Ovis
1.0.0
Ovis (Open VISion) adalah arsitektur Multimodal Large Language Model (MLLM) baru, yang dirancang untuk menyelaraskan struktur visual dan tekstual. Untuk pengenalan yang komprehensif, silakan merujuk ke makalah Ovis.
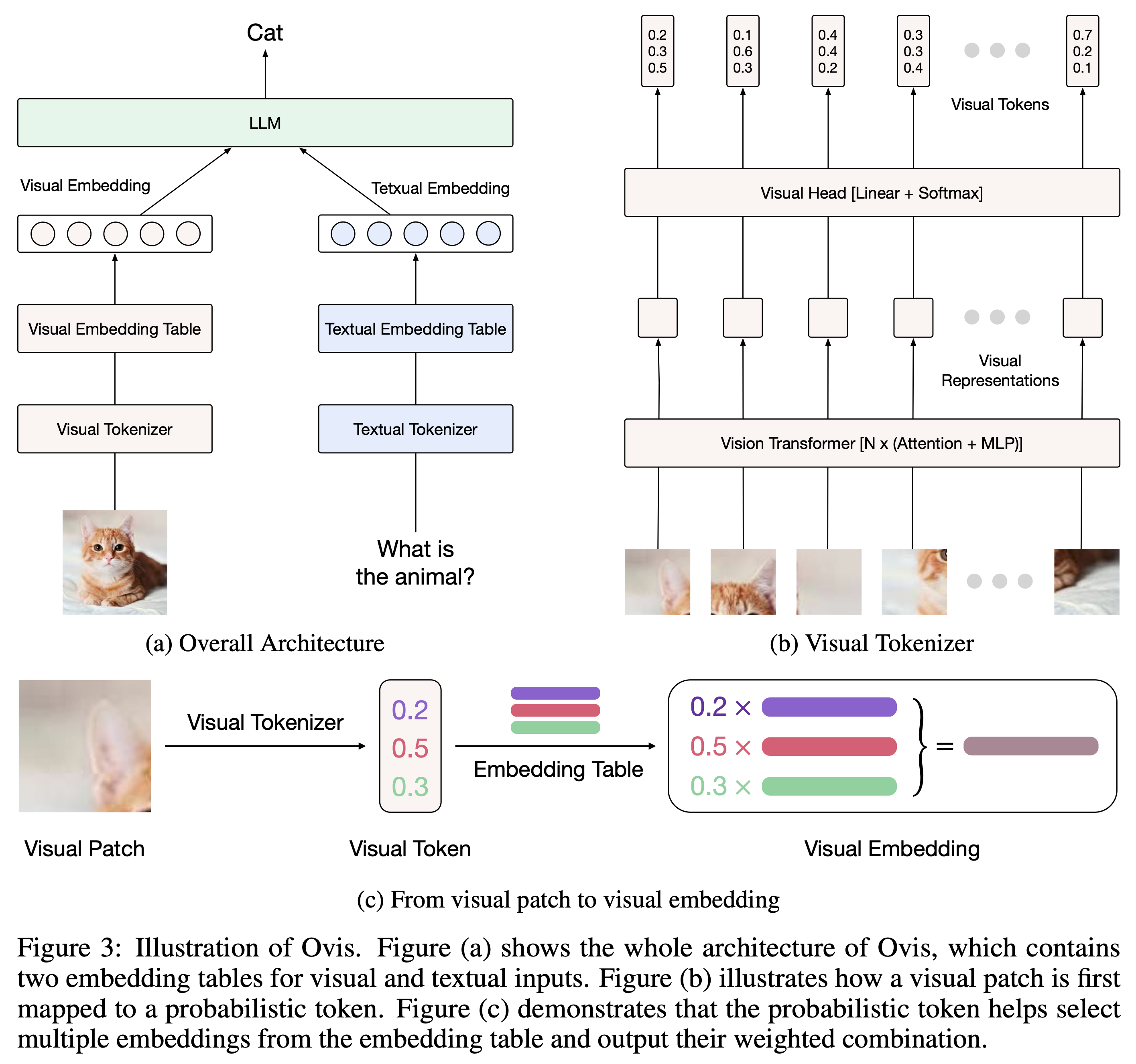
Ovis telah diuji dengan Python 3.10, Torch 2.4.0, Transformers 4.46.2, dan DeepSpeed 0.15.4. Untuk daftar lengkap dependensi paket, silakan lihat file requirements.txt . Sebelum melakukan finetuning atau inferensi, harap instal Ovis sebagai berikut.
git clone [email protected]:AIDC-AI/Ovis.git
conda create -n ovis python=3.10 -y
conda activate ovis
cd Ovis
pip install -r requirements.txt
pip install -e . Ovis dapat dipakai dengan LLM populer. Kami menyediakan Ovis MLLM berikut:
| Ovis MLLM | ViT | LLM | Bobot Model | Demo |
|---|---|---|---|---|
| Ovis1.6-Gemma2-27B | Siglip-400M | Gemma2-27B-Itu | wajah berpelukan | - |
| Ovis1.6-Gemma2-9B | Siglip-400M | Gemma2-9B-Itu | wajah berpelukan | Ruang angkasa |
| Ovis1.6-Llama3.2-3B | Siglip-400M | Llama-3.2-3B-Instruksikan | wajah berpelukan | Ruang angkasa |
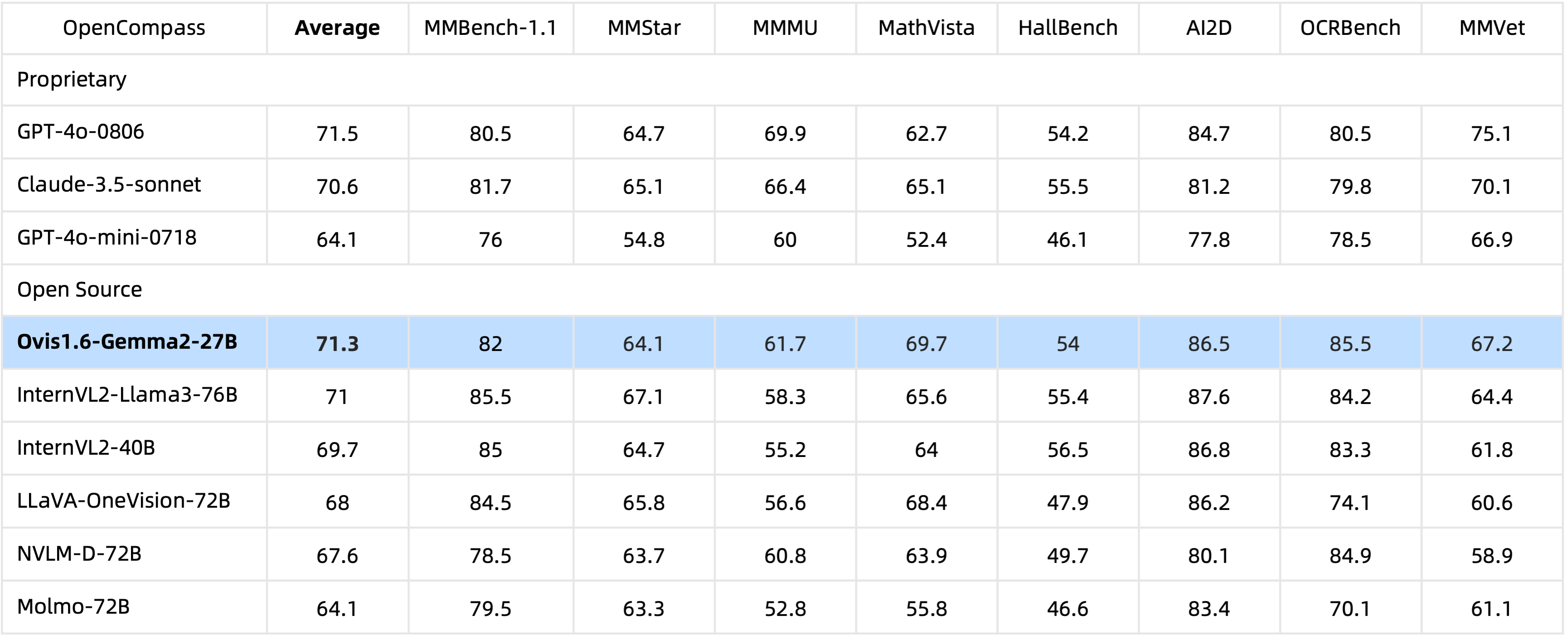
Dengan parameter 29B , Ovis1.6-Gemma2-27B mencapai kinerja luar biasa dalam benchmark OpenCompass, termasuk di antara MLLM sumber terbuka tingkat atas.
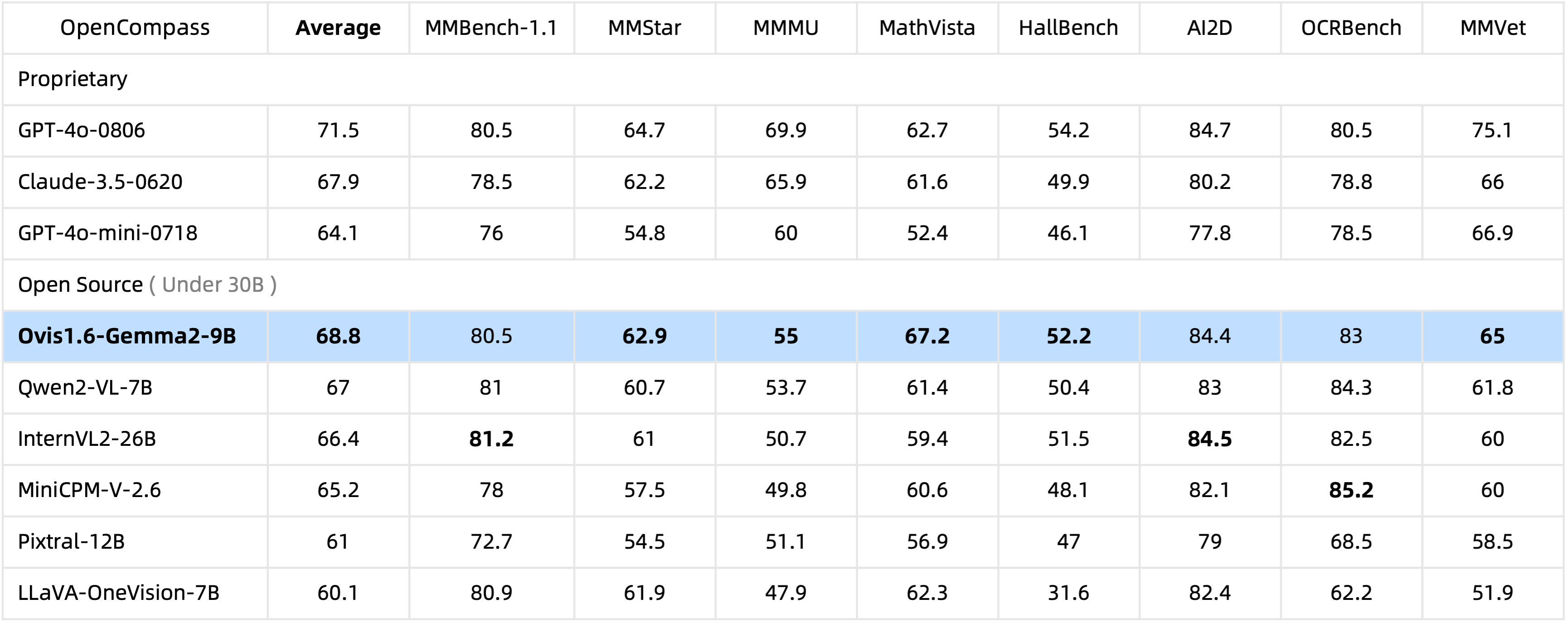
Dengan hanya parameter 10 miliar , Ovis1.6-Gemma2-9B memimpin tolok ukur OpenCompass di antara MLLM sumber terbuka dalam parameter 30 miliar .
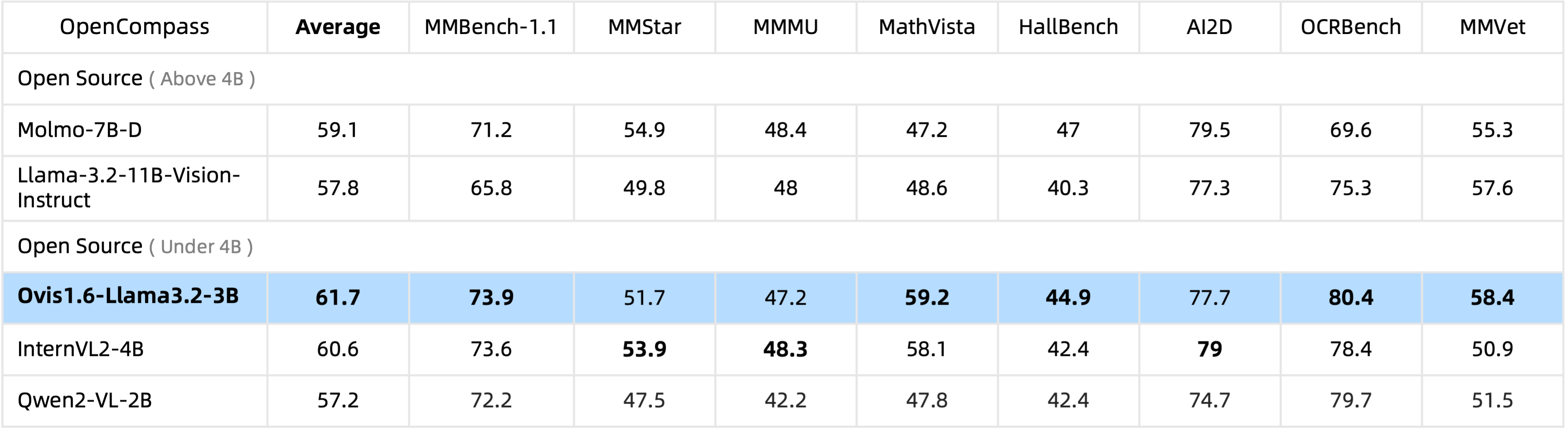
Ovis1.6-Llama3.2-3B memimpin tolok ukur OpenCompass di antara MLLM sumber terbuka dengan parameter 4B , bahkan melampaui Llama-3.2-11B-Vision-Instruct.
Penyempurnaan Ovis1.6-Gemma2-9B didukung di ms-swift.
Kami menyediakan pembungkus inferensi di ovis/serve/runner.py , yang dapat digunakan sebagai:
from PIL import Image
from ovis . serve . runner import RunnerArguments , OvisRunner
image = Image . open ( 'IMAGE_PATH' )
text = 'PROMPT'
runner_args = RunnerArguments ( model_path = 'MODEL_PATH' )
runner = OvisRunner ( runner_args )
generation = runner . run ([ image , text ])Berdasarkan Gradio, Ovis juga dapat diakses melalui antarmuka pengguna web:
python ovis/serve/server.py --model_path MODEL_PATH --port PORTKami mengukur Ovis1.6 menggunakan AutoGPTQ. Untuk informasi mendetail tentang menjalankan dan membuat versi terkuantisasi Anda sendiri, silakan merujuk ke masing-masing kartu model Huggingface: Ovis1.6-Gemma2-9B-GPTQ-Int4 dan Ovis1.6-Llama3.2-3B-GPTQ-Int4. Ovis1.6 yang terkuantisasi mempertahankan performa yang sebanding dengan versi non-kuantisasinya, namun memerlukan lebih sedikit memori GPU:
Kinerja tolok ukur: 

Penggunaan memori GPU (max_partition=9): 
Jika menurut Anda Ovis bermanfaat, silakan kutip makalahnya
@article{lu2024ovis,
title={Ovis: Structural Embedding Alignment for Multimodal Large Language Model},
author={Shiyin Lu and Yang Li and Qing-Guo Chen and Zhao Xu and Weihua Luo and Kaifu Zhang and Han-Jia Ye},
year={2024},
journal={arXiv:2405.20797}
}
Pekerjaan ini merupakan upaya kolaboratif tim MarcoVL. Kami juga ingin memberikan tautan ke makalah MLLM berikut dari tim kami:
Proyek ini dilisensikan di bawah Lisensi Apache, Versi 2.0 (SPDX-License-Identifier: Apache-2.0).
Kami menggunakan algoritme pemeriksaan kepatuhan selama proses pelatihan, untuk memastikan kepatuhan model yang dilatih sesuai kemampuan terbaik kami. Karena kompleksitas data dan keragaman skenario penggunaan model bahasa, kami tidak dapat menjamin bahwa model tersebut sepenuhnya bebas dari masalah hak cipta atau konten yang tidak patut. Jika Anda yakin ada sesuatu yang melanggar hak Anda atau menghasilkan konten yang tidak pantas, silakan hubungi kami, dan kami akan segera mengatasi masalah tersebut.


