dream
v1.13.0
DeepPavlov Dream adalah platform untuk menciptakan asisten AI generatif multi-keterampilan.
Untuk mempelajari lebih lanjut tentang platform ini dan cara membuat asisten AI dengannya, silakan kunjungi Dream. Jika Anda ingin mempelajari lebih lanjut tentang Agen DeepPavlov yang mendukung Dream, kunjungi dokumentasi Agen DeepPavlov.
Kami telah menyertakan enam distribusi: empat di antaranya didasarkan pada sosialbot Deepy yang ringan, satu adalah chatbot Dream berukuran penuh (berdasarkan versi Alexa Prize Challenge) dalam bahasa Inggris dan chatbot Dream dalam bahasa Rusia.
Versi dasar asisten Lunar. Deepy Base berisi anotator Spelling Preprocessing, Harvesters Maintenance Skill berbasis template, dan Skill Program-y domain terbuka berbasis AIML berdasarkan Dialog Flow Framework.
Versi lanjutan dari asisten Bulan. Deepy Advanced berisi Pemrosesan Awal Ejaan, Segmentasi Kalimat, Penautan Entitas, dan anotator Penangkap Niat, Keterampilan GoBot Pemeliharaan Pemanen untuk respons berorientasi tujuan, dan Keterampilan Program-y domain terbuka berbasis AIML berdasarkan Kerangka Alur Dialog.
Versi FAQ asisten Lunar. Deepy FAQ berisi anotator Ejaan Prapemrosesan, Keterampilan Pertanyaan Umum berbasis template, dan Keterampilan Program-y domain terbuka berbasis AIML berdasarkan Kerangka Alur Dialog.
Versi asisten Lunar yang berorientasi pada tujuan. Basis GoBot yang Dalam berisi anotator Ejaan Prapemrosesan, Keterampilan GoBot Pemeliharaan Pemanen untuk respons berorientasi tujuan, dan Keterampilan Program-y domain terbuka berbasis AIML berdasarkan Kerangka Alur Dialog.
Versi lengkap DeepPavlov Dream Socialbot. Ini adalah versi yang hampir sama dari DREAM socialbot seperti pada akhir Alexa Prize Challenge 4. Beberapa layanan API diganti dengan model yang dapat dilatih. Beberapa layanan (misalnya, News Annotator, Game Skill, Weather Skill) memerlukan kunci pribadi untuk API yang mendasarinya, sebagian besar dapat diperoleh secara gratis. Jika Anda ingin menggunakan layanan ini dalam penerapan lokal, tambahkan kunci Anda ke variabel lingkungan (misalnya, ./.env , ./.env_ru ). Versi Dream Socialbot ini menghabiskan banyak sumber daya karena arsitektur modular dan tujuan aslinya (partisipasi dalam Alexa Prize Challenge). Kami menyediakan demo Dream Socialbot di website kami.
Versi mini dari DeepPavlov Dream Socialbot. Ini adalah socialbot berbasis generatif yang menggunakan model DialoGPT Bahasa Inggris untuk menghasilkan sebagian besar respons. Ini juga berisi komponen penangkap maksud dan responden untuk mencakup permintaan pengguna khusus. Tautan ke distribusi.
DeepPavlov Dream Socialbot versi Rusia. Ini adalah bot sosial berbasis generatif yang menggunakan DialoGPT Rusia oleh DeepPavlov untuk menghasilkan sebagian besar respons. Ini juga berisi komponen penangkap maksud dan responden untuk mencakup permintaan pengguna khusus. Tautan ke distribusi.
Versi mini DeepPavlov Dream Socialbot dengan penggunaan model generatif berbasis prompt. Ini adalah bot sosial berbasis generatif yang menggunakan model bahasa besar untuk menghasilkan sebagian besar respons. Anda dapat mengunggah perintah Anda sendiri (file json) ke common/prompts, menambahkan nama perintah ke PROMPTS_TO_CONSIDER (dipisahkan koma), dan informasi yang diberikan akan digunakan dalam pembuatan balasan yang didukung LLM sebagai perintah. Tautan ke distribusi.
docker dari 20 ke atas;docker-compose v1.29.2; git clone https://github.com/deeppavlov/dream.git
Jika Anda mendapatkan kesalahan "Izin ditolak" saat menjalankan pembuatan buruh pelabuhan, pastikan untuk mengonfigurasi pengguna buruh pelabuhan Anda dengan benar.
docker-compose -f docker-compose.yml -f assistant_dists/deepy_base/docker-compose.override.yml up --build
docker-compose -f docker-compose.yml -f assistant_dists/deepy_adv/docker-compose.override.yml up --build
docker-compose -f docker-compose.yml -f assistant_dists/deepy_faq/docker-compose.override.yml up --build
docker-compose -f docker-compose.yml -f assistant_dists/deepy_gobot_base/docker-compose.override.yml up --build
Cara termudah untuk mencoba Dream adalah menyebarkannya melalui proxy. Semua permintaan akan dialihkan ke API DeepPavlov, jadi Anda tidak perlu menggunakan sumber daya lokal apa pun. Lihat penggunaan proxy untuk detailnya.
docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml -f assistant_dists/dream/proxy.yml up --build
Harap diperhatikan, bahwa komponen DeepPavlov Dream memerlukan banyak sumber daya. Lihat bagian komponen untuk melihat perkiraan kebutuhan.
docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml up --build
Kami juga menyertakan konfigurasi dengan alokasi GPU untuk lingkungan multi-GPU:
AGENT_PORT=4242 docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml -f assistant_dists/dream/test.yml up
Saat Anda perlu memulai ulang kontainer buruh pelabuhan tertentu tanpa membangun kembali (pastikan pemetaan di assistant_dists/dream/dev.yml sudah benar):
AGENT_PORT=4242 docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml restart container-name
docker-compose -f docker-compose.yml -f assistant_dists/dream_persona_prompted/docker-compose.override.yml -f assistant_dists/dream_persona_prompted/dev.yml -f assistant_dists/dream_persona_prompted/proxy.yml up --build
Kami juga menyertakan konfigurasi dengan alokasi GPU untuk lingkungan multi-GPU.
Agen DeepPavlov menyediakan beberapa opsi untuk interaksi: antarmuka baris perintah, API HTTP, dan bot Telegram
Di tab terminal terpisah, jalankan:
docker-compose exec agent python -m deeppavlov_agent.run agent.channel=cmd agent.pipeline_config=assistant_dists/dream/pipeline_conf.json
Masukkan nama pengguna Anda dan ngobrol dengan Dream!
Setelah Anda memulai bot, API Agen DeepPavlov akan berjalan di http://localhost:4242 . Anda dapat mempelajari tentang API dari Dokumen Agen DeepPavlov.
Antarmuka obrolan dasar akan tersedia di http://localhost:4242/chat .
Saat ini, bot Telegram digunakan sebagai pengganti HTTP API. Edit definisi command agent di dalam konfigurasi docker-compose.override.yml :
agent:
command: sh -c 'bin/wait && python -m deeppavlov_agent.run agent.channel=telegram agent.telegram_token=<TELEGRAM_BOT_TOKEN> agent.pipeline_config=assistant_dists/dream/pipeline_conf.json'
CATATAN: perlakukan token Telegram Anda sebagai rahasia dan jangan simpan ke repositori publik!
Dream menggunakan beberapa file konfigurasi pembuatan buruh pelabuhan:
./docker-compose.yml adalah konfigurasi inti yang mencakup kontainer untuk Agen DeepPavlov dan database mongo;
./assistant_dists/*/docker-compose.override.yml mencantumkan semua komponen untuk distribusi;
./assistant_dists/dream/dev.yml menyertakan pengikatan volume untuk memudahkan proses debug Dream;
./assistant_dists/dream/proxy.yml adalah daftar kontainer yang diproksi.
Jika sumber daya penerapan Anda terbatas, Anda dapat mengganti kontainer dengan salinan proksi yang dihosting oleh DeepPavlov. Untuk melakukannya, ganti definisi kontainer tersebut di dalam proxy.yml , misalnya:
convers-evaluator-annotator:
command: ["nginx", "-g", "daemon off;"]
build:
context: dp/proxy/
dockerfile: Dockerfile
environment:
- PROXY_PASS=proxy.deeppavlov.ai:8004
- SERVICE_PORT=8004
dan sertakan konfigurasi ini dalam perintah penerapan Anda:
docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml -f assistant_dists/dream/proxy.yml up --build
Secara default, proxy.yml berisi semua definisi proksi yang tersedia.
Arsitektur Impian disajikan pada gambar berikut: 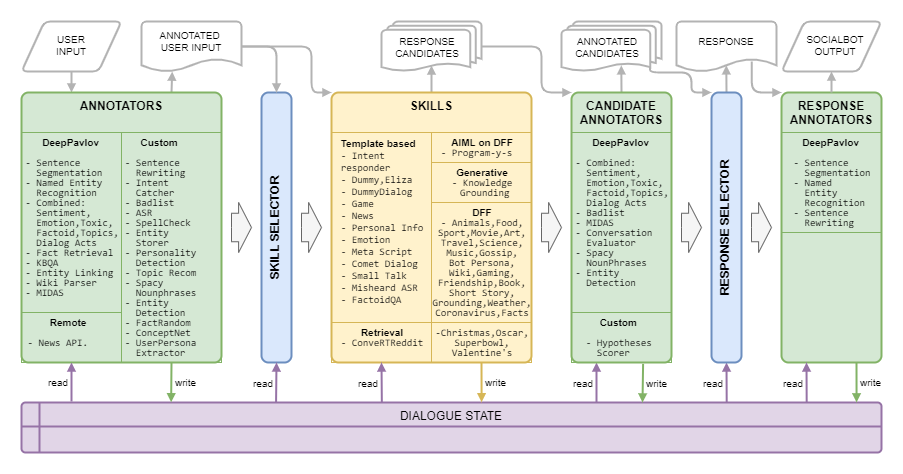
| Nama | Persyaratan | Keterangan |
|---|---|---|
| Pemilih Berbasis Aturan | Algoritma yang memilih daftar keterampilan untuk menghasilkan respons kandidat terhadap konteks saat ini berdasarkan topik, entitas, emosi, toksisitas, tindakan dialog, dan riwayat dialog | |
| Pemilih Respon | RAM 50 MB | Algoritma yang memilih respons akhir di antara daftar kandidat respons yang diberikan |
| Nama | Persyaratan | Keterangan |
|---|---|---|
| ASR | RAM 40MB | menghitung keseluruhan keyakinan ASR untuk ucapan tertentu dan menilainya sebagai sangat rendah , rendah , sedang , atau tinggi (untuk markup Amazon) |
| Kata-kata yang Masuk Daftar Buruk | RAM 150 MB | mendeteksi kata dan frasa dari daftar buruk |
| Klasifikasi Gabungan | RAM 1,5 GB, GPU 3,5 GB | Model berbasis BERT meliputi klasifikasi topik, klasifikasi tindakan dialog, sentimen, toksisitas, emosi, klasifikasi factoid |
| Klasifikasi Gabungan ringan | RAM 1,6 GB | Model yang sama dengan Klasifikasi Gabungan, namun membutuhkan waktu 42% lebih sedikit berkat tulang punggung yang lebih ringan |
| COMeT Atom | RAM 2 GB, GPU 1,1 GB | Model prediksi yang masuk akal COMeT Atomic |
| COMeT ConceptNet | RAM 2 GB, GPU 1,1 GB | Model prediksi yang masuk akal COMeT ConceptNet |
| Anotator Evaluator Percakapan | RAM 1 GB, GPU 4,5 GB | dilatih berdasarkan data Alexa Prize dari kompetisi sebelumnya dan memprediksi apakah respons kandidat menarik, dapat dipahami, sesuai topik, menarik, atau salah |
| Klasifikasi Emosi | RAM 2,5GB | anotator klasifikasi emosi |
| Deteksi Entitas | RAM 1,5 GB, GPU 3,2 GB | mengekstrak entitas dan tipenya dari ucapan |
| Tautan Entitas | RAM 2,5 GB, GPU 1,3 GB | menemukan id entitas Wikidata untuk entitas yang terdeteksi dengan Deteksi Entitas |
| Penyimpanan Entitas | RAM-nya 220 MB | komponen berbasis aturan, yang menyimpan entitas dari ucapan pengguna dan bot sosial jika ekspresi opini terdeteksi dengan pola atau Pengklasifikasi MIDAS dan menyimpannya bersama dengan sikap yang terdeteksi terhadap status dialog |
| Fakta Acak | RAM 50 MB | mengembalikan fakta acak untuk entitas tertentu (untuk entitas dari ucapan pengguna) |
| Pengambilan Fakta | RAM 7,4 GB, GPU 1,2 GB | mengekstrak fakta dari Wikipedia dan wikiHow |
| Penangkap Niat | RAM 1,7 GB, GPU 2,4 GB | mengklasifikasikan ucapan pengguna ke dalam sejumlah maksud yang telah ditentukan sebelumnya yang dilatih pada serangkaian frasa dan ekspresi reguler |
| KBQA | RAM 2 GB, GPU 1,4 GB | menjawab pertanyaan fakta pengguna berdasarkan Wikidata KB |
| Klasifikasi MIDAS | RAM 1,1 GB, GPU 4,5 GB | Model berbasis BERT dilatih pada subset kelas semantik dari dataset MIDAS |
| Prediktor MIDAS | RAM-nya 30 MB | Model berbasis BERT dilatih pada subset kelas semantik dari dataset MIDAS |
| Ner | RAM 2,2 GB, GPU 5 GB | mengekstrak nama orang, nama lokasi, organisasi dari teks tanpa huruf besar |
| Anotator API Berita | RAM-nya 80 MB | mengekstrak berita terbaru tentang entitas atau topik menggunakan GNews API. Penerapan DeepPavlov Dream menggunakan kunci API kami sendiri. |
| Penangkap Kepribadian | RAM-nya 30 MB | keahliannya adalah mengubah deskripsi kepribadian sistem melalui antarmuka obrolan, ini berfungsi sebagai perintah sistem, responsnya adalah pesan seperti sistem |
| Pemilih Cepat | RAM 50 MB | Anotator menggunakan Sentence Ranker untuk menentukan peringkat perintah dan memilih N_SENTENCES_TO_RETURN perintah yang paling relevan (berdasarkan pertanyaan yang diberikan dalam perintah) |
| Ekstraksi Properti | RAM 6,3 GiB | mengekstrak atribut pengguna dari ucapan |
| Rake Kata Kunci | RAM 40MB | mengekstrak kata kunci dari ucapan dengan bantuan algoritma RAKE |
| Ekstraktor Persona Relatif | RAM 50MB | Anotator menggunakan Sentence Ranker untuk menentukan peringkat kalimat persona dan memilih N_SENTENCES_TO_RETURN kalimat yang paling relevan |
| Sentrewrite | RAM 200MB | menulis ulang ucapan pengguna dengan mengganti kata ganti dengan nama spesifik yang memberikan informasi lebih berguna untuk komponen hilir |
| Senseg | RAM 1 GB | memungkinkan kami menangani ucapan pengguna yang panjang dan rumit dengan membaginya menjadi kalimat dan memulihkan tanda baca |
| Frase Kata Benda Spacy | RAM 180MB | mengekstrak frasa kata benda menggunakan Spacy dan memfilter frasa umum |
| Pengklasifikasi Fungsi Ucapan | RAM 1,1 GB, GPU 4,5 GB | algoritma hierarki berdasarkan beberapa model linier dan pendekatan berbasis aturan untuk prediksi fungsi ucapan yang dijelaskan oleh Eggins dan Slade |
| Prediktor Fungsi Ucapan | RAM 1,1 GB, GPU 4,5 GB | menghasilkan probabilitas fungsi ucapan yang dapat mengikuti fungsi ucapan yang diprediksi oleh Pengklasifikasi Fungsi Ucapan |
| Pemrosesan Awal Ejaan | RAM 50 MB | komponen berbasis pola untuk menulis ulang ekspresi sehari-hari yang berbeda ke gaya percakapan yang lebih formal |
| Rekomendasi Topik | RAM-nya 40 MB | menawarkan topik untuk percakapan lebih lanjut menggunakan informasi tentang topik yang dibahas dan preferensi pengguna. Versi saat ini didasarkan pada kepribadian Reddit (lihat Laporan Mimpi untuk Alexa Prize 4). |
| Klasifikasi Beracun | RAM 3,5 GB, GPU 3 GB | Model klasifikasi racun dari Transformers ditetapkan sebagai PRETRAINED_MODEL_NAME_OR_PATH |
| Ekstraktor Persona Pengguna | RAM-nya 40 MB | menentukan kategori usia pengguna berdasarkan beberapa kata kunci |
| Pengurai Wiki | RAM 100 MB | mengekstrak kembar tiga Wikidata untuk entitas yang terdeteksi dengan Penautan Entitas |
| Fakta Wiki | RAM 1,7GB | model yang mengekstrak fakta terkait dari halaman Wikipedia dan WikiHow |
| Nama | Persyaratan | Keterangan |
|---|---|---|
| DialogGPT | RAM 1,2 GB, GPU 2,1 GB | layanan generatif berdasarkan model generatif Transformers, model diatur dalam argumen penulisan buruh pelabuhan PRETRAINED_MODEL_NAME_OR_PATH (misalnya, microsoft/DialoGPT-small dengan 0,2-0,5 detik pada GPU) |
| DialoGPT berbasis Persona | RAM 1,2 GB, GPU 2,1 GB | layanan generatif berdasarkan model generatif Transformers, model tersebut telah dilatih sebelumnya pada kumpulan data PersonaChat untuk menghasilkan respons yang dikondisikan pada beberapa kalimat persona socialbot |
| Keterangan Gambar | RAM 4 GB, GPU 5,4 GB | membuat representasi teks dari gambar yang diterima |
| Mengisi | RAM 1 GB, GPU 1,2 GB | (dimatikan tetapi kode tersedia) layanan generatif berdasarkan model Infilling, untuk ucapan tertentu mengembalikan ucapan di mana _ dari teks asli diganti dengan token yang dihasilkan |
| Landasan Pengetahuan | RAM 2 GB, GPU 2,1 GB | layanan generatif berdasarkan arsitektur BlenderBot memberikan respons terhadap konteks dengan mempertimbangkan paragraf teks tambahan |
| LM bertopeng | RAM 1,1 GB, GPU 1 GB | (dimatikan tetapi kode tersedia) |
| Seq2seq berbasis Persona | RAM 1,5 GB, GPU 1,5 GB | layanan generatif berdasarkan model Transformers seq2seq, model tersebut telah dilatih sebelumnya pada kumpulan data PersonaChat untuk menghasilkan respons yang dikondisikan pada beberapa kalimat persona socialbot |
| Pemeringkatan Kalimat | RAM 1,2 GB, GPU 2,1 GB | model peringkat diberikan sebagai PRETRAINED_MODEL_NAME_OR_PATH yang untuk kalimat berpasangan mengembalikan skor korespondensi mengambang |
| CeritaGPT | RAM 2,6 GB, GPU 2,15 GB | layanan generatif berdasarkan GPT-2 yang disempurnakan, untuk kumpulan kata kunci tertentu mengembalikan cerita pendek menggunakan kata kunci |
| GPT-3.5 | RAM 100 MB | layanan generatif berdasarkan layanan OpenAI API, model diatur dalam argumen penulisan buruh pelabuhan PRETRAINED_MODEL_NAME_OR_PATH (khususnya, dalam layanan ini, text-davinci-003 digunakan. |
| ObrolanGPT | RAM 100 MB | layanan generatif berdasarkan layanan OpenAI API, model diatur dalam argumen penulisan buruh pelabuhan PRETRAINED_MODEL_NAME_OR_PATH (khususnya, dalam layanan ini, gpt-3.5-turbo digunakan. |
| Cerita CepatGPT | RAM 3 GB, GPU 4 GB | layanan generatif berdasarkan GPT-2 yang disempurnakan, untuk topik tertentu yang diwakili oleh satu kata benda mengembalikan cerita pendek tentang topik tertentu |
| GPT-J 6B | RAM 1,5 GB, GPU 24,2 GB | layanan generatif berdasarkan model generatif Transformers, model diatur dalam argumen penulisan buruh pelabuhan PRETRAINED_MODEL_NAME_OR_PATH (khususnya, dalam layanan ini, model GPT-J digunakan. |
| BLOOMZ 7B | RAM 2,5 GB, GPU 29 GB | layanan generatif berdasarkan model generatif Transformers, model diatur dalam argumen penulisan buruh pelabuhan PRETRAINED_MODEL_NAME_OR_PATH (khususnya, dalam layanan ini, model BLOOMZ-7b1 digunakan. |
| GPT-JT 6B | RAM 2,5 GB, GPU 25,1 GB | layanan generatif berdasarkan model generatif Transformers, model diatur dalam argumen penulisan buruh pelabuhan PRETRAINED_MODEL_NAME_OR_PATH (khususnya, dalam layanan ini, model GPT-JT digunakan. |
| Nama | Persyaratan | Keterangan |
|---|---|---|
| Pengendali Alexa | RAM-nya 30 MB | pengendali untuk beberapa perintah Alexa tertentu |
| Keterampilan Natal | RAM-nya 30 MB | mendukung FAQ, fakta, dan skrip untuk Natal |
| Keterampilan Dialog Komet | RAM 300MB | menggunakan model COMeT ConceptNet untuk mengungkapkan pendapat, mengajukan pertanyaan atau memberikan komentar tentang tindakan pengguna yang disebutkan dalam dialog |
| Konversi Reddit | RAM 1,2 GB | menggunakan encoder ConveRT untuk membangun representasi kalimat yang efisien |
| Keterampilan Boneka | bagian dari wadah agen | keterampilan cadangan dengan beberapa respons kandidat yang tidak beracun |
| Dialog Keterampilan Dummy | RAM 600 MB | mengembalikan giliran berikutnya dari kumpulan data Obrolan Topikal jika respons pengguna terhadap Keterampilan Dummy serupa dengan respons terkait di data sumber |
| Eliza | RAM-nya 30MB | Bot Obrolan (https://github.com/wadetb/eliza) |
| Keterampilan Emosi | RAM 40MB | mengembalikan respons template terhadap emosi yang terdeteksi oleh Klasifikasi Emosi dari anotator Klasifikasi Gabungan |
| QA fakta | RAM-nya 170 MB | menjawab pertanyaan faktual |
| Keterampilan Kooperatif Permainan | RAM 100 MB | memberi pengguna percakapan tentang permainan komputer: grafik permainan terbaik selama setahun terakhir, bulan lalu, dan minggu lalu |
| Keterampilan Pemeliharaan Pemanen | RAM-nya 30 MB | Keterampilan pemeliharaan pemanen |
| Keterampilan Gobot Pemeliharaan Pemanen | RAM-nya 30 MB | Pemeliharaan pemanen Keterampilan berorientasi pada tujuan |
| Keterampilan Landasan Pengetahuan | RAM 100 MB | menghasilkan respons berdasarkan riwayat dialog dan memberikan pengetahuan terkait topik percakapan saat ini |
| Keterampilan Skrip Meta | RAM 150 MB | memberikan dialog multi-putaran seputar aktivitas manusia. Keterampilan tersebut menggunakan model COMeT Atomic untuk menghasilkan deskripsi dan pertanyaan yang masuk akal pada beberapa aspek |
| Salah dengar ASR | RAM 40MB | menggunakan anotasi Prosesor ASR untuk memberikan umpan balik kepada pengguna ketika kepercayaan ASR terlalu rendah |
| Keterampilan API Berita | RAM 60MB | menyajikan berita terkini dengan peringkat teratas tentang entitas atau topik menggunakan GNews API |
| Keterampilan Oscar | RAM-nya 30 MB | mendukung FAQ, fakta, dan skrip untuk Oscar |
| Keterampilan Info Pribadi | RAM-nya 40 MB | menanyakan dan menyimpan nama pengguna, tempat lahir, dan lokasi |
| Keterampilan Y Program DFF | RAM-nya 800 MB | [Versi DFF baru] Program Chatbot Y (https://github.com/keiffster/program-y) diadaptasi untuk Dream socialbot |
| Program DFF Y Keterampilan Berbahaya | RAM 100 MB | [Versi DFF baru] Program Chatbot Y (https://github.com/keiffster/program-y) diadaptasi untuk Dream socialbot, berisi respons terhadap situasi berbahaya dalam dialog |
| Program DFF dan Keterampilan Luas | RAM 110 MB | [Versi DFF baru] Program Chatbot Y (https://github.com/keiffster/program-y) diadaptasi untuk Dream socialbot, yang hanya mencakup templat yang sangat umum (dengan tingkat kepercayaan lebih rendah) |
| Keterampilan Bicara Kecil | RAM 35MB | mengajukan pertanyaan menggunakan naskah tulisan tangan untuk 25 topik, termasuk namun tidak terbatas pada cinta, olahraga, pekerjaan, hewan peliharaan, dll. |
| Keterampilan Super Bowl | RAM-nya 30 MB | mendukung FAQ, fakta, dan skrip untuk SuperBowl |
| Teks QA | RAM 1,8GB, GPU 2,8GB | Layanan ini menemukan jawaban atas pertanyaan faktual dalam teks. |
| Keterampilan Hari Valentine | RAM-nya 30 MB | mendukung FAQ, fakta, dan skrip untuk Hari Valentine |
| Keterampilan Memanggil Wikidata | RAM 100 MB | menghasilkan ucapan menggunakan kembar tiga Wikidata. Belum dihidupkan, perlu perbaikan |
| Keterampilan Hewan DFF | RAM 200 MB | dibuat menggunakan DFF dan memiliki tiga cabang percakapan tentang hewan: hewan peliharaan pengguna, hewan peliharaan dari bot sosial, dan hewan liar |
| Keterampilan Seni DFF | RAM 100 MB | Keterampilan berbasis DFF untuk mendiskusikan seni |
| Keterampilan Buku DFF | RAM 400 MB | [Versi DFF baru] mendeteksi judul buku dan penulis yang disebutkan dalam ucapan pengguna dengan bantuan pengurai Wiki dan tautan Entitas serta merekomendasikan buku dengan memanfaatkan informasi dari database GoodReads |
| Keterampilan Persona Bot DFF | RAM 150 MB | bertujuan untuk mendiskusikan favorit pengguna dan 20 hal terpopuler dengan cerita pendek yang mengungkapkan pendapat socialbot terhadap mereka |
| Keterampilan Virus Corona DFF | RAM 110 MB | [Versi DFF baru] mengambil data tentang jumlah kasus dan kematian virus corona di berbagai lokasi yang bersumber dari Pusat Sains dan Teknik Sistem Universitas John Hopkins |
| Keterampilan Makanan DFF | RAM 150 MB | dibangun dengan DFF untuk mendorong percakapan terkait makanan |
| Keterampilan Persahabatan DFF | RAM 100 MB | [Versi DFF baru] Keterampilan berbasis DFF untuk menyapa pengguna di awal dialog, dan meneruskan pengguna ke beberapa keterampilan skrip |
| Keterampilan Fakta Fungsi DFF | RAM 100 MB | [Versi DFF baru] Memberi tahu pengguna fakta menarik |
| Keterampilan Permainan DFF | RAM-nya 80 MB | menyediakan diskusi video game. Gaming Skill adalah untuk pembicaraan yang lebih umum tentang video game |
| Keterampilan Gosip DFF | RAM-nya 95MB | Keterampilan berbasis DFF untuk mendiskusikan orang lain dengan berita tentang mereka |
| Keterampilan Gambar DFF | RAM 100 MB | [Versi DFF baru] Keterampilan tertulis yang berdasarkan teks gambar yang dikirim (dari anotasi) merespons dengan respons tertentu jika makanan, hewan, atau orang terdeteksi, dan respons default sebaliknya |
| Keterampilan Templat DFF | RAM 50MB | [Versi DFF baru] Skill berbasis DFF yang memberikan contoh penggunaan DFF |
| Keterampilan yang Diminta Template DFF | RAM 50 MB | [Versi DFF baru] Keterampilan berbasis DFF yang memberikan jawaban yang dihasilkan oleh model bahasa berdasarkan petunjuk yang ditentukan dan konteks dialog. Model yang akan digunakan ditentukan dalam GENERATIVE_SERVICE_URL. Misalnya, Anda dapat menggunakan layanan Transformer LM GPTJ. |
| Keterampilan Pembumian DFF | RAM-nya 90 MB | [Versi DFF baru] Keterampilan berbasis DFF untuk menjawab apa yang menjadi topik pembicaraan, untuk menghasilkan pengakuan, untuk menghasilkan respons universal pada beberapa aksi dialog MIDAS |
| Responden Niat DFF | RAM 100 MB | [Versi DFF baru] menyediakan balasan berbasis templat untuk beberapa maksud yang terdeteksi oleh anotator Intent Catcher |
| Keterampilan Film DFF | RAM 1,1GB | diimplementasikan menggunakan DFF dan menangani percakapan terkait film |
| Keterampilan Musik DFF | RAM-nya 70 MB | Keterampilan berbasis DFF untuk mendiskusikan musik |
| Keterampilan Sains DFF | RAM-nya 90 MB | Keterampilan berbasis DFF untuk mendiskusikan sains |
| Keterampilan Cerpen DFF | RAM-nya 90MB | [Versi DFF baru] menceritakan cerita pendek pengguna dari 3 kategori: (1) cerita pengantar tidur, seperti dongeng dan cerita moral, (2) cerita horor, dan (3) cerita lucu |
| Keterampilan Olahraga DFF | RAM-nya 70 MB | Keterampilan berbasis DFF untuk berdiskusi tentang olahraga |
| Keterampilan Perjalanan DFF | RAM-nya 70 MB | Keterampilan berbasis DFF untuk mendiskusikan perjalanan |
| Keterampilan Cuaca DFF | RAM 1,4 GB | [Versi DFF baru] menggunakan layanan OpenWeatherMap untuk mendapatkan perkiraan lokasi pengguna |
| Keterampilan Wiki DFF | RAM 150 MB | digunakan untuk membuat skenario dengan ekstraksi entitas, pengisian slot, penyisipan fakta, dan pengakuan |
| Nama | Persyaratan | Keterangan |
|---|---|---|
| Keterampilan FAQ AI | RAM 150 MB | [Versi DFF baru] Segala sesuatu yang ingin Anda ketahui tentang AI modern tetapi takut untuk bertanya! Asisten FAQ ini mengobrol dengan Anda sambil menjelaskan topik paling sederhana dari dunia teknologi saat ini. |
| Keterampilan Penata Busana | RAM 150 MB | [Versi DFF baru] Tetap terlindungi di setiap musim dengan Asisten Pakaian da Costa Industries! Rasakan kenyamanan dan perlindungan terbaik, apa pun cuacanya. Tetap hangat di musim dingin... |
| Keterampilan Persona Impian | RAM 150 MB | [Versi DFF baru] Keterampilan berbasis perintah yang memanfaatkan layanan generatif yang diberikan untuk menghasilkan respons berdasarkan perintah yang diberikan |
| Keterampilan Pemasaran | RAM 150 MB | [Versi DFF baru] Terhubung dengan audiens Anda dengan cara yang belum pernah ada sebelumnya dengan Asisten AI Pemasaran! Raih tingkat kesuksesan baru dengan memanfaatkan kekuatan empati. Ucapkan selamat tinggal.. |
| Keterampilan Dongeng | RAM 150 MB | [Versi DFF baru] Asisten ini akan menceritakan dongeng singkat namun menarik kepada Anda atau anak Anda. Pilih karakter dan topik dan serahkan sisanya pada imajinasi AI. |
| Keterampilan Gizi | RAM 150 MB | [Versi DFF baru] Temukan rahasia makan sehat dengan asisten AI kami! Temukan pilihan makanan bergizi untuk Anda dan orang yang Anda cintai dengan mudah. Ucapkan selamat tinggal pada stres saat makan dan sambut makanan lezat... |
| Keterampilan Pembinaan Kehidupan | RAM 150 MB | [Versi DFF baru] Buka potensi penuh Anda dengan asisten AI yang dipatenkan Rhodes & Co! Raih kinerja puncak di tempat kerja dan di rumah. Raih performa terbaik dengan mudah dan berikan inspirasi kepada orang lain. |
Kuratov Y. dkk. Laporan teknis DREAM untuk Alexa Prize 2019 //Alexa Prize Proceedings. – 2020.
Baymurzina D.dkk. Laporan Teknis DREAM untuk Alexa Prize 4 //Prosiding Alexa Prize. – 2021.
DeepPavlov Dream dilisensikan di bawah Apache 2.0.
Program-y (lihat dream/skills/dff_program_y_skill , dream/skills/dff_program_y_wide_skill , dream/skills/dff_program_y_dangerous_skill ) dilisensikan di bawah Apache 2.0. Eliza (lihat dream/skills/eliza ) dilisensikan di bawah Lisensi MIT.
Untuk membuat sertifikasi xlsx - file dengan respons bot, Anda dapat menggunakan skrip xlsx_responder.py dengan menjalankan
docker-compose -f docker-compose.yml -f dev.yml exec -T -u $( id -u ) agent python3
utils/xlsx_responder.py --url http://0.0.0.0:4242
--input ' tests/dream/test_questions.xlsx '
--output ' tests/dream/output/test_questions_output.xlsx '
--cache tests/dream/output/test_questions_output_ $( date --iso-8601=seconds ) .json Pastikan semua layanan dikerahkan. --input - file xlsx dengan pertanyaan sertifikasi, --output - file xlsx dengan respons bot, --cache - json , yang berisi markup terperinci dan digunakan untuk cache.


