ThinkRAG
1.0.0
Bahasa Inggris |. Cina Sederhana
Sistem pembuatan peningkatan pengambilan model besar ThinkRAG dapat dengan mudah diterapkan pada laptop untuk mewujudkan jawaban pertanyaan yang cerdas dalam basis pengetahuan lokal.
Sistem ini dibangun berdasarkan LlamaIndex dan Streamlit, dan telah dioptimalkan untuk pengguna domestik di banyak bidang seperti pemilihan model dan pemrosesan teks.
ThinkRAG adalah sistem aplikasi model besar yang dikembangkan untuk para profesional, peneliti, pelajar, dan pekerja pengetahuan lainnya. Sistem ini dapat digunakan langsung di laptop, dan data basis pengetahuan disimpan secara lokal di komputer.
ThinkRAG memiliki beberapa fitur berikut:
Secara khusus, ThinkRAG juga telah melakukan banyak penyesuaian dan optimalisasi untuk pengguna domestik:
ThinkRAG dapat menggunakan semua model yang didukung oleh bingkai data LlamaIndex. Untuk informasi daftar model, silakan merujuk ke dokumentasi yang relevan.
ThinkRAG berkomitmen untuk menciptakan sistem aplikasi yang dapat digunakan secara langsung, berguna dan mudah digunakan.
Oleh karena itu, kami telah membuat pilihan dan trade-off yang cermat di antara berbagai model, komponen, dan teknologi.
Pertama, dengan menggunakan model besar, ThinkRAG mendukung OpenAI API dan semua LLM API yang kompatibel, termasuk produsen model besar arus utama dalam negeri, seperti:
Jika Anda ingin menerapkan model besar secara lokal, ThinkRAG memilih Ollama, yang sederhana dan mudah digunakan. Kita dapat mendownload model besar untuk dijalankan secara lokal melalui Ollama.
Saat ini, Ollama mendukung penerapan lokal dari hampir semua model besar arus utama, termasuk Llama, Gemma, GLM, Mistral, Phi, Llava, dll. Untuk lebih jelasnya silahkan kunjungi website resmi Ollama dibawah ini.
Sistem ini juga menggunakan model penyematan dan model yang disusun ulang, serta mendukung sebagian besar model dari Hugging Face. Saat ini, ThinkRAG terutama menggunakan model seri BGE BAAI. Pengguna domestik dapat mengunjungi situs web mirror untuk mempelajari dan mengunduh.
Setelah mengunduh kode dari Github, gunakan pip untuk menginstal komponen yang diperlukan.
pip3 install -r requirements.txtUntuk menjalankan sistem secara offline, silakan unduh terlebih dahulu Ollama dari situs resminya. Kemudian, gunakan perintah Ollama untuk mendownload model besar seperti GLM, Gemma, dan QWen.
Secara bersamaan, unduh model penyematan (BAAI/bge-large-zh-v1.5) dan model pemeringkatan ulang (BAAI/bge-reranker-base) dari Hugging Face ke direktori model lokal.
Untuk langkah spesifik, silakan merujuk ke dokumen di direktori dokumen: HowToDownloadModels.md
Untuk mendapatkan performa yang lebih baik, disarankan untuk menggunakan API LLM model besar komersial dengan ratusan miliar parameter.
Pertama, dapatkan kunci API dari penyedia layanan LLM dan konfigurasikan variabel lingkungan berikut.
ZHIPU_API_KEY = " "
MOONSHOT_API_KEY = " "
DEEPSEEK_API_KEY = " "
OPENAI_API_KEY = " "Anda dapat melewati langkah ini dan mengonfigurasi kunci API melalui antarmuka aplikasi setelah sistem berjalan.
Jika Anda memilih untuk menggunakan satu atau lebih LLM API, harap hapus penyedia layanan yang tidak lagi Anda gunakan di file konfigurasi config.py.
Tentu saja, Anda juga dapat menambahkan penyedia layanan lain yang kompatibel dengan OpenAI API di file konfigurasi.
ThinkRAG berjalan dalam mode pengembangan secara default. Dalam mode ini, sistem menggunakan penyimpanan file lokal dan Anda tidak perlu menginstal database apa pun.
Untuk beralih ke mode produksi, Anda dapat mengonfigurasi variabel lingkungan sebagai berikut.
THINKRAG_ENV = productionDalam mode produksi, sistem menggunakan database vektor Chroma dan database nilai kunci Redis.
Jika Anda belum menginstal Redis, disarankan untuk menginstalnya melalui Docker atau menggunakan instance Redis yang sudah ada. Harap konfigurasikan informasi parameter instance Redis di file config.py.
Sekarang, Anda siap menjalankan ThinkRAG.
Silakan jalankan perintah berikut pada direktori yang berisi file app.py.
streamlit run app.pySistem akan berjalan dan secara otomatis membuka URL berikut di browser untuk menampilkan antarmuka aplikasi.
http://localhost:8501/
Pengoperasian pertama mungkin memakan waktu cukup lama. Jika model yang disematkan pada Hugging Face tidak diunduh terlebih dahulu, sistem akan otomatis mengunduh model tersebut dan Anda harus menunggu lebih lama.
ThinkRAG mendukung konfigurasi dan pemilihan model besar di antarmuka pengguna, termasuk: URL Dasar dan kunci API dari API LLM model besar, dan Anda dapat memilih model spesifik yang akan digunakan, misalnya: glm-4 dari ThinkRAG.
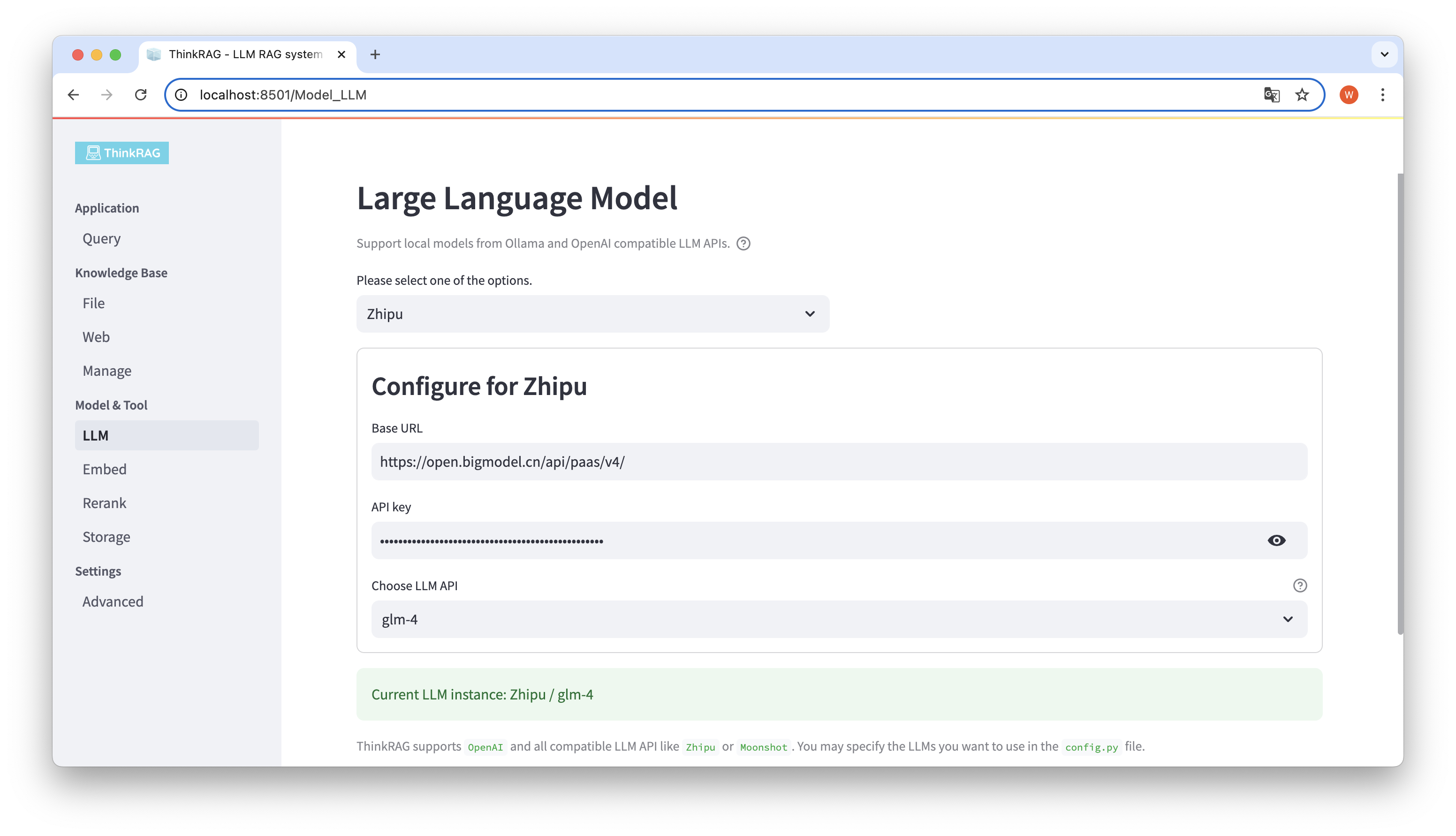
Sistem akan secara otomatis mendeteksi apakah API dan kunci tersedia. Jika tersedia, instance model besar yang dipilih saat ini akan ditampilkan dalam teks hijau di bagian bawah.
Demikian pula, sistem dapat secara otomatis mendapatkan model yang diunduh oleh Ollama, dan pengguna dapat memilih model yang diinginkan pada antarmuka pengguna.
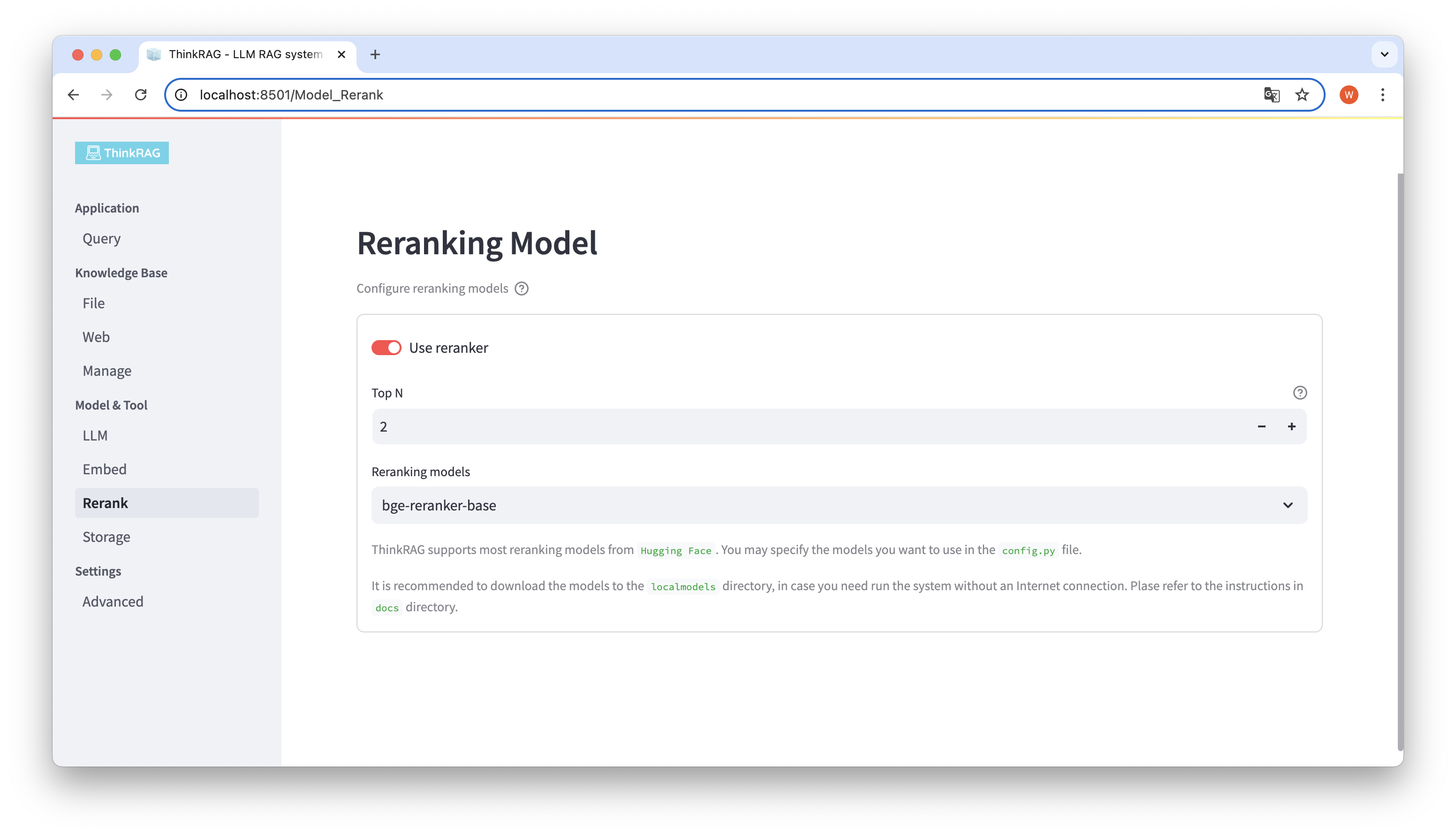
Jika Anda telah mengunduh model yang disematkan dan mengatur ulang model ke direktori localmodels lokal. Pada antarmuka pengguna, Anda dapat mengganti model yang dipilih dan mengatur parameter model yang disusun ulang, seperti Top N.
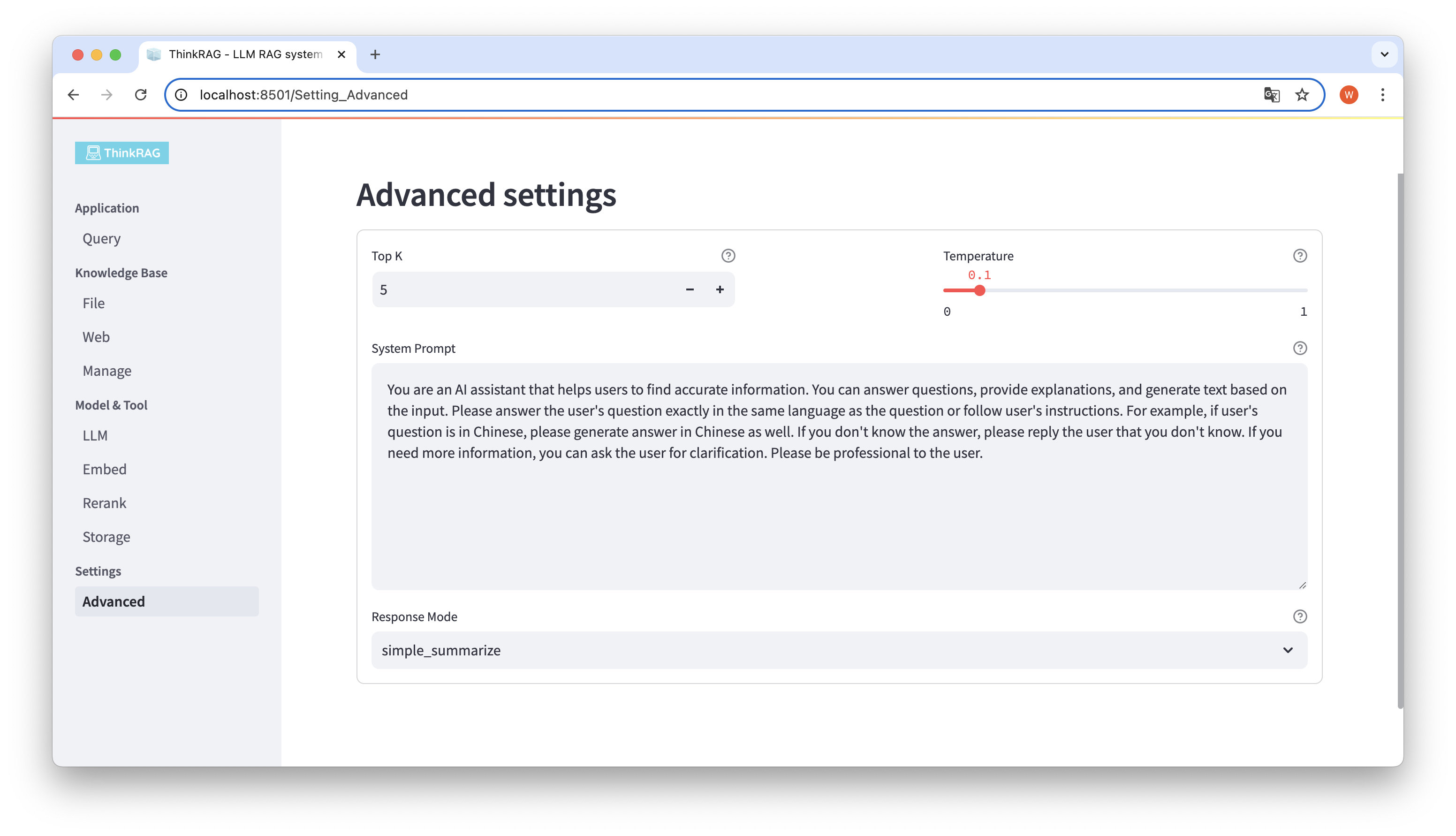
Di bilah navigasi kiri, klik Pengaturan Lanjutan (Pengaturan-Lanjutan).
Dengan menggunakan parameter yang berbeda, kita dapat membandingkan keluaran model yang besar dan menemukan kombinasi parameter yang paling efektif.
ThinkRAG mendukung pengunggahan berbagai file seperti PDF, DOCX, PPTX, dll., dan juga mendukung pengunggahan URL halaman web.
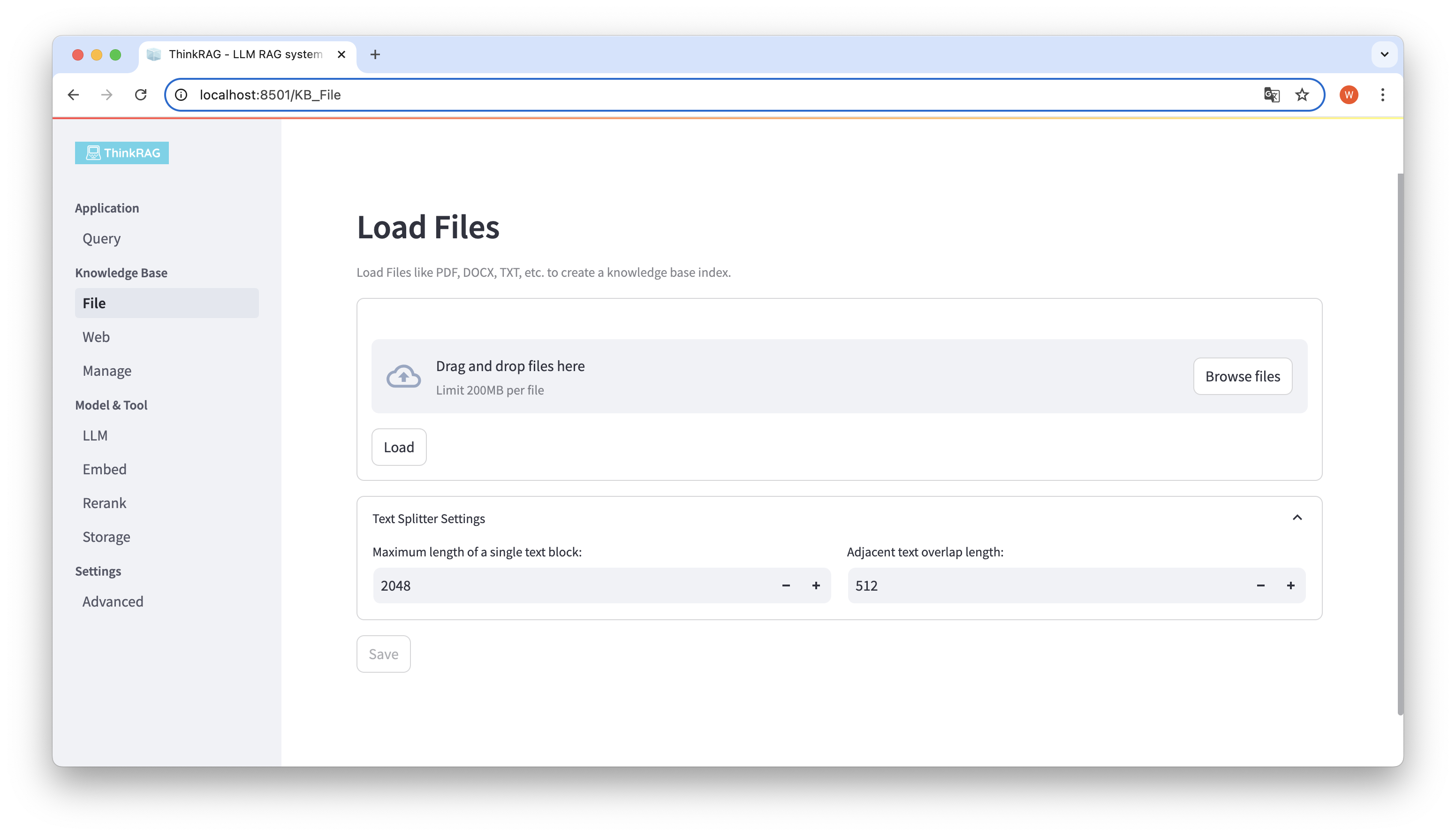
Klik tombol Telusuri file, pilih file di komputer Anda, lalu klik tombol Muat untuk memuat. Semua file yang dimuat akan dicantumkan.
Kemudian, klik tombol Simpan, dan sistem akan memproses file, termasuk segmentasi dan penyematan teks, dan menyimpannya ke basis pengetahuan.
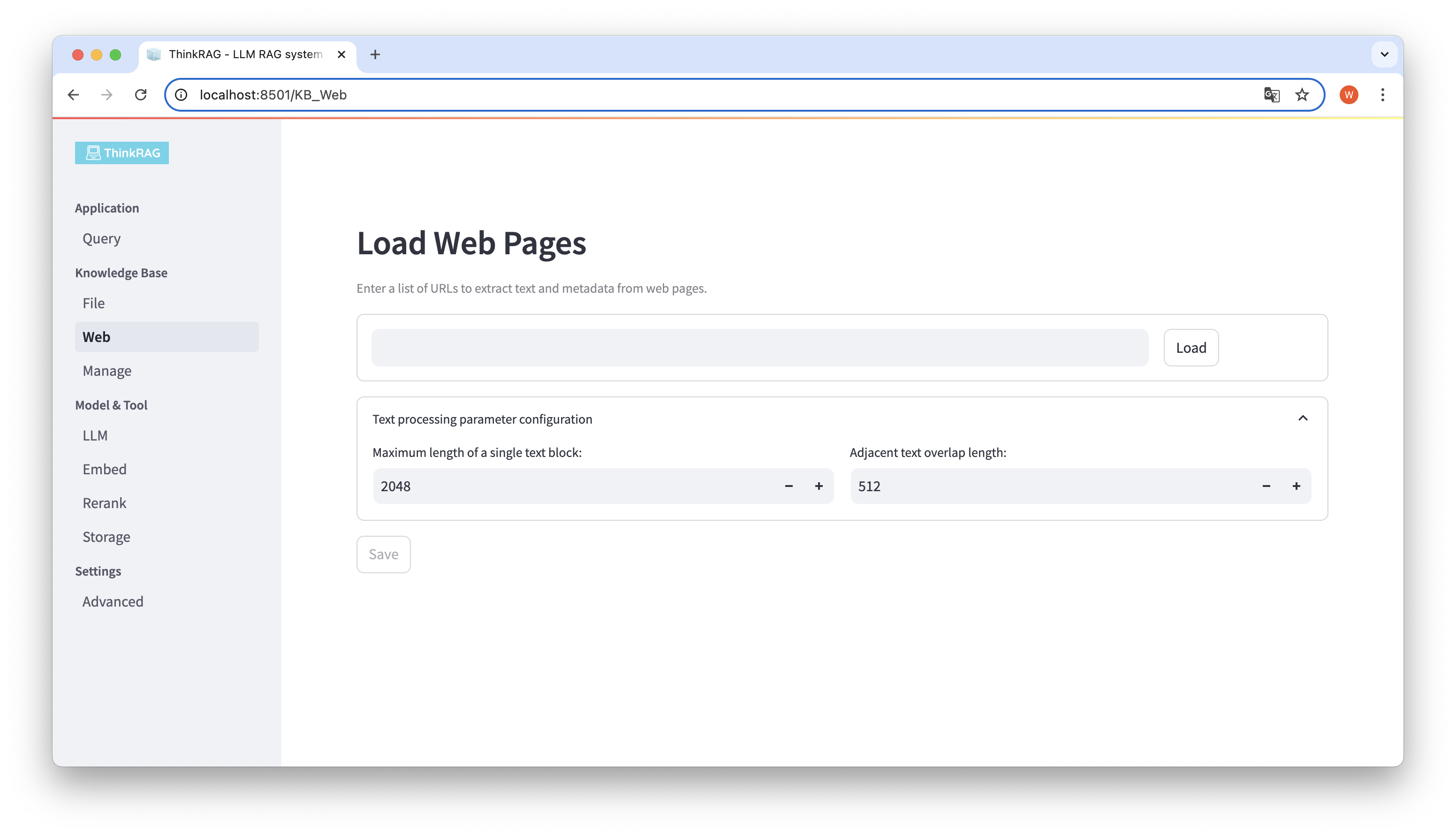
Demikian pula, Anda dapat memasukkan atau menempelkan URL halaman web, memperoleh informasi halaman web, dan menyimpannya ke basis pengetahuan setelah diproses.
Sistem ini mendukung pengelolaan basis pengetahuan.
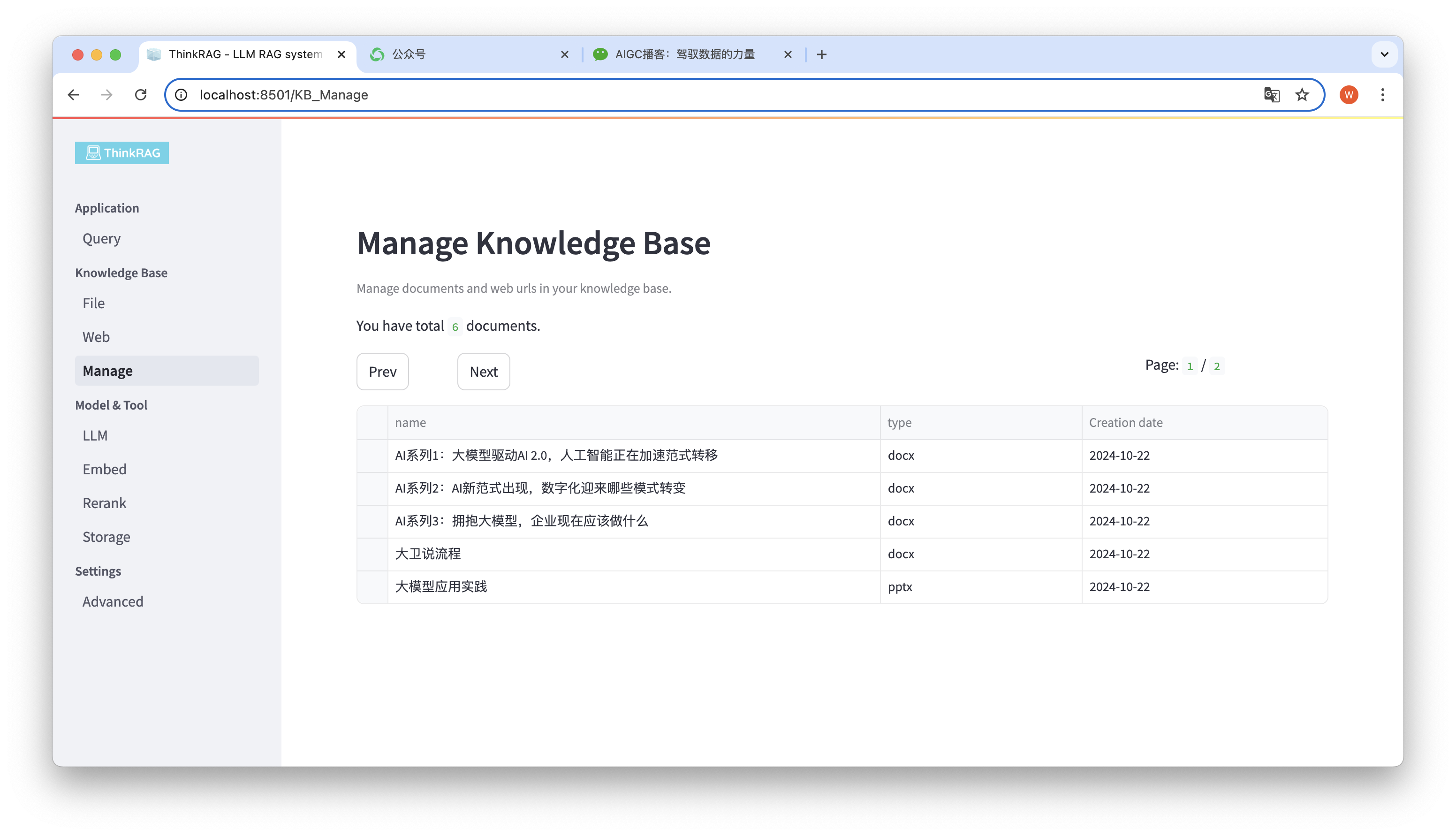
Seperti yang ditunjukkan pada gambar di atas, ThinkRAG dapat mencantumkan semua dokumen di basis pengetahuan dalam halaman.
Pilih dokumen yang akan dihapus, dan tombol Hapus dokumen yang dipilih akan muncul. Klik tombol ini untuk menghapus dokumen dari basis pengetahuan.
Di bilah navigasi kiri, klik Kueri, dan halaman Tanya Jawab cerdas akan muncul.
Setelah memasukkan pertanyaan, sistem akan mencari basis pengetahuan dan memberikan jawaban. Selama proses ini, sistem akan menggunakan teknologi seperti pengambilan hibrid dan penataan ulang untuk mendapatkan konten yang akurat dari basis pengetahuan.
Misalnya, kami telah mengunggah dokumen Word di basis pengetahuan: "David Says Process.docx".
Sekarang masukkan pertanyaan: "Apa tiga karakteristik suatu proses?"
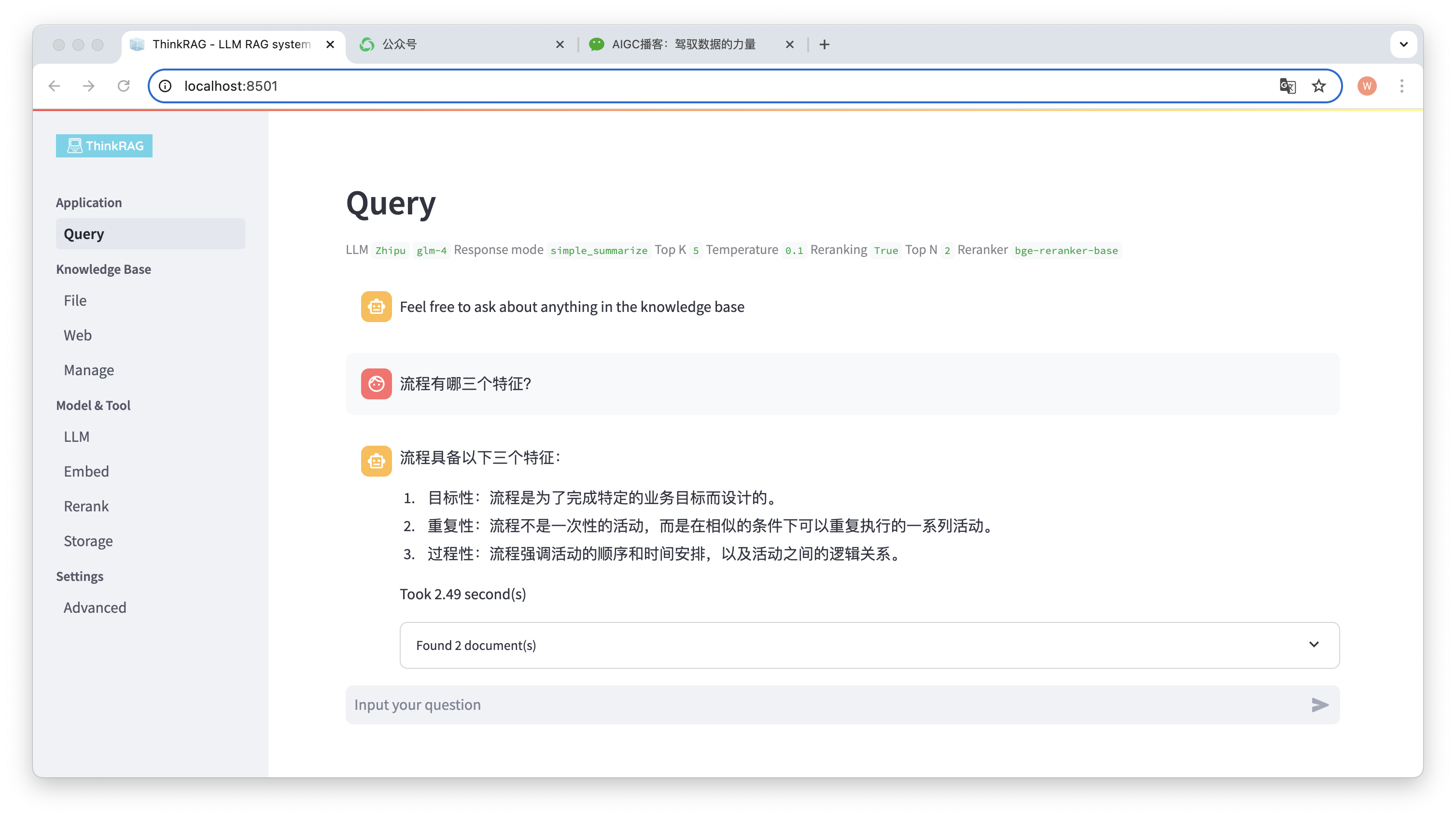
Seperti yang ditunjukkan pada gambar, sistem membutuhkan waktu 2,49 detik untuk memberikan jawaban yang akurat: prosesnya tepat sasaran, berulang, dan prosedural. Pada saat yang sama, sistem juga menyediakan 2 dokumen terkait yang diambil dari basis pengetahuan.
Dapat dilihat bahwa ThinkRAG secara lengkap dan efektif mengimplementasikan fungsi pengambilan model besar yang ditingkatkan berdasarkan basis pengetahuan lokal.
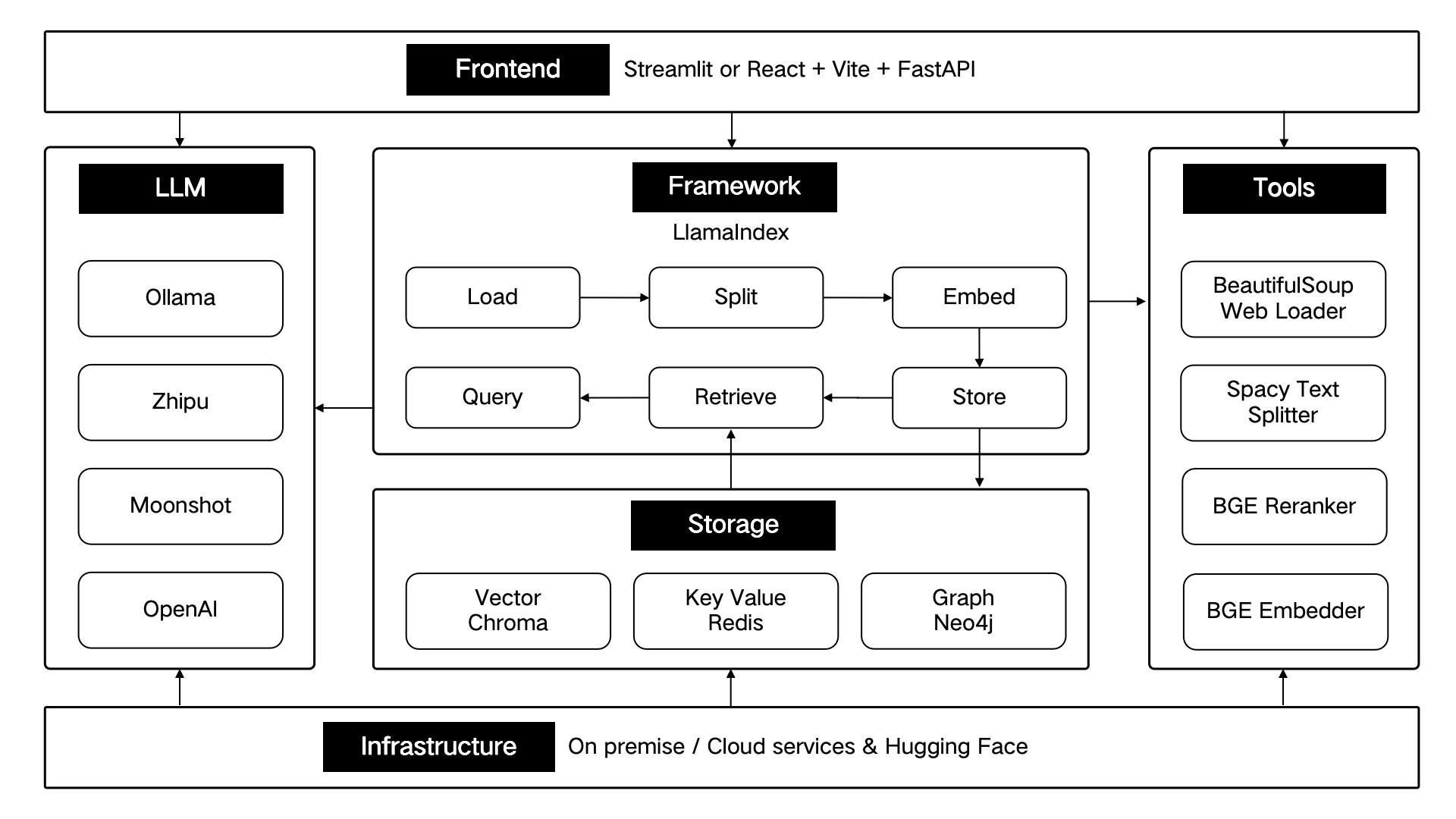
ThinkRAG dikembangkan menggunakan kerangka data LlamaIndex dan menggunakan Streamlit untuk front end. Mode pengembangan dan mode produksi sistem masing-masing menggunakan komponen teknis yang berbeda, seperti yang ditunjukkan pada tabel berikut:
| modus pengembangan | modus produksi | |
|---|---|---|
| kerangka RAG | Indeks Llama | Indeks Llama |
| kerangka front-end | Lampu aliran | Lampu aliran |
| model tertanam | BAAI/bge-kecil-zh-v1.5 | BAAI/bge-besar-zh-v1.5 |
| mengatur ulang modelnya | BAAI/bge-reranker-base | BAAI/bge-reranker-besar |
| pemisah teks | Pemisah Kalimat | SpacyTextSplitter |
| Penyimpanan percakapan | Toko Obrolan Sederhana | ulang |
| Penyimpanan dokumen | Toko Dokumen Sederhana | ulang |
| Penyimpanan indeks | Toko Indeks Sederhana | ulang |
| penyimpanan vektor | Toko Vektor Sederhana | LanceDB |
Komponen teknis ini dirancang secara arsitektural menurut enam bagian: front-end, kerangka kerja, model besar, alat, penyimpanan, dan infrastruktur.
Seperti yang ditunjukkan di bawah ini:
ThinkRAG akan terus mengoptimalkan fungsi inti dan terus meningkatkan efisiensi dan akurasi pengambilan, terutama meliputi:
Pada saat yang sama, kami akan terus meningkatkan arsitektur aplikasi dan meningkatkan pengalaman pengguna, terutama meliputi:
Anda dipersilakan untuk bergabung dengan proyek sumber terbuka ThinkRAG dan bekerja sama untuk menciptakan produk AI yang disukai pengguna!
ThinkRAG menggunakan lisensi MIT.


