llm chatbot rag
1.0.0
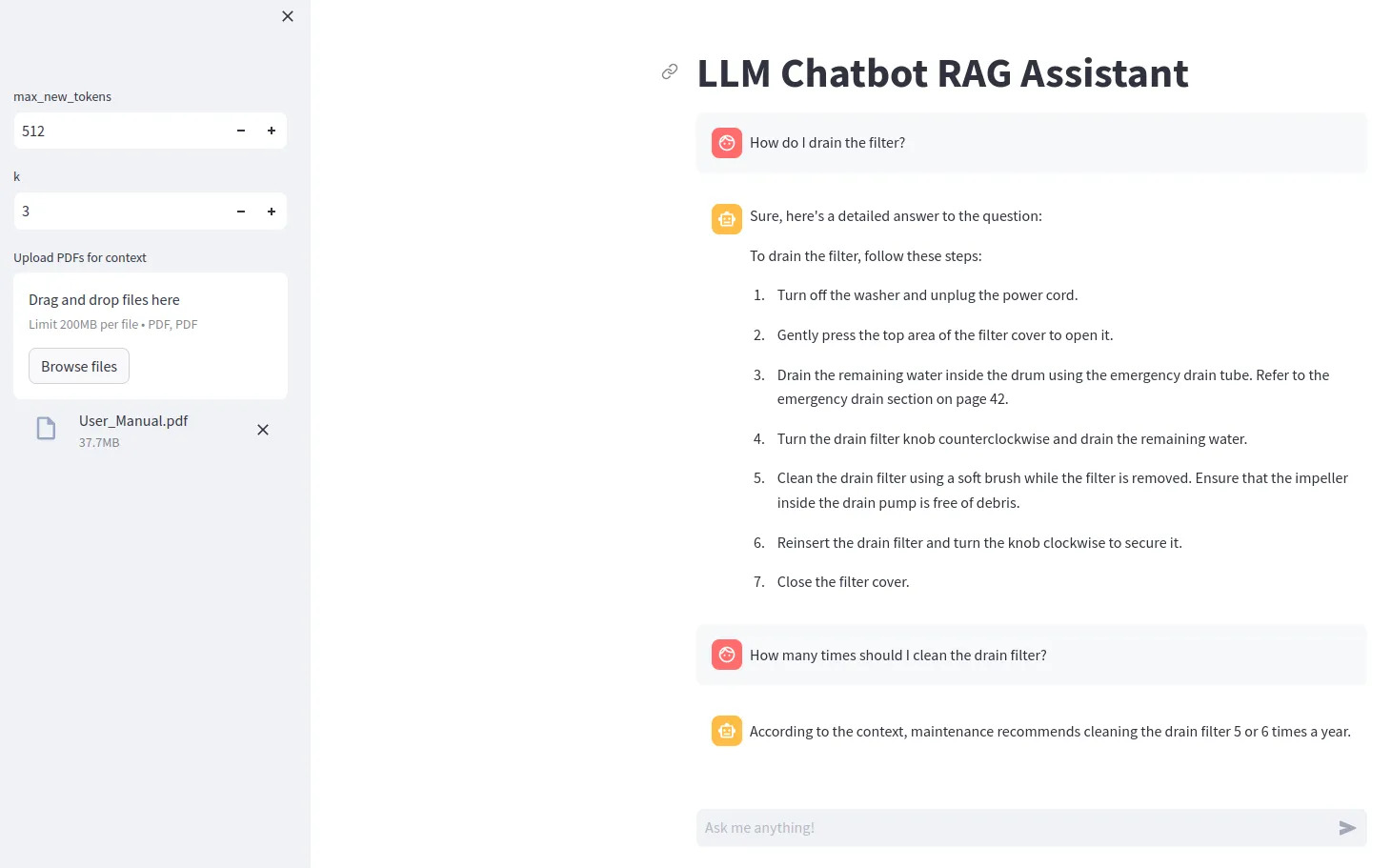
Untuk menggunakan model LLM tertentu (seperti Gemma), Anda perlu membuat file .env yang berisi baris ACCESS_TOKEN=<your hugging face token>
Instal dependensi dengan pip install -r requirements.txt
Jalankan dengan streamlit run src/app.py
Untuk menggunakan kuantisasi bitsandbytes, diperlukan GPU Nvidia. Pastikan untuk menginstal NVIDIA Toolkit terlebih dahulu, lalu PyTorch.
Anda dapat memeriksa apakah GPU Anda tersedia dalam Python dengan
import torch
print(torch.cuda.is_available())
Jika Anda tidak memiliki GPU yang kompatibel, coba atur device="cpu" untuk model dan hapus konfigurasi kuantisasi.


