local LLM with RAG
1.0.0

Proyek ini adalah kotak pasir eksperimental untuk menguji ide-ide terkait menjalankan Model Bahasa Besar (LLM) lokal dengan Ollama untuk melakukan Retrieval-Augmented Generation (RAG) untuk menjawab pertanyaan berdasarkan contoh PDF. Dalam proyek ini, kami juga menggunakan Ollama untuk membuat penyematan dengan teks penyematan nomic untuk digunakan dengan Chroma. Harap perhatikan bahwa penyematan dimuat ulang setiap kali aplikasi dijalankan, yang tidak efisien dan hanya dilakukan di sini untuk tujuan pengujian.
Ada juga UI web yang dibuat menggunakan Streamlit untuk memberikan cara berbeda dalam berinteraksi dengan Ollama.
python3 -m venv .venv .source .venv/bin/activate di Unix atau MacOS, atau ..venvScriptsactivate di Windows.pip install -r requirements.txt . Catatan: Pertama kali Anda menjalankan proyek, model yang diperlukan dari Ollama untuk LLM dan penyematannya akan diunduh. Ini adalah proses penyiapan satu kali dan mungkin memerlukan waktu tergantung pada koneksi internet Anda.
python app.py -m <model_name> -p <path_to_documents> untuk menentukan model dan jalur ke dokumen. Jika tidak ada model yang ditentukan, maka defaultnya adalah mistral. Jika tidak ada jalur yang ditentukan, maka defaultnya adalah Research yang terletak di repositori untuk tujuan contoh.-e <embedding_model_name> . Jika tidak ditentukan, defaultnya adalah nomic-embed-text. Ini akan memuat file PDF dan Markdown, menghasilkan penyematan, menanyakan koleksi, dan menjawab pertanyaan yang ditentukan di app.py .
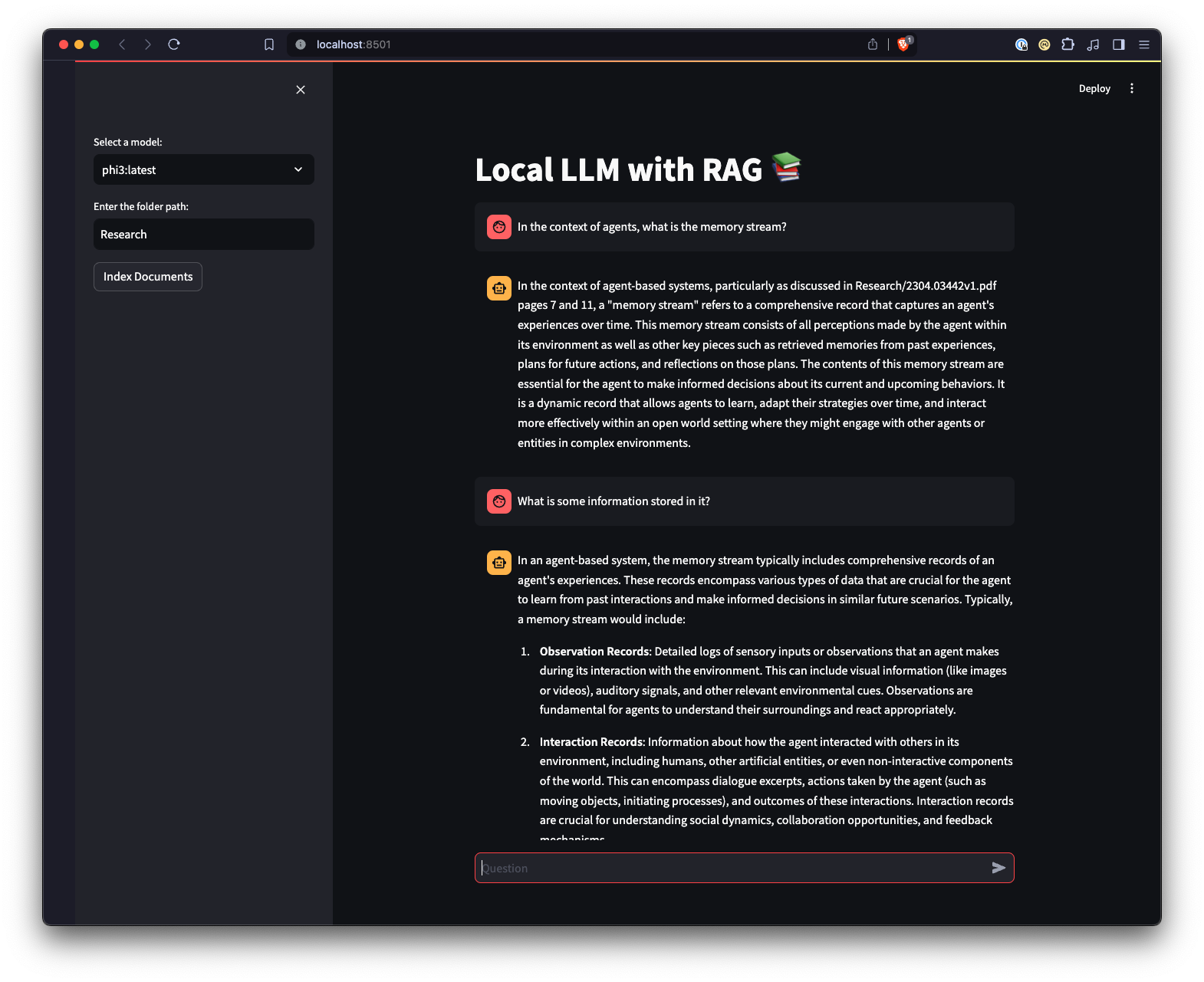
ui.pystreamlit run ui.py di terminal Anda.Ini akan memulai server web lokal dan membuka tab baru di browser web default Anda tempat Anda dapat berinteraksi dengan aplikasi tersebut. Streamlit UI memungkinkan Anda memilih model, memilih folder, menyediakan cara yang lebih mudah dan intuitif untuk berinteraksi dengan sistem chatbot RAG dibandingkan dengan antarmuka baris perintah. Aplikasi akan menangani pemuatan dokumen, menghasilkan embeddings, menanyakan koleksi, dan menampilkan hasilnya secara interaktif.


