cfg-path train_configs/finetune_bliva_vicuna.yamlAtau kami juga mendukung pelatihan Vicuna7b bersama BLIVA menggunakan LoRA pada langkah kedua, secara default kami tidak menggunakan versi ini.
torchrun --nnodes=1 --nproc_per_node=8
train.py
--cfg-path train_configs/finetune_bliva_and_vicuna.yamlJika menurut Anda BLIVA berguna untuk penelitian dan aplikasi Anda, silakan mengutip menggunakan BibTeX ini:
@misc { hu2023bliva ,
title = { BLIVA: A Simple Multimodal LLM for Better Handling of Text-Rich Visual Questions } ,
author = { Wenbo Hu and Yifan Xu and Yi Li and Weiyue Li and Zeyuan Chen and Zhuowen Tu } ,
publisher = { arXiv:2308.09936 } ,
year = { 2023 } ,
}Kode repositori ini berada di bawah Lisensi BSD 3-Clause. Banyak kode didasarkan pada Lavis dengan Lisensi 3-Klausul BSD di sini.
Untuk parameter model Versi BLIVA Vicuna kami, harus digunakan di bawah lisensi model LLaMA. Untuk bobot model BLIVA FlanT5, berada di bawah Lisensi Apache 2.0. Untuk data YTTB-VQA kami, menggunakan CC BY NC 4.0


