Okapi
1.0.0
Oke
Model Bahasa Besar yang disesuaikan dengan instruksi dalam Berbagai Bahasa dengan Pembelajaran Penguatan dari Umpan Balik Manusia
Ini adalah repo kerangka kerja Okapi yang memperkenalkan sumber daya dan model untuk penyetelan instruksi untuk model bahasa besar (LLM) dengan pembelajaran penguatan dari umpan balik manusia (RLHF) dalam berbagai bahasa. Kerangka kerja kami mendukung 26 bahasa, termasuk 8 bahasa dengan sumber daya tinggi, 11 bahasa dengan sumber daya sedang, dan 7 bahasa dengan sumber daya rendah.
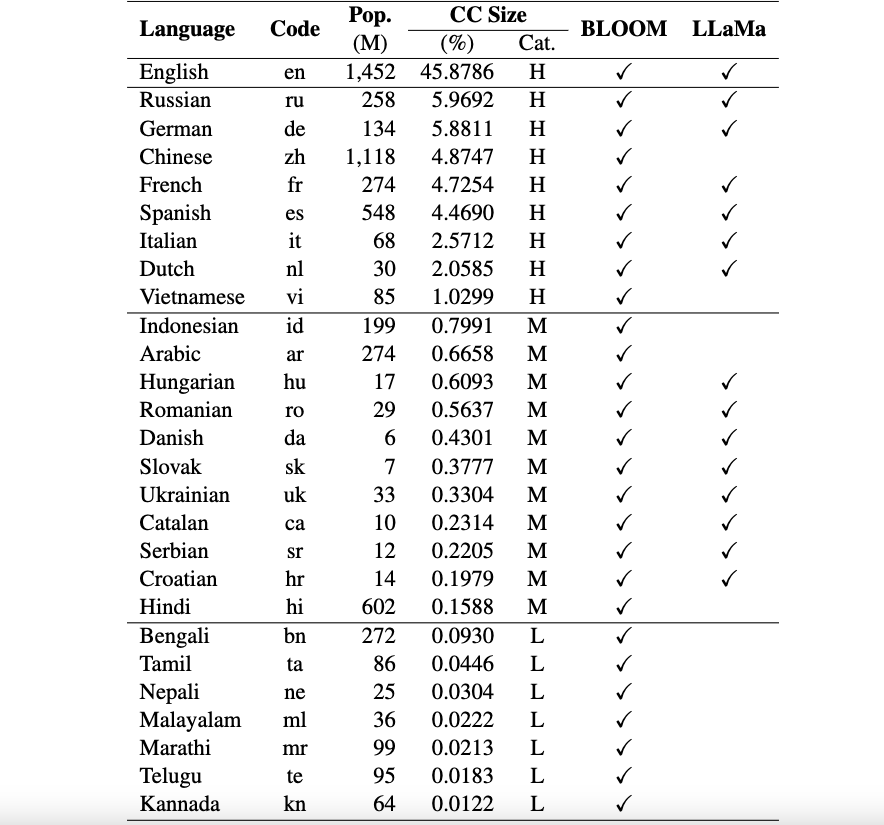
Sumber Daya Okapi : Kami menyediakan sumber daya untuk melakukan penyetelan instruksi dengan RLHF untuk 26 bahasa, termasuk perintah ChatGPT, kumpulan data instruksi multibahasa, dan data peringkat respons multibahasa.
Model Okapi : Kami menyediakan LLM yang disesuaikan dengan instruksi berbasis RLHF untuk 26 bahasa pada kumpulan data Okapi. Model kami mencakup versi berbasis BLOOM dan berbasis LLaMa. Kami juga menyediakan skrip untuk berinteraksi dengan model kami dan menyempurnakan LLM dengan sumber daya kami.
Kumpulan Data Tolok Ukur Evaluasi Multibahasa : Kami menyediakan tiga kumpulan data tolok ukur untuk mengevaluasi Model Bahasa Besar Multibahasa (LLM) untuk 26 bahasa. Anda dapat mengakses kumpulan data lengkap dan skrip evaluasi: di sini.
Pemberitahuan Penggunaan dan Lisensi : Okapi ditujukan dan dilisensikan hanya untuk penggunaan penelitian. Kumpulan datanya adalah CC BY NC 4.0 (hanya mengizinkan penggunaan non-komersial) dan model yang dilatih menggunakan kumpulan data tersebut tidak boleh digunakan di luar tujuan penelitian.
Makalah teknis kami dengan hasil evaluasi dapat ditemukan di sini.
Kami melakukan proses pengumpulan data yang komprehensif untuk menyiapkan data yang diperlukan untuk kerangka multibahasa Okapi kami dalam empat langkah utama:
Untuk mendownload seluruh dataset, Anda dapat menggunakan skrip berikut:
bash scripts/download.shJika Anda hanya memerlukan data untuk bahasa tertentu, Anda dapat menentukan kode bahasa sebagai argumen pada skrip:
bash scripts/download.sh [LANG]
# For example, to download the dataset for Vietnamese: bash scripts/download.sh viSetelah diunduh, data rilis kami dapat ditemukan di direktori kumpulan data . Ini termasuk:
multilingual-alpaca-52k : Data yang diterjemahkan untuk 52 ribu instruksi bahasa Inggris di Alpaca ke dalam 26 bahasa.
multilingual-ranking-data-42k : Data peringkat respons multibahasa untuk 26 bahasa. Untuk setiap bahasa, kami menyediakan 42 ribu instruksi; masing-masing memiliki 4 tanggapan peringkat. Data ini dapat digunakan untuk melatih model reward untuk 26 bahasa.
multilingual-rl-tuning-64k : Data instruksi multibahasa untuk RLHF. Kami menyediakan 62 ribu instruksi untuk masing-masing 26 bahasa.
Dengan menggunakan kumpulan data Okapi dan teknik penyetelan instruksi berbasis RLHF, kami memperkenalkan LLM multibahasa yang disempurnakan untuk 26 bahasa, yang dibangun di atas LLaMA dan BLOOM versi 7B. Modelnya bisa didapatkan dari HuggingFace di sini.
Okapi mendukung obrolan interaktif dengan LLM multibahasa yang disesuaikan dengan instruksi dalam 26 bahasa. Ikuti langkah-langkah berikut untuk obrolan:
git clone https://github.com/nlp-uoregon/Okapi.git
cd Okapi
pip install -r requirements.txt
from chat import pipeline
model_path = 'uonlp/okapi-vi-bloom'
p = pipeline ( model_path , gpu = True )
instruction = 'Dịch câu sau sang Tiếng Việt' # Translate the following sentence into Vietnamese
prompt_input = 'The City of Eugene - a great city for the arts and outdoors. '
response = p . generate ( instruction = instruction , prompt_input = prompt_input )
print ( response )Kami juga menyediakan skrip untuk menyempurnakan LLM dengan data instruksi kami menggunakan RLHF, yang mencakup tiga langkah utama: penyesuaian yang diawasi, pemodelan penghargaan, dan penyesuaian dengan RLHF. Gunakan langkah-langkah berikut untuk menyempurnakan LLM:
conda create -n okapi python=3.9
conda activate okapi
pip install -r requirements.txtbash scripts/supervised_finetuning.sh [LANG]bash scripts/reward_modeling.sh [LANG]bash scripts/rl_training.sh [LANG]Jika Anda menggunakan data, model, atau kode dalam repositori ini, harap kutip:
@article { dac2023okapi ,
title = { Okapi: Instruction-tuned Large Language Models in Multiple Languages with Reinforcement Learning from Human Feedback } ,
author = { Dac Lai, Viet and Van Nguyen, Chien and Ngo, Nghia Trung and Nguyen, Thuat and Dernoncourt, Franck and Rossi, Ryan A and Nguyen, Thien Huu } ,
journal = { arXiv e-prints } ,
pages = { arXiv--2307 } ,
year = { 2023 }
}

