msg_reply
1.0.0
Pernahkah Anda melihat atau menggunakan Google Smart Reply? Ini adalah layanan yang memberikan saran balasan otomatis untuk pesan pengguna. Lihat di bawah.
Ini adalah aplikasi yang berguna dari chatbot berbasis pengambilan. Pikirkan tentang hal ini. Berapa kali kita mengirim pesan seperti terima kasih , hai , atau sampai jumpa lagi ? Dalam proyek ini, kami membangun sistem saran balasan pesan sederhana.
Taman Kyubyong
Peninjauan kode oleh Yj Choe
Kita perlu mengatur daftar saran untuk ditampilkan. Tentu saja, frekuensi dipertimbangkan terlebih dahulu. Tapi bagaimana dengan ungkapan-ungkapan yang memiliki arti serupa? Misal harusnya terima kasih banyak dan terima kasih diperlakukan secara mandiri? Menurut kami tidak. Kami ingin mengelompokkannya dan menyimpan slot kami. Bagaimana? Kami menggunakan korpus paralel. Keduanya terima kasih banyak dan terima kasih kemungkinan besar akan diterjemahkan ke dalam teks yang sama. Berdasarkan asumsi ini, kami membangun kelompok sinonim bahasa Inggris yang memiliki terjemahan yang sama.
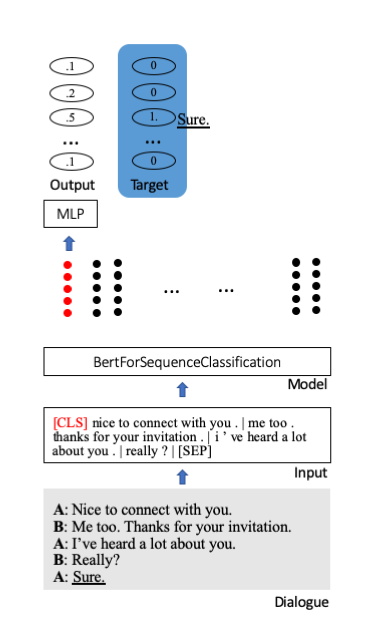
Kami menyempurnakan model Bert yang telah dilatih sebelumnya dari Huggingface untuk klasifikasi urutan. Di dalamnya, token awal khusus [CLS] menyimpan seluruh informasi sebuah kalimat. Lapisan tambahan dilampirkan untuk memproyeksikan informasi ringkas ke unit klasifikasi (di sini 100).
Kami menggunakan korpus paralel Spanyol-Inggris OpenSubtitles 2018 untuk membuat grup sinonim. OpenSubtitles adalah kumpulan besar subtitle film terjemahan. Data en-es terdiri dari lebih dari 61 juta garis sejajar.
Idealnya, korpus dialog (yang sangat) besar diperlukan untuk pelatihan, namun hal ini tidak dapat kami temukan. Kami menggunakan Cornell Movie Dialogue Corpus sebagai gantinya. Terdiri dari 83.097 dialog atau 304.713 baris.
ular piton>=3.6
tqdm>=4.30.0
obor>=1.0
pytorch_pretrained_bert>=0.6.1
nltk>=3.4
LANGKAH 0. Unduh data Paralel Spanyol-Inggris OpenSubtitles 2018.
bash download.sh
LANGKAH 1. Buatlah kelompok sinonim dari korpus.
python construct_sg.py
LANGKAH 2. Buat kamus phr2sg_id dan sg_id2phr.
python make_phr2sg_id.py
LANGKAH 3. Ubah teks bahasa Inggris monolingual menjadi id.
python encode.py
LANGKAH 4. Buat data pelatihan dan simpan sebagai acar.
python prepro.py
LANGKAH 5. Latih.
python train.py
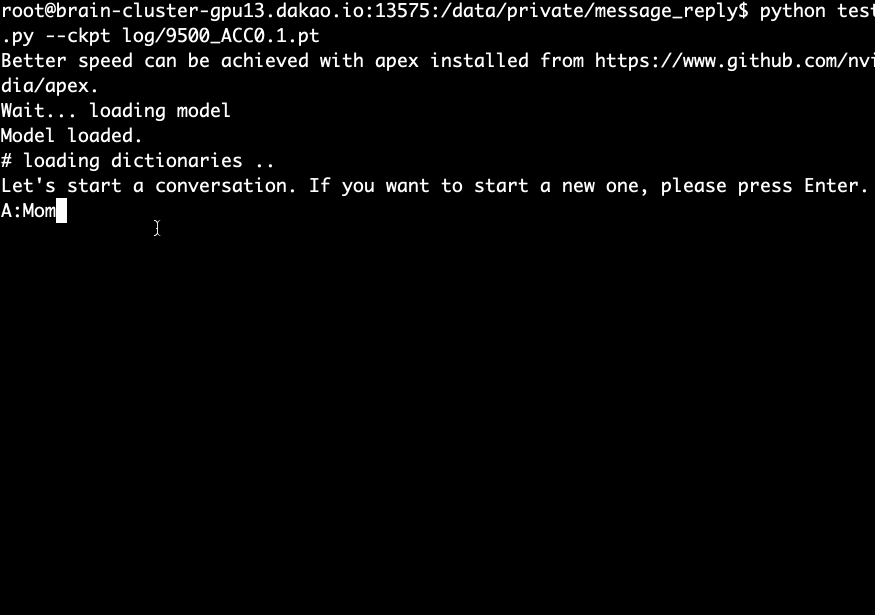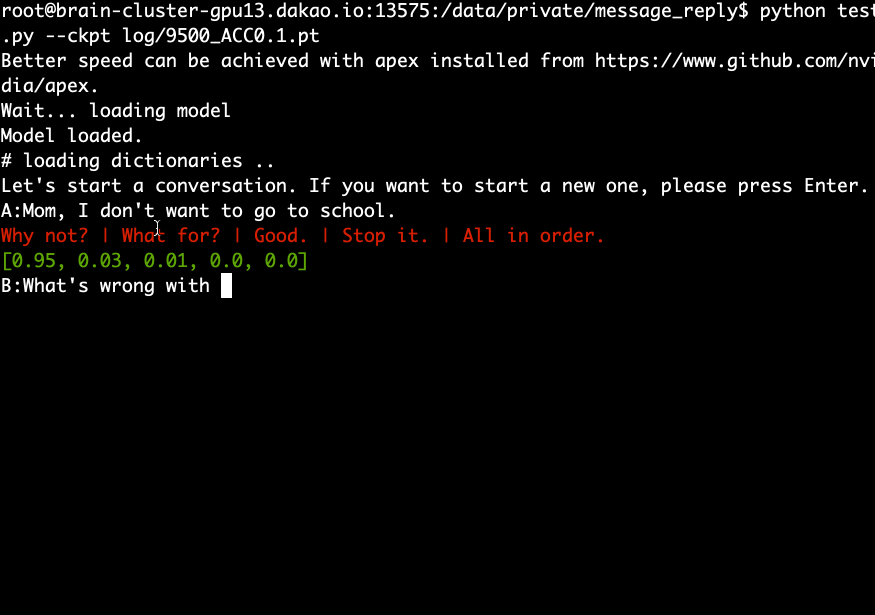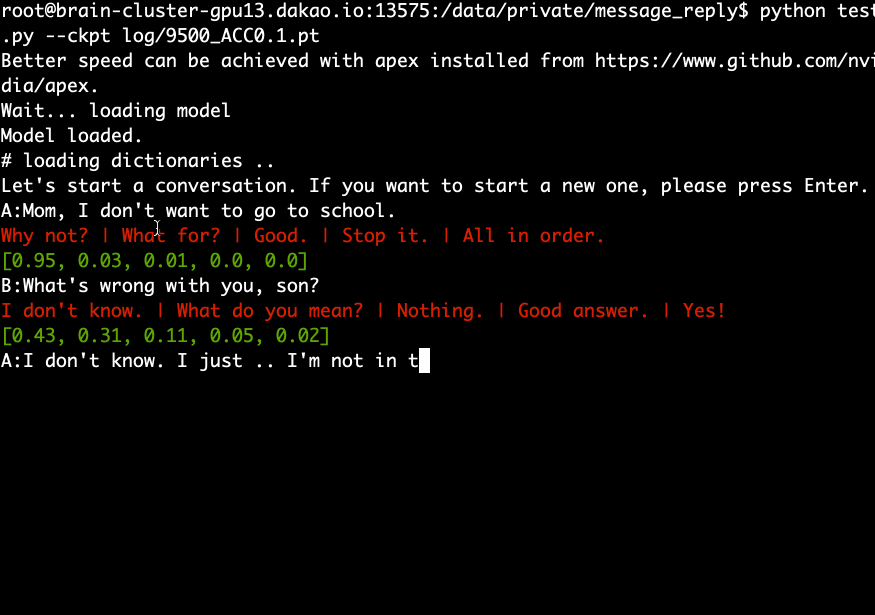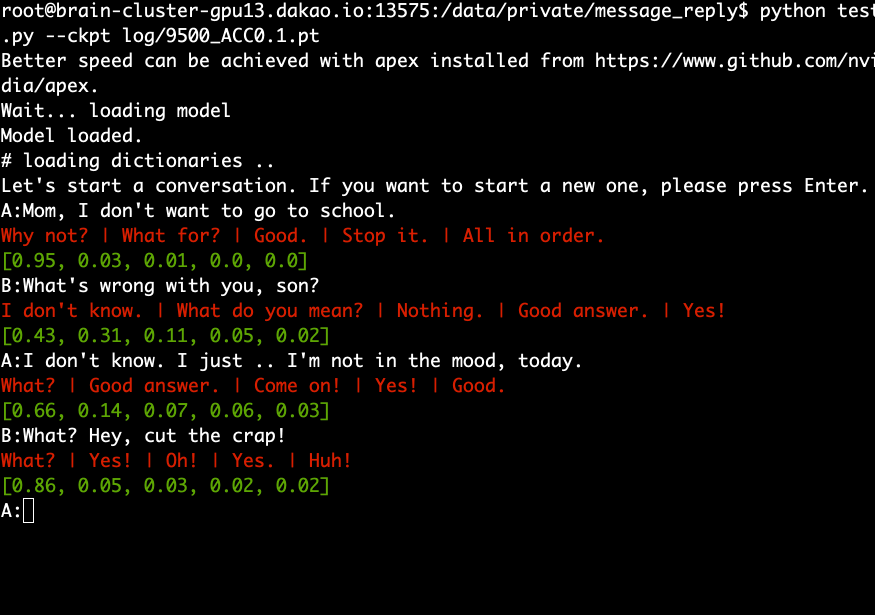
Unduh dan ekstrak model terlatih dan jalankan perintah berikut.
python test.py --ckpt log/9500_ACC0.1.pt
Kehilangan pelatihan perlahan tapi pasti menurun.
Accuracy@5 pada data evaluasi berkisar antara 10 hingga 20 persen.
Untuk penerapan nyata, diperlukan korpus yang jauh lebih besar.
Tidak yakin seberapa mirip skrip film dengan dialog pesan.
Diperlukan strategi yang lebih baik untuk membangun kelompok sinonim.
Chatbot berbasis pengambilan adalah aplikasi yang realistis karena lebih aman dan mudah dibandingkan aplikasi berbasis generasi.


