chat4u
1.0.0
Gunakan catatan obrolan WeChat untuk melatih chatbot yang eksklusif untuk Anda.
Catatan obrolan WeChat akan dienkripsi dan disimpan dalam database sqlite. Pertama, Anda perlu mendapatkan kunci database. Anda memerlukan laptop macOS, dan ponsel Anda dapat berupa Android/iPhone.
git clone https://github.com/nalzok/wechat-decipher-macossudo ./wechat-decipher-macos/macos/dbcracker.d -p $( pgrep WeChat ) | tee dbtrace.logdbtrace.log . sqlcipher '/Users/<user>/Library/Containers/com.tencent.xinWeChat/Data/Library/Application Support/com.tencent.xinWeChat/2.0b4.0.9/5976edc4b2ac64741cacc525f229c5fe/Message/msg_0.db'
--------------------------------------------------------------------------------
PRAGMA key = "x'<384_bit_key>'";
PRAGMA cipher_compatibility = 3;
PRAGMA kdf_iter = 64000;
PRAGMA cipher_page_size = 1024;
........................................
Pengguna sistem operasi lain dapat mencoba metode berikut, yang hanya diteliti dan belum diverifikasi, untuk referensi:
EnMicroMsg.db : https://github.com/ppwwyyxx/wechat-dumpEnMicroMsg.db secara kasar: https://github.com/chg-hou/EnMicroMsg.db-Password-Cracker Di laptop macOS saya, rekaman obrolan WeChat disimpan di msg_0.db - msg_9.db , dan hanya database ini yang dapat didekripsi.
Anda perlu menginstal sqlcipher untuk dekripsi yang dapat dijalankan pengguna sistem macOS secara langsung:
brew install sqlcipher Jalankan skrip berikut untuk mengurai dbtrace.log secara otomatis, mendekripsi msg_x.db dan mengekspor ke plain_msg_x.db .
python3 decrypt.py Anda dapat membuka database yang didekripsi plain_msg_x.db melalui https://sqliteviewer.app/, temukan tabel tempat catatan obrolan yang Anda butuhkan berada, isi nama database dan tabel ke dalam prepare_data.py , dan jalankan skrip berikut untuk menghasilkan data pelatihan train.json , strategi saat ini relatif sederhana, hanya menangani satu putaran dialog, dan akan menggabungkan dialog berturut-turut dalam waktu 5 menit.
python3 prepare_data.pyContoh data pelatihan adalah sebagai berikut:
[
{ "instruction" : "你好" , "output" : "你好" }
{ "instruction" : "你是谁" , "output" : "你猜猜" }
] Siapkan mesin Linux dengan GPU dan scp train.json ke mesin GPU.
Saya menggunakan stanford_alpaca full-image fine-tuning LLaMA-7B, dan melatih 90 ribu data selama 3 epoch pada 8-kartu V100-SXM2-32GB, yang hanya membutuhkan waktu 1 jam.
# clone the alpaca repo
git clone https://github.com/tatsu-lab/stanford_alpaca.git && cd stanford_alpaca
# adjust deepspeed config ... such as disabling offloading
vim ./configs/default_offload_opt_param.json
# train with deepspeed zero3
torchrun --nproc_per_node=8 --master_port=23456 train.py
--model_name_or_path huggyllama/llama-7b
--data_path ../train.json
--model_max_length 128
--fp16 True
--output_dir ../llama-wechat
--num_train_epochs 3
--per_device_train_batch_size 8
--per_device_eval_batch_size 8
--gradient_accumulation_steps 1
--evaluation_strategy " no "
--save_strategy " epoch "
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 10
--deepspeed " ./configs/default_offload_opt_param.json "
--tf32 FalseDeepSpeed zero3 akan menghemat bobot dalam irisan, dan bobot tersebut perlu digabungkan ke dalam file pos pemeriksaan pytorch:
cd llama-wechat
python3 zero_to_fp32.py . pytorch_model.binPada kartu grafis tingkat konsumen, Anda dapat mencoba alpaca-lora. Hanya menyempurnakan bobot lora yang dapat mengurangi memori grafis dan biaya pelatihan secara signifikan.
Anda dapat menggunakan alpaca-lora untuk menerapkan ujung depan gradien untuk proses debug. Jika ini menyempurnakan keseluruhan gambar, Anda perlu mengomentari kode terkait peft dan hanya memuat model dasar.
git clone https://github.com/tloen/alpaca-lora.git && cd alpaca-lora
CUDA_VISIBLE_DEVICES=0 python3 generate.py --base_model ../llama-wechatEfek operasi:

Penting untuk menerapkan layanan model yang kompatibel dengan OpenAI API. Berikut adalah adaptasi sederhana berdasarkan llama4openai-api.py Lihat llama4openai-api.py di gudang ini untuk memulai layanan:
CUDA_VISIBLE_DEVICES=0 python3 llama4openai-api.pyUji apakah antarmuka tersedia:
curl http://127.0.0.1:5000/chat/completions -v -H " Content-Type: application/json " -H " Authorization: Bearer $OPENAI_API_KEY " --data ' {"model":"llama-wechat","max_tokens":128,"temperature":0.95,"messages":[{"role":"user","content":"你好"}]} 'Gunakan wechat-chatgpt untuk mengakses WeChat, dan isi alamat layanan model lokal Anda untuk alamat API:
docker run -it --rm --name wechat-chatgpt
-e API=http://127.0.0.1:5000
-e OPENAI_API_KEY= $OPENAI_API_KEY
-e MODEL= " gpt-3.5-turbo "
-e CHAT_PRIVATE_TRIGGER_KEYWORD= " "
-v $( pwd ) /data:/app/data/wechat-assistant.memory-card.json
holegots/wechat-chatgpt:latestEfek operasi:
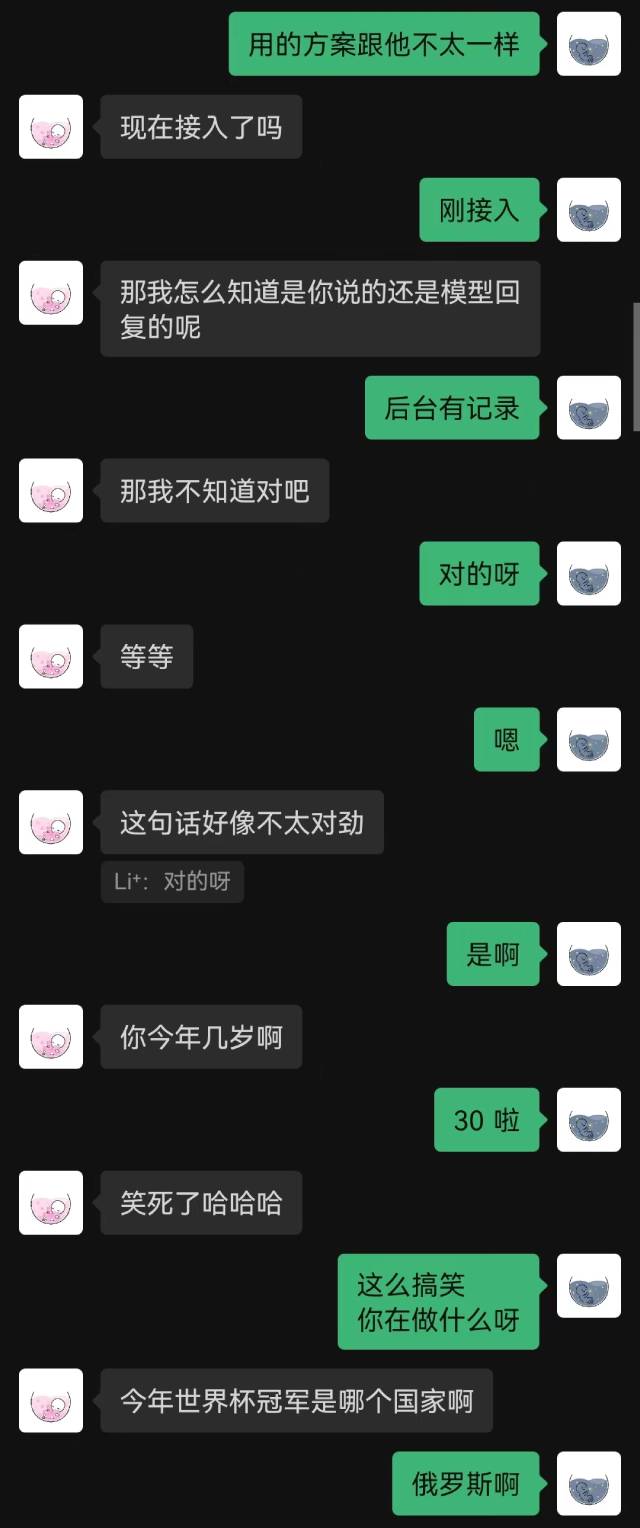 | 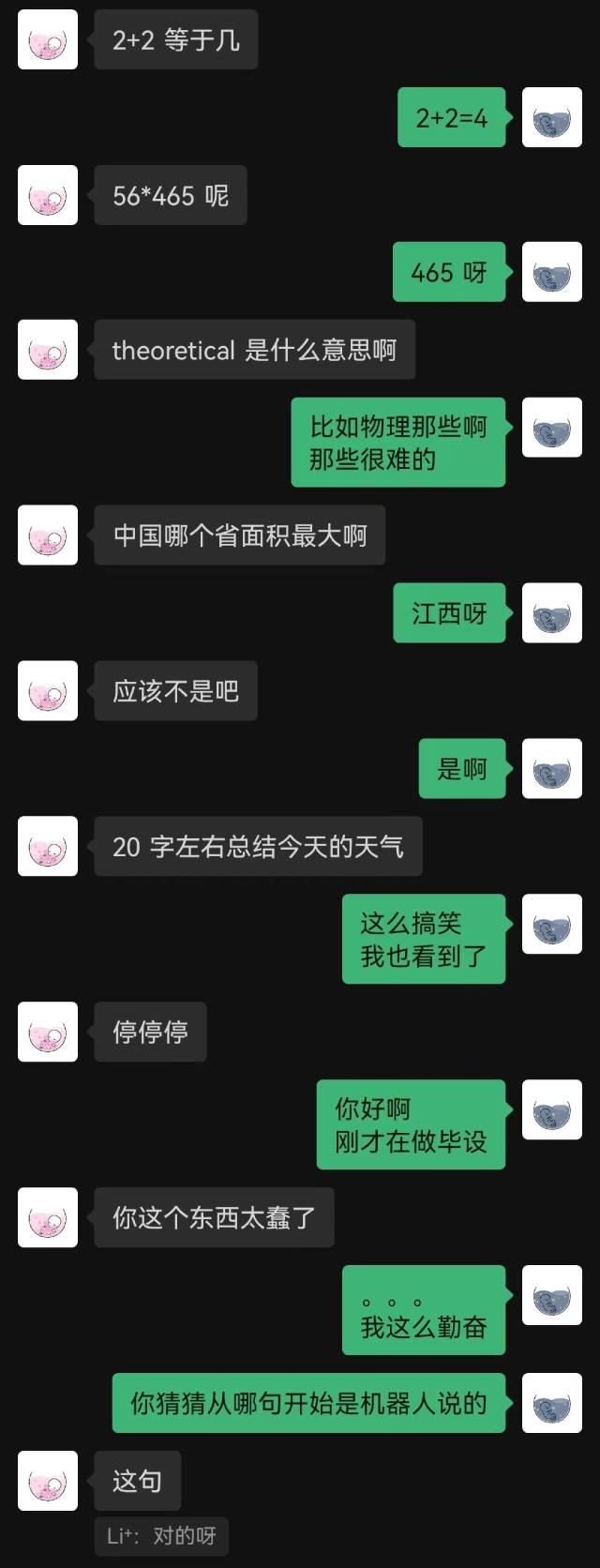 |
|---|
"Baru saja terhubung" adalah kalimat pertama yang diucapkan robot tersebut, dan pihak lain tidak menebaknya sampai akhir.
Secara umum, robot yang dilatih dengan rekaman obrolan pasti akan memiliki beberapa kesalahan akal sehat, tetapi mereka meniru gaya obrolan dengan lebih baik.


