duplicut
v2.2 release
Saat ini, pembuatan daftar kata kata sandi biasanya berarti menggabungkan beberapa sumber data.
Idealnya, sebagian besar kemungkinan kata sandi harus berada di awal daftar kata, sehingga sebagian besar kata sandi umum dapat dipecahkan secara instan.
Dengan alat dedupe yang ada, Anda dipaksa untuk memilih apakah Anda lebih suka mempertahankan urutan ATAU menangani daftar kata yang sangat besar .
Sayangnya, pembuatan daftar kata memerlukan keduanya :

Jadi saya menulis duplikat dalam C yang sangat dioptimalkan untuk memenuhi kebutuhan yang sangat spesifik ini?
git clone https://github.com/nil0x42/duplicut
cd duplicut/ && make
./duplicut wordlist.txt -o clean-wordlist.txt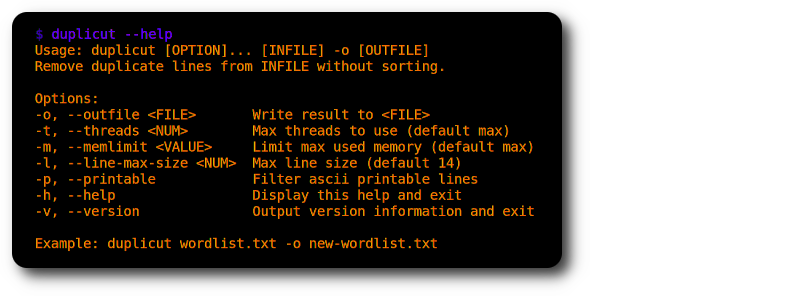
Fitur :
-l )-p )Implementasi :
Keterbatasan :
Sebuah uint64 cukup untuk mengindeks baris dalam hashmap, dengan mengemas informasi size dalam bit tambahan pointer:
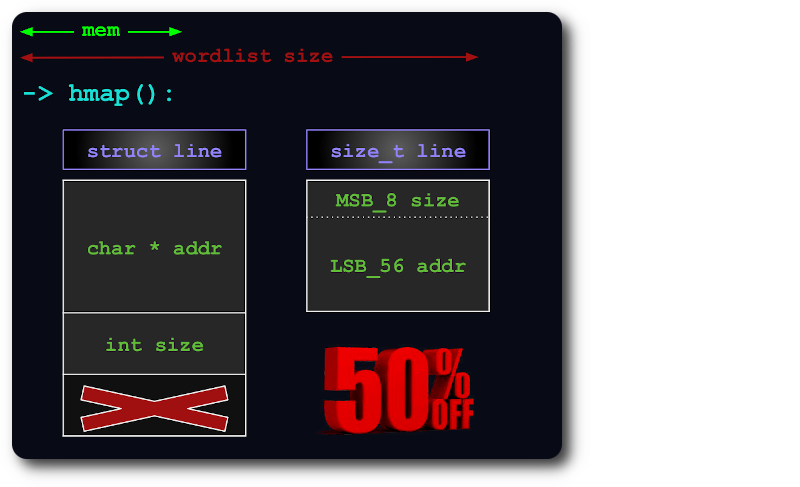
Jika seluruh file tidak dapat ditampung dalam memori, maka file tersebut akan dipecah menjadi beberapa bagian virtual, sedemikian rupa sehingga setiap bagian menggunakan RAM sebanyak mungkin.
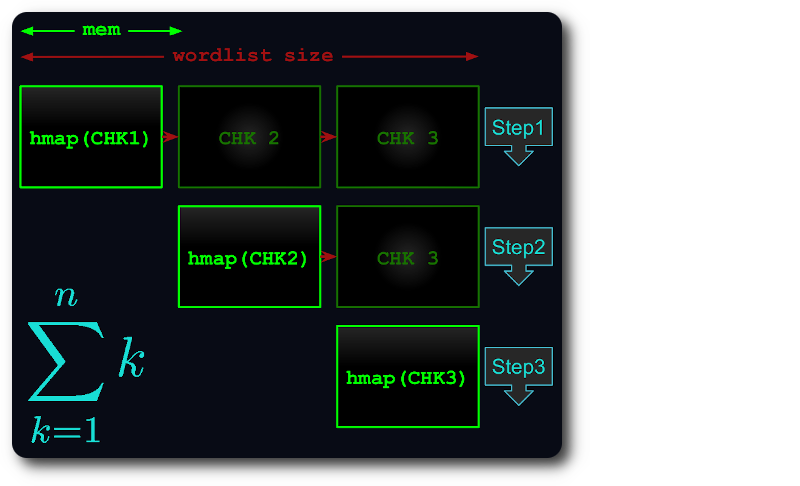
Setiap potongan kemudian dimuat ke dalam hashmap, dideduplikasi, dan diuji terhadap potongan berikutnya.
Dengan begitu, waktu eksekusi dikurangi menjadi paling banyak bilangan segitiga :
Jika Anda menemukan bug, atau sesuatu tidak berfungsi seperti yang diharapkan, harap kompilasi duplikat dalam mode debug dan posting masalah dengan keluaran terlampir:
# debug level can be from 1 to 4
make debug level=1
./duplicut [OPTIONS] 2>&1 | tee /tmp/duplicut-debug.log


