cambrian
1.0.0
Fakta menarik: penglihatan muncul pada hewan selama periode Kambrium! Inilah yang menjadi inspirasi nama proyek kami, Cambrian.
eval/ untuk lebih jelasnya.dataengine/ subfolder untuk lebih jelasnya.Saat ini, kami mendukung pelatihan tentang TPU menggunakan TorchXLA
git clone https://github.com/cambrian-mllm/cambrian
cd cambrianconda create -n cambrian python=3.10 -y
conda activate cambrian
pip install --upgrade pip # enable PEP 660 support
pip install -e " .[tpu] " pip install torch~=2.2.0 torch_xla[tpu]~=2.2.0 -f https://storage.googleapis.com/libtpu-releases/index.html
git clone https://github.com/cambrian-mllm/cambrian
cd cambrianconda create -n cambrian python=3.10 -y
conda activate cambrian
pip install --upgrade pip # enable PEP 660 support
pip install " .[gpu] " Berikut adalah pos pemeriksaan Kambrium kami beserta petunjuk tentang cara menggunakan beban. Model kami unggul dalam berbagai dimensi, pada tingkat parameter 8B, 13B, dan 34B. Mereka menunjukkan kinerja kompetitif dibandingkan dengan model berpemilik sumber tertutup seperti GPT-4V, Gemini-Pro, dan Grok-1.4V pada beberapa tolok ukur.
| Model | #vis. Tok. | MMB | SQA-I | MatematikaVistaM | BaganQA | MMVP |
|---|---|---|---|---|---|---|
| GPT-4V | UNK | 75.8 | - | 49.9 | 78.5 | 50.0 |
| Gemini-1.0 Pro | UNK | 73.6 | - | 45.2 | - | - |
| Gemini-1.5 Pro | UNK | - | - | 52.1 | 81.3 | - |
| Grok-1.5 | UNK | - | - | 52.8 | 76.1 | - |
| MM-1-8B | 144 | 72.3 | 72.6 | 35.9 | - | - |
| MM-1-30B | 144 | 75.1 | 81.0 | 39.4 | - | - |
| LLM Dasar: Phi-3-3.8B | ||||||
| Kambrium-1-8B | 576 | 74.6 | 79.2 | 48.4 | 66.8 | 40.0 |
| LLM Dasar: LLaMA3-8B-Instruksikan | ||||||
| Mini-Gemini-HD-8B | 2880 | 72.7 | 75.1 | 37.0 | 59.1 | 18.7 |
| LLaVA-NeXT-8B | 2880 | 72.1 | 72.8 | 36.3 | 69.5 | 38.7 |
| Kambrium-1-8B | 576 | 75.9 | 80.4 | 49.0 | 73.3 | 51.3 |
| Basis LLM: Vicuna1.5-13B | ||||||
| Mini-Gemini-HD-13B | 2880 | 68.6 | 71.9 | 37.0 | 56.6 | 19.3 |
| LLaVA-NeXT-13B | 2880 | 70.0 | 73.5 | 35.1 | 62.2 | 36.0 |
| Kambrium-1-13B | 576 | 75.7 | 79.3 | 48.0 | 73.8 | 41.3 |
| Basis LLM: Hermes2-Yi-34B | ||||||
| Mini-Gemini-HD-34B | 2880 | 80.6 | 77.7 | 43.4 | 67.6 | 37.3 |
| LLaVA-NeXT-34B | 2880 | 79.3 | 81.8 | 46.5 | 68.7 | 47.3 |
| Kambrium-1-34B | 576 | 81.4 | 85.6 | 53.2 | 75.6 | 52.7 |
Untuk tabel selengkapnya, silakan lihat makalah Cambrian-1 kami.
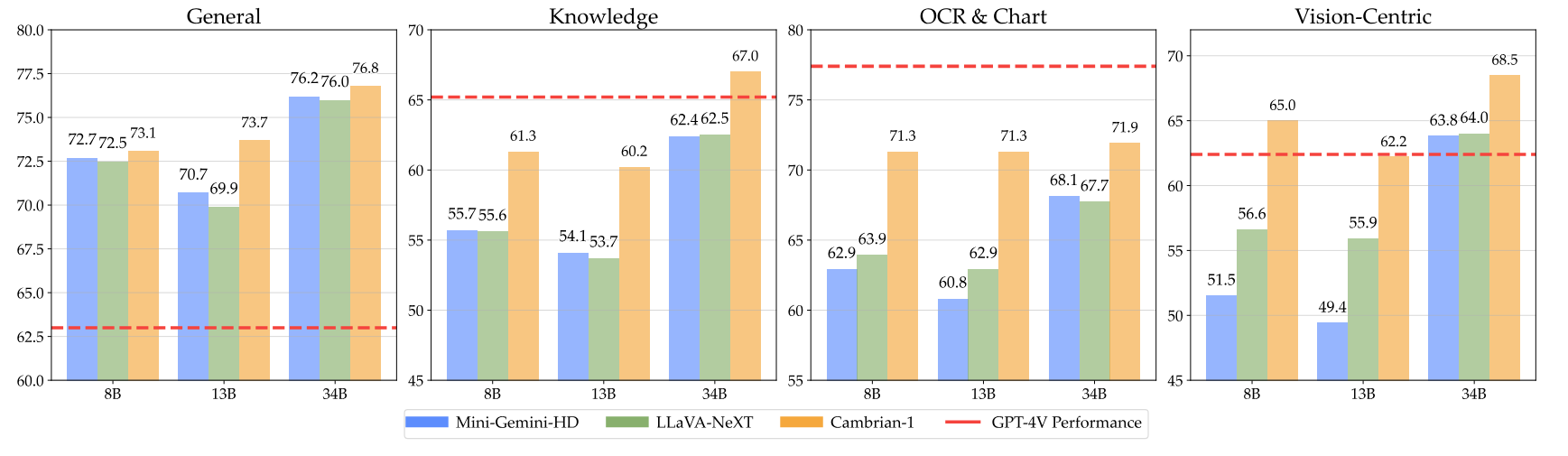
Model kami menawarkan kinerja yang sangat kompetitif dengan menggunakan token visual dalam jumlah tetap yang lebih kecil.
Untuk menggunakan bobot model, unduh dari Hugging Face:
Kami menyediakan contoh skrip pemuatan dan pembuatan model di inference.py .

Dalam pekerjaan ini, kami mengumpulkan kumpulan data penyetelan instruksi yang sangat besar, Cambrian-10M, untuk kami dan pekerjaan masa depan untuk mempelajari data dalam pelatihan MLLM. Dalam studi pendahuluan kami, kami memfilter data ke kumpulan 7 juta titik data kurasi berkualitas tinggi, yang kami sebut Cambrian-7M. Kedua dataset ini tersedia dalam Hugging Face Dataset berikut: Cambrian-10M.
Kami mengumpulkan beragam data penyetelan instruksi visual dari berbagai sumber, termasuk VQA, percakapan visual, dan interaksi visual yang diwujudkan. Untuk memastikan data pengetahuan berkualitas tinggi, andal, dan berskala besar, kami merancang Mesin Data Internet.
Selain itu, kami mengamati bahwa data VQA cenderung menghasilkan keluaran yang sangat singkat, sehingga menyebabkan pergeseran distribusi dari data pelatihan. Untuk mengatasi masalah ini, kami memanfaatkan GPT-4v dan GPT-4o untuk menghasilkan respons yang lebih luas dan data yang lebih kreatif.
Untuk mengatasi kekurangan data terkait sains, kami merancang Mesin Data Internet untuk mengumpulkan data VQA terkait sains yang andal. Mesin ini dapat diterapkan untuk mengumpulkan data tentang topik apa pun. Dengan menggunakan mesin ini, kami mengumpulkan 161 ribu titik data penyetelan instruksi visual terkait sains tambahan, sehingga meningkatkan total data dalam domain ini sebesar 400%! Jika Anda ingin menggunakan bagian data ini, silakan gunakan jsonl ini.
Kami menggunakan GPT-4v untuk membuat 77 ribu titik data tambahan. Data ini menggunakan GPT-4v untuk menulis ulang VQA asli yang hanya berisi jawaban menjadi jawaban yang lebih panjang dengan respons yang lebih mendetail atau menghasilkan data penyetelan instruksi visual berdasarkan gambar yang diberikan. Jika Anda ingin menggunakan bagian data ini, silakan gunakan jsonl ini.
Kami menggunakan GPT-4o untuk membuat 60 ribu titik data materi iklan tambahan. Data ini mendorong model untuk menghasilkan respons yang sangat panjang dan sering kali berisi pertanyaan yang sangat kreatif, seperti menulis puisi, mengarang lagu, dan banyak lagi. Jika Anda ingin menggunakan bagian data ini, silakan gunakan jsonl ini.
Kami melakukan studi awal tentang kurasi data dengan:
Secara empiris, kami menemukan pengaturan itu
| Kategori | Rasio Data |
|---|---|
| Bahasa | 21,00% |
| Umum | 34,52% |
| OCR | 27,22% |
| Perhitungan | 8,71% |
| Matematika | 7,20% |
| Kode | 0,87% |
| Sains | 0,88% |
Dibandingkan dengan model LLaVA-665K sebelumnya, peningkatan skala dan peningkatan kurasi data secara signifikan meningkatkan performa model, seperti yang ditunjukkan pada tabel di bawah:
| Model | Rata-rata | Pengetahuan Umum | OCR | Bagan | Berpusat pada Visi |
|---|---|---|---|---|---|
| LLaVA-665K | 40.4 | 64.7 | 45.2 | 20.8 | 31.0 |
| Kambrium-10M | 53.8 | 68.7 | 51.6 | 47.1 | 47.6 |
| Kambrium-7M | 54.8 | 69.6 | 52.6 | 47.3 | 49.5 |
Meskipun pelatihan dengan Cambrian-7M memberikan hasil benchmark yang kompetitif, kami mengamati bahwa model tersebut cenderung menghasilkan respons yang lebih pendek dan bertindak seperti mesin tanya jawab. Perilaku ini, yang kami sebut sebagai fenomena "Mesin Jawaban", dapat membatasi kegunaan model dalam interaksi yang lebih kompleks.
Kami menemukan bahwa menambahkan perintah sistem seperti "Jawab pertanyaan menggunakan satu kata atau frasa." dapat membantu mengurangi masalah ini. Pendekatan ini mendorong model untuk memberikan jawaban ringkas hanya jika sesuai secara kontekstual. Untuk lebih jelasnya, silakan merujuk ke makalah kami.
Kami juga telah menyusun kumpulan data, Cambrian-7M dengan perintah sistem, yang mencakup perintah sistem untuk meningkatkan kreativitas model dan kemampuan mengobrol.
Di bawah ini adalah konfigurasi pelatihan terbaru untuk Cambrian-1.
Dalam makalah Cambrian-1, kami melakukan penelitian ekstensif untuk menunjukkan perlunya pelatihan dua tahap. Pelatihan Cambrian-1 terdiri dari dua tahap:
Cambrian-1 dilatih pada TPU-V4-512 tetapi juga dapat dilatih pada TPU mulai dari TPU-V4-64. Kode pelatihan GPU akan segera dirilis. Untuk pelatihan GPU pada GPU yang lebih sedikit, kurangi per_device_train_batch_size dan tingkatkan gradient_accumulation_steps , pastikan ukuran batch global tetap sama: per_device_train_batch_size x gradient_accumulation_steps x num_gpus .
Hyperparameter yang digunakan dalam pra-pelatihan dan penyesuaian disediakan di bawah.
| Dasar LLM | Ukuran Batch Global | Kecepatan pembelajaran | Kecepatan Pembelajaran SVA | zaman | Panjang maksimal |
|---|---|---|---|---|---|
| LLaMA-3 8B | 512 | 1e-3 | 1e-4 | 1 | 2048 |
| Vicuna-1.5 13B | 512 | 1e-3 | 1e-4 | 1 | 2048 |
| Hermes Yi-34B | 1024 | 1e-3 | 1e-4 | 1 | 2048 |
| Dasar LLM | Ukuran Batch Global | Kecepatan pembelajaran | zaman | Panjang maksimal |
|---|---|---|---|---|
| LLaMA-3 8B | 512 | 4e-5 | 1 | 2048 |
| Vicuna-1.5 13B | 512 | 4e-5 | 1 | 2048 |
| Hermes Yi-34B | 1024 | 2e-5 | 1 | 2048 |
Untuk menyempurnakan instruksi, kami melakukan eksperimen untuk menentukan kecepatan pembelajaran optimal untuk pelatihan model kami. Berdasarkan temuan kami, sebaiknya gunakan rumus berikut untuk menyesuaikan kecepatan pemelajaran berdasarkan ketersediaan perangkat Anda:
optimal lr = base_lr * sqrt(bs / base_bs)
Untuk mendapatkan LLM dasar dan melatih model 8B, 13B, dan 34B:
Kami menggunakan kombinasi data penyelarasan LLaVA, ShareGPT4V, Mini-Gemini, dan ALLaVA untuk melatih konektor visual (SVA) kami terlebih dahulu. Di Cambrian-1, kami melakukan penelitian ekstensif untuk menunjukkan perlunya dan manfaat penggunaan data penyelarasan tambahan.
Untuk memulai, silakan kunjungi halaman data perataan Wajah Memeluk kami untuk lebih jelasnya. Anda dapat mengunduh data penyelarasan dari tautan berikut:
Kami menyediakan contoh skrip pelatihan di:
Jika Anda ingin berlatih dengan sumber data lain atau data khusus, kami mendukung format data LLaVA yang umum digunakan. Untuk menangani file yang sangat besar, kami menggunakan format JSONL, bukan format JSON untuk pemuatan data yang lambat guna mengoptimalkan penggunaan memori.
Mirip dengan Pelatihan SVA, silakan kunjungi data Cambrian-10M kami untuk detail lebih lanjut tentang data penyetelan instruksi.
Kami menyediakan contoh skrip pelatihan di:
--mm_projector_type : Untuk menggunakan modul SVA kami, setel nilai ini ke sva . Untuk menggunakan proyektor MLP 2 lapis gaya LLaVA, tetapkan nilai ini ke mlp2x_gelu .--vision_tower_aux_list : Daftar model vision yang akan digunakan (misalnya '["siglip/CLIP-ViT-SO400M-14-384", "openai/clip-vit-large-patch14-336", "facebook/dinov2-giant-res378", "clip-convnext-XXL-multi-stage"]' ).--vision_tower_aux_token_len_list : Daftar jumlah token visi untuk setiap menara visi; setiap angka harus berupa angka kuadrat (misalnya '[576, 576, 576, 9216]' ). Peta fitur setiap menara visi akan diinterpolasi untuk memenuhi persyaratan ini.--image_token_len : Jumlah akhir token visi yang akan diberikan kepada LLM; angkanya harus berupa angka kuadrat (misalnya 576 ). Perhatikan bahwa jika mm_projector_type adalah mlp, setiap nomor di vision_tower_aux_token_len_list harus sama dengan image_token_len . Argumen di bawah ini hanya berarti untuk proyektor SVA--num_query_group : Nilai G untuk modul SVA.--query_num_list : Daftar nomor kueri untuk setiap grup kueri di SVA (misalnya '[576]' ). Panjang daftar harus sama dengan num_query_group .--connector_depth : Nilai D untuk modul SVA.--vision_hidden_size : Ukuran tersembunyi untuk modul SVA.--connector_only : Jika benar, modul SVA hanya akan muncul sebelum LLM, jika tidak maka akan dimasukkan beberapa kali ke dalam LLM. Tiga argumen berikut hanya bermakna jika disetel ke False .--num_of_vision_sampler_layers : Jumlah total modul SVA yang dimasukkan ke dalam LLM.--start_of_vision_sampler_layers : Indeks lapisan LLM setelah penyisipan SVA dimulai.--stride_of_vision_sampler_layers : Langkah penyisipan modul SVA di dalam LLM. Kami telah merilis kode evaluasi kami di subfolder eval/ . Silakan lihat README di sana untuk lebih jelasnya.
Petunjuk berikut akan memandu Anda dalam meluncurkan demo Gradio lokal dengan Cambrian. Kami menyediakan antarmuka web sederhana bagi Anda untuk berinteraksi dengan model. Anda juga dapat menggunakan CLI untuk inferensi. Pengaturan ini sangat terinspirasi oleh LLaVA.
Silakan ikuti langkah-langkah di bawah ini untuk meluncurkan demo Gradio lokal. Diagram kode penyajian lokal di bawah 1 .
%%{init: {"tema": "dasar"}}%%
diagram alur BT
%% Deklarasikan Node
gaya gws isi:#f9f,guratan:#333,lebar guratan:2px
gaya c isi:#bbf,guratan:#333,lebar guratan:2px
gaya mw8b isi:#aff,guratan:#333,lebar guratan:2px
gaya mw13b isi:#aff,guratan:#333,lebar guratan:2px
%% gaya sglw13b isi:#ffa,guratan:#333,lebar guratan:2px
%% gaya lsglw13b isi:#ffa,guratan:#333,lebar guratan:2px
gws["Gradio (Server UI)"]
c["Pengontrol (Server API):<br/>PORT: 10000"]
mw8b["Pekerja Teladan:<br/><b>Cambrian-1-8B</b><br/>PELABUHAN: 40000"]
mw13b["Pekerja Teladan:<br/><b>Cambrian-1-13B</b><br/>PELABUHAN: 40001"]
%% sglw13b["Backend SGLang:<br/><b>Cambrian-1-34B</b><br/>http://localhost:30000"]
%% lsglw13b["Pekerja SGLang:<br/><b>Cambrian-1-34B<b><br/>PELABUHAN: 40002"]
subgraf "Demo Arsitektur"
arah BT
c <--> gw
mw8b <-->c
mw13b <-->c
%% lsglw13b <-->c
%% sglw13b <--> lsglw13b
akhir
python -m cambrian.serve.controller --host 0.0.0.0 --port 10000python -m cambrian.serve.gradio_web_server --controller http://localhost:10000 --model-list-mode reloadAnda baru saja meluncurkan antarmuka web Gradio. Sekarang, Anda dapat membuka antarmuka web dengan URL yang tercetak di layar. Anda mungkin memperhatikan bahwa tidak ada model dalam daftar model. Jangan khawatir, karena kami belum meluncurkan pekerja model apa pun. Ini akan diperbarui secara otomatis saat Anda meluncurkan pekerja model.
Segera hadir.
Ini adalah pekerja sebenarnya yang melakukan inferensi pada GPU. Setiap pekerja bertanggung jawab atas satu model yang ditentukan dalam --model-path .
python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path nyu-visionx/cambrian-8bTunggu hingga proses memuat model selesai dan Anda melihat "Uvicorn running on...". Sekarang, segarkan UI web Gradio Anda, dan Anda akan melihat model yang baru saja Anda luncurkan di daftar model.
Anda dapat meluncurkan pekerja sebanyak yang Anda inginkan, dan membandingkan antara pos pemeriksaan model yang berbeda dalam antarmuka Gradio yang sama. Harap jaga agar --controller tetap sama, dan ubah --port dan --worker ke nomor port yang berbeda untuk setiap pekerja.
python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port < different from 40000, say 40001> --worker http://localhost: < change accordingly, i.e. 40001> --model-path < ckpt 2> Jika Anda menggunakan perangkat Apple dengan chip M1 atau M2, Anda dapat menentukan perangkat mps dengan menggunakan tanda --device : --device mps .
Jika VRAM GPU Anda kurang dari 24 GB (misalnya RTX 3090, RTX 4090, dll.), Anda dapat mencoba menjalankannya dengan beberapa GPU. Basis kode terbaru kami akan secara otomatis mencoba menggunakan beberapa GPU jika Anda memiliki lebih dari satu GPU. Anda dapat menentukan GPU mana yang akan digunakan dengan CUDA_VISIBLE_DEVICES . Di bawah ini adalah contoh pengoperasian dengan dua GPU pertama.
CUDA_VISIBLE_DEVICES=0,1 python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path nyu-visionx/cambrian-8bTODO
Jika menurut Anda Cambrian berguna untuk penelitian dan aplikasi Anda, silakan mengutip menggunakan BibTeX ini:
@misc { tong2024cambrian1 ,
title = { Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs } ,
author = { Shengbang Tong and Ellis Brown and Penghao Wu and Sanghyun Woo and Manoj Middepogu and Sai Charitha Akula and Jihan Yang and Shusheng Yang and Adithya Iyer and Xichen Pan and Austin Wang and Rob Fergus and Yann LeCun and Saining Xie } ,
year = { 2024 } ,
eprint = { 2406.16860 } ,
}
Pemberitahuan Penggunaan dan Lisensi : Proyek ini menggunakan kumpulan data dan pos pemeriksaan tertentu yang tunduk pada lisensi aslinya masing-masing. Pengguna harus mematuhi semua syarat dan ketentuan lisensi asli ini, termasuk namun tidak terbatas pada Ketentuan Penggunaan OpenAI untuk kumpulan data dan lisensi khusus untuk model bahasa dasar untuk pos pemeriksaan yang dilatih menggunakan kumpulan data (misalnya lisensi komunitas Llama untuk LLaMA-3, dan Vicuna-1.5). Proyek ini tidak menerapkan batasan tambahan apa pun di luar yang ditetapkan dalam izin awal. Selain itu, pengguna diingatkan untuk memastikan bahwa penggunaan dataset dan pos pemeriksaan mematuhi semua hukum dan peraturan yang berlaku.
Disalin dari diagram LLaVA. ↩


